
文章目录
TransFG: A Transformer Architecture for Fine-grained Recognition
Abstract
目前的工作主要通过关注如何定位最具识别度的区域并依靠它们来提高网络捕捉细微变化的能力来完成FGVC。
这些工作中的大部分是通过RPN模块来提出绑定框并重新使用主干网络来提取所选框的特征。
近年来,ViT在传统分类任务重大放异彩,其自我关注机制将每个patch的token连接到分类token。注意力连接的强度可以被直观地视为表征重要性的指标。
本文中,提出了一个新的、基于transformer的结构TransFG。
本文将所有原始注意力权重聚合为一个注意力图来指导网络有效且准确地选择有区分度的图像块并且计算他们之间的关系。
此外,本文还用对比损失来进一步扩大相似子类的特征表示之间的距离。
introduction
为了避免劳动密集的局部标注问题,目前主要聚焦于仅有图像标签的弱监督FGVC。
现有的方法主要分为两大类,即定位方法与特征编码方法。定位方法的优势在于能够明确捕捉不同子类之间的细微差异,更具有可解释性以及更好的结果。
典型的策略是使用局部特征进行分类并且采用rank loss老保持bbox和输出概率之间的一致性。
然而,这样的方法显然忽视了所选择区域之间的关系,并且鼓励RPN产生一些大的bbox以包含更多的局部从而产生正确的分类结果。甚至,大的bbox会造成背景的混乱。
vision transformer取得巨大成功,这表明将具有固有注意力机制的pure transformer直接应用到图像块序列时能够捕捉重要的区域从而促进分类。
本文提出了TransFG,是一个基于ViT的简单且有效的框架,具体来说:
- 通过利用先天的多头自我注意力机制,本文提出了一个局部选择模块来计算有区分度的区域并且去除冗余信息。
- 本文将所选的局部token与全局token连接起来,作为i最后一个transformer层的输入序列;
- 引入duplicate loss来估计多头注意力模块产生不同的结果。
这样一种策略推动网络聚焦于图像的不同区域。为了进一步增大不同类别样本的特征表示之间的距离,减小同类样本的特征表示之间的距离,本文引入了对比损失来进一步提高性能。
Method
Vision transformer as feature extractor
Image Sequentialization
遵循ViT,首先将输入图像预处理成一系列展平的patches
x
p
x_p
xp。
然而,这些原始的分割方法将图像裁剪成为一些non-overlapping的patches,严重伤害了local neighboring structures。尤其是有区分度的区域被分开了(因为是简单的分割,可能鸟的一半头是一块,另一半头在另一块)。
为了解决这一问题,本文提出了用滑动窗口生成重叠的patches。
具体来说,我们设输入图像的分辨率为
H
∗
W
H*W
H∗W,image patch的size为
P
P
P,滑动窗口的步长为
S
S
S,于是我们能得到N个patches。
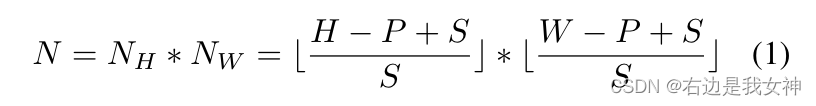
于是,两个连接的patches就有了重叠的区域,尺寸为
(
P
−
S
)
∗
P
(P-S)*P
(P−S)∗P,帮助保护更好的局部区域信息。
按理来说,步长越小,性能越好,但是随着减小S,也会增大计算代价。
Patch Embedding
本文使用可训练的线性投影将矢量化的patches嵌入一个潜在的D维空间。
一个可学习的位置嵌入被加入到patch embedding中来保持位置信息,其操作如下所示:
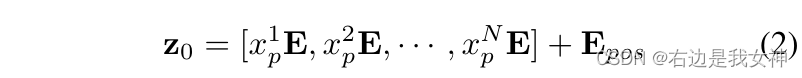
其中,
E
∈
R
(
P
2
⋅
C
)
∗
D
E\in R^{(P^2\cdot C)*D}
E∈R(P2⋅C)∗D,
E
p
o
s
∈
R
N
∗
D
E_{pos}\in R^{N*D}
Epos∈RN∗D。
Transformer encoder包含L个多头自注意力(MSA)和MLP模块。
单层的操作如下所示:
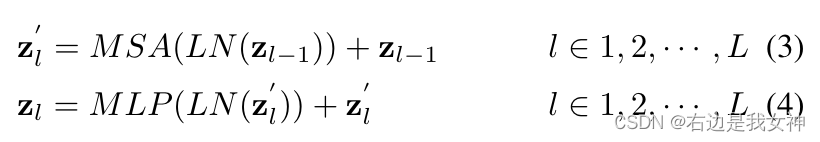
其中,
L
N
(
⋅
)
LN(\cdot)
LN(⋅)是层归一化。ViT将最后一层的第一个token
Z
L
0
Z_L^0
ZL0作为全局特征并且把它送入到一个分类器的头部来获得最终的分类结果而**没有考虑剩下token中的潜在信息**。
TransFG Architecture
pure ViT可以直接用于FGVC当中,但是没有很好地捕获FGVC所需的本地信息。为此,本文提出了部分选择模块PSM,并应用对比学习来扩大相似子类别之间的表示距离。
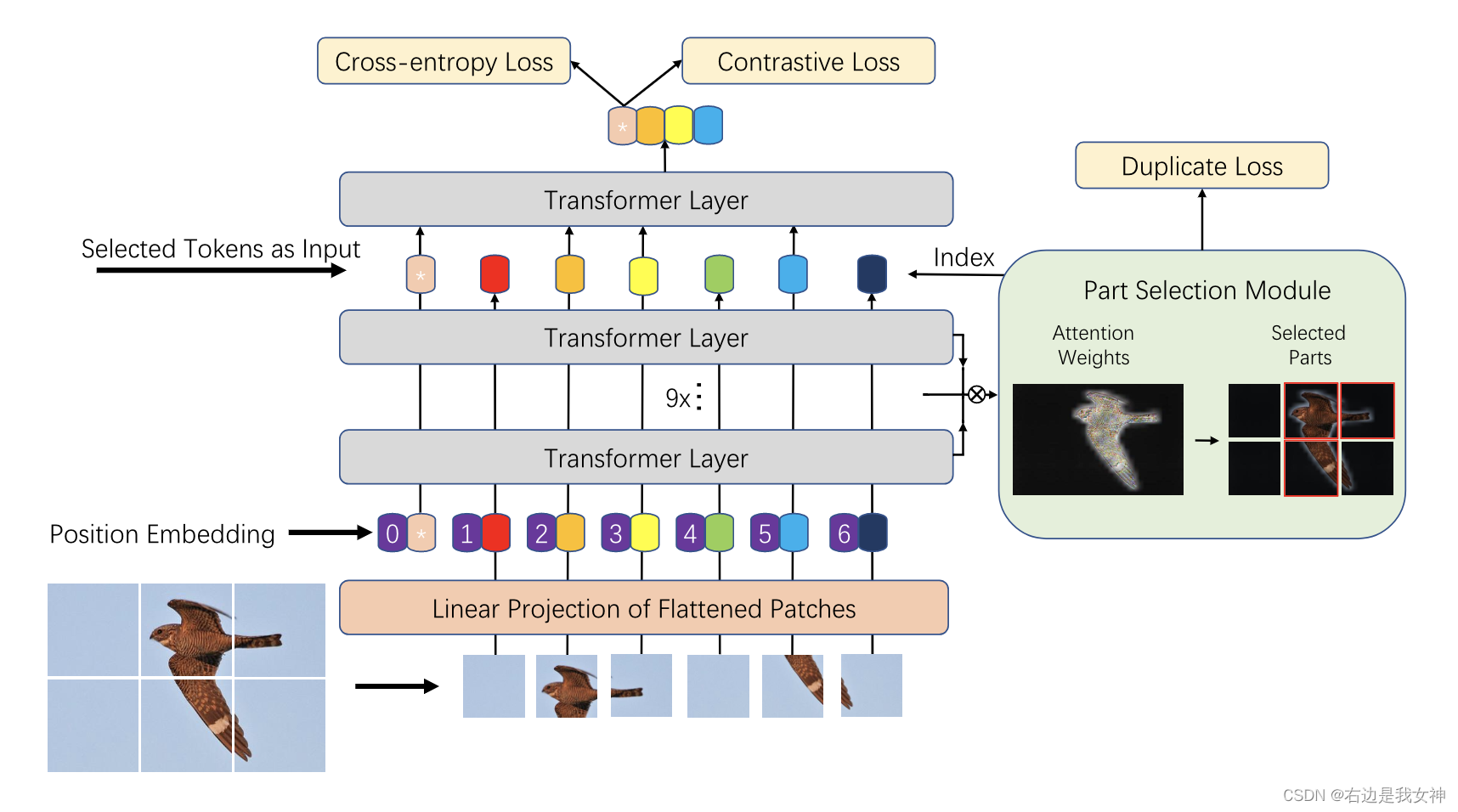
Part Selection Module
假设模型有K个自注意力头并且设送入最后一层的隐藏的特征是
z
L
−
1
=
[
z
L
−
1
0
,
z
L
−
1
1
,
.
.
.
,
z
L
−
1
N
]
z_{L-1}=[z_{L-1}^0,z_{L-1}^1,...,z_{L-1}^N]
zL−1=[zL−10,zL−11,...,zL−1N]。
其中,前几层的注意力权重可以写为:
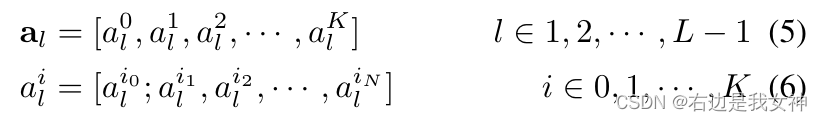
可见,每个头的注意力都是一个向量。
先前的工作表明,原始的注意力权重不一定对应于输入token的相对重要性,特别是对模型的较高层来说,因为缺乏嵌入token的可识别性。
因此,我们考虑聚合所有先前层的注意力权重。具体来说,我们递归地将矩阵乘法应用于所有层:
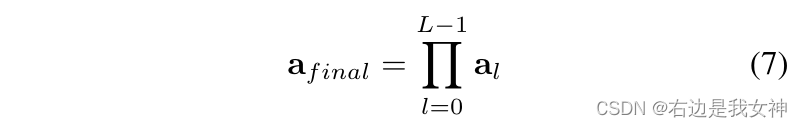
其捕捉了信息是如何从输入层传播到更高的嵌入层的。
相比于单一层的原始注意力权重
a
L
−
1
a_{L-1}
aL−1,这个矩阵扮演了一个更好的选择来选取有区分度的区域。
我们之后选择关于
a
f
i
n
a
l
a_{final}
afinal中K个不同的注意力头的最大值
A
1
,
A
2
,
.
.
.
,
A
K
A_1,A_2,...,A_K
A1,A2,...,AK的索引。这些位置被用作我们模型的索引来提取
z
L
−
1
z_{L-1}
zL−1中相关的索引。
最终,我们连接这些选择的tokens并标注为: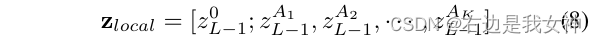
我们不仅保持全局信息,同时也强迫了最后一个Transformer Layer关注微小的不同。
为了估计多头注意力关注不同的有区分度的区域,我们加入了duplicate loss来限制选取相同的区域: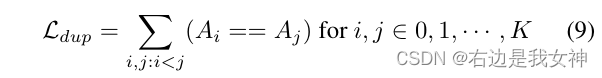
Constrastive feature learning
我们仍然采用PSM的第一个token来进行分类。一个简单的交叉熵损失不足以完全监督这个特征的学习,因为子类之间的不同是比较小的。
于是,我们采用对比损失以最小化不同标签对应的分类token的相似性并且最大化相同标签对应的分类token之间的相似性。
为了防止损失轻易被简单的负样本支配,我们引入了一个常数间隔
α
\alpha
α,意味着只有负样本对的相似性比
α
\alpha
α大时才会对损失有贡献。
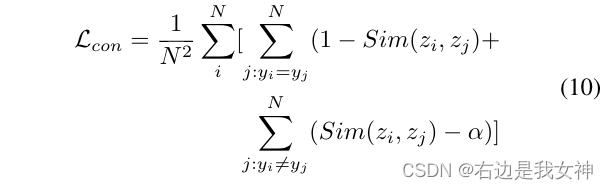
意思是,样本标签不一样的两个样本往往对应的特征就该是极度不相似的,这样的简单负样本会很大程度上影响模型。
最终的损失函数由三部分组成:
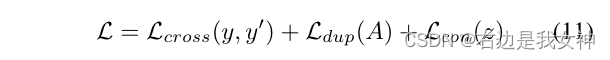
ViT-FOD:A Vision Transformer based Fine-grained Object Discriminator
Abstract
目前一些基于ViT的方法被提出,这些方法是明显优于现有的基于CNN的方法的。
然而,将ViT直接应用于FGVC有一些限制:
- ViT需要将图像分割为小块并计算每一对的注意力,这可能会导致大量冗余计算,并且在处理具有复杂背景和小对象的细粒度图像时性能不令人满意;
- 标准ViT仅仅利用最后一层的类token进行分类,这不足以提取全面的细粒度信息。
为了解决上述两项问题,本文基于细粒度对象鉴别器提出了一种新的ViT,简称为ViT-FOD。
具体来说,出了ViT的主干之外,它还引入了三个新的组件,分别是Attention Patch Combination(APC)、Critical Regions Filter(CRF)以及Complementary Tokens Integration(CTI)。
其中,APC从两幅图像中分割出信息块来生成一幅新图像,减少冗余计算。CRF强调对于具有区分度区域的token,以产生用于细微特征学习的新的类别token。为了提取全面的信息,CTI集成了由不同ViT层中的类别token捕获的补充信息。
Introduction
基于CNN的方法缺乏适当的手段来建立这些区域之间的关系并将它们集成到一个统一的概念中,而自注意力机制是解决这一问题的方法。
目前有这几篇论文做了研究,取得了初步的成功:
- Ju He, Jie-Neng Chen, Shuai Liu, Adam Kortylewski, Cheng Yang, Yutong Bai,Changhu Wang, and Alan Yuille. 2022. TransFG: A Transformer Architecturefor Fine-grained Recognition. InProceedings of the AAAI Conference on ArtificialIntelligence
- Yunqing Hu, Xuan Jin, Yin Zhang, Haiwen Hong, Jingfeng Zhang, Yuan He,and Hui Xue. 2021. RAMS-Trans: Recurrent Attention Multi-scale Transformerfor Fine-grained Image Recognition. InProceedings of the ACM InternationalConference on Multimedia. 4239–4248.
- Xinda Liu, Lili Wang, and Xiaoguang Han. 2021. Transformer with Peak Sup-pression and Knowledge Guidance for Fine-grained Image Recognition.arXivpreprint arXiv:2107.06538(2021).
- Jun Wang, Xiaohan Yu, and Yongsheng Gao. 2021. Feature Fusion Vision Trans-former for Fine-grained Visual Categorization.arXiv preprint arXiv:2107.02341(2021).
仍然有一些问题需要考虑:
1)标准的ViT需要将图像分割为小块作为输入,然后每层中的多头自注意力模块(MSA)获得任意两个小块之间的关系。然而,对于精细的图像来说,许多样本包含复杂的背景且一些物体也可能相对较小,于是用ViT进行处理事,不可避免的会产生大量无用的计算,甚至还会引入噪声。

大量的草地块对ViT进行的分类没有什么帮助。
2)ViT使用预先定义的类token进行预测。在标准的ViT模型中,类token和每个图像块一样在MSA中被处理,只有最后一层是被拿出来分类的。从某种角度看,类token是在自注意力的方式下基于所有图像块获得的,这可能不利于它进一步专注于一些关键的、细微的区域。从另一个角度来看,根据本文的实验,来自不同层次的类标记可以提取针对不同信息的特征,并且它们是互补的。因此,仅仅用最终的类标记不足与充分利用ViT的特征提取能力。
本文给出了三个改进模块:
- APC将两幅图像分解成小块,并将其中有信息的图像拼接在一起,生成新图像。这样,它通过用另一幅图像的信息部分替换响应的区域以减少输入图像中背景的影响;
- CRF以较低的计算成本,强调了对应有区分度区域对应的token以生成一个新的类token;
- CTI基于多隔层的类token队对象进行分类以捕获不同层之间的互补的信息。
Method
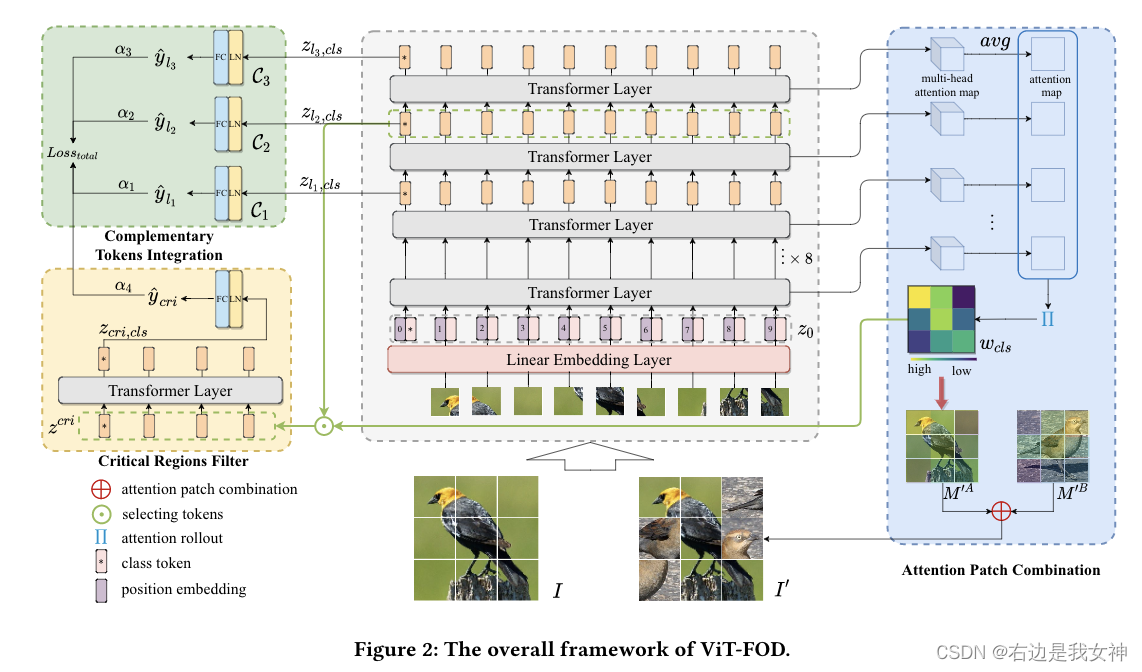
Complementary Tokens Integration
图像
I
I
I被分割为
H
×
W
H\times W
H×W个patches
x
i
∈
R
P
×
P
×
C
,
i
∈
{
1
,
.
.
.
,
N
}
x^i\in R^{P\times P\times C},i\in\{1,...,N\}
xi∈RP×P×C,i∈{1,...,N},P是每个patch的size,C是图像的通道数,
N
=
H
×
W
N=H\times W
N=H×W是patch的数量。
一个线性嵌入层(linear embedding layer)被用来映射每个patch为一个token。此外,一个可学习的class token
x
c
l
s
x_{cls}
xcls被引入来进行分类。
然后,位置编码被引入来维持空间信息。因此,输入第一个Transformer Layer的数据如下所示: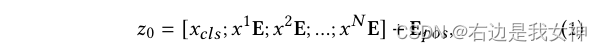
之后就是常规的ViT操作: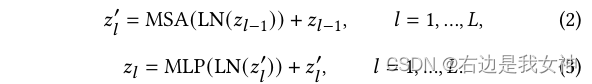
最后一层的class token被送入分类器进行分类以生成标签:
y
^
=
C
L
(
z
L
,
c
l
s
)
\hat{y}=C_L(z_{L,cls})
y^=CL(zL,cls)。
为了信息互补,CTI将每一层的class token送入分类器,得到类别:
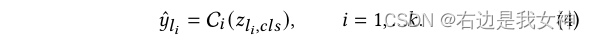
最终的决策由所有预测加权得到,相应的损失为:
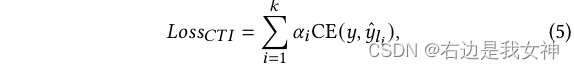
Attention Patch Combination
首先介绍一下Self- Attention的基本运作机制:
我们记注意力图为
A
l
∈
R
(
N
+
1
)
×
(
N
+
1
)
A_l\in R^{(N+1)\times(N+1)}
Al∈R(N+1)×(N+1),对于多头注意力,其size为
R
H
h
e
a
d
(
N
+
1
)
×
(
N
+
1
)
R^{H_{head}(N+1)\times(N+1)}
RHhead(N+1)×(N+1)。
我们增加一个识别矩阵E到这个注意力当中去,并且平均它们来得到每一层的注意力权重: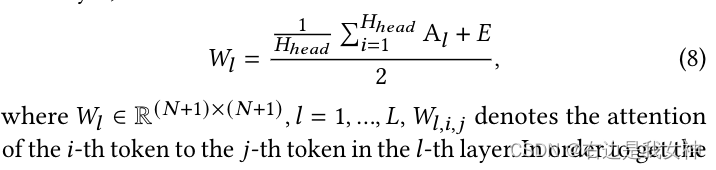
为了得到最终的注意力图,本文采用了attention rollout algorithm,此方法对所有层的注意力权重通过迭代应用一个矩阵乘法:
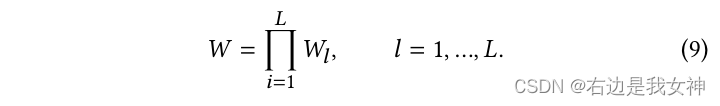
APC的目标是根据权重图将两幅图像的重要patches进行合并以消除冗余计算。此外,APC还可以作为一种数据扩充的方法来提高模型的泛化能力。
具体来说,我们在得到
w
c
l
s
∈
R
N
w_{cls}\in R^N
wcls∈RN之后(class token相对于其他tokens的注意力权重,从W中获得),我们将其reshape成一个二维,然后将它池化为pxp以得到
w
c
l
s
′
∈
R
p
×
p
w_{cls}'\in R^{p\times p}
wcls′∈Rp×p:
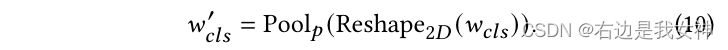
根据权重图,我们可以得到相应的、以降序排列的序列号
i
d
x
c
l
s
idx_{cls}
idxcls。
对于两幅图
I
A
I_A
IA和
I
B
I_B
IB来说,生成掩码
M
A
M^A
MA和
M
B
M^B
MB按照如下方式:
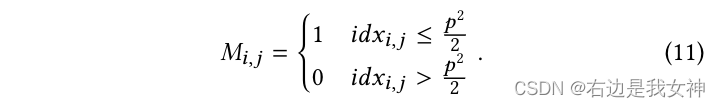
然后我们用下面的操作得到一个新的图像:
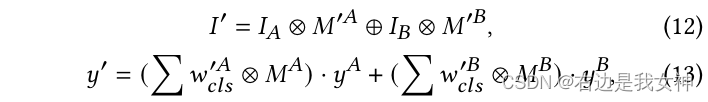
圈乘表示逐元素相乘,圈加则表示用后面1的部分填充前面0的部分。
我来翻译一下:
- 得到一个从原图到final的注意力矩阵的class token部分,体现了每一个token对class token的一个吸引程度,吸引越大表明这部分越重要;
- 把这个局部attention vector二维+池化,相当于对原图划分了一手,按照重要程度对图像块标号,越重要号越靠前,其中的一半标为1,另一半标为0;
- 最后把A图的1图像块和B图的1图像块拼一起。
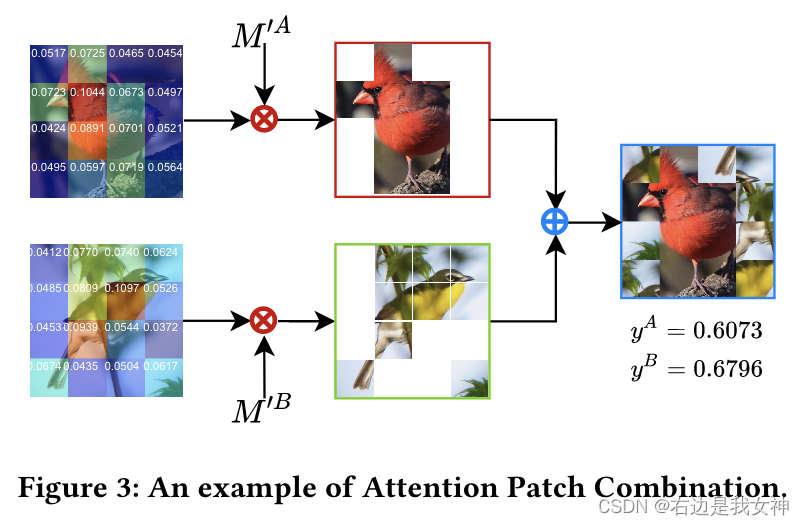
关于合成图的标签,本文给出了相应的计算方法。
这相当于一个复杂的数据增广。
我觉得这么做的道理是,原来模型会学习背景和背景之间的注意力关系,这是没有用的,所以希望模型能多学学关键部位之间的关系。
Critical Regions Filter
裁剪出有区分度的区域然后再训练模型是一个有意思的想法,这在RAMS-Trans中被采用,但是这种方法会显著增加计算成本。此外,矩形裁剪还有一个很大的限制。
为了解决上述问题,本文提出了一个简单且有效的关键区域过滤模块来选择有区分度的区域的token,并生成一个额外的类token来收集所选token的信息。
首先定义了一个阈值
η
\eta
η来控制所选择的token数量。
假设token根据
w
c
l
s
w_{cls}
wcls中的大小降序排序,记第
η
N
\eta N
ηN个token的权重为
w
c
l
s
ˉ
\bar{w_{cls}}
wclsˉ,于是我们选token的方法可以按照下面来:
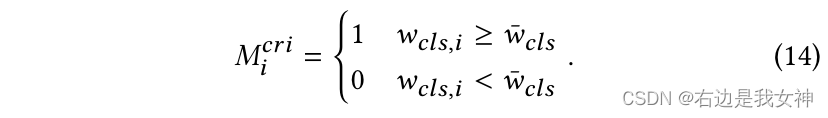
最终,所选择的token和类token被连接作为CRF中的Transformer Layer的输入:

Feature Fusion Vision Transformer for Fine-Grained Visual Categorization
Abstract
ViT在一般的图像识别任务上实现了SOTA的性能。自注意力机制将来自所有token的信息聚集并加权到分类token。然而,深层的分类token更多地关注全局信息,缺少对FGVC重要的局部特征和底层特征。
本文提出了一种新的、基于纯变换的框架融合视觉变换,其中,本文汇集了来自每个变换层的重要的token来补偿局部、低级和中级的信息。
本文设计了一种新的token选择模型,称为相互注意力权重选择(MAWS),以有效地引导网络在不引入额外参数的情况下选择有区别的token。
Introduction
常见的方法分为localization-based和attention-based。
localization-based:早期通过直接注释图像中有区分度的部分实现;之后由于标注的成本大,采用RPN来获得潜在的、有区分度的bbox;
然而,目前的方法忽视了区域之间的关系;并且该类方法往往会促使RPN提出大的bbox,这类bbox不准确,容易发生混淆等问题;此外,有一些区域不能简单地用矩形来标注。
attention-based:接触了对区分区域人工标注的依赖,并且取得了不错的结果。
本文提出的FFVT从低级、中级和高级token中聚集局部信息以促进分类。本文提出了一种新的重要的token选择方法,用于选择每一层上的代表性token。这些token备添加作为最后一个Transformer层的输入。
Methods
ViT For Image Recognition
给一张HxW大小的图,vit首先将它处理为
N
=
⌊
H
P
⌋
×
⌊
W
P
⌋
N=\lfloor\frac{H}{P}\rfloor\times\lfloor\frac{W}{P}\rfloor
N=⌊PH⌋×⌊PW⌋个patch
x
p
x_p
xp。
之后对这些patch进行线性映射与位置编码。之后再加入一个额外的class token,于是输入就完成了:
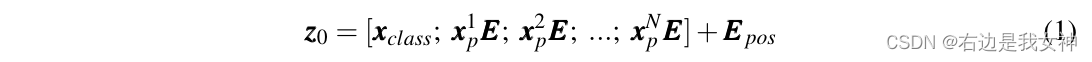
之后就是进入堆叠的MSA层和MLP层: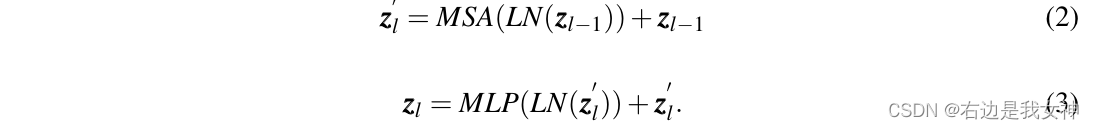
FFVT Architecture
TransFG暗示了这个ViT不能捕捉足够的信息。为了解决这个问题,本文提出融合这些低级的特征和中级的特征来丰富这些局部信息。
本文提出了一个新的token选择方法称为mutual attention weight selection(MAWS)来决定token进行汇集。
整体框架如下所示:

Feature Fusion Module
给出重要的tokens,我们将最后一层的输入用这些tokens进行替换(除了class token)。通过这种方式,class token再最后一层能够与low、middle、high级别的特征进行充分交互,丰富了局部信息和特征表示能力。
我们标记第l层中选出来的tokens为: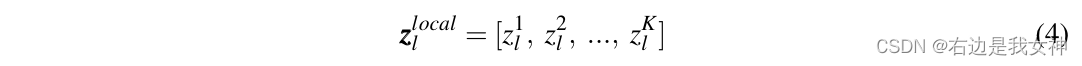
于是,送入最后一层的输入为:
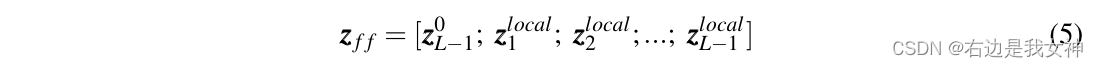
最后,最终层的class token备分发到classification head执行分类。于是,问题变成了如何选择重要的和有区分度的token。
Mutual Attention Weight Selection Module
本文直接使用MSA生成的注意力分数来执行token选择策略。更具体来说,一个attention head的注意力矩阵
A
∈
R
(
N
+
1
)
×
(
N
+
1
)
A\in R^{(N+1)\times(N+1)}
A∈R(N+1)×(N+1)如下表示:
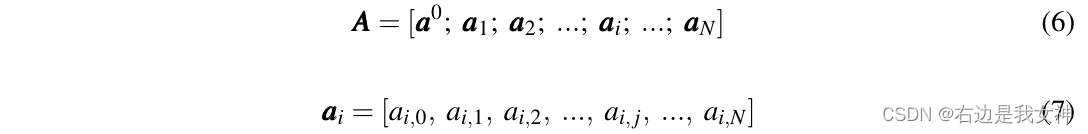
a
i
,
j
a_{i,j}
ai,j表示token I的query和token j的key之间的dot-product。
一种最简单的策略是选择与classification token有更高attention score的token,因为classification token包含丰富的分类信息。
如此一来,只要通过对
a
0
a_0
a0进行排序并且选择K个较大的值对应的索引即可。
本文将这种方法称呼为single attention weight selection(SAWS)。
但是这种方法会引入一些噪声,因为所选择的token能够汇集更多来自noisy patch的信息。
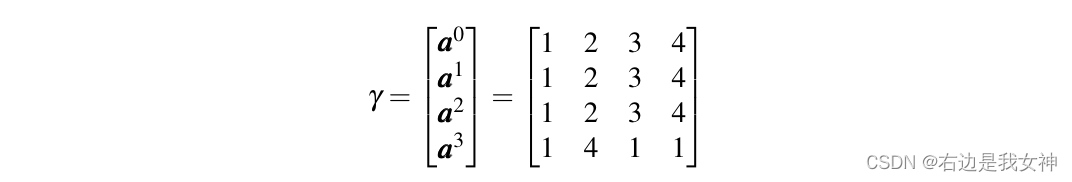
上图中,classification token选择了第三个token,但是第三个token包含了太多第一个token的信息,如果第一个token是个noisy token的话,那么token3就包含了很多noise。
为了解决这个问题,本文提出了一个mutual attention weight selection module,其要求所选择的token在分类token中的上下文和token本身中都与分类token相似。
将attention map的第一列表示为
b
0
b_0
b0,表示在其他token的上下文中,classification token和other token的注意力得分。
然后与
a
0
a_0
a0做比较,交互注意力权重
m
a
i
ma_i
mai表示为:
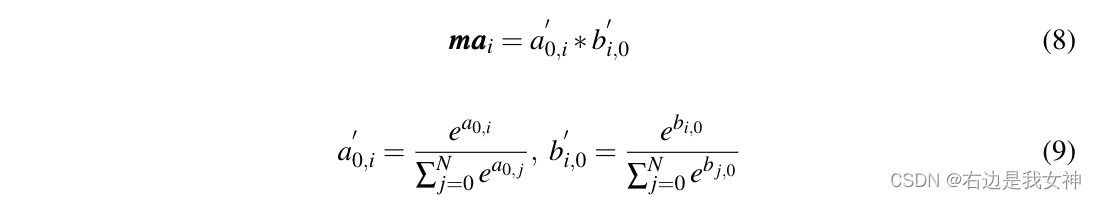
对于多头自注意力,本文对所有头的关注度得分进行平均。
这个指标的意思是说,classification token对token I的关注度和token I对classification token的关注度都要高。
版权归原作者 右边是我女神 所有, 如有侵权,请联系我们删除。