
文章目录
前言
本篇文章记录的是我对AI质量评测的初探索,欢迎专业人员评价指正~
也欢迎对AI系统测评感兴趣的小伙伴一起交流学习~
一、如何测评一个AI系统?
1.什么是AI?
AI全称Artificial Intelligence,人工智能,也就是由人制造出的机器所表现出的智能
举个通俗的例子,比如验证码识别本来是人来做的,现在网上很多眼花缭乱的验证码,就可以利用人工智能识别;还有我们经常使用的语音转文字...这些重复性较强的工作可以交给人工智能来处理
AI目前用于多个领域如新闻、交通、教育、医疗
基于大数据,通过AI给用户个性化地推送新闻,AI还可以用于写稿,剪辑,审核等 - 在教育领域,人工智能可以用于批改作业,授课等项目- 在物流领域,智能分单、智能配送、无人仓等- 在零售领域,无人超市
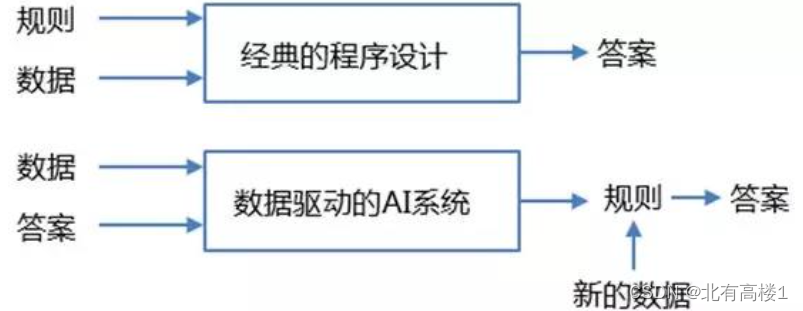
2.AI和传统软件的区别?
(1)传统软件是 [基于规则] 的,我们输入的是 规则 和 需要处理的数据,系统输出的是答案,我们可以对比实际值和预期值来验证程序的正确性
(2)而AI系统是数据驱动的,不是通过编写明确的逻辑,而是通过数据来训练程序
输入的是数据和预期答案,系统输出的是规则,这些规则可以应用于新的数据和场景,自动计算出答案
可见,AI系统是 [从特定的大量数据] 中提取规律,归纳出某些 [规则和知识] ,然后将它们应用到现实场景中解决实际问题
人工智能总结出来的知识并不是像传统软件一样,可以直观精确的表达出来。它更像人类学习到的知识一样,比较抽象,很难表达
3.AI系统向我们提出了哪些新挑战?
每个智能系统都包含了AI模型,比如对话大模型、ASR语音识别模型、OCR文字识别模型...
要支持AI模型对外提供服务,需要很多传统组件,例如数据库、web容器、交互界面等,所以我们常规的测试方法和技术仍然适用;但除此之外,AI系统具有一些特殊性,所以它还需要一些特定的测试方法
总的来说,测试AI系统需要:传统的测试方法+特定测试方法
<1>首先第一个挑战:测试彻底变成了黑盒
- 传统非智能系统的测试过程中,每一个测试用例都有明确的测试预期
- 但是对于智能系统,测试用例往往难以给定明确的预期,预期是不确定的;所以这就需要测试人员充分地理解业务,从业务角度去理解智能系统的目标,成为一个"业务专家",否则就很难确定实际结果满足了业务目标
<2>第二个挑战:数据划分困难
传统非智能系统需要的数据 就是我们常说的测试用例的输入数据
而AI系统更重要的一部分是AI算法训练模型所需要的"原始数据"
原始数据被设计为:训练集、验证集、测试集 -训练集:用来训练模型(占比70%-80%) -验证集:验证模型在新数据上的表现如何,用于模型的调优(占比10%-15%) -测试集:通过测试集来做最终的评估(占比10%-15%) 如果数据集的设计有一定偏差,结果可能就会相差甚远,所以,如何选择原始数据、又如何划分数据集,这是一个很重要的问题
<3>第三个挑战:可能性导致了需要重新指定判断标准
很多AI系统的实现是基于概率的,每次返回的预期并不都是完全一致的
例如,规划自动驾驶的路线,由于红绿灯、拥堵情况等影响,每次都会有不同的路线,因此需要多次运行测试,来评价正常的结果概率
4.应该怎么测?
这里讲的是大致的测试思路,具体细节会在后面的实战中提及
- 收集和准备数据
- 划分测试集
- 确定评估指标
- 训练、评估模型
- 分析错误
- 对比竞品/基准测试
5.需要测什么?
算法模型测试
泛化能力测试
测试模型对未知数据的预测能力,即泛化能力。泛化能力越强,模型的预测能力越强 衡量泛化能力的指标有:错误率、准确率、精准率、召回率、F值稳定性/鲁棒性测试
测试算法多次运行的稳定性、以及当输入值发生微小变化时算法的输出变化 如果算法在输入值发生微小变化时产生巨大的输出变化,就可以说这个算法是不稳定的公平性测试
检查模型是否存在偏见,确保对所有用户群体公平无歧视
功能测试
- 验证AI系统的功能是否能按预期工作,包括输入输出是否正确、功能逻辑是否符合产品设计
- 模拟用户交互,测试AI功能在各种用户行为下的响应
用户体验测试
- 用户界面测试:确保AI交互界面友好、直观,符合用户习惯
- 响应时间测试:测试AI反馈的速度,确保用户等待的时间是合理的
- 语音识别测试:对于语音类产品,测试它的识别精度是否恰当
性能测试
- 负载测试:评估在高并发情况下,AI系统的稳定性和响应时间
- 压力测试:测试AI系统的极限性能,确定它的崩溃阈值
- 资源消耗测试:监控CPU、内存等资源的使用情况,优化性能
安全性测试
- 数据保护:保护用户数据的安全,测试加密机制、访问控制
- 安全漏洞扫描:查找并修复可能的安全漏洞,防止数据泄露或恶意攻击
- 隐私合规性:确保产品遵守GDPR/CCPA等隐私法规
兼容性测试
- 平台兼容性:测试AI产品在不同的操作系统、浏览器、设备上的表现
- 网络兼容性:验证产品在不同的网络环境下(弱网、断网)的表现
二、实战
1.介绍
我们的测试产品是词典笔
有查词翻译、全科答疑、随身听、单词本、背单词、写作指导、AI语法分析、AI口语教练、语音助手等丰富功能
其中包括很多AI技术:ASR自动语音识别、OCR文字识别、OpenCV图像识别、对话大模型
在此我只介绍关于 [ASR自动语音识别] 的测评流程
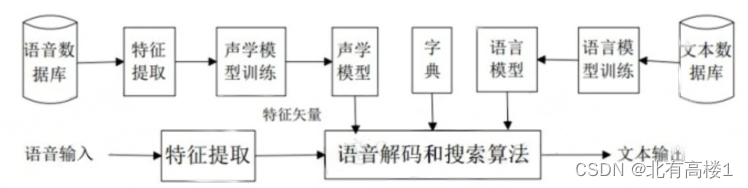
2.ASR大致原理
- 特征提取:从输入的语音信号中提取特征,常用的特征包括梅尔频率倒谱系数(MFCC)和梅尔频率倒谱图(Mel Spectrogram)等
- 声学模型训练:使用声学模型来对提取出的语音特征进行建模,常用的声学模型包括隐马尔可夫模型(HMM)和深度神经网络(DNN)等
- 语言模型:利用语言模型来对识别出的文本进行建模,可以是基于统计的n-gram模型,也可以是基于神经网络的模型
- 解码:将声学模型和语言模型结合起来,使用解码算法(如维特比算法)来找出概率最大、最有可能的输出文本,实现从语音到文本的转换
- 后处理:对识别出的文本进行后处理,包括校正拼写、纠正语法等,来提高识别结果的质量
附:语音识别流程的举例(只是形象表述,不是真实数据和过程)
- 语音信号:我是机器人
- 特征提取:我是机器人
- 声学模型:w o s i j i q i r n
- 字典:窝:w o;我:w o; 是:s i; 机:j i; 器:q i; 人:r n;级:j i;忍:r n;
- 语言模型(给出概率):我:0.0786, 是: 0.0546,我是:0.0898,机器:0.0967,机器人:0.6785;
- 输出文字:我是机器人
3.测试流程
1.准备数据
我们先是收集了语音数据集,包括不同说话人、不同语速、不同环境条件下的语音样本
2.确定评估指标
然后我们制定的评测指标是这样的:
(1)识别准确率:
-文本准备
英语:大写转小写,去除标点,以词为单位
汉语、日语、韩语:去除标点和空格,以字为单位
准确率 = 所有文本的总操作数/参考文本的单词数量和
(2)标点:
需要打分的标点符号包括:句号、分号、感叹号、省略号、逗号、问号、冒号
标点位置正确、并且标点准确——2分
标点位置正确、但是标点错误——1分
标点位置错误—— -1分
分数 = 识别到的标点得分/标准标点得分
(3)逆转文本标准化ITN(Inverse Text Normalization):
量词、普通数字、日期时间(年份)等非词信息的数字表达
举例:
长串数字:电话号码、数字金额、证件号码 度量单位:3kg、45米、2分钟等
年份:2002年12月25日
定型表达:5G手机、G20峰会、7911事件等
应该转为数字的做了转换、不应转为数字的保持中文/英文—正确+1
应该转为数字的未做转换、不应转为数字的转了数字—错误-1
识别失败导致未做ITN转换—其他0
3.划分测试集
我们项目中采取了两种划分方法:
(1)说话人划分:根据说话人的身份将语音数据集划分成训练集70%、验证集15%、测试集15%,验证模型对于 新说话人的泛化能力
(2)话题划分:根据语音数据集中的话题将语音数据集划分成训练集75%、验证集10%、测试集15%,评估模型在 不同话题下的性能
4.训练、评估模型
计算评估指标来衡量模型的准确性,分析模型在不同语音样本上的表现,了解它的强项和弱点
我们最终得出的测试结论如下:
一、质量测试
结论: 整体情况较好,基本能够划分句子的大致断句情况;但在细节的标点使用上,仍有待改进
(1)中文
a.以音频为单位,50个音频中,badcase数量为26个;但每个音频中标点识别问题的数量并不多,1~2个
b.模型输出所有音频的断句数量为960个
-标点错标问题占比最高,为1.56%(表述不完整的情况下错误断句占比最高,46.67%);
-其次是标点少标问题,占比1.25%(缺少语气停顿占比最高,41.67%)
(2)英文
a.以音频为单位,50个音频中,badcase数量为22个;但每个音频中标点识别问题的数量并不多,1~2个
b.模型输出所有音频的断句数量为1096个
-标点多标问题占比最高,为1.50%(固定表达出现多余标点占比最高,87.5%);
-其次是标点标错问题,占比1.22%(短语被当做完整句子占比最高,61.54%)
(3)维语的识别词准率为93.50%
(4)藏语的识别词准率为96.70%
(5)日文的识别词准率为80%
(5)韩文的识别词准率为87.99%
二、性能测试
(1)中文
服务并发1,10,20,30,40,50,60,70,80,90,100路,依次压测15分钟, 服务极限QPS为43.59,平均延时1343.01ms
(2)英文
服务并发1,10,20,30,40,50,60,70,80,90,100路,依次压测15分钟, 服务极限QPS为43.22,平均延时1284.14ms
(3)维语
服务并发1,10,20,30,40路,依次压测15分钟,服务极限QPS为4,平均延时2538.75ms (4)藏语
服务并发1,10,20,30,40路,依次压测15分钟,服务极限QPS为10,平均延时863.17ms (5)日文
服务并发1,10,20,30,40,50,60,70,80,90,100路,依次压测15分钟, 服务极限QPS为14,平均延时600ms
(6)韩文
服务并发1,10,20,30,40,50,60,70,80,90,100路,依次压测15分钟, 服务极限QPS为90,平均延时677ms
三、稳定性测试(使用Grafana监控面板)
结论:程序运行比较稳定,没有程序崩溃,没有出现内存突变
(1)中文
服务并发60路,依次压测12h,服务内存稳定,保持在26.7GB左右
(2)英文
服务并发60路,依次压测12h,服务内存稳定,保持在23.5GB左右
(3)维语
服务并发10路,依次压测12h,服务内存稳定
(4)藏语
服务并发10路,依次压测12h,服务内存稳定
5.分析错误
分析模型产生错误的原因:语音质量、噪声干扰、说话人变化等
我们的分析是:
中文:在哼唱场景、有一定噪音环境下,识别问题最严重
英文:在发音相似、说话断续的场景下错误占比最高
日文:停顿时间过长、发音不清晰、多人同时说话、语速较快时错误占比最高
之后我们还会将训练好的模型与其他现有的ASR模型对比,进行基准测试
总结
标签:
人工智能
本文转载自: https://blog.csdn.net/Ersin555/article/details/139150960
版权归原作者 北有高楼1 所有, 如有侵权,请联系我们删除。
版权归原作者 北有高楼1 所有, 如有侵权,请联系我们删除。