
目录
1 绪论 1
1.1选题背景 1
1.1.1课题的国内外的研究现状 1
1.1.2课题研究的必要性 2
1.2课题研究的内容 2
2 开发软件平台介绍 4
2.1 软件开发平台 4
2.2 开发语言 6
3 网络爬虫总体方案 8
3.1 系统组成 8
3.2 工作原理 8
4模块化设计 9
4.1 Tkinter图形界面模块 9
4.1.1图形模块的略解 9
4.1.2图形模块与其他模块的交互 9
4.2 爬虫模块 13
4.2.1 requests库的说明及选择 13
4.2.2 bs4的说明及使用 15
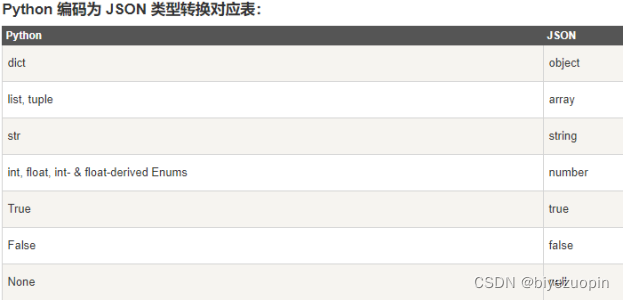
4.2.3 json的说明及使用 17
4.2.4 爬虫整体的流程解析 19
4.3 数据分析模块 21
4.4 请求头及代理池模块 24
4.4.1 24
5实验结论与发展前景 25
5.1低层实现代码 25
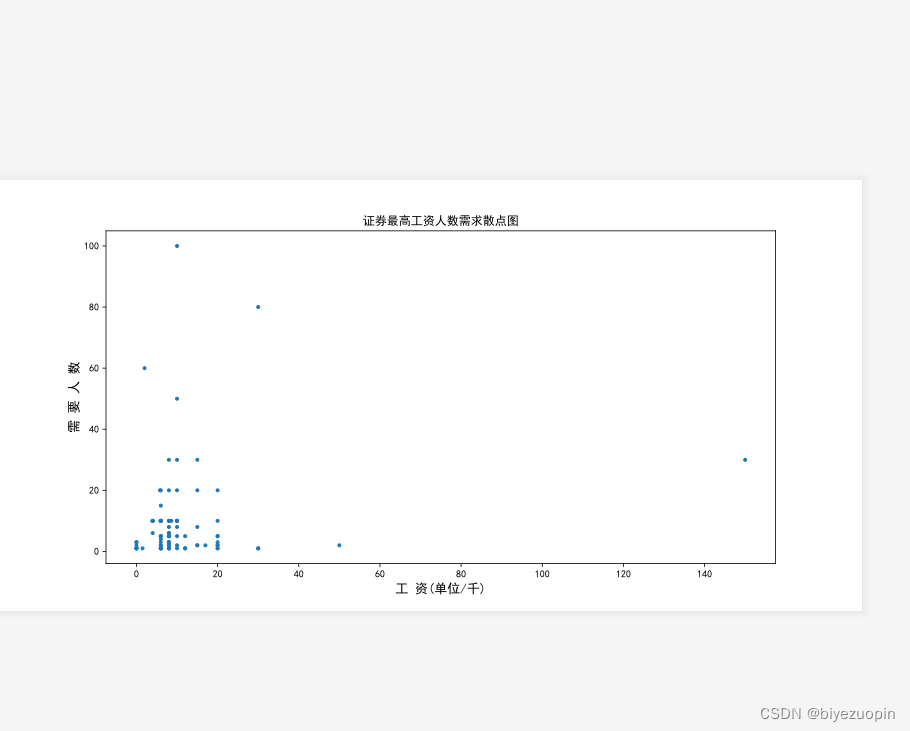
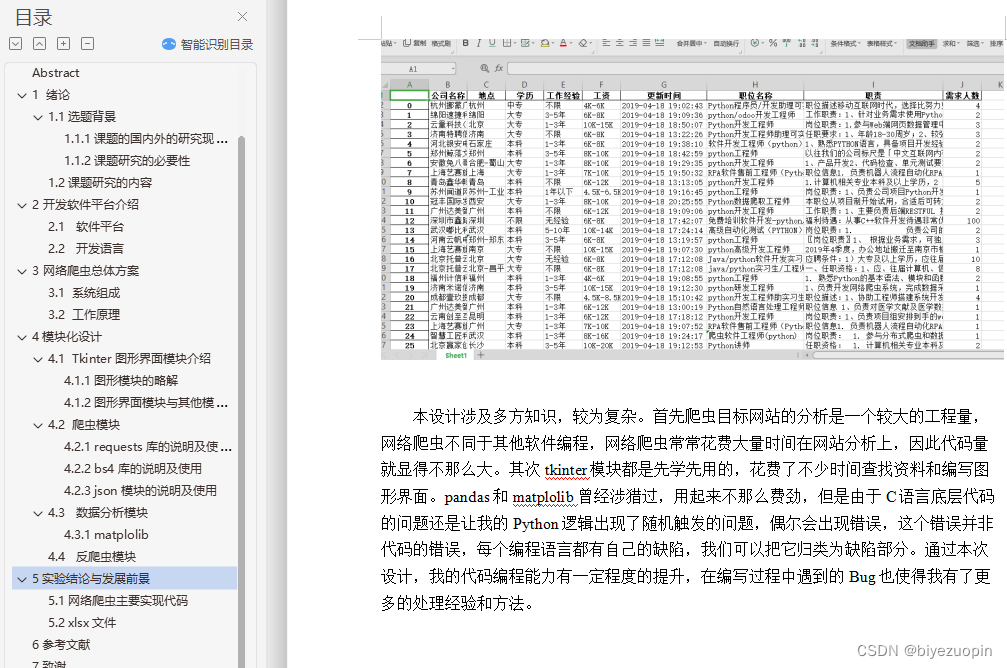
5.2 数据分析结果图 26
5.3 xlsx文件 26
6参考文献 29
7致谢 30
3 网络爬虫总体方案
3.1 系统组成
主要由四个.py文件构成:crawl_views.py、crawl_ZL.py、data_views.py、Against_Reptilia_solve.py,分别负责图像界面、网络爬虫、数据分析、反爬虫模块。
图1.4 简易网络爬虫及数据分析的流程图
3.2 工作原理
在爬虫界面预设目标网站的相关url,在输入不同信息时,进行不同的url拼接得到完整的相关地址进而获取相应信息,对获取的信息进行解析,从解析后的数据中获取需要的数据创建并存入对应的xlsx表格中。数据获取完毕后,用API从xlsx读取关键信息,在用API生成可视化图像(API(Application Programming Interface,应用程序编程接口)是一些预先定义的函数,目的是提供应用程序与开发人员基于某软件或硬件得以访问一组例程的能力,而又无需访问源码,或理解内部工作机制的细节[3]。)。
4模块化设计
4.1 Tkinter图形界面模块介绍
Tkinter是Python的事实上的标准GUI(图形用户界面)包。 它是Tcl / Tk顶部的薄面向对象层。Tkinter不是Python唯一的工具包。 然而,它是最常用的一种。CameronLaird将保留TkInteri的年度决定称为“Python世界的次要传统之一”。
4.1.1图形模块的略解
要创建一个图形界面,我们需要首先定义窗口:
import tkinter as tk
window = tk.Tk()
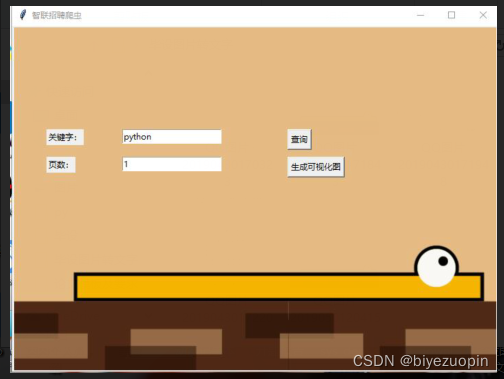
window.title(‘智联招聘爬虫’)
window.geometry(‘700X500’)
通过以上代码,完成对图形界面窗口的名称命名和大小设置。
窗口创建完毕后,进行填充,首先添加背景:
canvans = tk.Canvas(window,height=500,width=700)
image = canvans.create_image(0,0,anchor=‘nw’,image=tk.PhotoImage(flie=‘爬虫_gif.gif’)
canvans.pack()
以上代码完成窗口背景设置,分别对背景图像大小和位置进行的设置,被使用的图像名称为’爬虫_gif.gif’。
为窗口添加文本框,设置文本框的名称和位置:
tk.Label(window,text=“关键字:”).place(x=50,y=150)
var_kwords = tk.StringVar()
为文本框设置默认值
var_kwords.set(‘python’)
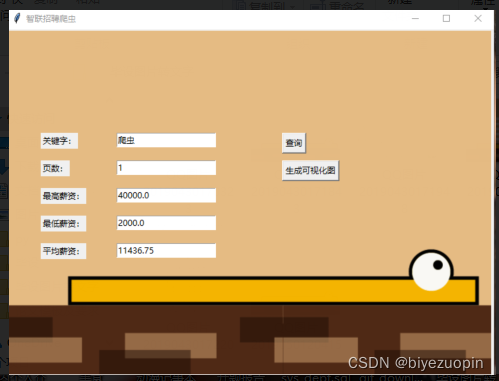
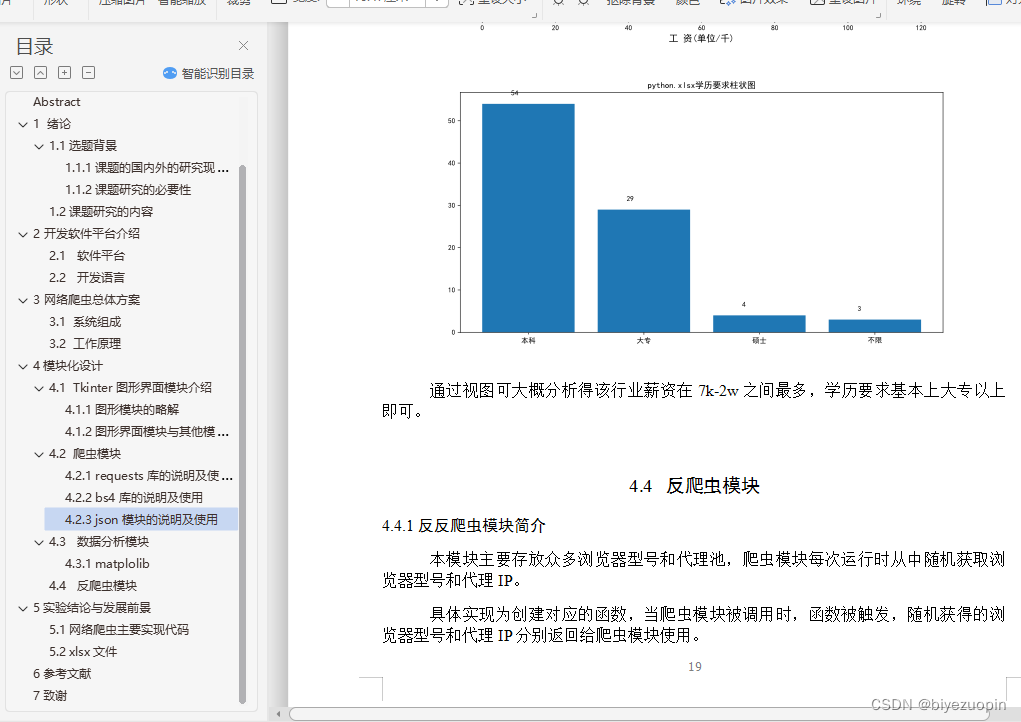
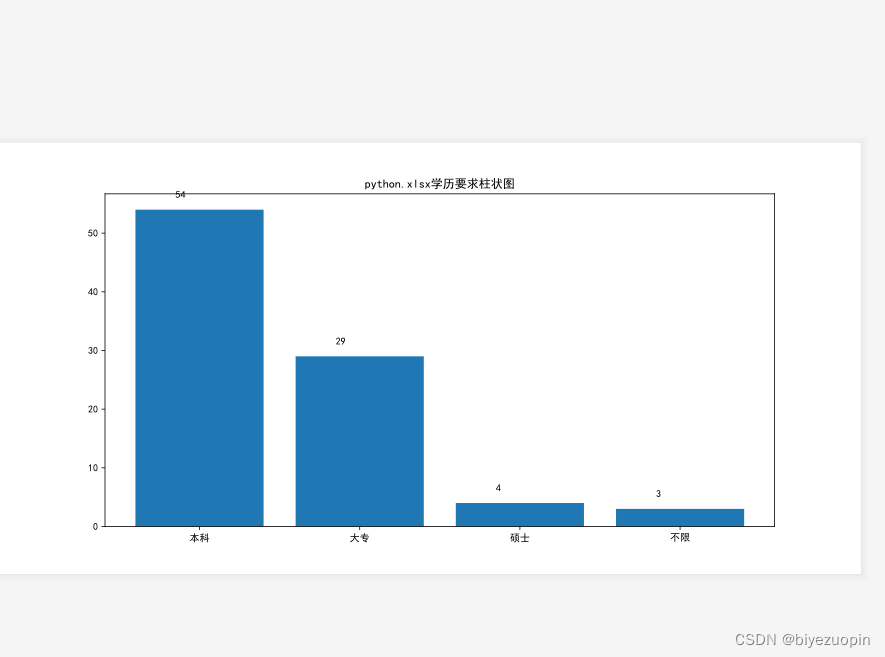
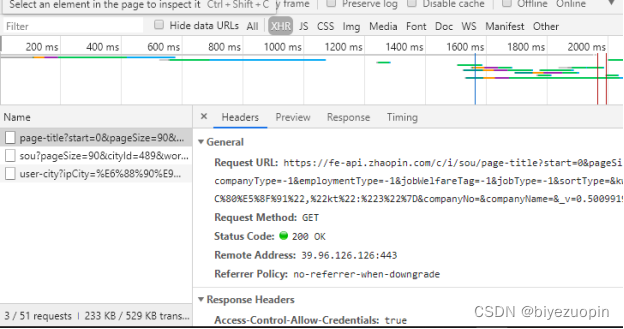
本文中运行网络爬虫后会返回显示对应查询目标行业的薪资的平均值、最大值和最小值,通过文本框的默认值显示。http://www.biyezuopin.vip/onews.asp?id=12427
import tkinter as tk
from tkinter import *
import crawl_ZL
import data_views
class TK_Scrapy(object):
def __init__(self):
pass
#将str中的'K'字符去除,将str转换为float
def data_finally(self,Scrapy_start):
str_salary_list = [] # 接收纯数字的字符串列表['10','15',...]
str_toInt_list = [] # 将字符串转换为浮点型数值
avg_count = 0 # 计数器,用于统计个数,注意结果再除2,智联薪资为区间
salary_count = 0 # 统计薪资总和
for str_salist in Scrapy_start:
# 去除字符'K'(大写)
str_empty = str_salist.split('K') # ['10',''],['15','']
# 取出列表中的非空字符
for delete_empty in str_empty:
if delete_empty != '':
str_salary_list.append(delete_empty)
# 字符串转为浮点型
for str_toInt in str_salary_list:
toInt = float(str_toInt)
# print(type(toInt), toInt)
str_toInt_list.append(toInt)
# print(type(str_toInt_list), str_toInt_list)
max_salary = max(str_toInt_list) * 1000
min_salary = min(str_toInt_list) * 1000
# 获取平均值
for now_salary in str_toInt_list:
salary_count += now_salary
avg_count += 1
avg_salary = (salary_count / avg_count) * 1000
# 保留2为小数
avg_salary_round = round(avg_salary, 2)
finally_salary = [max_salary, min_salary,avg_salary_round]
return finally_salary
#主函数,生成图形界面
def TK_mian(self):
#定义画布名称及大小
window = tk.Tk()
window.title('智联招聘爬虫')
window.geometry('700x500')
#定义画布背景信息
canvans = tk.Canvas(window,height=500,width=700)
image_file = tk.PhotoImage(file='爬虫_gif.gif')
image = canvans.create_image(0,0,anchor='nw',image=image_file)
canvans.pack()
#文本框设置
tk.Label(window,text="关键字:").place(x=50,y=150)
tk.Label(window,text='页数:').place(x=50,y=190)
#设置默认值
var_kwords = tk.StringVar()
var_kwords.set('python')
var_pumber = tk.StringVar()
var_pumber.set('1')
#设置输入框
entry_kwords = tk.Entry(window,textvariable=var_kwords)
entry_kwords.place(x=160,y=150)
entry_pnumber = tk.Entry(window,textvariable=var_pumber)
entry_pnumber.place(x=160,y=190)
# 与爬虫.py数据交互
def usr_selection():
print('按下开始')
selection_kwords = var_kwords.get()
selection_pnumber = var_pumber.get()
#检查输入框文本内容是否导入成功
selection_list=[selection_kwords,selection_pnumber]
# 调用爬虫.py
print('开始爬虫')
Scrapy_start_1 = crawl_ZL.Spider(selection_list) #启动爬虫.py并返回工资列表
Scrapy_start = Scrapy_start_1.run_1()
print('爬虫结束')
print(type(Scrapy_start),Scrapy_start)
# 设置文本框,默认值为爬虫程序return的结果,并以列表接收return的结果,
# salary_list = ['10000', '4000', '7000']
# #不调用函数做测试
salary_list = self.data_finally(Scrapy_start)
tk.Label(window, text="最高薪资:").place(x=50, y=230)
tk.Label(window, text='最低薪资:').place(x=50, y=270)
tk.Label(window, text='平均薪资:').place(x=50, y=310)
# 定义字符
var_max_salary = tk.StringVar()
var_min_salary = tk.StringVar()
var_avg_salary = tk.StringVar()
# 设置默认值
var_max_salary.set(salary_list[0])
var_min_salary.set(salary_list[1])
var_avg_salary.set(salary_list[2])
# 设置文本框位置
entry_max_salary = tk.Entry(window, textvariable=var_max_salary)
entry_max_salary.place(x=160, y=230)
entry_min_salary = tk.Entry(window, textvariable=var_min_salary)
entry_min_salary.place(x=160, y=270)
entry_avg_salary = tk.Entry(window, textvariable=var_avg_salary)
entry_avg_salary.place(x=160, y=310)
#定义查询按钮的位置以及按下时调用的函数
btn_selection = tk.Button(window, text="查询", command=usr_selection)
btn_selection.place(x=400, y=150)
def views_database():
print('开始生成视图')
xlsx_name = var_kwords.get()
data_views_start = data_views.data_to_view(xlsx_name)
#查询按钮的位置及对应的函数调用
btn_selection = tk.Button(window, text="生成可视化图", command=views_database)
btn_selection.place(x=400, y=190)
window.mainloop()
if __name__ == '__main__':
Tserver = TK_Scrapy()
Tserver.TK_mian()



版权归原作者 biyezuopin 所有, 如有侵权,请联系我们删除。