
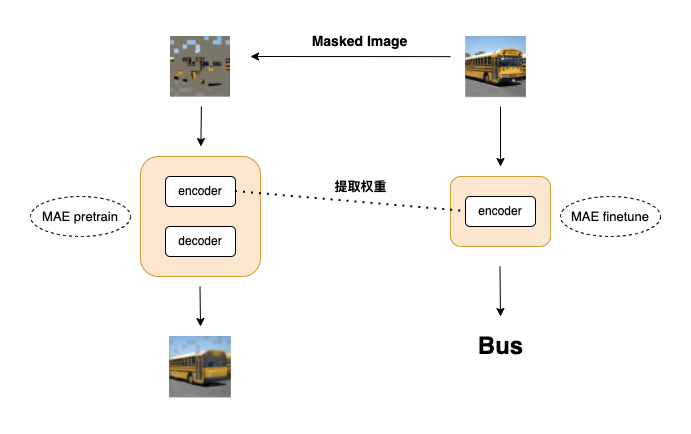
MAE实现及预训练可视化 (CIFAR-Pytorch)
文章目录
灵感来源
监督学习是训练机器学习模型的传统方法,它在训练时每一个观察到的数据都需要有标注好的标签。如果我们有一种训练机器学习模型的方法不需要收集标签,会怎么样?如果我们从收集的相同数据中提取标签呢?这种类型的学习算法被称为自监督学习。这种方法在自然语言处理中工作得很好。一个例子是BERT,谷歌自2019年以来一直在其搜索引擎中使用BERT¹。不幸的是,对于计算机视觉来说,情况并非如此。
Facebook AI的kaiming大神等人提出了一种带掩码自编码器(MAE),它基于(ViT) 架构。他们的方法在ImageNet上的表现要好于从零开始训练的VIT。
自去年 11 月份恺明大神提出 MAE 来,大家都被 MAE 简单的实现、极高的效率和惊艳的性能所吸引。近几个月,大家也纷纷 follow 恺明的工作,在 MAE 进行改进(如将 MAE 用到层次 Transformer 结构)或将 MAE 应用于图片之外的数据(如视频、多模态)。
这是何凯明大佬的又一力作=,CV 圈子基本都晓得,当时火爆了整个圈子,所以今天尝试在cifar数据集上进行搭建。

别人的工作是提升了多少点,kaiming 的工作是 best、best、best
自监督学习
在深度学习模型中,数据通常会通过 Backbone 来提取特征,常见的 Backbone 包括 ResNet、ResNeXt 和 Transformer 等。Backbone 之所有能够提取出对任务有用的特征,是因为它通常已经在带标签的大数据集(如 ImageNet)中已经进行训练。然而,人工进行标注数据是昂贵和费时的,如何在没有标注数据的情况下获得一个 strong 的 Backbone 是一个非常重要的问题。
自监督学习(Self-supervised learning)可以解决这个问题,它的目标是基于无标注的数据,设计辅助任务来将数据本身的某一部分的信息作为监督信号,从而基于这个监督信号来训练模型。基于这些无标签的数据,可以学习到一个模型,这个过程可以称为预训练(pre-train)。
由于这个预训练之后的模型已经具备一定的知识,因此在进行具体的下游任务时,可以将它作为 Backbone 的初始化,进行下游任务的训练,这个过程成为微调(fine-tuning)。由于模型在预训练阶段已经学习到了一定的知识,因此就可以大大减少微调阶段所需的数据集和训练时间。由于预训练阶段的数据是无需标注的,因此也就大大减少的标注数据的成本。
根据自监督训练阶段的辅助任务不同,可以大致将目前的自监督学习工作分为三类:Data Centric, Prediction 和Contrastive(如下所示)。由于本文介绍的 MAE 的辅助任务为预测 Mask 部分的图像内容,因此属于Prediction 这一类别。
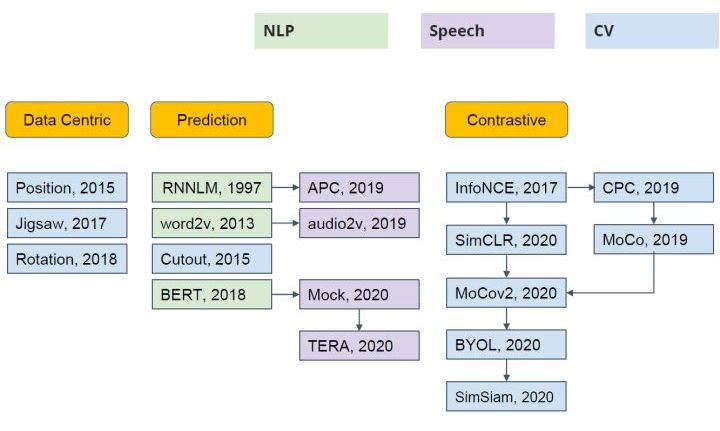
自监督的发展
在详细解读 MAE 之前我们先了解一下视觉自监督发展的背景,在 BEiT 之前视觉自监督一直是对比学习(Contrastive Learning)为主导,如 SimCLR、MoCo v3 等。对比学习说简单点就是让模型学习一种能力,去分辨相同的类型和不同的类型。
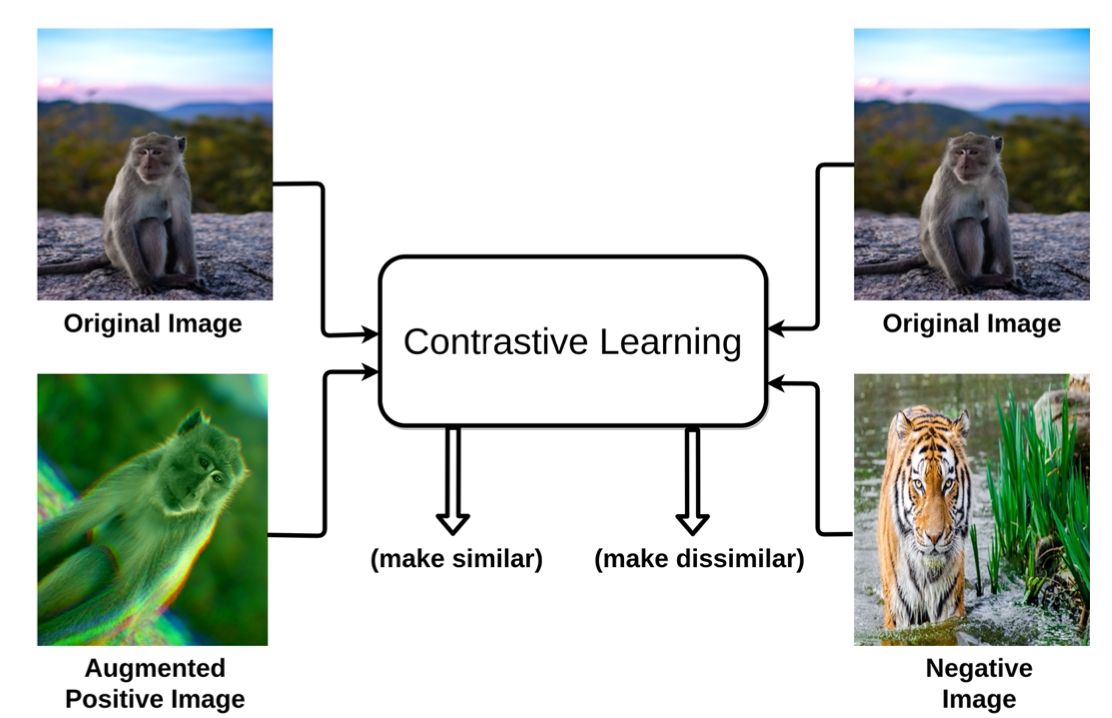
拉近相同图片(Aug),疏远不同图片
如上图所示,我们要让模型去拉近 origin image 和经过 Aug 的图片,同时分开和 origin image 不同的图片,这样通过拉近原图和其 Aug 之后的图片,疏远不同的图片达到了对比学习的效果,这样模型就可以学会自己区分相同类型的图片
尽管对比学习在一些 benchmark 上超过了有监督的方法,但是其局限也很明显,过度依赖 data augmentation(数据扩增),不可避免陷入不变性和一致性的矛盾,但是对比学习确实吊打了之前自监督方法(预测旋转上色拼图等)
kaiming(没错又是他)的 MoCo v3 大概算是后对比学习时代的优秀工作之一了。在这个时期微软提出了 BEiT,通过 Masked Image 的方式来做自监督,以此来复制 NLP 领域 Masked Language 的成功,结果确实很成功,ImageNet1k 下Top-1 acc 达到了惊人的 88.6 %,就这样自监督研究风向开始偏向了生成式自监督
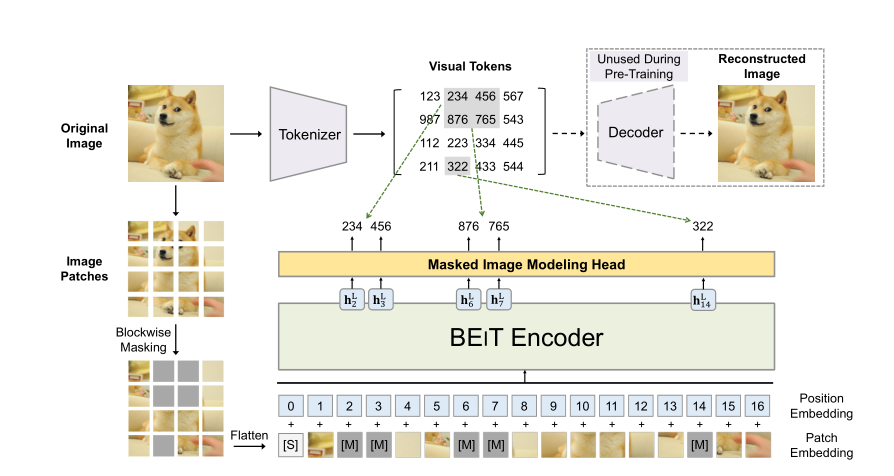
BEiT 是一个生成式自监督范式
基于 BEiT 产生了很多优秀的工作,除了本文的 MAE 之外还有 PeCo、SimMIM、MaskedFeat 等生成式自监督算法,也可以说是因为视觉 Transformer 的发展带动了生成式自监督算法发展。
MAE (Masked Autoencoders)

论文标题:Masked Autoencoders Are Scalable Vision Learners
论文地址:https://arxiv.org/abs/2111.06377
代码地址:https://github.com/facebookresearch/mae
论文动机:

随着 BERT 的出现,Mask Language Modeling(MLM)的自监督学习方法逐渐进入人们的视野,这一方法在 NLP 领域中得到了广泛的应用。受到 MLM 的启发,一些工作也尝试在图像上进行 Mask Modeling(即,mask 图片的部分区域,然后对区域的内容进行重建),并且也取得了不错的效果。但目前的方法通常都采用对称的 encoder 和 decoder 结构,在 encoder 中,mask token 也需要消耗大量的计算,因此作者提出了一个非对称 encoder-decoder 的结构——masked autoencoders(MAE)。
MAE 方法很简单:mask 输入图像的随机 patch,并重建缺失的像素(上图展示了不同 mask 比率的重建结果)。它基于两个核心设计。首先,作者开发了一种非对称编码器-解码器结构,其中的编码器仅对可见的 patch 子集(不带 mask token)进行操作,而轻量级解码器则从潜在表示和 mask token 重建原始图像。
MAE基于两个核心进行设计的
- 第一,首先MAE是一个非对称的编码—解码结构,这种不对称是因为encoder只作用在可见的patches,也就没有mask的patches,同时也还有一个轻量级的解码器来重构原始图像。
- 第二,作者发现,mask比较高的比例,比如说mask75%的patches,这样就会产生一个有意义的自监督任务。这两者结合起来,加速了训练次数,因为原来需要整个图像,当我们mask掉75%的patches以后,我们只剩下了25%的像素,所以训练速度提高了3倍或更多,并且提高了准确性。在论文中,作者利用ImageNet-1K的数据集进行训练,一个普通的v-huge的模型获得了最好的准确率87.8%。在一些目标检测、分类、分割的任务中,效果超过了一些有监督学习预训练的效果,显示了良好的可扩展性。
方法介绍
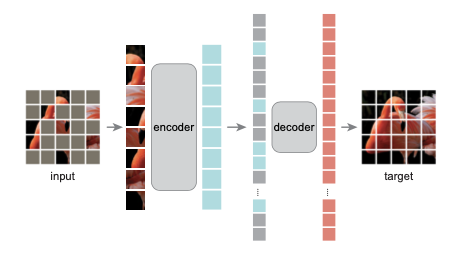
大道至简的 MAE
MAE 的结构如上图所示,与所有自动编码器一样,MAE 有一个编码器,将观察到的信号映射到潜在表示,还有一个解码器,从潜在表示重建原始信号。与经典的自动编码器不同,作者采用了一种非对称设计,允许编码器仅对部分观察信号(无mask token)进行操作,并采用一种轻量级解码器,从潜在表示和 mask token 重建完整信号。
具体来说,作者首先将图像划分为规则的非重叠 patch。然后,对一个子集的 patch 进行采样,并移除其余的 patch。然后将这些剩余的 patch 送入到编码器中,编码器是一个标准的 ViT 结构,由于编码器只处理很少一部分的 patch,因此可以用很少的计算和显存来训练非常大的编码器。编码器输出 token 后,作者在 mask 的位置加入了可学习的向量,组成完整的全套 token。
此外,作者向这个完整集合中的所有 token 添加位置嵌入;如果没有这一点,mask token 将没有关于其在图像中位置的信息。MAE 解码器仅在预训练期间用于执行图像重建任务(仅编码器用于生成用于识别的图像表示)。因此,可以以独立于编码器设计的方式灵活地设计解码器架构。作者用比编码器更窄、更浅的解码器进行实验。使用这种非对称设计,全套 token 仅由轻量级解码器处理,这大大减少了预训练时间。
MAE流程图
其实很简单,从左到右,将图片 patch 化然后 mask 掉一部分,未 mask 的部分进入 encoder,得到的输出再加上之前 mask 的部分一起进入 decoder 复原图像,目标是复原的图像尽可能接近原图,更详细的东西我们搭建模型时候慢慢讲解
为了方便大家理解,我借鉴了一个流程图带大家实现一个简单的 MAE
MAE 流程图
MAE,可以认为这是一个BERT 的一个 CV 的版本,它基于 ViT ,把整个训练 拓展到没有标号的数据上面,通过完型填空来获取图片的一个理解,它不是第一个将 BERT 拓展到 CV 上,但MAE 很有可能 未来影响最大,BERT 加速了 Transformer 架构 在 NLP 的应用,MAE 加速 Transformer 在 CV 上的应用。
原论文在 ImageNet1k 下使用了 8 机 8 卡跑实验,在21k用了两个集群的TPU,这里我们采用 Cifar10 来作为 MAE 的数据集,这样我们仅需单卡 V100-32g 就可以实现一个简单的 MAE。
搭建 MAE 模型
首先是搭建模型,如上图所示我们先搭建 pretrain 和 finetune 模型,分别是
- MAE finetune model
- MAE pretrain model
🎯 FAQ:pretrain 和 finetune 都是在干啥?
答:pretrain 用来让模型学习 “复原能力”,即把原图 mask 掉一部分,让模型去学习复原它,在学习复原过程中模型学到了数据内在的表示。finetune 则是将 pretrain 之后的encoder 权重提取出来,利用学习好的权重在 down stream 做微调
🎯 FAQ:encoder 和 decoder 有什么区别?
答:在 pretrain 阶段,encoder 主要用来学习数据内在表征,decoder 主要用来复原图像。encoder 模型大一些,decoder 模型小一些。它们都是 ViT 的架构
MAE 组网
因为 encoder 和 decoder 都是 ViT 的架构,需要先搭建 ViT 需要的模块,如果想详细了解ViT的话,可以看我另一篇博客。Pytorch CIFAR10图像分类 Vision Transformer(ViT) 篇
首先我们可以充分利用当前timm中的各个模型架构,不过我们也可以自己进行定义,我这里不进行讲解。给出部分代码
from timm.models.vision_transformer import Block
MAE 预训练(pretrain)
Encoder
记住最重要的一点,Encoder 仅处理可见(unmasked)的 patches。Encoder 本身可以是 ViT 或 ResNet(其它 backbone 也 ok,不过paper中是ViT,我们也用ViT),至于如何将图像划分成 patch 嘛,使用 ViT 时的套路是这样的:
先将图像从 (B,C,H,W) reshape 成 (B, N, PxPxC),其中 N 和 P 分别为 patch 数量 和 patch 大小 (
N
=
H
P
×
W
P
N = \frac{H}{P} \times \frac{W}{P}
N=PH×PW ),也就是**将3通道的图像转换成 N 个 维度大小为 PxPxC 的向量**;然后,**通过线性映射(linear projection,可以是全连接层)将其嵌入(embed)到指定的维度空间大小**,记为 ‘dim’(从 PxPxC project 到 dim),转换成为 **token**(B,N,dim);最后再**加上位置嵌入(position embedding)**,从而为各个 patch 添加位置信息。**位置嵌入是所有图像共享的、可学习的**,shape 与 每张图的 token 相对应,即:(N,dim)。
由于 unmasked 的 patches 所有 patches 的少数,因此可以训练很大的 Encoder,因为计算和空间要求都减少了。
接着我们就可以构建我们的MAE Encoder了
classMAE_Encoder(torch.nn.Module):def__init__(self,
image_size=32,
patch_size=2,
emb_dim=192,
num_layer=12,
num_head=3,
mask_ratio=0.75,)->None:super().__init__()
self.cls_token = torch.nn.Parameter(torch.zeros(1,1, emb_dim))
self.pos_embedding = torch.nn.Parameter(torch.zeros((image_size // patch_size)**2,1, emb_dim))# 对patch进行shuffle 和 mask
self.shuffle = PatchShuffle(mask_ratio)# 这里得到一个 (3, dim, patch, patch)
self.patchify = torch.nn.Conv2d(3, emb_dim, patch_size, patch_size)
self.transformer = torch.nn.Sequential(*[Block(emb_dim, num_head)for _ inrange(num_layer)])# ViT的laynorm
self.layer_norm = torch.nn.LayerNorm(emb_dim)
self.init_weight()# 初始化类别编码和向量编码definit_weight(self):
trunc_normal_(self.cls_token, std=.02)
trunc_normal_(self.pos_embedding, std=.02)defforward(self, img):
patches = self.patchify(img)
patches = rearrange(patches,'b c h w -> (h w) b c')
patches = patches + self.pos_embedding
patches, forward_indexes, backward_indexes = self.shuffle(patches)
patches = torch.cat([self.cls_token.expand(-1, patches.shape[1],-1), patches], dim=0)
patches = rearrange(patches,'t b c -> b t c')
features = self.layer_norm(self.transformer(patches))
features = rearrange(features,'b t c -> t b c')return features, backward_indexes
Decoder
Decoder它不仅需要处理经过 Encoder 编码的 unmasked 的 tokens,还需要处理mask tokens。但请注意,mask token 并非由之前 mask 掉的 patch 经过 embedding 转换而来,而是可学习的、所有 masked patch 都共享的1个向量,对,仅仅就是1个!
那么你会问:这样如何区分各个 maked patch 所对应的 token 呢?
别忘了,我们还有 position embedding 嘛!如同在 Encoder 中的套路一样,这里对于 mask token 也需要加入位置信息。position emebdding 是每个 masked patch 对应1个,shape 是 (N’,dim),其中 N’ 是 masked patch 的数量。但 mask token 只有1个怎么办是不是?简单粗暴——“复制”多份即可,使得每个 masked patch 都对应1个 mask token,这样就可以和 position embedding 进行相加了。
另外,Decoder 仅仅是在预训练任务为了重建图像而存在,而我们的下游任务形式多样,因此实际应用时很可能没 Decoder 什么事了(和它 say byebye 咯~)。
所以,Decoder 的设计和 Encoder 是解耦的,Decoder 可以设计得简单、轻量一些(比 Encoder 更窄、更浅。窄:对应通道数;浅:对应深度),毕竟真正能学习到潜在特征表示的是 Encoder。
这样,尽管 Decoder 要处理的 token 数很多(全量token,而 Encoder 仅处理 unmasked 的部分),但其本身轻量,所以还是能够高效计算。再结合 Encoder 虽然本身结构重载(相对 Decoder 来说),但其处理的 token 较少,这样,整体架构就十分 efficient 了,漂亮~!
class MAE_Decoder(torch.nn.Module):
def __init__(self,
image_size=32,
patch_size=2,
emb_dim=192,
num_layer=4,
num_head=3,
) -> None:
super().__init__()
self.mask_token = torch.nn.Parameter(torch.zeros(1, 1, emb_dim))
self.pos_embedding = torch.nn.Parameter(torch.zeros((image_size // patch_size) ** 2 + 1, 1, emb_dim))
self.transformer = torch.nn.Sequential(*[Block(emb_dim, num_head) for _ in range(num_layer)])
self.head = torch.nn.Linear(emb_dim, 3 * patch_size ** 2)
self.patch2img = Rearrange('(h w) b (c p1 p2) -> b c (h p1) (w p2)', p1=patch_size, p2=patch_size, h=image_size//patch_size)
self.init_weight()
def init_weight(self):
trunc_normal_(self.mask_token, std=.02)
trunc_normal_(self.pos_embedding, std=.02)
def forward(self, features, backward_indexes):
T = features.shape[0]
backward_indexes = torch.cat([torch.zeros(1, backward_indexes.shape[1]).to(backward_indexes), backward_indexes + 1], dim=0)
features = torch.cat([features, self.mask_token.expand(backward_indexes.shape[0] - features.shape[0], features.shape[1], -1)], dim=0)
features = take_indexes(features, backward_indexes)
features = features + self.pos_embedding # 加上了位置编码的信息
features = rearrange(features, 't b c -> b t c')
features = self.transformer(features)
features = rearrange(features, 'b t c -> t b c')
features = features[1:] # remove global feature 去掉全局信息,得到图像信息
patches = self.head(features) # 用head得到patchs
mask = torch.zeros_like(patches)
mask[T:] = 1 # mask其他的像素全部设为 1
mask = take_indexes(mask, backward_indexes[1:] - 1)
img = self.patch2img(patches) # 得到 重构之后的 img
mask = self.patch2img(mask)
return img, mask
总结
最后可以总结这整一个流程,然后构建模型
- 将图像划分成 patches:(B,C,H,W)->(B,N,PxPxC);
- 对各个 patch 进行 embedding(实质是通过全连接层),生成 token,并加入位置信息(position embeddings):(B,N,PxPxC)->(B,N,dim);
- 根据预设的掩码比例(paper 中提倡的是 75%),使用服从均匀分布的随机采样策略采样一部分 token 送给 Encoder,另一部分“扔掉”(mask 掉);
- 将 Encoder 编码后的 token 与 加入位置信息后的 mask token 按照原先在 patch 形态时对应的次序拼在一起,然后喂给 Decoder 玩(如果 Encoder 编码后的 token 的维度与 Decoder 要求的输入维度不一致,则需要先经过 linear projection 将维度映射到符合 Decoder 的要求);
- Decoder 解码后取出 mask tokens 对应的部分送入到全连接层,对 masked patches 的像素值进行预测,最后将预测结果与 masked patches 进行比较,计算 MSE loss
classMAE_ViT(torch.nn.Module):def__init__(self,
image_size=32,
patch_size=2,
emb_dim=192,
encoder_layer=12,
encoder_head=3,
decoder_layer=4,
decoder_head=3,
mask_ratio=0.75,)->None:super().__init__()
self.encoder = MAE_Encoder(image_size, patch_size, emb_dim, encoder_layer, encoder_head, mask_ratio)
self.decoder = MAE_Decoder(image_size, patch_size, emb_dim, decoder_layer, decoder_head)defforward(self, img):
features, backward_indexes = self.encoder(img)
predicted_img, mask = self.decoder(features, backward_indexes)return predicted_img, mask
测试MAE
最后测试一下,是否代码正确
shuffle = PatchShuffle(0.75)
a = torch.rand(16,2,10)
b, forward_indexes, backward_indexes = shuffle(a)print(b.shape)
img = torch.rand(2,3,32,32)
encoder = MAE_Encoder()
decoder = MAE_Decoder()
features, backward_indexes = encoder(img)print(forward_indexes.shape)
predicted_img, mask = decoder(features, backward_indexes)print(predicted_img.shape)
loss = torch.mean((predicted_img - img)**2* mask /0.75)
torch.Size([4,2,10])
torch.Size([16,2])
torch.Size([2,3,32,32])
MAE 微调(finetune)
MAE finetune 模型和 ViT 模型是一样的,不同之处是后续处理部分,ViT 是提取 cls token 做分类,MAE finetune 模型则是将 patches token(除了 cls token 之外) 做 mean 然后分类
所以很简单,我就定义了一个分类器,其实就是接受encoder的输出,接着输入分类器即可,并且,我们已经设置了我们的类别,因为cifar10的类别是十个。
classViT_Classifier(torch.nn.Module):def__init__(self, encoder : MAE_Encoder, num_classes=10)->None:super().__init__()
self.cls_token = encoder.cls_token
self.pos_embedding = encoder.pos_embedding
self.patchify = encoder.patchify
self.transformer = encoder.transformer
self.layer_norm = encoder.layer_norm
self.head = torch.nn.Linear(self.pos_embedding.shape[-1], num_classes)defforward(self, img):
patches = self.patchify(img)
patches = rearrange(patches,'b c h w -> (h w) b c')
patches = patches + self.pos_embedding
patches = torch.cat([self.cls_token.expand(-1, patches.shape[1],-1), patches], dim=0)
patches = rearrange(patches,'t b c -> b t c')
features = self.layer_norm(self.transformer(patches))
features = rearrange(features,'b t c -> t b c')
logits = self.head(features[0])return logits
MAE 预训练
接着我们就可以开始准备Cifar10 数据集
现在我们用搭建好的模型来试一下 Cifar10 数据集把
在我们训练的过程中,我们的目的是重构图片,在这之后进行学习,我利用了tensorboard可视化,我们可以看一看结果
在我们的epoch为225时,我们可以看到,模型已经能够基本构建一个轮廓信息了,但是可能还是不够好

接着我们看到达到2000次的时候,模型已经能够较好的重构出图像,说明学习到了很多信息了

我们可以看到,经过 pretrain 之后的 mae 可以大致复原出原图像轮廓,令人吃惊的是这仅仅只用了原图像的 25% 像素,正如 mae 论文所说的,“与 language 不同,image 具有很高的冗余性”
如果你问论文为什么选mask ratio 0.75?
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-uD5jSBt4-1663202645416)(https://ai-studio-static-online.cdn.bcebos.com/3f49ce2f0a7b4154ba94318513fa2c79fd5bdd8d9556438a9e9ebb612b6f32ca)]
ratio=0.75 性能更好,不论是训练整个模型的 fine-truning ,还是冻结权重只微调最后分类头的 linear probing,mask ratio 0.75 都取得了良好的性能
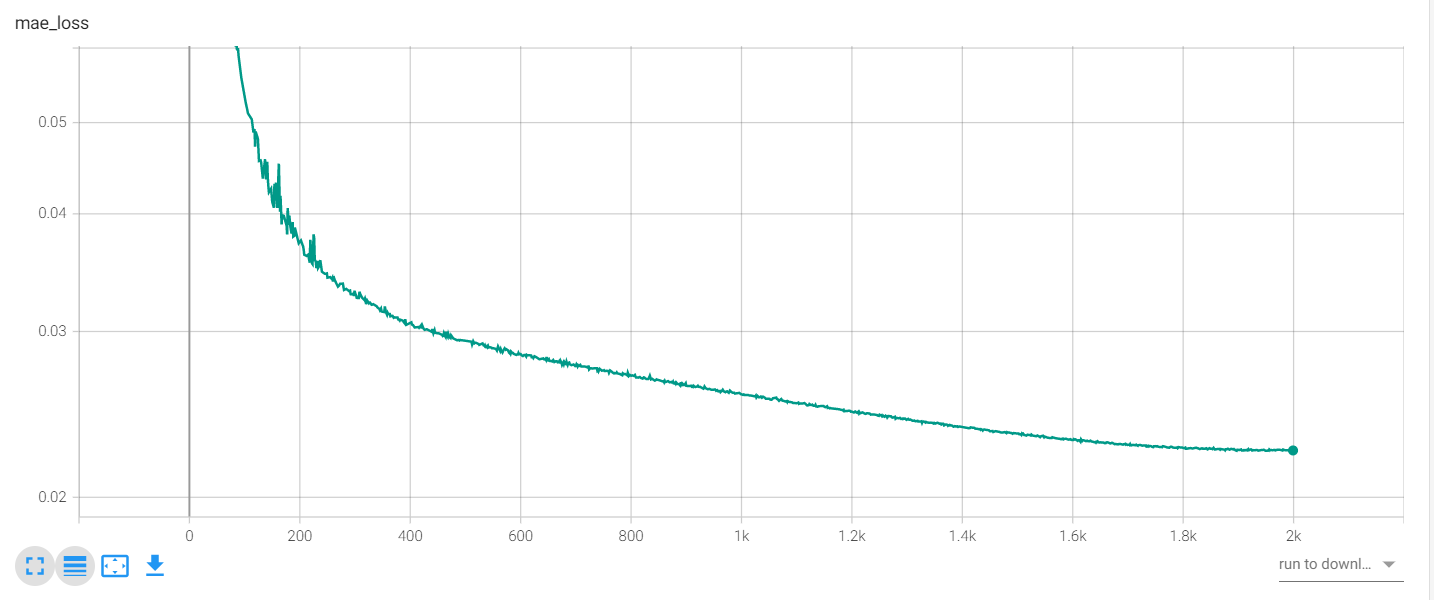
除此之外,我一共迭代了2000次,也有损失曲线,也就是我们重构损失。下面是损失函数曲线,越到后面,我们会发现,模型基本收敛了,下降的不多了。(提一下,训练了2天,也可以减少预训练的次数,也能达到不错的结果)。
MAE 微调
MAE 微调有两种,一个是对整个模型进行 finetune,加载的权重参与更新,一个是 linear prob,加载的权重不参与更新,只更新最后的分类头部分
首先进行了自监督的预训练,这时候是不需要标记的,然后会将encoder用在ViT的图像分类中,做一些下游的任务,也就是利用训练好的encoder作为特征提取的部分,去掉编码器,在ViT中进行分类
这里我们用 cifar10 分类做 finetune 微调,训练 epoch 为100,我们可以自己进行调参以获得更好的性能,也可以尝试 linear prob。
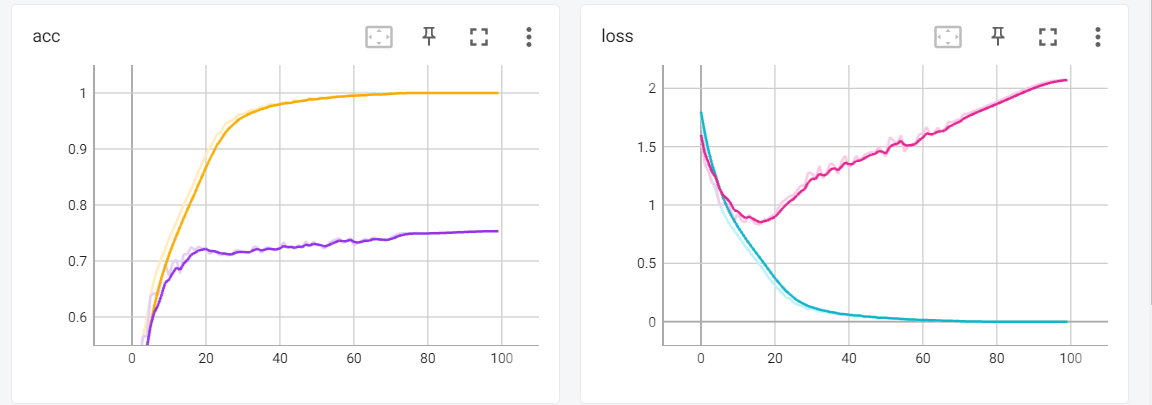
为了比较MAE分类的性能,用一样的训练数据,这里我们做了两个训练
- 第一个是将分类器进行单独训练,也就是从0开始训练
- 第二个就是将MAE对图片进行处理,不更新他的权重,将其的encoder的输出作为输入,进行训练。
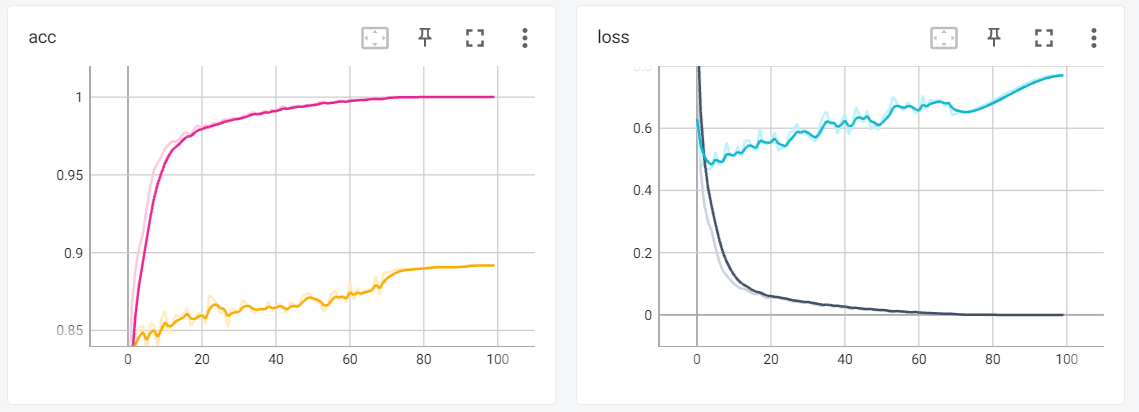
- 我们可以一起比较一下,我们会发现,首先MAE的架构会更快的收敛,并且最后的准确率也是远远大于我们从0开始训练的,除此之外,他还使得模型有更好的泛化性,在迭代次数加深的时候,模型的损失不会一直上升,有很好的泛化性。
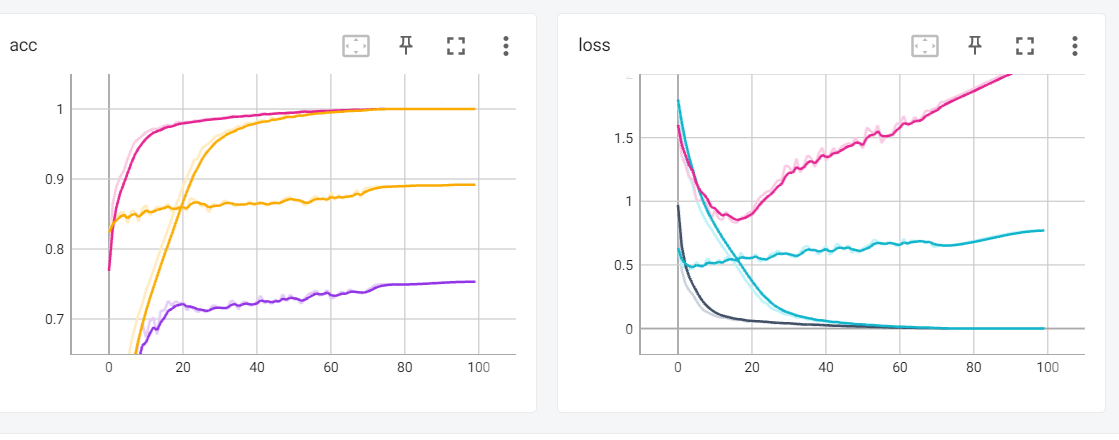
Result 结果
最后我们可以看到结果,确实MAE得到了很不错的结果,是一个非常好的思路,同时得到很好的结果。
ModelValidation AccViT-T pretrain (scratch 从0开始训练)74.13ViT-T pretrain89.77
总结
本项目简单实现了MAE 在 cifar10 数据集上的训练,MAE 表现了令人惊讶的重建能力,进一步说明图像相比语言具有更冗余的信息,作者认为像素信息具有连续性。
其实仔细研究一下模型,会发现 mae 在降低计算量上面是很优雅的,encoder 部分计算的 token 数是经过 masked 的 token,即原来的四分之一(mask ratio 0.75),这大大降低了计算复杂度,同时用于重建的 decoder 模型深度很浅,尽管进入 decoder 的 token 数几乎是原 token 数,但是其带来的计算复杂度在可接受的范围,是非常成功的模型。
感谢和体会
这次实验也让我看到了一个新的方向,从有监督学习到自监督学习的转变,也有可能之后会还往无监督学习中进行发展。也看到了一个从原始的CNN,到利用Transformer来得到更好的结果,但是可能不好的是,虽然说Transformer的精度比较高,不过有时候需要很大很大的数据集,并且速度可能一般,如果Transformer在保持精度的情况下能够达到的试试的效果可能会统治整个CV界,不过已经看到了Transformer的各种在计算机视觉中的各种应用了,还是非常好的。
除此之外,在后面的论文中,基于MAE重构像素,展开了很多的自监督学习的展开,比如MAE出现的一个月后,北大Chen Wei发现,重构图像的HOG,也就是方向梯度直方图比重构像素能得到更好的结果,并且因此在众多下游任务中,得到了12个SOTA,称为MaskFeat,简而言之,MaskFeat的ViT-B在ImageNet 1K上的准确率达到了84.0%,MViT-L在Kinetics-400上的准确率达到了86.7%,成功地超越了MAE,BEiT和SimMIM等方法。

有人评价说,视觉自监督领域做了这么些年,从最早的生成式学习出发,绕了一圈,又回到生成式学习。到头来,我们发现像素级特征跟各种手工特征、tokenizer、甚至离线预训练网络得到的特征,在作为判断生成图像质量方面,没有本质区别。也就是说,自监督也许只是把模型和参数调得更适合下游任务,但在「新知识从哪里来」这个问题上,并没有任何实质进展。这也可能是这样的,不过具体可能得不断的调节,比如说,如何在CNN设计Mask,虽然说何凯明也在论文中说,CNN是很难进行mask的,因为卷积是一个滑动窗口,CNN 在一张图片上,使用一个卷积窗口、不断地平滑,来汇聚一些像素上面的信息 + 模式识别,而卷积窗口扫过来、扫过去时,无法区分边界,无法保持 mask 的特殊性,无法拎出来 mask,最后从掩码信息很难还原出来。不过自监督学习能得到这样好的效果,说明这是一种趋势,如果考虑如何从一个更前沿的方法来得到更好的结果,可能就是之后的目标,融合多种特征,结合多个tricks。
在这次实验,我尝试着往比较前沿的方法去学习和发展,而没有拘泥于下游任务的图像分类、目标检测、图像分割等,在这里面也学到了更多东西,知道了一些没想过的,我觉得这也是符合人的,在我们没认识到一些东西的时候,我们是被mask的,当我们或者一些信息的时候,我们也会进行一些重构,得到一些东西,我们要做的就是需要,让我们的自监督学习学习学的更好。
版权归原作者 风信子的猫Redamancy 所有, 如有侵权,请联系我们删除。