
目录
0. FPS记录的原理
参考自:睿智的目标检测21——如何调用摄像头进行目标检测
FPS简单来理解就是图像的
刷新频率
,也就是
每秒多少帧
假设目标检测网络处理1帧要0.02s,此时FPS就是50
#---------------------------分割线-------------------------------- #
也就是说在计算FPS的时候,会强调
每秒
、
每张
。因此,在众多博客中计算FPS时,都会注意以下两点:
- 实现要求
每张:将batch-size设置为1 - 实现要求
每秒:用1000去除以3个时间之和(1s=1000ms,调用yolov5中的val.py后会计算并打印出pre-process图像预处理、inference推理、NMS非极大值抑制处理这3个ms级时间)

1. 自己的
在yolov5的
val.py
文件中添加了如下两行代码,即可实现打印:
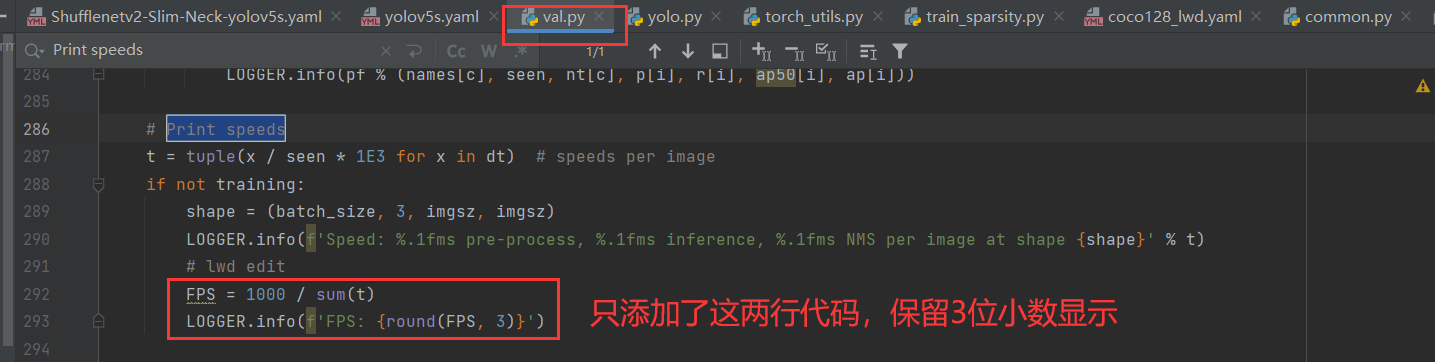
实现步骤:
- 在
val.py中按住快捷键Ctrl+F搜索Print speeds定位过去 - 在上图中的合适位置添加如下代码:
FPS =1000/sum(t)
LOGGER.info(f'FPS: {round(FPS,3)}')
- 调整好合适参数,直接运行
val.py即可(但是要注意一下,batch-size要设置为1)
2. 其实yolov5有自带的打印这些参数
参考链接:查看yolov5/lite各层参数量和各层FLOPs
实现方法:(主要是直接调用的yolov5中已经写好的代码
utils/torch_utils.py
中的
profile
等函数)
- 在终端运行
yolo.py时,带上参数--profile,这样可以打印整体的参数量、浮点数运算等 - 在终端运行
yolo.py时,带上参数--line-profile,这样可以打印出每层的参数量、浮点数等(这第2种方法,在yolov5-master下载下来的val.py中可实现,如果单独下载的yolov5-v6.1中没有这个--line-profile参数)
3. 清风大佬分享的
3.1 单个的计算fps函数
defcompute_speed(model, input_size, device, iteration=100):
torch.cuda.set_device(device)
cudnn.benchmark =True
model.eval()
model = model.cuda()input= torch.randn(*input_size, device=device)for _ inrange(50):
model(input)print('=========Eval Forward Time=========')
torch.cuda.synchronize()
t_start = time.time()for _ inrange(iteration):
model(input)
torch.cuda.synchronize()
elapsed_time = time.time()- t_start
speed_time = elapsed_time / iteration *1000
fps = iteration / elapsed_time
print('Elapsed Time: [%.2f s / %d iter]'%(elapsed_time, iteration))print('Speed Time: %.2f ms / iter FPS: %.2f'%(speed_time, fps))return speed_time, fps
3.2 整体的完整代码
defcompute_speed(model, input_size, device, iteration=100):
torch.cuda.set_device(device)
cudnn.benchmark =True
model.eval()
model = model.cuda()input= torch.randn(*input_size, device=device)for _ inrange(50):
model(input)print('=========Eval Forward Time=========')
torch.cuda.synchronize()
t_start = time.time()for _ inrange(iteration):
model(input)
torch.cuda.synchronize()
elapsed_time = time.time()- t_start
speed_time = elapsed_time / iteration *1000
fps = iteration / elapsed_time
print('Elapsed Time: [%.2f s / %d iter]'%(elapsed_time, iteration))print('Speed Time: %.2f ms / iter FPS: %.2f'%(speed_time, fps))return speed_time, fps
if __name__ =='__main__':
parser = ArgumentParser()
parser.add_argument("--size",type=str, default="256,256",help="input size of model")
parser.add_argument('--num-channels',type=int, default=3)
parser.add_argument('--batch-size',type=int, default=8)
parser.add_argument('--classes',type=int, default=2)
parser.add_argument('--iter',type=int, default=501)
parser.add_argument('--model',type=str, default='deeplabv3plus_mobilenet')
parser.add_argument("--gpus",type=str, default="0",help="gpu ids (default: 0)")
args = parser.parse_args()
h, w =map(int, args.size.split(','))
model = build_model(args.model, num_classes=args.classes)
compute_speed(model,(args.batch_size, args.num_channels, h, w),int(args.gpus), iteration=args.iter)
4. 记录运行B导yolov7-tiny后计算fps的方法
B导的yolov7-tiny代码地址:yolov7-tiny-pytorch
兴许他的
yolox
的fps也可以这样来计算呢,地址为:yolox-pytorch
顺利跑起来的步骤:
- 在根目录下的
summary.py中加入上面3.清风大佬分享的代码,整体如下:
# --------------------------------------------## 该部分代码用于看网络结构# --------------------------------------------#import torch
from thop import clever_format, profile
from torch.backends import cudnn
import time
from nets.yolo import YoloBody
defcompute_speed(model, input_size, device, iteration=1000):# 这个iteration的作用是预热cpu
torch.cuda.set_device(device)
cudnn.benchmark =True
model.eval()
model = model.cuda()input= torch.randn(*input_size, device=device)for _ inrange(50):
model(input)print('=========Eval Forward Time=========')
torch.cuda.synchronize()
t_start = time.time()for _ inrange(iteration):
model(input)
torch.cuda.synchronize()
elapsed_time = time.time()- t_start
speed_time = elapsed_time / iteration *1000
fps = iteration / elapsed_time
print('Elapsed Time: [%.2f s / %d iter]'%(elapsed_time, iteration))print('Speed Time: %.2f ms / iter FPS: %.2f'%(speed_time, fps))return speed_time, fps
if __name__ =="__main__":
input_shape =[640,640]
anchors_mask =[[6,7,8],[3,4,5],[0,1,2]]
num_classes =4
device = torch.device("cuda"if torch.cuda.is_available()else"cpu")
m = YoloBody(anchors_mask, num_classes,False).to(device)for i in m.children():print(i)print('==============================')
dummy_input = torch.randn(1,3, input_shape[0], input_shape[1]).to(device)
flops, params = profile(m.to(device),(dummy_input,), verbose=False)# --------------------------------------------------------## flops * 2是因为profile没有将卷积作为两个operations# 有些论文将卷积算乘法、加法两个operations。此时乘2# 有些论文只考虑乘法的运算次数,忽略加法。此时不乘2# 本代码选择乘2,参考YOLOX。# --------------------------------------------------------#
flops = flops *2
flops, params = clever_format([flops, params],"%.3f")print('Total GFLOPS: %s'%(flops))print('Total params: %s'%(params))# -------------------------计算fps------------------------ #
model = YoloBody(anchors_mask, num_classes,False)
speed_time, fps = compute_speed(m,(1,3,640,640), device=0)print(speed_time)print(fps)
- 然后就报错咯,如下图
问题应该是出在最后那一句报错:
AttributeError: 'LeakyReLU' object has no attribute 'total_ ops'

针对2.报的错,清风大佬让我试试【把LeaKy这个激活函数去了】。于是我的操作就是:在
nets\backbone.py文件中的15行加入一句代码act = False。如下图:
有个疑问,
compute_speed函数中的iteration是什么作用,为什么默认为100?
然后清风大佬就给我解释了:
iteration是用于预热cpu的iteration的值不固定,对结果的影响很小
下图对比了我训练完之后,用
iteration=100
和
iteration=1000
的fps结果: lwd
lwd
本文转载自: https://blog.csdn.net/LWD19981223/article/details/127042070
版权归原作者 孟孟单单 所有, 如有侵权,请联系我们删除。
版权归原作者 孟孟单单 所有, 如有侵权,请联系我们删除。