
Flink的体系架构基本上可以分为三层,由上往下依次是API & Libraries层、Runtime核心层以及物理部署层。
API & Libraries层作为分布式数据处理框架,Flink同时提供了支撑流计算和批计算的接口,并在此基础之上抽象出不同的应用类型的组件库,如基于流处理的CEP(复杂事件处理库)、SQL&Table库和基于批处理的FlinkML(机器学习库)等、Gelly(图处理库)等。
另外,Flink整个系统主要由两个组件组成,分别为JobManager和TaskManager。Flink架构也遵循Master-Slave架构设计原则,其中JobManager为Master节点,TaskManager为Worker(Slave)节点。
总的来说,Flink的体系架构非常灵活和可扩展,能够适应不同的数据处理需求和应用场景。
01 Flink简介
•
Flink是什么?
•
实时数据分析一直是个热门话题,需要实时数据分析的场景也越来越多,如金融支付中的风控、基础运维中的监控告警、实时大盘之外,AI模型也需要消费更为实时的聚合结果来达到很好的预测效果。
•
Apache Flink是下一代开源大数据处理引擎。它是一个分布式大数据处理引擎,可对有限数据流和无限数据流进行有状态计算。可部署在各种集群环境,对各种大小的数据规模进行快速计算。
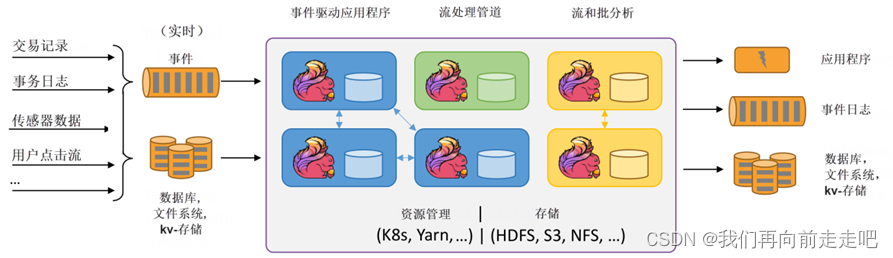
•Flink特性
•Apache Flink 为用户提供了更强大的计算能力和更易用的编程接口:
•(1) 批流统一。Flink在Runtime和SQL层批流统一,提供高吞吐低延时计算能力和更强大的SQL支持。
•(2) 生态兼容。Flink能与Hadoop Yarn / Apache Mesos / Kubernetes集成,并且支持单机模式运行。
•(3) 性能卓越。Flink提供了性能卓越的批处理与流处理支持。
•(4) 规模计算。Flink的作业可被分解成上千个任务,分布在集群中并发执行。
•Flink已经被证明可以扩展到数千个内核和TB级的应用程序状态,提供高吞吐量和低延迟,并支持世界上一些要求最高的流处理应用程序
02Flink应用场景
•
Fl
版权归原作者 我们再向前走走吧 所有, 如有侵权,请联系我们删除。