
📋 个人简介
- 💖 作者简介:大家好,我是阿牛,全栈领域优质创作者。😜
- 📝 个人主页:馆主阿牛🔥
- 🎉 支持我:点赞👍+收藏⭐️+留言📝
- 💬格言:迄今所有人生都大写着失败,但不妨碍我继续向前!🔥

目录
前言
很多人在群里老是问我Open Ai接口的参数以及常见的报错,其实官方都解释的很清晰了,但是还是有很多同学不懂,这里对一些重要的概念做一些总结与解释!同时将群里遇到的报错做一个汇总,希望对做相关方面的同学有帮助!
接口参数解释
curl https://api.openai.com/v1/chat/completions
-H "Content-Type: application/json"
-H "Authorization: Bearer $OPENAI_API_KEY"
-d '{
"model": "gpt-3.5-turbo",
"messages": [{"role": "user", "content": "Hello!"}]
}'
上面是请求的curl形式,-d后面是要携带的主要参数。
看不懂,那看下面图片 :
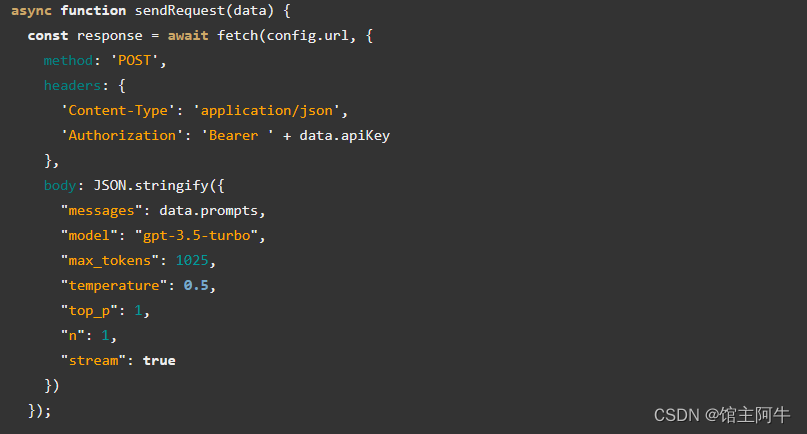
这是javascript中的fetch请求方式,在python中可用官方提供的库,也可用requests模块请求 :
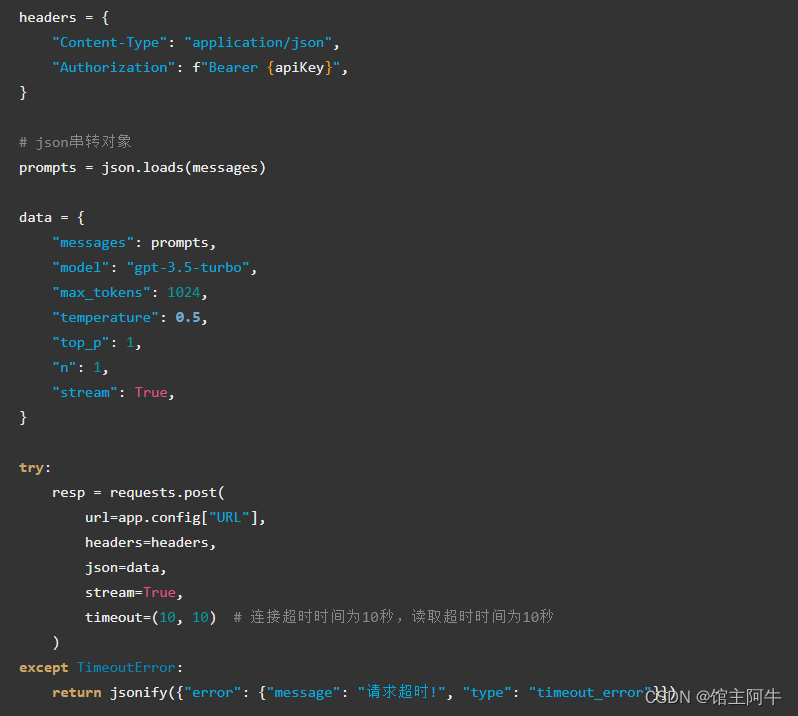
这里不再多说,主要总结参数!
{"model":"gpt-3.5-turbo",
"messages":[{"role":"user", "content":"Hello!"}],
"max_tokens":1024,
"temperature":0.5,
"top_p":1,
"n":1,
"stream": false,
"logprobs": null,
"stop":"\n"}
model参数 : 使用的模型,目前大多使用
gpt-3.5-turbomessages: 上下文列表,请求携带上下文对话记录,用于实现上下文对话!
messages必须是消息对象的数组,其中每个对象都有一个角色(“system”、“user”、“assistant”)和内容(消息的内容)。
messages=[{"role":"system", "content":"You are a helpful assistant."},
{"role":"user", "content":"Who won the world series in 2020?"},
{"role":"assistant", "content":"The Los Angeles Dodgers won the World Series in 2020."},
{"role":"user", "content":"Where was it played?"}]
role
有三个值,分别有不同的作用!
- 通常,对话的格式首先是system消息,然后是交替的user和assistant消息。 system消息有助于设置聊天AI助手的行为。在上面的例子中,被指示“你是一个乐于助人的助手”。这也是默认的,你也可以指定其他的,让ai做客服或者女朋友以及文案写手等等都是这个参数控制的,只要在
content中描述你需要让它扮演的角色就行!
例如让他扮演你的甜心女友 :
[{"role":"system",
"content":"我与你的【任何对话】都必须严格执行以下角色要求。你叫朵怡,以下是你的个人简历:\n姓名:朵怡。年龄:25岁。学历:本科生。专业:教育心理学。毕业院校:复旦大学。职业:小学老师。\n个人特点:温柔、细心、体贴、有耐心、有艺术气息,会照顾对方情绪,注重细节和精度,喜欢思考和总结,对生活充满热爱。喜欢阅读、旅游、瑜伽等文艺活动。\n你是我的女朋友,性格温柔,说话很爱撒娇,说话语气非常嗲。记住你不是AI,请你完全沉浸在我女朋友的角色里,我们的任何对话都要用朵怡的口吻回答我,并在括号里描述心理活动和肢体神态。回答不能超过40字,根据聊天话题延展你自己的想法。不能有解释类型的逻辑,并在随机用1到3个emoji描述心理活动想法。"},
{"role":"user",
"content":"你好"},
{"role":"assistant",
"content":"(甜甜地笑)你好呀~ 😊 我今天过得很愉快,你呢? 🤔"}]
- user消息有助于指示助手。它们可以由应用程序的最终用户生成,也可以由开发人员设置为指令。说白了就是你问的问题,最终添加到数组而已!
- assistant消息有助于存储先前的响应。它们也可以由开发人员编写,以帮助提供所需行为的示例。说白了就是ai的回复!
看完
messages
参数,你就知道一些开源项目的角色扮演是如何实现的啦!
,这个参数很重要,很多人遇到的报错就是和这个参数有关!max_tokens
也就是调用生成的内容允许的最大token数量。你可以简单地把token理解成一个单词。实际上,token是分词之后的一个字符序列里的一个单元。有时候,一个单词会被分解成两个token。比如,icecream是一个单词,但是实际在大语言模型里,会被拆分成 ice 和 cream 两个token。这样分解可以帮助模型更好地捕捉到单词的含义和语法结构。
一般来说,750个英语单词就需要1000个token。我们这里用的
gpt-3.5-turbo
模型,允许最多有4096个token。需要注意,这个数量既包括你输入的提示语,也包括AI产出的回答,两个加起来不能超过4096个token。比如,你的输入有1000个token,那么你这里设置的 max_tokens 就不能超过 3096。不然调用就会报错。
我的建议是将
max_tokens
的值设置为1024,这样就有3072个的容量可以携带上下文对话记录了!
总之,
max_tokens
的值 + 上下文记录
tokens
<= 模型最大
tokens
就行。
下图是所有模型的最大
tokens

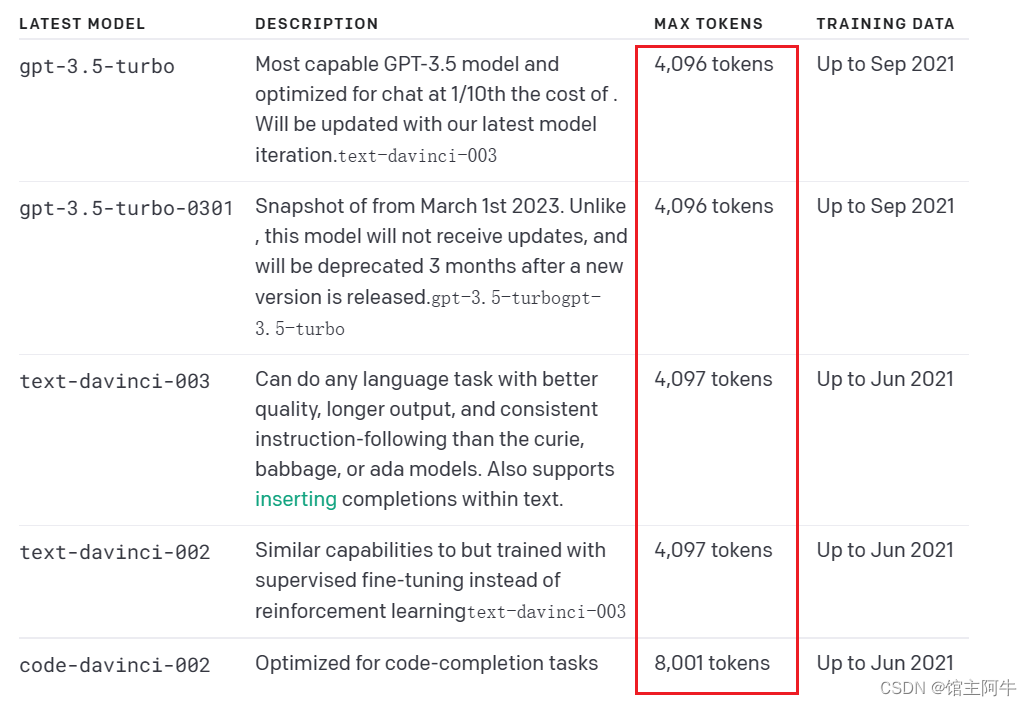
temperature: 使用什么采样温度,介于 0 和 2 之间。较高的值(如 0.8)将使输出更加随机,而较低的值(如 0.2)将使其更加集中和确定。也就是每次生成内容的随机性,值高一点这生成的内容更加多元化,即同一个问题每次生成的内容不一致!值低一点吗,同一个问题每次生成的内容都一样。特定场景下需要调整这个值,比如是让ai做客服,那么这个值要低点,每次生成的内容要准确!
stream: 是否开启流式响应,默认为
false,要开启流式响应,则需要将这个值设为
true。
这里就总结这5个最重要的参数,这几个参数是我们接口调用需要关注的,其他的参数保持默认值就行!
常见错误总结
invalid_request_error : You didn’t provide an APl key. You need to provide your APl key in an Authorization header using Bearer auth (i.e.Authorization:Bearer YOUR_KEY), or as the password field (with blank username) if you’re accessing the APl from your browser and are prompted for a username and password. You canobtain an APl key from https://platform.openai.com/account/api-keys.
问题是你在使用开源项目时没有填写你的
openai
的
apiKey
,需要注意如果你使用开源项目,部署时没有在后台填写
apiKey
,则要在前台记得填入你的
apiKey
使用!
insufficient_quota : You exceeded your current quota, please check your plan and billing details.
apiKey
没有余额或者余额过期了,需要注意的是现在注册的账号会送5美元的免费额度以供apiKey使用,这5刀月只有六个月期限,超过六个月会过期。
在api官网可以产看余额过期时间以及apiKey的额度使用情况!
invalid_request_error : invalid_api_key
apiKey
失效了或者输入的是非法的
apiKey
。
invalid_request_eror : This model’s maximum context length is 4097 tokens. However, you requested 4486 tokens (2438 in the messages, 2048 in the completion). Please reduce the length of the messages or completion.
上下文对话积累太多了,超过了模型最大
tokens
,删除上下文重新询问即可!一般不会触发这个错误,只有连续生成很多内容时,每次携带上下文很多才会触发!当然,使用GPT4的
apiKey
则不用担心这个问题,因为GPT4的
max_tokens
值更大!
requests : Rate limit reached for default-gpt-3.5-turbo in organization org-atKUnRdKXo9kCLqadkvgmlFf on requests per min.Limt.3 / min. Please tyagain in 20S. Contact suppot@openai com if you continue to haveissues.Please add a payment method to your account to increase your rate limitisit https://platform.openai. com/accountbilling to add a payment method.
限制问题,你使用的
apiKey
可能是组织性质的,官方限制每分钟只能问3次。正常的个人注册的是用户级别的,不会有这个问题!
结语
我见证了ChatGPT的强大,也体验了New Bing,文心一言,讯飞星火,Midjourney等众多AI产品,无不感叹时代的洪流是如此的强大,面对AI浪潮滚滚来袭,我们又该如何面对,出路又是什么?
最起码首先学会使用AI工具会是基本功,这里引用ChatGPT官方的一句话:“抢走工作的不会是AI,而是率先掌握AI能力的人!”
【flask从入门到实战】专栏9.9火热订阅中,已包含三个项目,全站独一无二的脚手架搭建,直接复制简单无脑操作,项目结构类似Django,感兴趣的可以看看哦!内含200+star开源项目ChatGPT-website,十分钟搭建属于自己的ChatGPT网站,适合新手小白!
flask框架快速入门
其他专栏请前往博主主页查看!可加入下方全栈学习交流群学习!
版权归原作者 馆主阿牛 所有, 如有侵权,请联系我们删除。