
一.常见的特征提取器类别
- 卷积神经网络(Convolutional Neural Network,CNN):CNN 是一种常用的特征提取器,它能够对图像、音频等二维或一维数据进行特征提取。
- 循环神经网络(Recurrent Neural Network,RNN):**RNN **是一种能够处理序列数据的特征提取器,它能够对文本、语音等序列数据进行特征提取。
- Transfomer:Transformer是一种用于自然语言处理(NLP)和其他序列到序列(Seq2Seq)任务的深度学习模型。与传统的循环神经网络(RNN)模型不同,Transformer模型使用了注意力机制(Attention Mechanism)来处理输入序列。
- 特征金字塔(Feature Pyramid):特征金字塔是一种用于多尺度特征提取的算法,它能够同时提取不同尺度的特征,并将它们进行融合。
- 预训练模型(Pre-trained Models):预训练模型是指在大规模数据上预训练的深度学习模型,如ImageNet上训练的ResNet、VGG等。可以将这些预训练模型的特征提取部分作为特征提取器来使用,而无需重新训练整个模型。
主要以最热门的ChatGPT自然领域的RNN、CNN、Transfomer为例。
二、RNN在NLP的崛起与衰败
循环神经网络(Recurrent Neural Network,简称RNN)是一种能够处理序列数据的深度学习模型。在RNN中,数据的每个时间步都被视为一个输入,并与之前的时间步产生联系。
RNN的基本单元是循环单元(Recurrent Unit),也称为RNN单元(RNN Cell)。RNN单元接收当前时间步的输入和上一个时间步的隐藏状态(Hidden State),并产生一个新的隐藏状态和当前时间步的输出。隐藏状态可以看作是模型对过去的记忆,可以通过不断地传递到下一个时间步来保留信息。
RNN的反向传播(Backpropagation Through Time,简称BPTT)算法与传统的神经网络类似,可以通过最小化损失函数来更新模型参数。由于RNN的隐藏状态可以传递到后面的时间步,因此BPTT需要在时间维度上展开计算梯度,会导致梯度消失或爆炸的问题。为了缓解这个问题,一些变体模型如长短时记忆网络(LSTM)和门控循环单元(GRU)被提出,能够更好地处理长序列数据。
为什么RNN能够这么快在NLP流行并且占据了主导地位呢?
基于以上RNN的特点,主要原因是因为RNN的结构天然适配解决NLP的问题,NLP的输入往往是个不定长的线性序列句子,而RNN本身结构就是个可以接纳不定长输入的由前向后进行信息线性传导的网络结构,而在LSTM引入三个门后,对于捕获长距离特征也是非常有效的。所以RNN特别适合NLP这种线形序列应用场景,这是RNN为何在NLP界如此流行的根本原因。
为什么RNN在NLP又快速衰败了呢?
成也其特点,败也其特点。RNN本身的序列依赖结构对于大规模并行计算来说相当之不友好。通俗点说,就是RNN很难具备高效的并行计算能力,这个乍一看好像不是太大的问题,其实问题很严重。如果你仅仅满足于通过改RNN发一篇论文,那么这确实不是大问题,但是如果工业界进行技术选型的时候,在有快得多的模型可用的前提下,是不太可能选择那么慢的模型的。
那么为什么RNN的并行计算能力不行呢?问题就出在这里。因为T时刻的计算依赖T-1时刻的隐层计算结果,而T-1时刻的计算依赖T-2时刻的隐层计算结果……..这样就形成了所谓的序列依赖关系。
精简化总结:序列依赖结构天然适配NLP的问题,但计算依赖T-1时刻的隐层计算结果,而T-1时刻的计算依赖T-2时刻的隐层计算结果形成的序列依赖关系,又天然限制了并行计算能力,而想要在序列依赖结构上提高并行计算能力,由此引出了CNN。
三、CNN的一度辉煌
卷积神经网络(Convolutional Neural Network,简称CNN)是一种常用于处理图像和语音数据的深度学习模型。【在视觉领域获得了巨大的成功】
在NLP领域,RNN的序列依赖结构导致的并行计算缺陷的原因,之后有很多论文发表,在探索RNN的新结构,而这种新结构,却逐渐向CNN的结构靠拢,由此引发CNN在NLP领域的应用。
以下是对CNN原理具体解释:
CNN主要由卷积层(Convolutional Layer)、池化层(Pooling Layer)和全连接层(Fully Connected Layer)组成。其中,卷积层和池化层构成了CNN的特征提取部分,全连接层则负责将提取到的特征映射到输出类别上。
卷积层是CNN的核心部分,它使用一组可学习的卷积核(Convolution Kernel)对输入的特征图(Feature Map)进行卷积操作。卷积操作可以提取出特征图中的局部特征,同时保留特征的空间位置信息。卷积操作的输出称为卷积特征图(Convolutional Feature Map)。
在实际应用中,卷积操作通常会应用多个不同大小的卷积核,并且会对卷积特征图进行非线性激活操作,如ReLU。
池化层用于降低特征图的空间大小,减少模型的参数数量,从而避免过拟合。常用的池化操作有最大池化(Max Pooling)和平均池化(Average Pooling)两种。最大池化操作将输入特征图的每个区域内的最大值作为输出,平均池化则将每个区域内的平均值作为输出。
全连接层将卷积和池化操作得到的特征映射到输出类别上。通常将卷积和池化层得到的特征展开成一维向量,然后通过多个全连接层进行分类或回归等任务。
CNN的训练通常采用反向传播算法来更新模型参数。由于CNN模型的层次结构,反向传播的计算可以方便地应用于整个网络,从而提高了模型的训练效率。
卷积过程示例图:
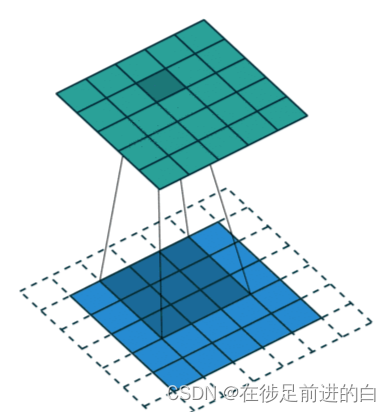
** 二位卷积是最常用的卷积:**
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride, padding=2,
bias=False, dilation=1) # 前两个参数为通道数

函数中参数解释:
卷积核大小(Kernel Size):卷积核大小定义了卷积的视野。2维中的常见选择是3 - 即3x3像素矩阵。
步长(Stride):步长定义遍历图像时卷积核的移动的步长。虽然它的默认值通常为1,但我们可以使用值为2的步长来对类似于MaxPooling的图像进行下采样。
填充(Padding):填充定义如何处理样本的边界。Padding的目的是保持卷积操作的输出尺寸等于输入尺寸,因为如果卷积核大于1,则不加Padding会导致卷积操作的输出尺寸小于输入尺寸。
输入和输出通道(Channels):卷积层通常需要一定数量的输入通道(I),并计算一定数量的输出通道(O)。可以通过I * O * K来计算所需的参数,其中K等于卷积核中参数的数量,即卷积核大小。
【二维卷积是最常用的,还有不同的卷积,后文会有专题总结】
四、Transfomer特征提取的大势所趋
Transformer指的是完整的Encoder-Decoder框架,而我这里是从特征提取器角度来说的,你可以简单理解为论文中的Encoder部分。因为Encoder部分目的比较单纯,就是从原始句子中提取特征,而Decoder部分则功能相对比较多,除了特征提取功能外,还包含语言模型功能,以及用attention机制表达的翻译模型功能。
Transformer有两个版本:Transformer base和Transformer Big。两者结构其实是一样的,主要区别是包含的Transformer Block数量不同,Transformer base包含12个Block叠加,而Transformer Big则扩张一倍,包含24个Block。

能让Transformer效果好的,不仅仅是Self attention,这个Block里所有元素,包括Multi-head self attention,Skip connection,LayerNorm,FF一起在发挥作用。
我们知道Transformer Block其实不是只有一个构件,而是由multi-head attention/skip connection/Layer Norm/Feed forward network等几个构件组成的一个小系统,如果我们把RNN或者CNN塞到Transformer Block里会发生什么事情呢?

五、Transformer模型的详解
【说的比较复杂,文字比较多,大致了解过程即可】
Transformer模型由编码器(Encoder)和解码器(Decoder)两部分组成,其中编码器负责将输入序列转换为一组特征向量,解码器负责将这些特征向量转换为输出序列。编码器和解码器都由多个相同的层(Layer)组成,每个层包含一个多头自注意力(Multi-Head Self-Attention)和一个前向神经网络(Feedforward Neural Network)模块。
在编码器中,输入序列的每个位置都被转换为一个特征向量,并在每个层中被处理。在自注意力模块中,每个位置的特征向量都与其他位置的特征向量进行交互,其中注意力权重由每个位置与所有位置之间的相似度计算得出。这个过程可以看作是对输入序列的一种自我关注(Self-Attention),它能够学习序列中不同位置的重要性。然后,通过前向神经网络模块对每个位置的特征向量进行非线性变换,得到新的特征向量表示。
在解码器中,与编码器类似地,输出序列的每个位置也被转换为一个特征向量,并在每个层中被处理。但与编码器不同的是,解码器还需要通过另一个自注意力模块来关注编码器产生的特征向量,以便在生成每个输出时考虑编码器产生的所有信息。在自注意力模块中,注意力权重由解码器中每个位置的特征向量与编码器中每个位置的特征向量之间的相似度计算得出。然后,通过前向神经网络模块对每个位置的特征向量进行非线性变换,得到新的特征向量表示。
通过交替进行编码器和解码器层的处理,Transformer模型能够学习输入序列和输出序列之间的对应关系,并用于各种序列到序列的NLP任务,如机器翻译、文本摘要、语音识别等。相较于传统的RNN模型,Transformer模型能够处理更长的序列,且能够并行处理,训练速度更快。
六、特征金字塔
图像中存在不同尺寸的目标,而不同的目标具有不同的特征,利用浅层的特征就可以将简单的目标的区分开来;利用深层的特征可以将复杂的目标区分开来。【此特征提取器主要应用于目标检测、图像分割等计算机视觉任务中。】
原理详解:
在传统的目标检测算法中,通常使用固定大小的滑动窗口来对输入图像进行检测。但是,在不同尺度下目标的大小是不同的,如果使用固定大小的滑动窗口,就可能会错过一些目标或检测出一些错误的目标。特征金字塔技术可以解决这个问题,它可以在不同尺度下提取图像特征,从而可以检测不同大小的目标。
特征金字塔的实现方法是对输入图像进行多次下采样,从而得到一系列不同尺度的图像。对于每个尺度的图像,可以使用已训练好的卷积神经网络提取特征,并生成一个特征图。由于下采样后图像的尺寸会变小,因此在每个特征图上检测目标的大小也会相应缩小。为了检测到不同大小的目标,可以使用不同大小的滤波器在不同尺度的特征图上进行滑动窗口操作。
最终,特征金字塔会生成多个尺度的特征图,然后将这些特征图进行融合,得到最终的特征图,并在该特征图上进行目标检测。特征金字塔技术可以有效提高目标检测的准确率和召回率,但也会增加计算复杂度和模型训练的难度。
下面是一个示例代码,用于创建具有 5 个特征级别的 FeaturePyramid 模型:
import torch.nn as nn
class FeaturePyramid(nn.Module):
def __init__(self, in_channels=256, out_channels=256, levels=5):
super(FeaturePyramid, self).__init__()
self.levels = levels
self.convs = nn.ModuleList()
self.upsamples = nn.ModuleList()
# bottom-up pathway
for level in range(self.levels):
self.convs.append(nn.Conv2d(in_channels, out_channels, kernel_size=1))
# lateral connections
for level in range(self.levels - 1):
self.convs.append(nn.Conv2d(in_channels, out_channels, kernel_size=1))
self.upsamples.append(nn.Upsample(scale_factor=2, mode='nearest'))
# top-down pathway
self.top_down = nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1, stride=1)
self.smooth = nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1, stride=1)
def forward(self, inputs):
# bottom-up pathway
features = [self.convs[0](inputs)]
for level in range(1, self.levels):
features.append(self.convs[level](features[-1]))
# top-down pathway
for level in range(self.levels - 2, -1, -1):
lateral = self.convs[self.levels + level](features[level])
upsampled = self.upsamples[level](lateral)
top_down = self.top_down(features[level+1])
features[level] = self.smooth(upsampled + top_down)
# upsample highest level feature map
features[-1] = self.upsamples[-1](features[-1])
return features
在 PyTorch 中,可以使用 nn.ModuleList 来定义一个模块列表,并将所有模块添加到该列表中。可以将模块列表作为构造函数参数传递给 FeaturePyramid 类。对于每个级别的特征图,可以使用 nn.Conv2d 层定义卷积操作。最终的特征图将使用 nn.Conv2d 层和 nn.Upsample 层级联生成。
在这个例子中,FeaturePyramid 类使用 nn.ModuleList 定义了三个模块列表:self.convs、self.upsamples 和 self.downscales。其中,self.convs 列表包含了从底部到顶部每个特征级别的卷积层,self.upsamples 列表包含了从底部到顶部每个特征级别的上采样层,self.smooth 和 self.top_down 层用于连接上下两个路径。
在 forward 方法中,首先从输入图像计算底层特征,然后将其作为参数传递给每个级别的卷积层,逐步计算出每个级别的特征图。然后使用从最高层到最底层的顺序遍历上下两个路径,通过在每个级别使用上采样、卷积和平滑层的组合来合并来自下面和来自上面的特征。最终,返回所有级别的特征图,以列表的形式返回。
要获取 class FeaturePyramid 中的 model, levels=5,只需创建 FeaturePyramid 的实例。
import torch
import torch.nn.functional as F
class FeaturePyramid:
def __init__(self, model, levels=5):
self.model = model
self.levels = levels
def __call__(self, image):
pyramid = []
for i in range(self.levels):
factor = 2 ** i
h, w = image.shape[-2:]
new_h, new_w = h // factor, w // factor
scaled_image = F.interpolate(image, size=(new_h, new_w), mode='bilinear', align_corners=False)
pyramid.append(scaled_image)
features = []
for i in range(self.levels):
feature_map = self.model(pyramid[i])
features.append(feature_map)
sizes = [(f.shape[-2], f.shape[-1]) for f in features]
return features, sizes
#该类的初始化函数接受一个已训练好的卷积神经网络模型和金字塔层数作为参数。调用对象时,需要传入输入#图像,并返回特征金字塔中每个尺度的特征图和大小。
使用该特征金字塔类进行目标检测的示例代码:
class ObjectDetector:
def __init__(self, model, pyramid_levels=5, num_scales=3, score_thresh=0.5, nms_thresh=0.5):
self.model = model
self.pyramid = FeaturePyramid(model, levels=pyramid_levels)
self.num_scales = num_scales
self.score_thresh = score_thresh
self.nms_thresh = nms_thresh
def __call__(self, image):
detections = []
features, sizes = self.pyramid(image)
for i in range(len(features)):
feature_map = features[i]
h, w = sizes[i]
for j, size in enumerate([64, 128, 256][:self.num_scales]):
detection_map = self.model(feature_map)
detection_map = F.interpolate(detection_map, size=(h, w), mode='bilinear', align_corners=False)
scores, labels, boxes = self.decode_detection_map(detection_map)
# keep only detections with score above threshold
keep = scores > self.score_thresh
scores, labels, boxes = scores[keep], labels[keep], boxes[keep]
# apply non-maximum suppression
keep = self.non_max_suppression(scores, labels, boxes)
scores, labels, boxes = scores[keep], labels[keep], boxes[keep]
# convert boxes from relative to absolute coordinates
boxes[:, 0::2] *= w
boxes[:, 1::2] *= h
# append detections for this scale
detections.append((scores, labels, boxes))
# concatenate detections across all scales and sort by score
all_scores = torch.cat([s for s, _, _ in detections], dim=0)
all_labels = torch.cat([l for _, l, _ in detections], dim=0)
all_boxes = torch.cat([b for _, _, b in detections], dim=0)
_, idx = all_scores.sort(descending=True)
all_scores = all_scores[idx]
all_labels = all_labels[idx]
all_boxes = all_boxes[idx]
return all_scores, all_labels, all_boxes
def decode_detection_map(self, detection_map):
scores, labels = detection_map[:, :, 0], detection_map[:, :, 1:].argmax(dim=-1)
num_classes = detection_map.shape[-1] - 1
boxes = torch.zeros_like(detection_map[:, :, 1:])
for i in range(num_classes):
# compute center, width and height of boxes
ctr_x = torch.arange(detection_map.shape[1], dtype=torch.float32, device=detection_map.device) + 0.5
ctr_y = torch.arange(detection_map.shape[2], dtype=torch.float32, device=detection_map.device) + 0.5
ctr_x, ctr_y = torch.meshgrid(ctr_x, ctr_y)
ctr_x, ctr_y = ctr_x.reshape(-1), ctr_y.reshape(-1)
w = torch.exp(detection_map[:, :, i+1])
h = torch.exp(detection_map[:, :, num_classes+i+1])
# compute left, top, right and bottom coordinates of boxes
x1 = ctr_x - 0.5 * w
y1 = ctr_y - 0.5 * h
x2 = ctr_x + 0.5 * w
y2 = ctr_y + 0.5 * h
# concatenate box coordinates
boxes[:, :, i] = torch.stack([x1, y1, x2, y2], dim=-1)
return scores, labels, boxes
该函数接受一个检测图(一个 3D 的张量,第一维是 batch 大小,第二维和第三维分别是检测图的宽和高,第四维是目标类别和边界框的输出通道数),并返回目标检测结果。首先,该函数从检测图中提取出每个像素点的得分和类别预测,然后使用指数函数将边界框的宽度和高度预测还原为实际值。接着,该函数在图像中的每个像素点上计算出边界框的左上角和右下角坐标,最后返回得分、类别和边界框。
七、预训练模型
预训练模型通常由两部分组成:模型架构和模型参数。模型架构定义了模型的结构和计算图,包括各种卷积层、池化层、全连接层等。模型参数是模型的权重和偏置项,这些参数是在训练过程中学习到的。
使用预训练模型可以大大加快模型的训练速度,并提高模型的准确性。在许多计算机视觉和自然语言处理任务中,预训练模型已经成为了最先进的技术。例如,使用预训练的BERT模型进行文本分类任务,可以取得比使用从头开始训练的模型更好的结果。
应用预训练模型的步骤可以概括为以下几个:
1.选择合适的预训练模型:根据具体任务的需求,选择适合的预训练模型,例如在自然语言处理任务中可以选择BERT、GPT等模型,在计算机视觉任务中可以选择ResNet、Inception等模型。
2.加载预训练模型:将预训练模型的参数和架构加载到内存中,通常使用模型训练框架提供的API完成,例如PyTorch、TensorFlow等框架。
3.针对具体任务微调模型:由于预训练模型是在大规模数据集上训练的,因此其参数已经具有很强的特征提取能力。但是在具体任务中,预训练模型可能需要微调以适应任务的需求。微调可以通过在具体任务的数据集上训练模型来完成。
4.模型评估和调优:使用评估数据集对微调后的模型进行评估,并对模型进行调优,以获得最好的性能。
5.应用模型:使用微调后的模型进行具体任务,例如文本分类、目标检测、图像分割等。
以下是一些常用的预训练模型示例:
1.自然语言处理预训练模型:
- BERT (Bidirectional Encoder Representations from Transformers)
- GPT (Generative Pre-trained Transformer)
- RoBERTa (Robustly Optimized BERT Pretraining Approach)
- XLNet (eXtreme MultiLingual Language Understanding)
- ALBERT (A Lite BERT)
- T5 (Text-to-Text Transfer Transformer)
- ELECTRA (Efficiently Learning an Encoder that Classifies Token Replacements Accurately)
2.计算机视觉预训练模型:
- ResNet (Residual Network)
- Inception (GoogleNet Inception)
- VGG (Visual Geometry Group)
- MobileNet (Mobile Network)
- EfficientNet (Efficient Neural Network)
- DenseNet (Densely Connected Convolutional Network)
这些预训练模型已经在大规模数据集上进行了预训练,并且在各自的领域中获得了很好的效果,可以直接应用于相应的任务中,或者进行微调以适应具体任务的需求。
版权归原作者 在徏足前进的白 所有, 如有侵权,请联系我们删除。