

今天看到一篇写的很不错的文,想着自己总结一下。
异地多活到底是什么?为什么需要异地多活?它到底解决了什么问题?究竟是怎么解决的?
文章目录
系统可用性
让我们从最基础的开始往上垒。

这个图我想会点开这篇博客的朋友应该都不陌生了,就不需要我多做解释了。
我很喜欢的一句话和大家分享一下:很多模式是不能直接复制的。当数量级直线上升的时候,其背后的难度是几何增长的。
图中小数点后的一个9,对系统的要求那绝对是更上一层楼了。
难点一般体现在3个方面:
1、硬件故障:CPU、内存、磁盘、网卡、交换机、路由器等
2、软件问题
3、不可抗力:天灾人祸
这些风险随时都有可能发生,在面对故障时,我们的系统能否以最快的速度恢复,成为了可用性的关键。
我们来走一走这条艰难发展之路,感受一下前辈们的智慧。在发展的过程中都出现了什么问题,以及思考前辈们为什么会选择当初那个方案。
单机架构
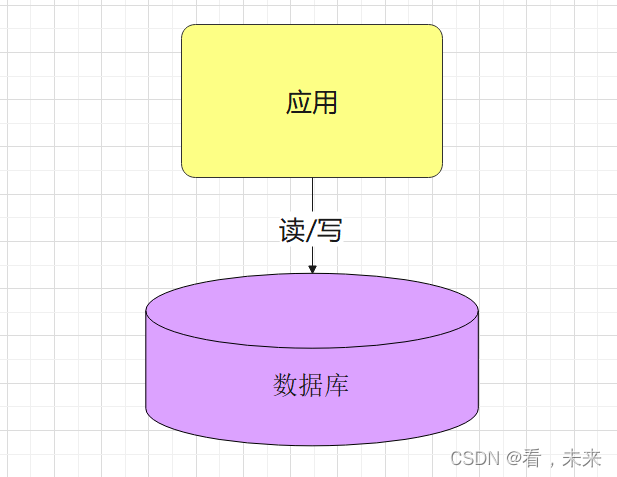
早期发展的架构模型,如果你的业务量比较少的话可以用这个。客户端请求进来,业务层读写数据库,返回结果。
不要看不上这个架构,我个人觉得目前这个架构在跨界领域还是应用面比较广的。
随着互联网业务量的增长,瓶颈开始出现了。这里的数据库是单机部署的,所以一旦这个数据库遭遇意外,那这个损失将是巨大的。
于是,一个新的方案出来了:备份。
你可以对数据做备份,把数据库文件定期备份到另一台机器上,这样,即使原机器丢失数据,你依然可以通过备份找回数据。
这个方案自己玩玩就好了,真要铺开来使用存在两个问题:
1、耗时长。
2、数据不完整。
那有什么更好的方案,既可以快速恢复业务?还能尽可能保证数据完整性呢?
主从复制
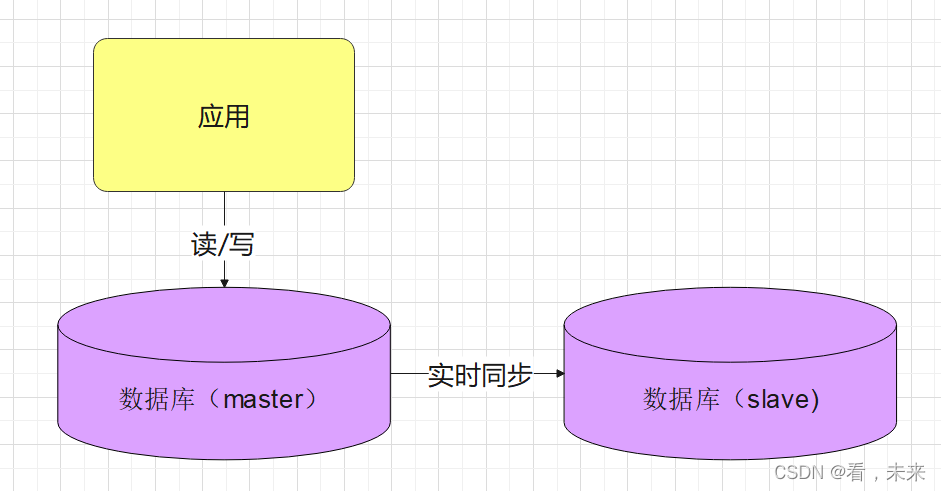
但是呢,作为商业型公司要获利就要开源节流嘛,平白整个数据库在那边是不是要利用起来,这时候考虑到主库既要读又要写,压力有点大,从库闲着也是闲着,那就让它分担掉绝大部分读的压力吧。
这就是 “读写分离”。
这里有个误区:读写分离并不是完全分离的干干净净,因为主从之间毕竟还是存在延迟的,所以有些核心数据还是需要从主库获取第一手数据的。
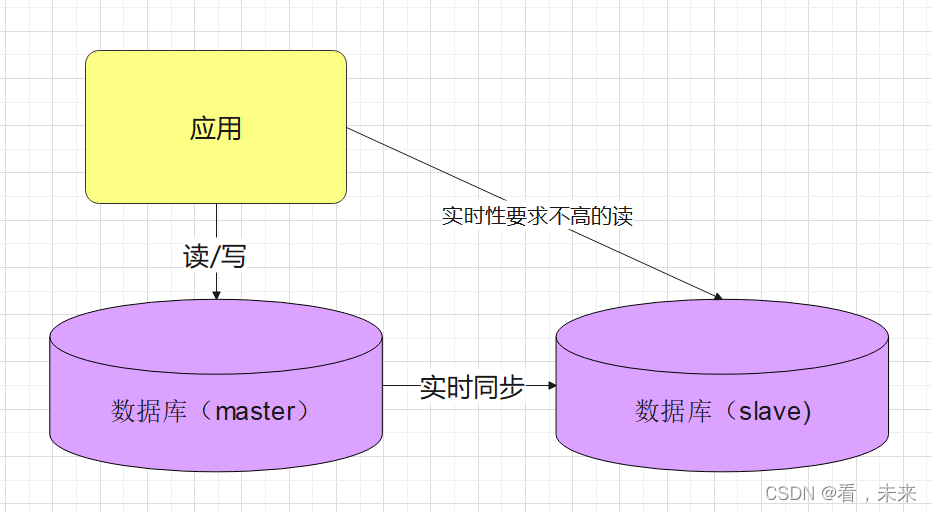
流量高了,既然数据库都可以部署多个,那业务层是不是也可以部署多个嘞?
既然是分摊流量,则需要一个分摊的规则,不然可就乱套了,于是出现了 负载均衡。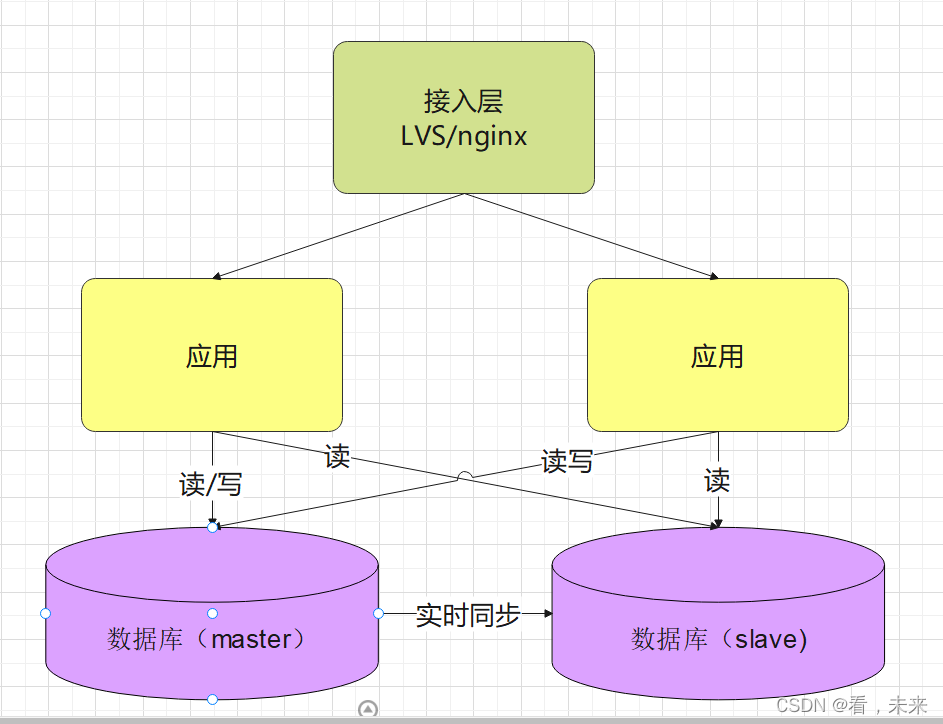
到这里,已经基本成型成为现在的主流方案了。但是,这样就可保万全了吗?
让我们把眼界往上提升一个档次。
不可抗力
一个机房有很多服务器,这些服务器分布在一个个的机柜上,如果你使用的这些机器,恰好在一个机柜上,且连接这个机柜的 交换机/路由器 发生了故障,那么你的应用依旧有 GG 的风险。
部署在一个机柜有风险,那把这些机器打散,分散到不同机柜上,是不是就没问题了?
这样确实会大大降低出问题的概率。但我们依旧不能掉以轻心,因为无论怎么分散,它们总归还是在一个相同的环境下:机房。
有的人可能会觉得有点小题大做了。
(如果觉得没有必要,那就没有必要吧)
体量很小的系统,它会重点关注「用户」规模、增长,这个阶段获取用户是一切。等用户体量上来了,这个阶段会重点关注「性能」,优化接口响应时间、页面打开速度等等,这个阶段更多是关注用户体验。
等体量再大到一定规模后你会发现,「可用性」就变得尤为重要。像微信、支付宝这种全民级的应用,如果机房发生一次故障,那整个影响范围可以说是非常巨大的。
所以,再小概率的风险,我们在提高系统可用性时,也不能忽视。
分析了风险,再说回我们的架构。那到底该怎么应对机房级别的故障呢?
同城灾备
一个数据库会出问题,那就两个数据库。一个机房会出问题,那就两个机房。
简单起见,你可以在同一个城市再搭建一个机房。原机房为A,新机房为B,两个机房之间的网络用一条专线连通。
A机房的数据,定时在B机房做备份(拷贝数据文件),这样即使是A机房遭到严重损坏,B机房的数据也不会丢失。这种方案被称之为冷备。
但是前面单机冷备会出现的问题(慢 + 数据缺失 + 闲置)这里依然会出现,于是我们把那个模式复制到这里来看看:

这样的话,即使整个A机房挂掉,我们很快就能恢复服务:
1、B 机房所有从库提升为主库。
2、DNS 指向 B 机房接入层。
这种方案,我们称之为 热备。
同城灾备的最大优势在于,我们再也不用担心「机房」级别的故障了,一个机房发生风险,我们只需把流量切换到另一个机房即可。
同城双活
虽然我们有了应对机房故障的解决方案,但这里有个问题是我们不能忽视的:A 机房挂掉,全部流量切到 B 机房,B 机房能否真的如我们所愿,正常提供服务?
To be,or not to be,it’s a question.
都说用进废退,没有扛过那么大压力的 B 机房,是否不孚众望谁也说不准。而且这不还有个 闲置 的问题要解决一下嘛。
因此,我们需要让 B 机房也接入流量,实时提供服务。一是可以实时训练这支后备军,让它达到与 A 机房相同的作战水平,随时可切换;二是 B 机房接入流量后,可以分担 A 机房的流量压力。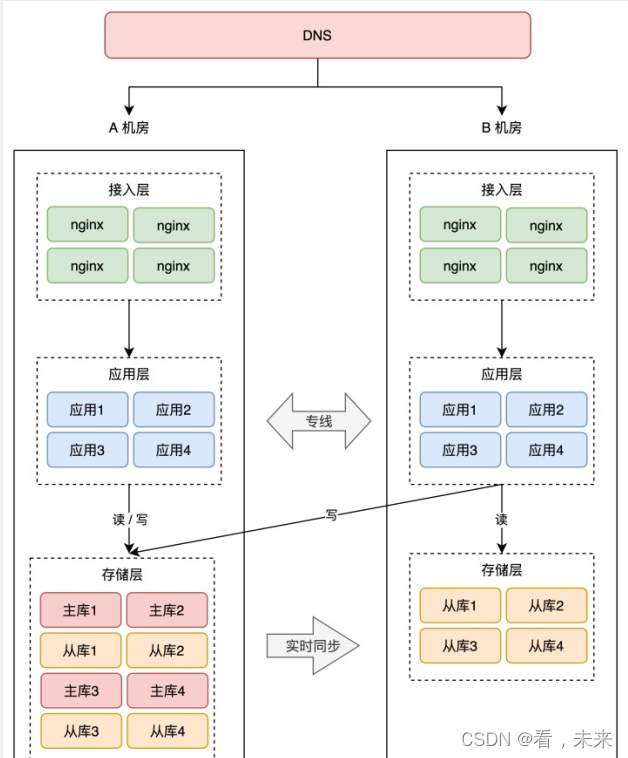
业务改造完成后,B 机房可以慢慢接入流量,从 10%、30%、50% 逐渐覆盖到 100%,你可以持续观察 B 机房的业务是否存在问题,有问题及时修复,逐渐让 B 机房的工作能力,达到和 A 机房相同水平。
这种方案我们把它叫做「同城双活」。
两地三中心
我们的架构随着风险等级的提升在不断的升级,现在也该到了可接受的最高的风险等级了吧:天灾人祸。
(这里不考虑什么星际问题哈)
如果是整个城市发生自然灾害,那 2 个机房依旧存在「全局覆没」的风险。
但这次冗余机房,就不能部署在同一个城市了,你需要把它放到距离更远的地方,部署在「异地」。
按照前面的思路,把 C 机房用起来,最简单粗暴的方案还就是做「冷备」。

这种方式称之为两地三中心。这会儿不用我多言了吧,该改进。
异地双活
按照上面的思路,只要把 “同城双活” 那一趴的图里的 “A机房”、“B机房”放到两个不同的城市好了。但是现实是如此的吗?
因为是异地,两个机房之间的专线也将升级为 跨域专线 了。受物理距离的限制,两地之间的网络延迟就成为了不可忽视的因素。
不止是延迟,远距离的网络专线质量,是远远达不到机房内网络质量的,专线网络经常会发生延迟、丢包、甚至中断的情况。总之,不能过度信任和依赖「跨城专线」。
既然「跨机房」调用延迟是不容忽视的因素,那我们只能尽量避免跨机房「调用」,规避这个延迟问题。
这时候就不能再采取原先的 “主从架构”了,因为两地的服务器都要提供读写功能,且要保持数据的一致性。
MySQL 本身就提供了双主架构,它支持双向复制数据,但平时用的并不多。而 Redis、MongoDB 等数据库并没有提供这个功能,所以,你必须开发对应的「数据同步中间件」来实现双向同步的功能。
此外,除了数据库这种有状态的软件之外,你的项目通常还会使用到消息队列,例如 RabbitMQ、Kafka,这些也是有状态的服务,所以它们也需要开发双向同步的。
于是乎,整个架构改版成为这个样子了:
那么,这个架构又存在了什么样的问题呢?分布式的数据一致性问题。
麻烦吧。其实这个解决方案倒是直观,直接划分流量即可。打游戏的时候还有分:华东区、华南区、华中区等,这不就是个很现成的解决方案嘛。
或者也可以通过别的方式,如哈希分片等,反正只要确保让同一个用户的相关请求,只在一个机房内完成所有业务「闭环」,不再出现「跨机房」访问。,从源头避免数据冲突!

当然,最上层的路由层把用户分片后,理论来说同一个用户只会落在同一个机房内,但不排除程序 Bug 导致用户会在两个机房「漂移」。安全起见,每个机房在写存储时,还需要有一套机制,能够检测「数据归属」,应用层操作存储时,需要通过中间件来做「兜底」,避免不该写本机房的情况发生。
这里还有一种情况,是无法做数据分片的:全局数据。
例如系统配置、商品库存这类需要强一致的数据,这类服务依旧只能采用写主机房,读从机房的方案,不做双活。
== 双活的重点,是要优先保证「核心」业务先实现双活,并不是「全部」业务实现双活。==
异地多活
理解了异地双活,那「异地多活」顾名思义,就是在异地双活的基础上,部署多个机房即可。
版权归原作者 看,未来 所有, 如有侵权,请联系我们删除。