
TCN 从“阿巴阿巴”到“巴拉巴拉”
- TCN的概念(干嘛来的!能解决什么问题)
- TCN的父母(由来)
- TCN的原理介绍
- 上代码!
1、TCN(时域卷积网络、时间卷积网络)是干嘛的,能干嘛
主要应用方向:
时序预测、概率预测、时间预测、交通预测
2、TCN的由来
ps:在了解TCN之前需要先对CNN和RNN有一定的了解。
- 处理问题:
是一种能够处理时间序列数据的网络结构,在特定条件下,效果优于传统的神经网络(RNN、CNN等)。
3、TCN的原理介绍
TCN 的网络结构
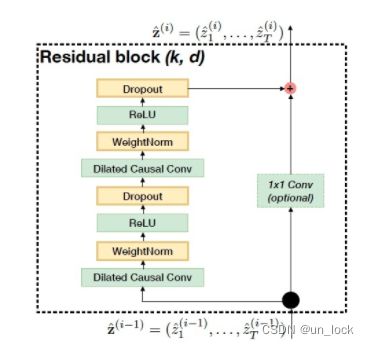
一、TCN的网络结构主要由上图构成。本文分为左边和右边两部分,首先是左边
Dilated Causal Conv ---> WeightNorm--->ReLU--->Dropout--->Dilated Causal Conv ---> WeightNorm--->ReLU--->Dropout
很明显这个可以分为
(Dilated Causal Conv ---> WeightNorm--->ReLU--->Dropout)*2
ok,下面我们对这四个逐个进行讲解,如有了解可以选择跳读
1、Dilated Gausal Conv
中文名:膨胀因果卷积
膨胀因果卷积可以分为膨胀、因果和卷积三部分。
卷积是指 CNN中的卷积,是指卷积核在数据上进行的一种滑动运算操作;
膨胀是指 允许卷积时的输入存在间隔采样,其和卷积神经网络中的stride有相似之处,但也有很明显的区别
图片说明:
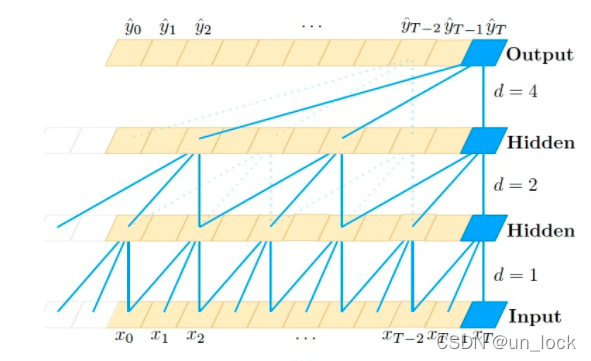
因果是指 第i层中t时刻的数据,只依赖与(i-1)层t时刻及其以前的值的影响。因果卷积可以在训练的时候摒弃掉对未来数据的读取,是一种严格的时间约束模型。
图片说明:

(ps:没有加入膨胀卷积)
2、WeightNorm
权重归一化
对权重值进行归一化,如果有想仔细研究归一化过程&归一化公式的,可以点击链接进行学习
点击
优点:
1、时间开销小,运算速度快!
2、引入更少的噪声
3、WeightNorm是通过重写深度网络的权重来进行加速的,没有引入对minibatch的依赖
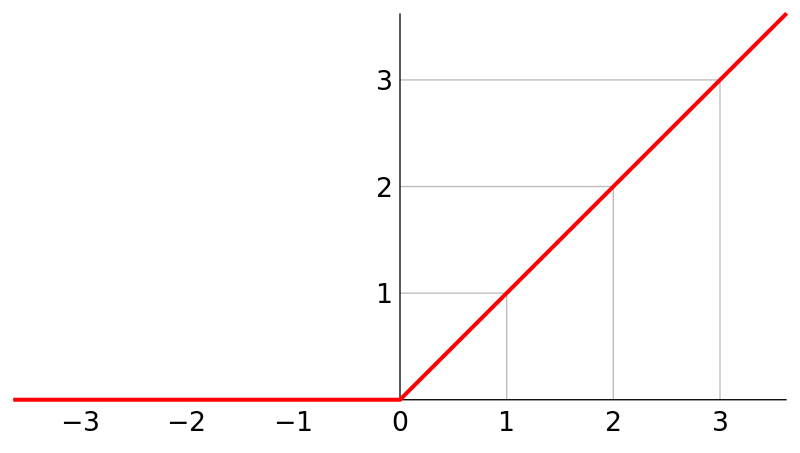
3、ReLU()
激活函数的一种
优点:
1、可以使网络的训练速度更快
2、增加网络的非线性,提高模型的表达能力
3、防止梯度消失,
4、使网络具有稀疏性等
公式:
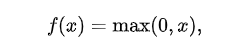
概述图:
4、Dropout()
Dropout是指在深度学习网络的训练过程中,对于神经网络单元,按照一定的概率将其暂时从网络中丢弃。
优点:防止过拟合,提高模型的运算速度
二、最后是右边—**-残差连接**:
右边是一个1*1的卷积块儿,不仅可以使网络拥有跨层传递信息的功能,而且可以保证输入输出的一致性。
三、TCN的优点:
1、并行性
2、可以很大程度上避免梯度消失和梯度爆炸
3、感受野更大,学习到的信息更多
4、从零coding
import os
import sys
import paddle
import paddle.nn as nn
import numpy as np
import pandas as pd
import seaborn as sns
from pylab import rcParams
import matplotlib.pyplot as plt
from matplotlib import rc
import paddle.nn.functional as F
from paddle.nn.utils import weight_norm
from sklearn.preprocessing import MinMaxScaler
from pandas.plotting import register_matplotlib_converters
from sourceCode import TimeSeriesNetwork
sys.path.append(os.path.abspath(os.path.join(os.getcwd(),"../..")))classChomp1d(nn.Layer):def__init__(self, chomp_size):super(Chomp1d, self).__init__()
self.chomp_size = chomp_size
defforward(self, x):return x[:,:,:-self.chomp_size]classTemporalBlock(nn.Layer):def__init__(self,
n_inputs,
n_outputs,
kernel_size,
stride,
dilation,
padding,
dropout=0.2):super(TemporalBlock, self).__init__()
self.conv1 = weight_norm(
nn.Conv1D(
n_inputs,
n_outputs,
kernel_size,
stride=stride,
padding=padding,
dilation=dilation))# Chomp1d is used to make sure the network is causal.# We pad by (k-1)*d on the two sides of the input for convolution,# and then use Chomp1d to remove the (k-1)*d output elements on the right.
self.chomp1 = Chomp1d(padding)
self.relu1 = nn.ReLU()
self.dropout1 = nn.Dropout(dropout)
self.conv2 = weight_norm(
nn.Conv1D(
n_outputs,
n_outputs,
kernel_size,
stride=stride,
padding=padding,
dilation=dilation))
self.chomp2 = Chomp1d(padding)
self.relu2 = nn.ReLU()
self.dropout2 = nn.Dropout(dropout)
self.net = nn.Sequential(self.conv1, self.chomp1, self.relu1,
self.dropout1, self.conv2, self.chomp2,
self.relu2, self.dropout2)
self.downsample = nn.Conv1D(n_inputs, n_outputs,1)if n_inputs != n_outputs elseNone
self.relu = nn.ReLU()
self.init_weights()definit_weights(self):
self.conv1.weight.set_value(
paddle.tensor.normal(0.0,0.01, self.conv1.weight.shape))
self.conv2.weight.set_value(
paddle.tensor.normal(0.0,0.01, self.conv2.weight.shape))if self.downsample isnotNone:
self.downsample.weight.set_value(
paddle.tensor.normal(0.0,0.01, self.downsample.weight.shape))defforward(self, x):
out = self.net(x)
res = x if self.downsample isNoneelse self.downsample(x)# 让输入等于输出return self.relu(out + res)classTCNEncoder(nn.Layer):def__init__(self, input_size, num_channels, kernel_size=2, dropout=0.2):# input_size : 输入的预期特征数# num_channels: 通道数# kernel_size: 卷积核大小super(TCNEncoder, self).__init__()
self._input_size = input_size
self._output_dim = num_channels[-1]
layers = nn.LayerList()
num_levels =len(num_channels)# print('print num_channels: ', num_channels)# print('print num_levels: ',num_levels)# exit(0)for i inrange(num_levels):
dilation_size =2** i
in_channels = input_size if i ==0else num_channels[i -1]
out_channels = num_channels[i]
layers.append(
TemporalBlock(
in_channels,
out_channels,
kernel_size,
stride=1,
dilation=dilation_size,
padding=(kernel_size -1)* dilation_size,
dropout=dropout))
self.network = nn.Sequential(*layers)defget_input_dim(self):return self._input_size
defget_output_dim(self):return self._output_dim
defforward(self, inputs):
inputs_t = inputs.transpose([0,2,1])
output = self.network(inputs_t).transpose([2,0,1])[-1]return output
classTimeSeriesNetwork(nn.Layer):def__init__(self, input_size, next_k=1, num_channels=[256]):super(TimeSeriesNetwork, self).__init__()
self.last_num_channel = num_channels[-1]
self.tcn = TCNEncoder(
input_size=input_size,
num_channels=num_channels,
kernel_size=3,
dropout=0.2)
self.linear = nn.Linear(in_features=self.last_num_channel, out_features=next_k)defforward(self, x):
tcn_out = self.tcn(x)
y_pred = self.linear(tcn_out)return y_pred
'''
我努力把自己塑造成悲剧里面的男主角,
把一切过错推到你的身上,
让你成为万恶的巫婆,
丧心病狂
可是我就是一个正常的人,
有悲有喜,
有错有对,
走到今天这个地步,
我们都有责任,
直到现在我还没有觉得我失去了你
你告诉我,我失去你了么?
'''defconfig_mtp():
sns.set(style='whitegrid', palette='muted', font_scale=1.2)
HAPPY_COLORS_PALETTE =["#01BEFE","#FFDD00","#FF7D00","#FF006D","#93D30C","#8F00FF"]
sns.set_palette(sns.color_palette(HAPPY_COLORS_PALETTE))
rcParams['figure.figsize']=14,10
register_matplotlib_converters()defread_data():
df_all = pd.read_csv('./data/time_series_covid19_confirmed_global.csv')# print(df_all.head())# 我们将对全世界的病例数进行预测,因此我们不需要关心具体国家的经纬度等信息,只需关注具体日期下的全球病例数即可。
df = df_all.iloc[:,4:]
daily_cases = df.sum(axis=0)
daily_cases.index = pd.to_datetime(daily_cases.index)# print(daily_cases.head())
plt.figure(figsize=(5,5))
plt.plot(daily_cases)
plt.title("Cumulative daily cases")# plt.show()# 为了提高样本时间序列的平稳性,继续取一阶差分
daily_cases = daily_cases.diff().fillna(daily_cases[0]).astype(np.int64)# print(daily_cases.head())
plt.figure(figsize=(5,5))
plt.plot(daily_cases)
plt.title("Daily cases")
plt.xticks(rotation=60)
plt.show()return daily_cases
defcreate_sequences(data, seq_length):
xs =[]
ys =[]for i inrange(len(data)- seq_length +1):
x = data[i:i + seq_length -1]
y = data[i + seq_length -1]
xs.append(x)
ys.append(y)return np.array(xs), np.array(ys)defpreprocess_data(daily_cases):
TEST_DATA_SIZE,SEQ_LEN =30,10
TEST_DATA_SIZE =int(TEST_DATA_SIZE/100*len(daily_cases))# TEST_DATA_SIZE=30,最后30个数据当成测试集,进行预测
train_data = daily_cases[:-TEST_DATA_SIZE]
test_data = daily_cases[-TEST_DATA_SIZE:]print("The number of the samples in train set is : %i"% train_data.shape[0])print(train_data.shape, test_data.shape)# 为了提升模型收敛速度与性能,我们使用scikit-learn进行数据归一化。
scaler = MinMaxScaler()
train_data = scaler.fit_transform(np.expand_dims(train_data, axis=1)).astype('float32')
test_data = scaler.transform(np.expand_dims(test_data, axis=1)).astype('float32')# 搭建时间序列# 可以用前10天的病例数预测当天的病例数,为了让测试集中的所有数据都能参与预测,我们将向测试集补充少量数据,这部分数据只会作为模型的输入。
x_train, y_train = create_sequences(train_data, SEQ_LEN)
test_data = np.concatenate((train_data[-SEQ_LEN +1:], test_data), axis=0)
x_test, y_test = create_sequences(test_data, SEQ_LEN)# 尝试输出'''
print("The shape of x_train is: %s"%str(x_train.shape))
print("The shape of y_train is: %s"%str(y_train.shape))
print("The shape of x_test is: %s"%str(x_test.shape))
print("The shape of y_test is: %s"%str(y_test.shape))
'''return x_train,y_train,x_test,y_test,scaler
# 数据集处理完毕,将数据集封装到CovidDataset,以便模型训练、预测时调用。classCovidDataset(paddle.io.Dataset):def__init__(self, feature, label):
self.feature = feature
self.label = label
super(CovidDataset, self).__init__()def__len__(self):returnlen(self.label)def__getitem__(self, index):return[self.feature[index], self.label[index]]defparameter():
LR =1e-2
model = paddle.Model(network)
optimizer = paddle.optimizer.Adam(
learning_rate=LR, parameters=model.parameters())
loss = paddle.nn.MSELoss(reduction='sum')
model.prepare(optimizer, loss)
config_mtp()
data = read_data()
x_train,y_train,x_test,y_test,scaler = preprocess_data(data)
train_dataset = CovidDataset(x_train, y_train)
test_dataset = CovidDataset(x_test, y_test)
network = TimeSeriesNetwork(input_size=1)# 参数配置
LR =1e-2
model = paddle.Model(network)
optimizer = paddle.optimizer.Adam(learning_rate=LR, parameters=model.parameters())# 优化器
loss = paddle.nn.MSELoss(reduction='sum')
model.prepare(optimizer, loss)# Configures the model before runing,运行前配置模型# 训练
USE_GPU =False
TRAIN_EPOCH =100
LOG_FREQ =20
SAVE_DIR = os.path.join(os.getcwd(),"save_dir")
SAVE_FREQ =20if USE_GPU:
paddle.set_device("gpu")else:
paddle.set_device("cpu")
model.fit(train_dataset,
batch_size=32,
drop_last=True,
epochs=TRAIN_EPOCH,
log_freq=LOG_FREQ,
save_dir=SAVE_DIR,
save_freq=SAVE_FREQ,
verbose=1# The verbosity mode, should be 0, 1, or 2. 0 = silent, 1 = progress bar, 2 = one line per epoch. Default: 2.)# 预测
preds = model.predict(
test_data=test_dataset
)# 数据后处理,将归一化的数据转化为原数据,画出真实值对应的曲线和预测值对应的曲线。
true_cases = scaler.inverse_transform(
np.expand_dims(y_test.flatten(), axis=0)).flatten()
predicted_cases = scaler.inverse_transform(
np.expand_dims(np.array(preds).flatten(), axis=0)).flatten()print(true_cases.shape, predicted_cases.shape)# print (type(data))# print(data[1:3])# print (len(data), len(data))# print(data.index[:len(data)])
mse_loss = paddle.nn.MSELoss(reduction='mean')print(paddle.sqrt(mse_loss(paddle.to_tensor(true_cases), paddle.to_tensor(predicted_cases))))print(true_cases, predicted_cases)
如果需要数据欢迎下方评论,同时也可以私信获取。
千万不要忘了点赞、评论、收藏,对我真的很重要偶~
版权归原作者 un_lock 所有, 如有侵权,请联系我们删除。