
文章目录
写在前面
作为大数据开发人员,我们经常会收到一些数据分析工程师给我们的指标,我们基于这些指标进行数据提取。其中数据分析工程师最主要的一个特征提取方式就是PCA主成分分析,下面我将介绍Python的sklearn库中是如何实现PCA算法及其使用。
一、PCA主成分分析
什么是PCA主成分分析。百度百科给出如下定义: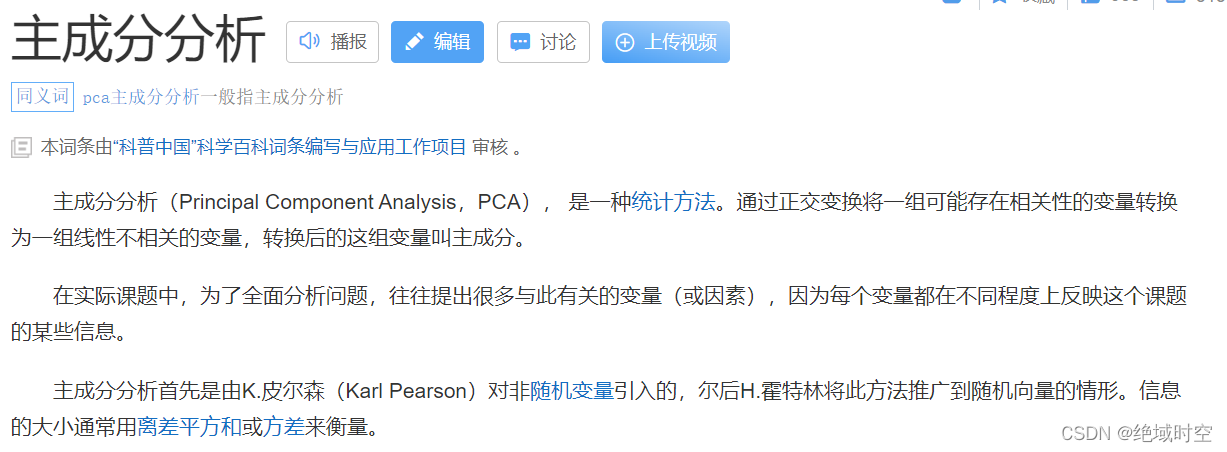
1、主成分分析步骤
对于一个PCA主成分分析,一般分为以下几个步骤:
- 去除平均值
- 计算协方差矩阵
- 计算协方差矩阵的特征值和特征向量
- 将特征值排序
- 保留前N个最大的特征值对应的特征向量
- 将原始特征转换到上面得到的N个特征向量构建的新空间中(最后两步,实现了特征压缩)
2、主成分分析的主要作
概括起来说,主成分分析主要有以下几个方面的作用。
- 主成分分析能降低所研究的数据空间的维数。即用研究m维的Y空间代替p维的X空间(m<p),而低维的Y空间代替高维的x空间所损失的信息很少。即:使只有一个主成分Yl(即 m=1)时,这个Yl仍是使用全部X变量(p个)得到的。例如要计算Yl的均值也得使用全部x的均值。在所选的前m个主成分中,如果某个Xi的系数全部近似于零的话,就可以把这个Xi删除,这也是一种删除多余变量的方法。
- 有时可通过因子负荷aij的结论,弄清X变量间的某些关系。
- 多维数据的一种图形表示方法。我们知道当维数大于3时便不能画出几何图形,多元统计研究的问题大都多于3个变量。要把研究的问题用图形表示出来是不可能的。然而,经过主成分分析后,我们可以选取前两个主成分或其中某两个主成分,根据主成分的得分,画出n个样品在二维平面上的分布况,由图形可直观地看出各样品在主分量中的地位,进而还可以对样本进行分类处理,可以由图形发现远离大多数样本点的离群点。
- 由主成分分析法构造回归模型。即把各主成分作为新自变量代替原来自变量x做回归分析。
- 用主成分分析筛选回归变量。回归变量的选择有着重的实际意义,为了使模型本身易于做结构分析、控制和预报,好从原始变量所构成的子集合中选择最佳变量,构成最佳变量集合。用主成分分析筛选变量,可以用较少的计算量来选择量,获得选择最佳变量子集合的效果。
二、Python使用PCA主成分分析
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
import numpy as np
X = np.array([[12,350,1.825,0.102,315,0,2,4],[25,300,5.57,0.45,220,25,3,2.5],[25,300,5.25,1.1,220,20,4,3]])
Y = np.array([22,300,4.25,1.86,210,18,3,2])# n_components指定降维后的维数
pca = PCA(n_components=2)print(pca)# 应用于训练集数据进行PCA降维
pca.fit(X)# 用X来训练PCA模型,同时返回降维后的数据
newX = pca.fit_transform(X)print(newX)# 将降维后的数据转换成原始数据,
pca_new = pca.transform(X)print(pca_new.shape)# 输出具有最大方差的成分print(pca.components_)# 输出所保留的n个成分各自的方差百分比print(pca.explained_variance_ratio_)# 输出所保留的n个成分各自的方差print(pca.explained_variance_)# 输出未处理的特征维数print(pca.n_features_)# 输出训练集的样本数量print(pca.n_samples_)# 输出协方差矩阵print(pca.noise_variance_)# 每个特征的奇异值print(pca.ingular_values_)# 用生成模型计算数据精度矩阵print(pca.get_precision())# 计算生成特征系数矩阵
covX = np.around(np.corrcoef(X.T), decimals=3)# 输出特征系数矩阵print(covX)# 求解协方差矩阵的特征值和特征向量
featValue, featVec = np.linalg.eig(covX)# 将特征进行降序排序
featValue =sorted(featValue)[::-1]# 图像绘制# 同样的数据绘制散点图和折线图
plt.scatter(range(1, X.shape[1]+1), featValue)
plt.plot(range(1, X.shape[1]+1), featValue)# 显示图的标题
plt.title("Test Plot")# xy轴的名字
plt.xlabel("Factors")
plt.ylabel("Eigenvalue")# 显示网格
plt.grid()# 显示图形
plt.show()
本文转载自: https://blog.csdn.net/m0_43405302/article/details/123594788
版权归原作者 绝域时空 所有, 如有侵权,请联系我们删除。
版权归原作者 绝域时空 所有, 如有侵权,请联系我们删除。