
文章目录
misc_or_crypto?
bmp里面是RSA的私钥和加密密文,在线直接解一下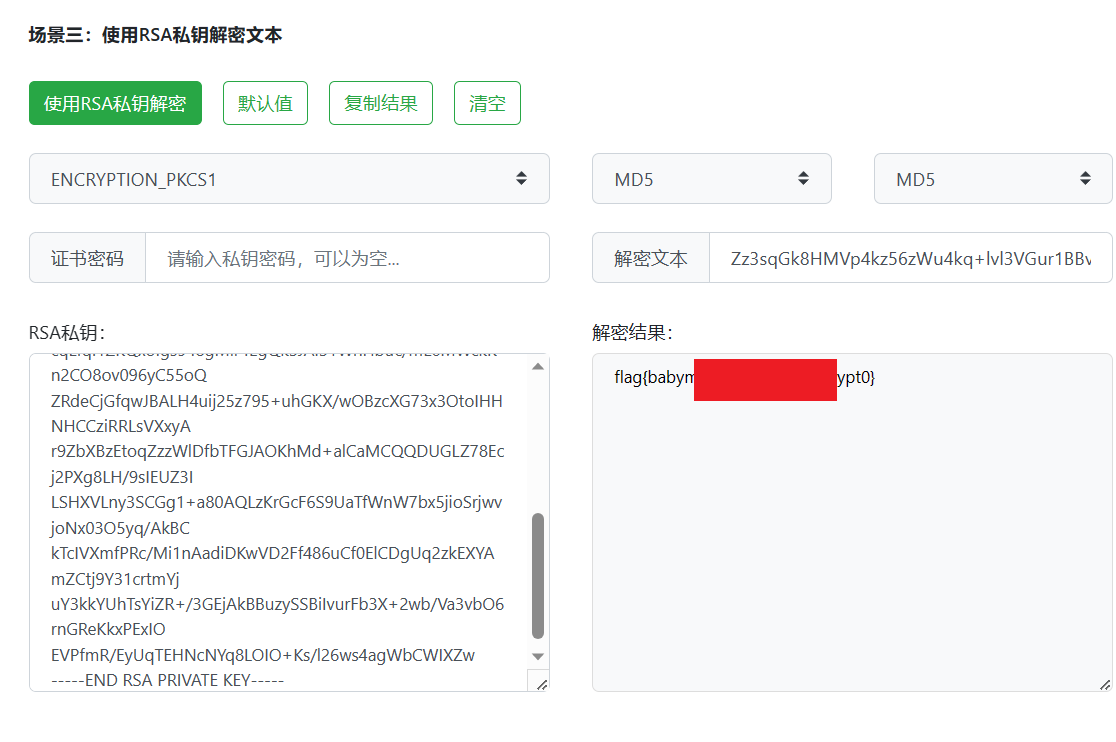
Hidden In Plain Sight
图片数据里提示了exiftool,看一下前两个图片exif信息,很明显AttributionName拼接是flag值
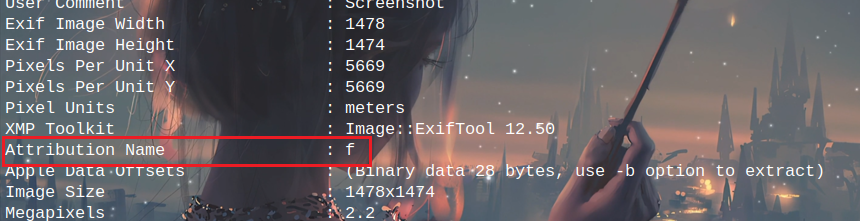
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Mk03O1kH-1682052296988)(https://c.img.dasctf.com/images/2023421/1682051520212-782d0af8-402b-4aa3-bc73-4bff4a5155f1.png)]
由于默认读取是以字符串大小顺序读取的,需要以文件名数字大小读取
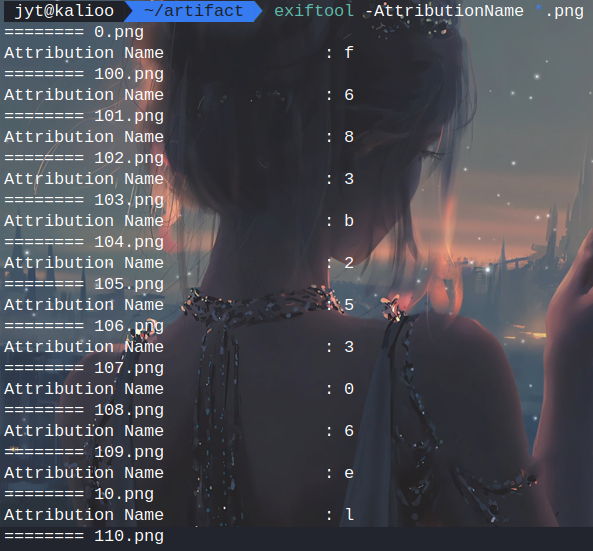
linux下:
exiftool -AttributionName -b -ext png $(ls -v *.png) > flag.txt
ls -1v *.png | xargs exiftool -AttributionName -b > flag.txt
windows下:
dir /b /on *.png | xargs exiftool -AttributionName -b > flag.txt
ls -1v
或
dir /b /on
部分会将当前目录下的
.png
文件按照文件名中的数字大小顺序进行排序,并作为参数传递给
exiftool
。
-b
参数表示以二进制方式输出
Attribution Name
的内容,将其写入
flag.txt
文件中。
得到flag
一开始以为还有一步flag在有6b88805329********************78这串16进制的图片里(
谁家flag这么奇怪啊!!

Matryoshka
压缩包套娃,每个password里是英文的算式,结果是同级压缩包的密码
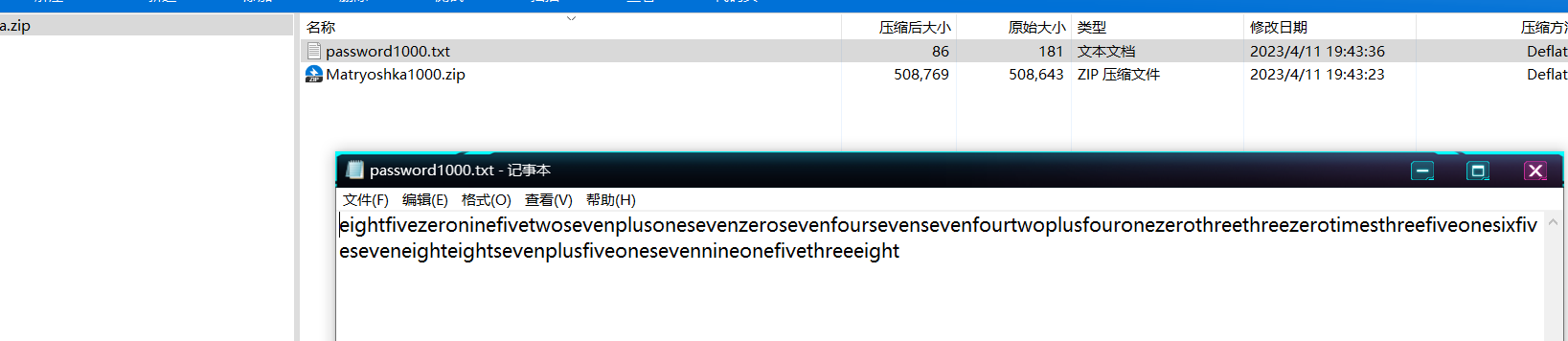
一个坑,结果如果为负要取绝对值
简单写个脚本跑一下即可:
- 建议自己写的时候加上个打印的操作监视运行过程
import re
import os
import zipfile
# 定义数字与字符的对应关系
char_to_digit ={'zero':'0','one':'1','two':'2','three':'3','four':'4','five':'5','six':'6','seven':'7','eight':'8','nine':'9','plus':'+','times':'*','minus':'-','mod':'%'}defchange(string):# 将字符串中的单词转换为数字
expression = string
for char, digit in char_to_digit.items():
expression = expression.replace(char, digit)# 分离出操作数和运算符
tokens = re.findall(r'\d+|[+*]|[-]|[%]', expression)print(tokens)# 从左到右依次计算
result =int(tokens[0])for i inrange(1,len(tokens),2):
operator = tokens[i]
operand =int(tokens[i+1])if operator =='+':
result += operand
elif operator =='*':
result *= operand
elif operator =='-':
result -= operand
elif operator =='%':
result %= operand
result=abs(result)returnstr(result)# 压缩包的总层数
num_layers =10# 构造密码字典,键为层数,值为对应层的密码
passwords ={}
passwords[num_layers]='password1000.txt'# 最外层的压缩包的密码已知for i inrange(num_layers -1,0,-1):
password_filename ='password{}.txt'.format(i +1)
passwords[i]= password_filename
defextract_all(name, level):
password_file = os.path.join(os.path.dirname(name),"password"+str(level)+".txt")
password =open(password_file).read().strip()# print(password)
password = change(password)# print(password)print(f"正在解压{name},使用的密码为:{password}")with zipfile.ZipFile(name)as zf:try:
zf.extractall(pwd=password.encode())except:print(f"解压{name}失败,密码错误")returnelse:print(f"{name}解压成功")
namelist = zf.namelist()for item in namelist:if item.endswith(".zip"):
extract_all(item, level-1)
extract_all("Matryoshka1000.zip",1000)
pixelart
文件尾有个大小的提示
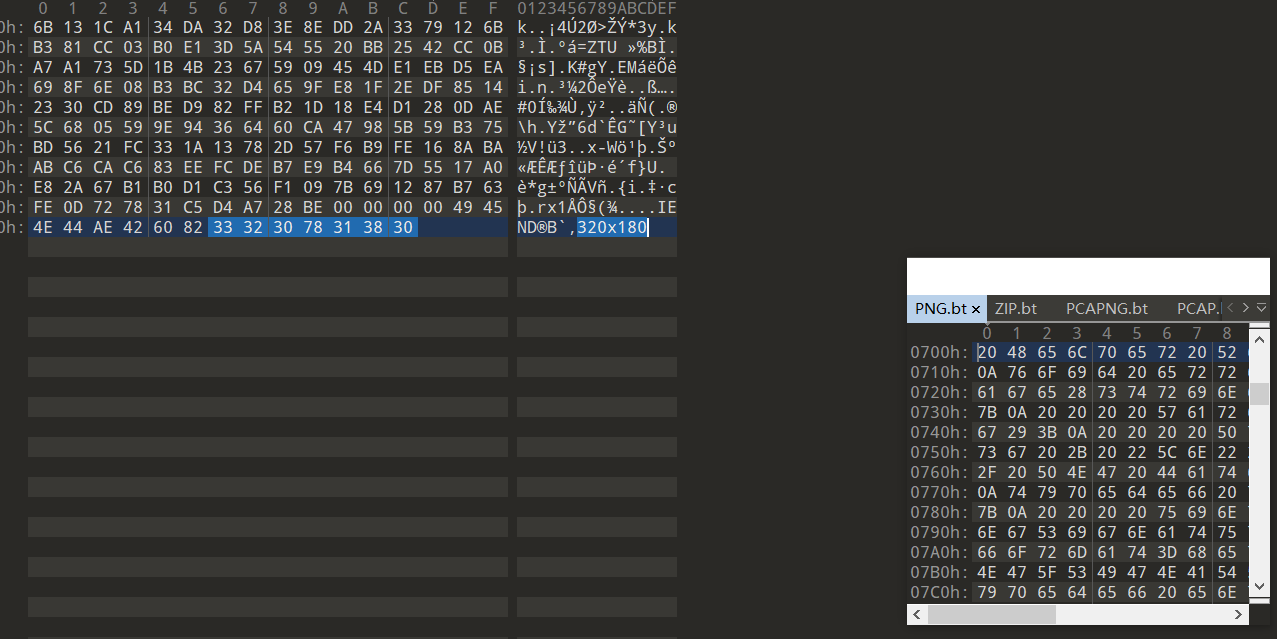
把图片放大后可以看到有隐藏的像素点,根据文件尾的提示,每12个像素提取一次即可

from PIL import Image
im = Image.open('arcaea.png')
pix = im.load()
width = im.size[0]
height = im.size[1]# 新图像的宽度和高度(每12个像素生成一个新像素)
new_width = width //12
new_height = height //12# 创建一个新的图像对象
new_img = Image.new("RGB",(new_width, new_height))for x inrange(0,width,12):for y inrange(0,height,12):
rgb=pix[x, y]
new_img.putpixel((x//12,y//12),(int(rgb[0]),int(rgb[1]),int(rgb[2])))
new_img.save('new_image.png')
得到fakeflag

zsteg
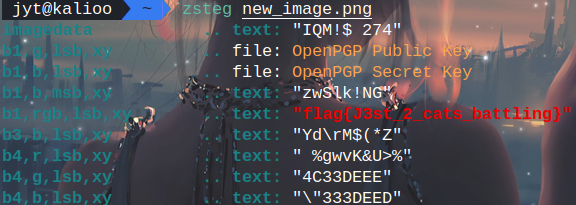
getnopwd
store,pcapng,一眼明文攻击

echo -n "00004D3C2B1A01000000FFFFFFFFFFFFFFFF" | xxd -r -ps > pcap_plain1
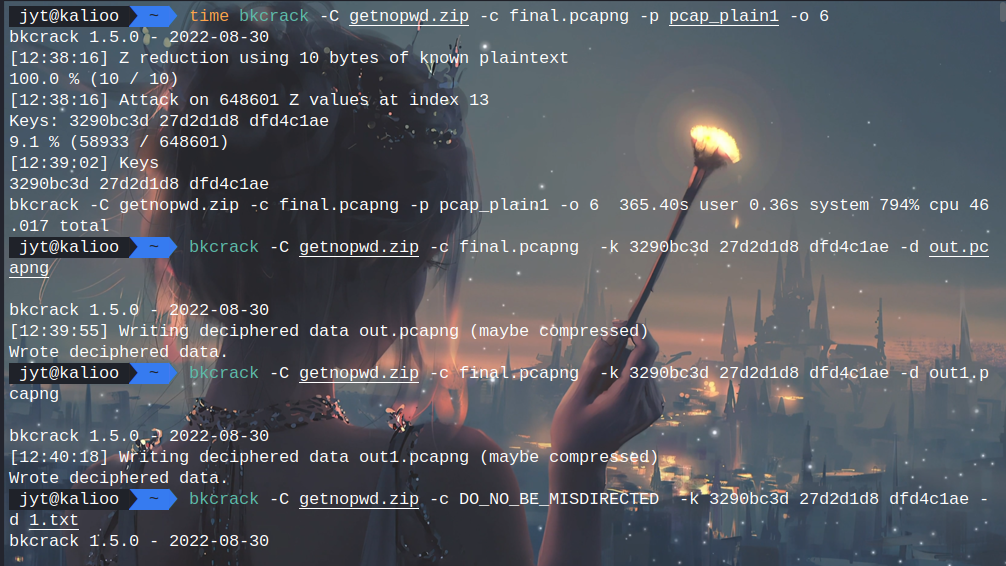
DO_NO_BE_MISDIRECTED是个docx文件,少了个文件头,随便找个docx文件头复制过来修一下
啥也不是

流量包是wacom的数位板流量
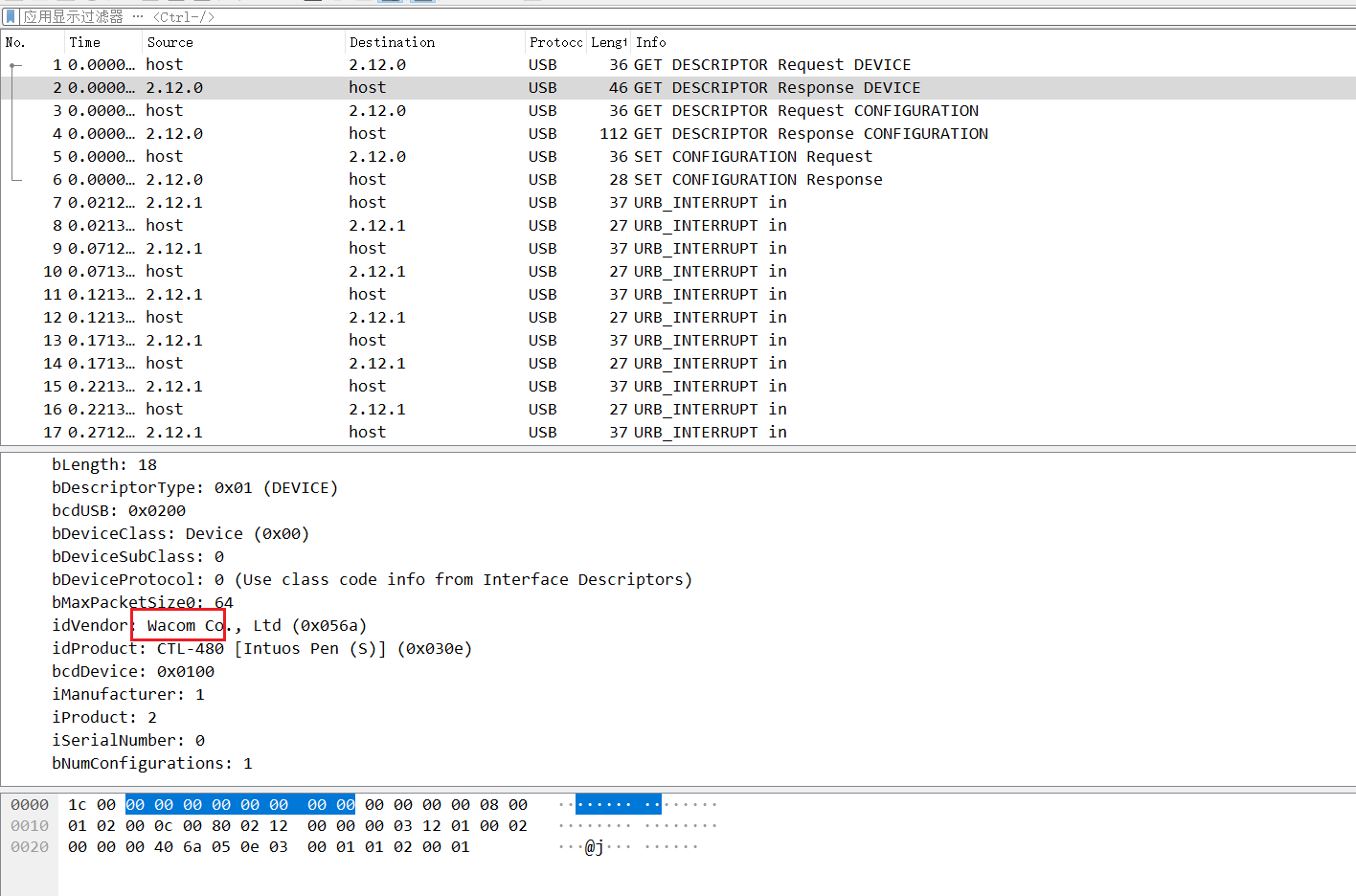
tshark提取一下
tshark -r keyboard.pcapng -T fields -e usbhid.data | sed '/^\s*$/d' > usbdata.txt
数位板流量的分析可以参考一下zys的博客数位板流量分析探索 - zysgmzb - 博客园 (cnblogs.com)
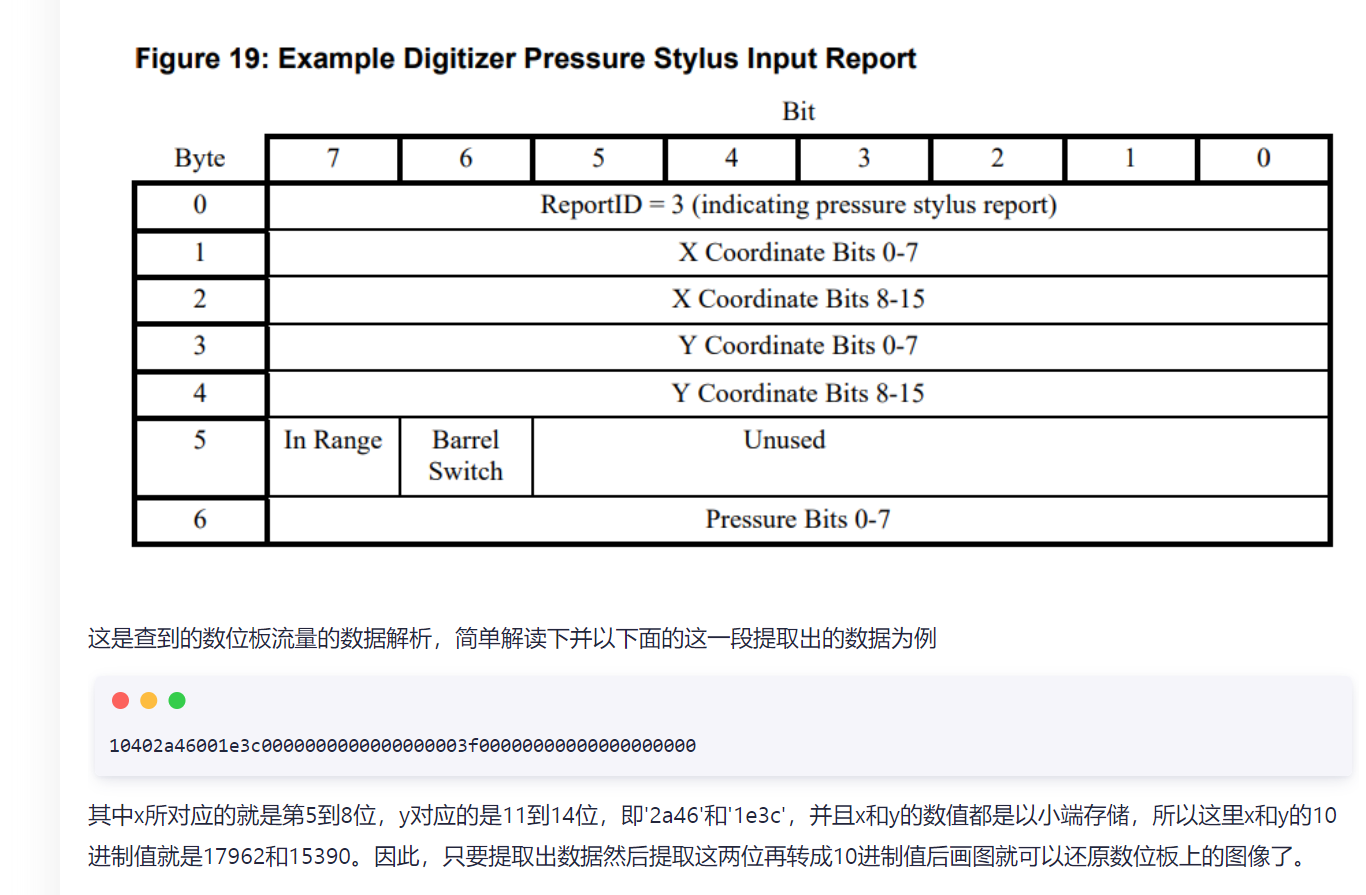
当然可能由于版本的不同,直接套用脚本是不太行的
这里观察一下usb的数据可以发现,主要改变的数据是第5-12位,猜测5-8对应x,9-12对应y

import os
import matplotlib.pyplot as plt
data=[]
lines=[]
line=[]withopen('usbdata.txt',"r")as f:for i in f.readlines():if i!='\n':
lines.append(i.strip('\n'))
X =[]
Y =[]for i in lines:# print(i)
x0=int(i[4:6],16)
x1=int(i[6:8],16)
x=x0+x1*256
y0=int(i[8:10],16)
y1=int(i[10:12],16)
y=y0+y1*256
X.append(x)
Y.append(-y)
fig = plt.figure()
ax1 = fig.add_subplot(111)
ax1.set_title("result")
ax1.scatter(X, Y, c='b', marker='o')
plt.show()
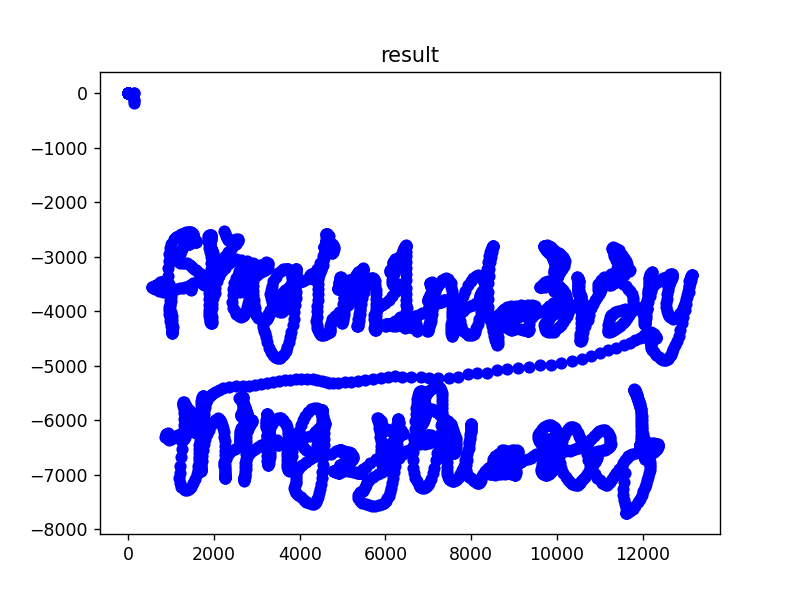
有些冗余数据,要清理一下,由于没找到具体的开发文档,就手动多次尝试后发现前四位为02f1是所需数据
import os
import matplotlib.pyplot as plt
data=[]
lines=[]
line=[]withopen('usbdata.txt',"r")as f:for i in f.readlines():if i!='\n':
lines.append(i.strip('\n'))for i in lines:if i[0:4]=="02f1":
data.append(i)print(data)
X =[]
Y =[]for i in data:# print(i)
x0=int(i[4:6],16)
x1=int(i[6:8],16)
x=x0+x1*256
y0=int(i[8:10],16)
y1=int(i[10:12],16)
y=y0+y1*256
X.append(x)
Y.append(-y)
fig = plt.figure()
ax1 = fig.add_subplot(111)
ax1.set_title("result")
ax1.scatter(X, Y, c='b', marker='o')
plt.show()
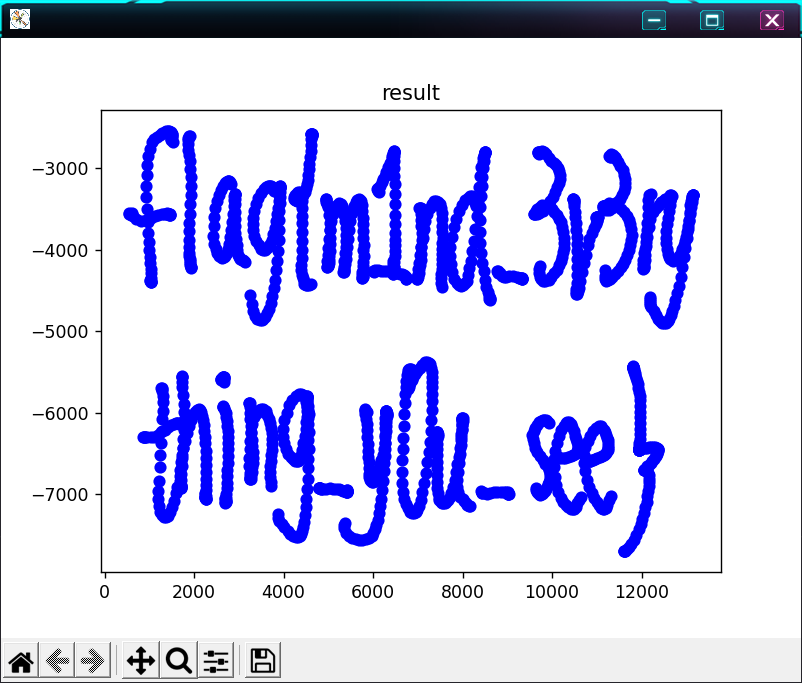
t3stify
根据提示

audacity分别将左右声道分离出来后根据音量差得到新的wav文件(原始数据)
- [::-1]是因为wav是little-endian格式
- [:2]切片是因为用audacity提取的单声道对应的另一个声道的数据为0x00
- 由于计算的是wav的原始数据差,wav文件头需要去掉
fl =open('l','rb')
fr =open('r','rb')len=31163904//4
data =[]for i inrange(len):
ll = fl.read(4)[:2][::-1]
rr = fr.read(4)[2:][::-1]if ll !=b'':
numl =int(bytes.hex(ll),16)
numr =int(bytes.hex(rr),16)print(numl-numr)
data.append(abs(numl-numr))withopen('all','wb')as f:for j in data:
f.write(bytes.fromhex(hex(j)[2:].zfill(4))[::-1])
f.close()
原始数据导入audacity
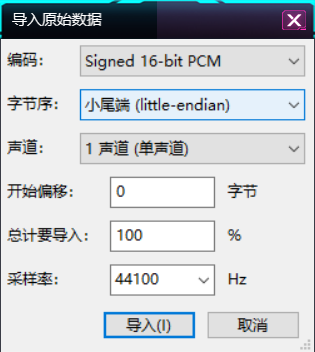
中间可以找到一段摩斯,解得ARCAEA1F1E33

作为deepsound的key
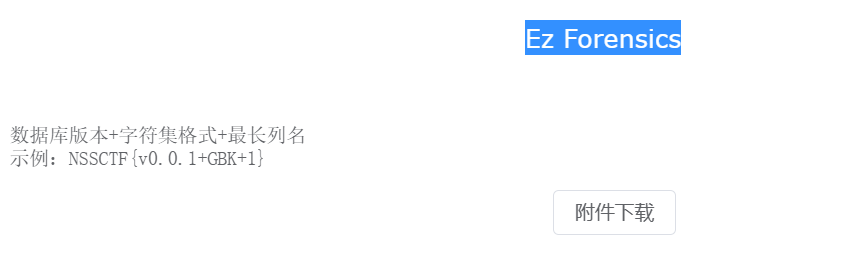
Ez Forensics
mysql的数据库文件被分别打包在四个压缩包里了,提取压缩包的过程就不讲了,拿取证软件直接一把梭,或者diskgenius挂载一下,文件系统硬翻或者搜就好了,其中3.zip被删除了,但可以在mysql.exe(是个zip)里面找到
而后根据mysql的数据库文件格式frm,MYD,MYI,opt,用file命令对比一下
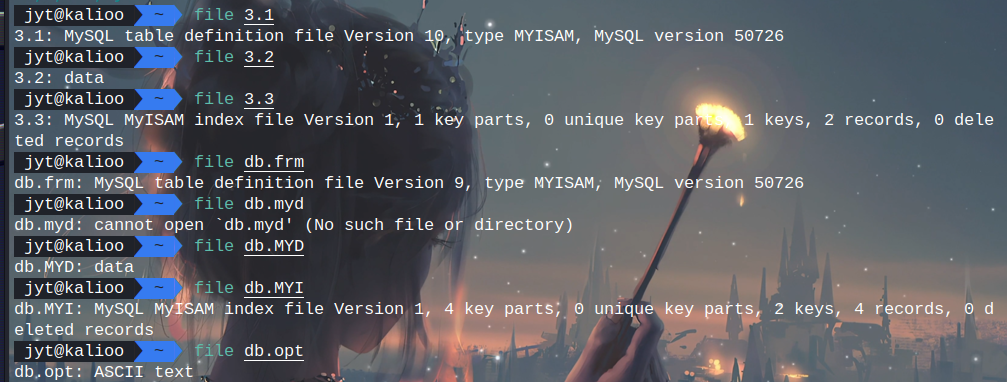
可以看出后缀.1是frm文件,.2是MYD文件,.3是MYI文件,只要将后缀更改之后,放到软件里即可正确识别mysql表,我这里用火眼自带的数据库分析软件,用DB Browser for SQLite或者navicat也完全可以的
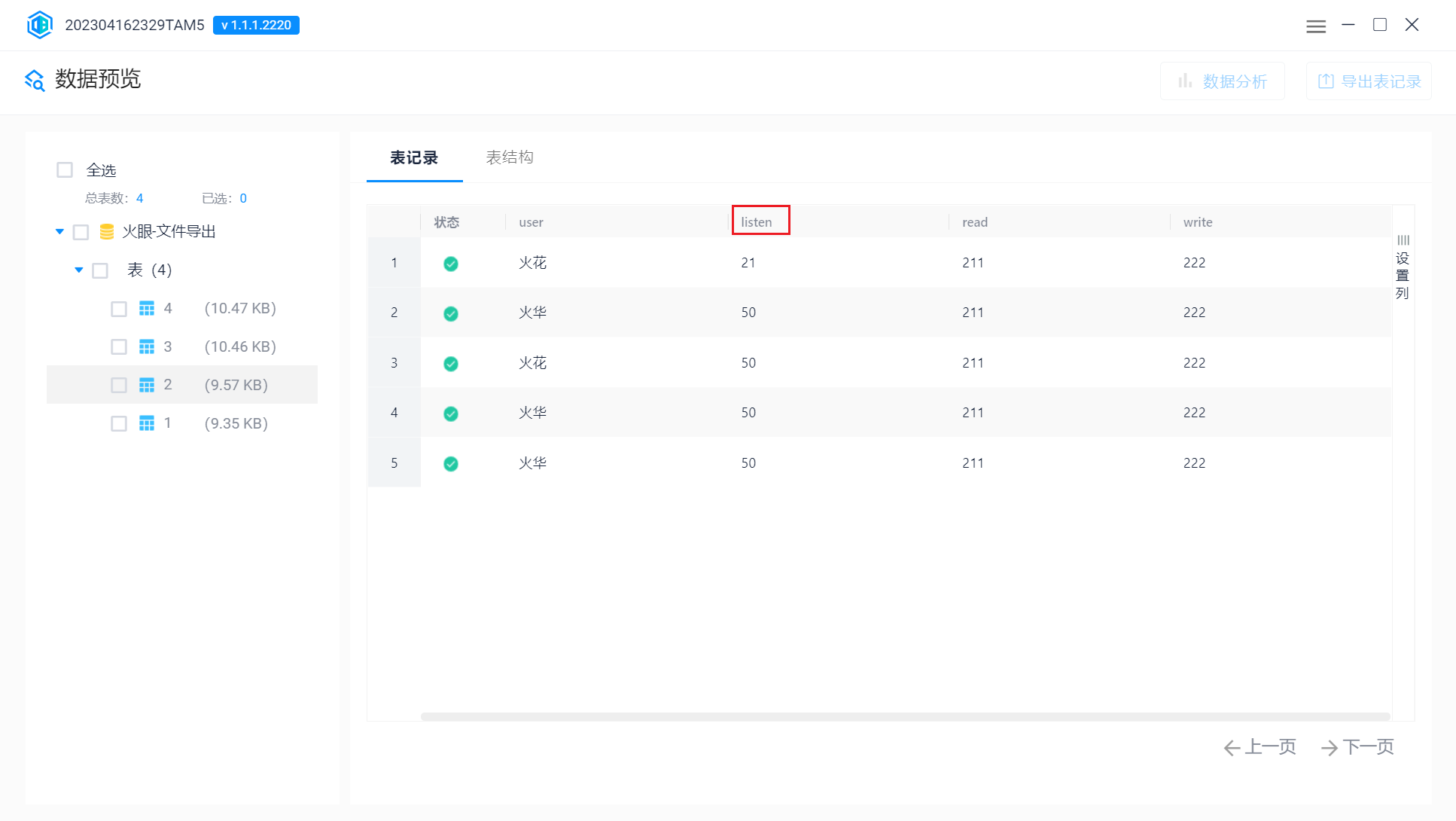
最长列名
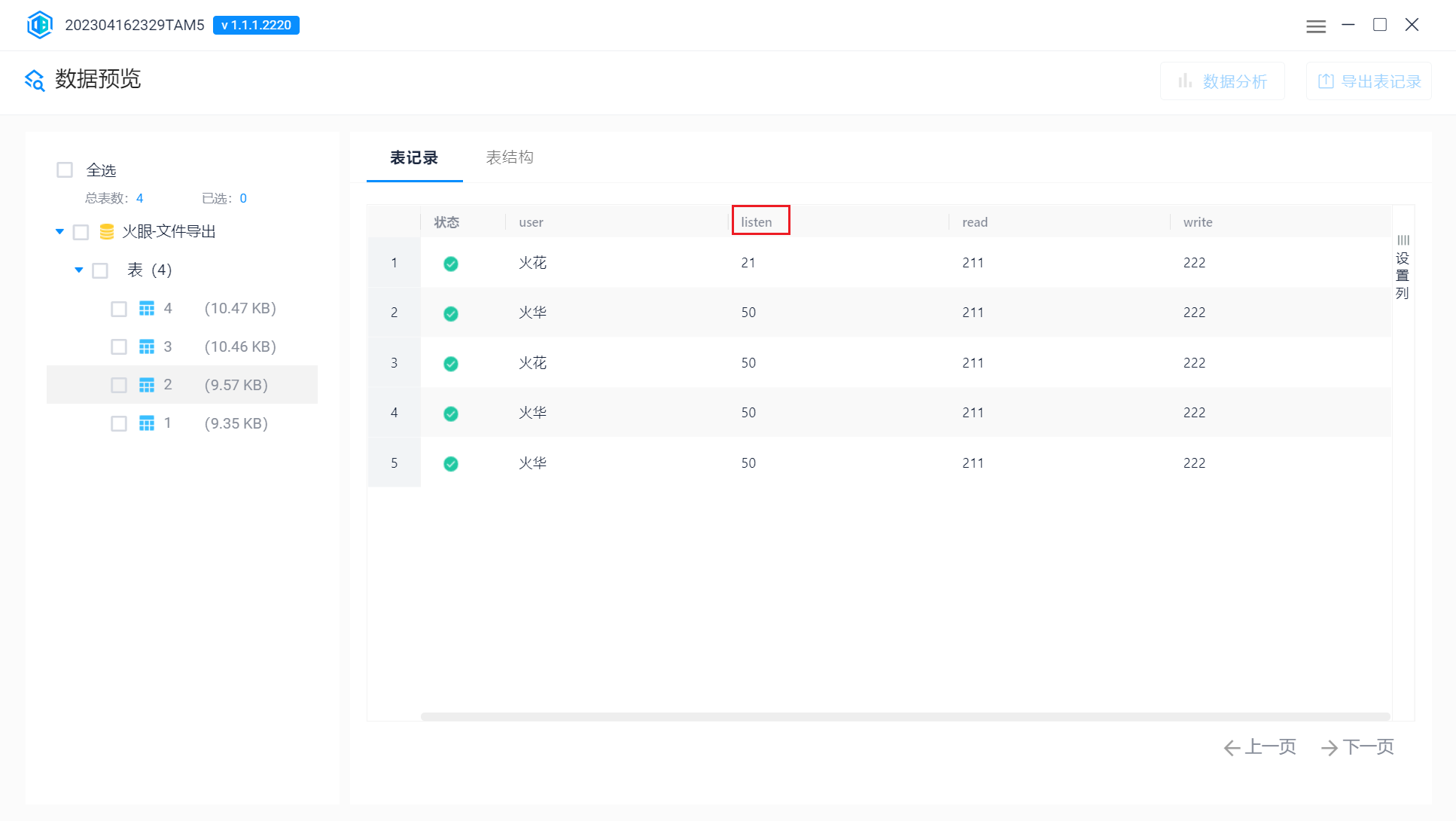
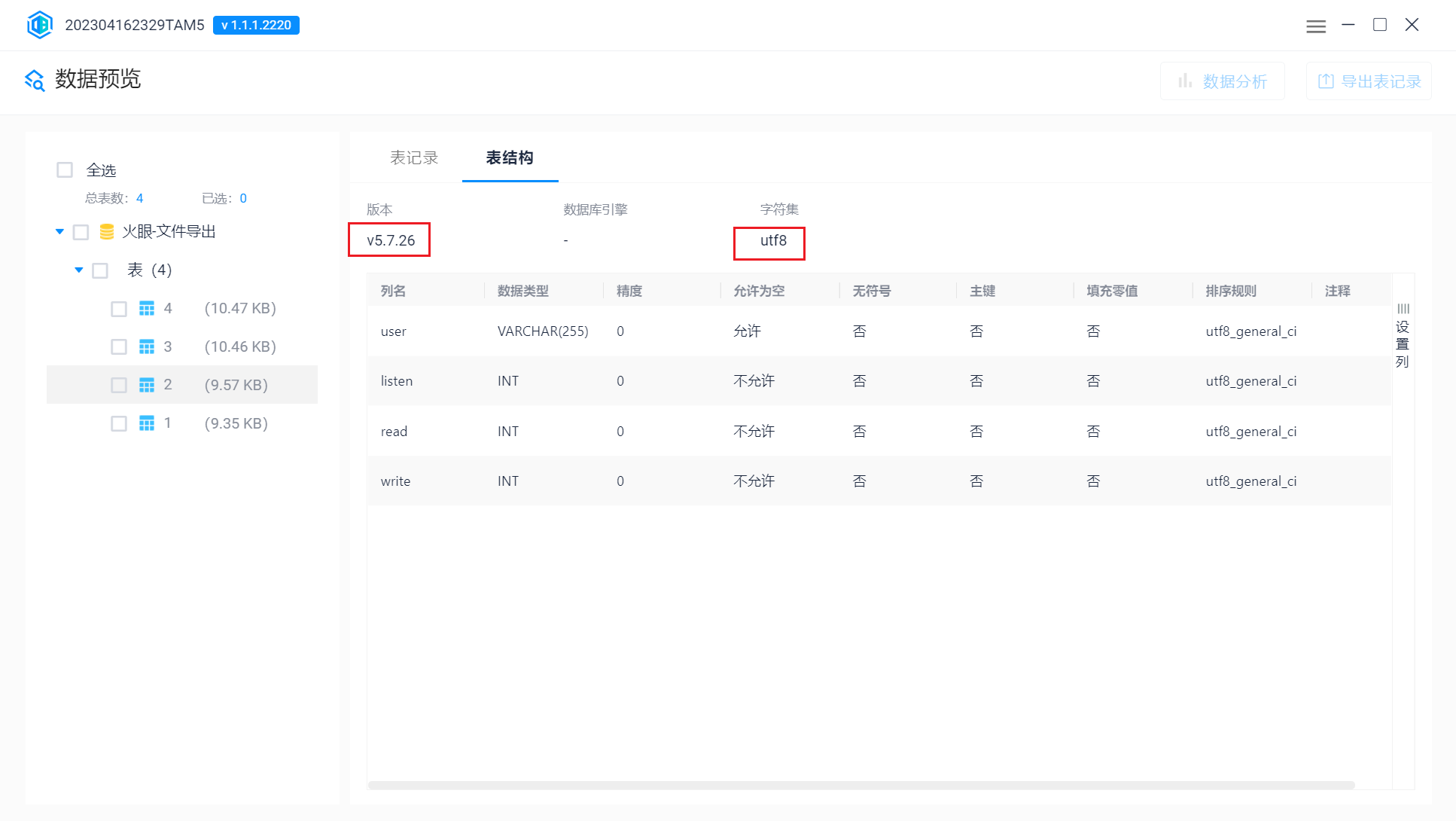
版本和字符集,字符集要改成UTF-8
件搜就好了,其中3.zip被删除了,但可以在mysql.exe(是个zip)里面找到
而后根据mysql的数据库文件格式frm,MYD,MYI,opt,用file命令对比一下
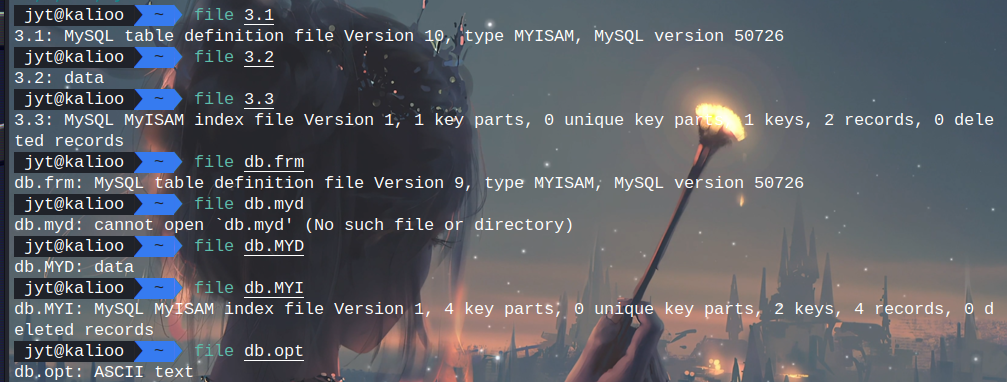
可以看出后缀.1是frm文件,.2是MYD文件,.3是MYI文件,只要将后缀更改之后,放到软件里即可正确识别mysql表,我这里用火眼自带的数据库分析软件
最长列名
版本和字符集,字符集要改成UTF-8
版权归原作者 是toto 所有, 如有侵权,请联系我们删除。