
基础知识
匹配算法:
- SORT算法: Kalman滤波, 匈牙利算法(匹配算法), 马氏距离(损失指标);
- Kalman滤波是通过对上一帧每个检测对象进行预测,得到一个BBox_predicted,然后再将predicted与当前帧的检测对象BBox_measure进行匹配,这样的话就能固定ID了; 如果不用Kalman滤波,将当前帧的BBox_measure与上一帧的BBox_measure’进行匹配?
追踪为什么需要卡尔曼滤波?
通常要对一些事物的状态去做估计,为什么要做估计呢?因为我们通常无法精确的知道物体当前的状态。为了估计一个事物的状态,我们往往会去测量它,但是我们不能完全相信我们的测量,因为我们的测量是不精准的,它往往会存在一定的噪声,这个时候我们就要去估计我们的状态。卡尔曼滤波就是一种结合预测(先验分布)和测量更新(似然)的状态估计算法;其二,若出现视频中目标运动过快,前后两帧中同一个目标运动距离很远,那么这种直接匹配的方式就会失效。因此,可以通过现预测目标下一帧出现的位置,然后与检测的位置进行匹配关联,这样就不会由于速度太快而产生误差。 参考1
匈牙利算法
匈牙利算法只是尽可能地多匹配,而对于准确度没有很好的约束;
马氏距离
欧式距离是度量两点间的距离方法,而马氏距离针对的是多变量情况下的协方差距离。
即当量纲不同,考虑各种特性之间的联系下的一种距离尺度。由公式可知,欧式距离除以了一个协方差距离。
- 方差:方差是标准差的平方,而标准差的意义是数据集中各个点到均值点距离的平均值。反应的是数据的离散程度。
- 协方差: 标准差与方差是描述一维数据的,当存在多维数据时,我们通常需要知道每个维数的变量中间是否存在关联。协方差就是衡量多维数据集中,变量之间相关性的统计量。比如说,一个人的身高与他的体重的关系,这就需要用协方差来衡量。如果两个变量之间的协方差为正值,则这两个变量之间存在正相关,若为负值,则为负相关。
- 协方差矩阵: 当变量多了,超过两个变量了。那么,就用协方差矩阵来衡量这么多变量之间的相关性。
余弦距离
余弦相似度的取值范围是[-1,1],相同两个向量的之间的相似度为1。
余弦相似度定义公式:
c
o
s
(
A
,
B
)
=
A
⋅
B
∥
A
∥
2
∥
B
∥
2
cos(A,B) = \frac{A\cdot{B}}{\lVert{A}\rVert_2\lVert{B}\rVert}_2
cos(A,B)=∥A∥2∥B∥A⋅B2
余弦距离定义:
d
i
s
t
(
A
,
B
)
=
1
−
c
o
s
(
A
,
B
)
=
∥
A
∥
2
∥
B
∥
2
−
A
⋅
B
∥
A
∥
2
∥
B
∥
2
dist(A,B) = 1 - cos(A,B) = \frac{{\lVert{A}\rVert_2\lVert{B}\rVert_2}-A\cdot{B}}{\lVert{A}\rVert_2\lVert{B}\rVert_2}
dist(A,B)=1−cos(A,B)=∥A∥2∥B∥2∥A∥2∥B∥2−A⋅B
DeepSORT
SORT
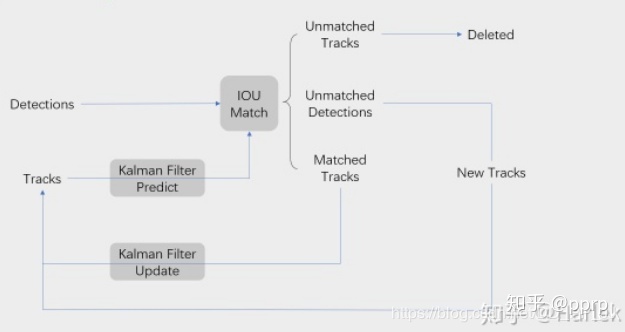
SORT算法是通过检测的测量值和卡尔曼滤波得到的预测值进行IOU匹配。
对于没有匹配到的detections,创建新的trackers;
对于成功匹配的detections,对kalman的trackers进行更新;
对于未成功匹配的trackers,则进行剔除。
DeepSORT
algorithm base
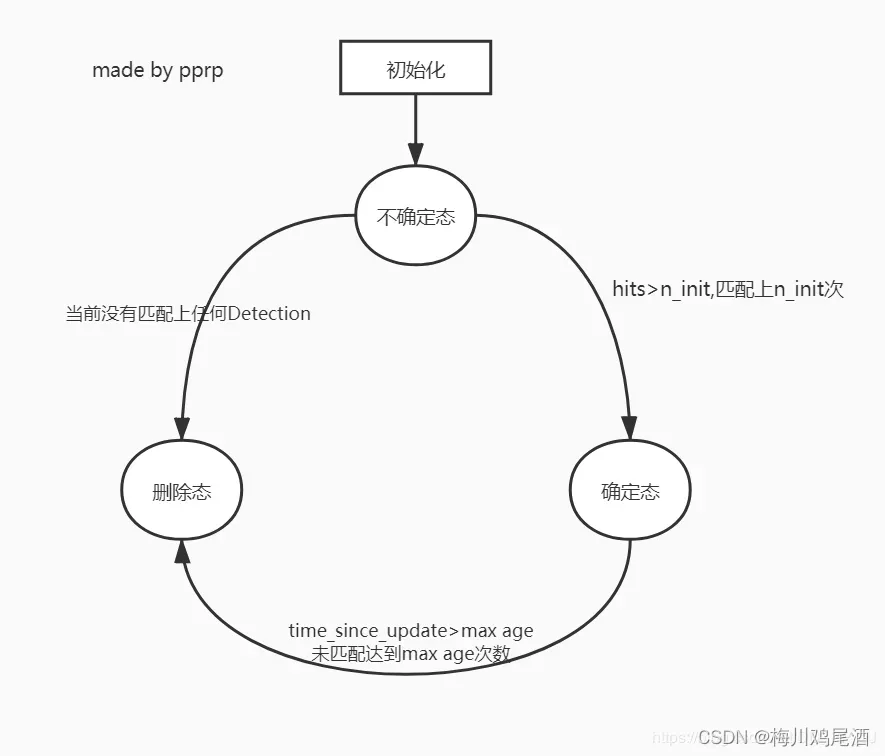
- 对于每个tacker,有三种状态,分别是tentative,confirmed, unconfirmed;其中,第一种状态为每个tacker的初始化状态;
- tentative转换为confirmed状态,需要连续匹配上n_init次;
- 对于每一个tracker,有time_since_update参数,每次与detection关联更新后重置为0;
- 级联匹配根据time_since_update来作为优先级,先匹配那些一直得到更新的tracker,对于状态为confirmed,但没有得到更新的tracker(tracker每predict一次,time_since_update增加一次),也能使之得到更新,只是优先级靠后;即根据time_since_update参数来控制更新的顺序。由小到达对消失时间相同的轨迹进行匹配。
- 当time_since_update>max_age(70)时,则将confirmed状态改变为deleted状态;
- unconfirmed trackers和 unmatched trackers 一起组成iou candicates,与unmatched detections进行IOU匹配;
cost matrix
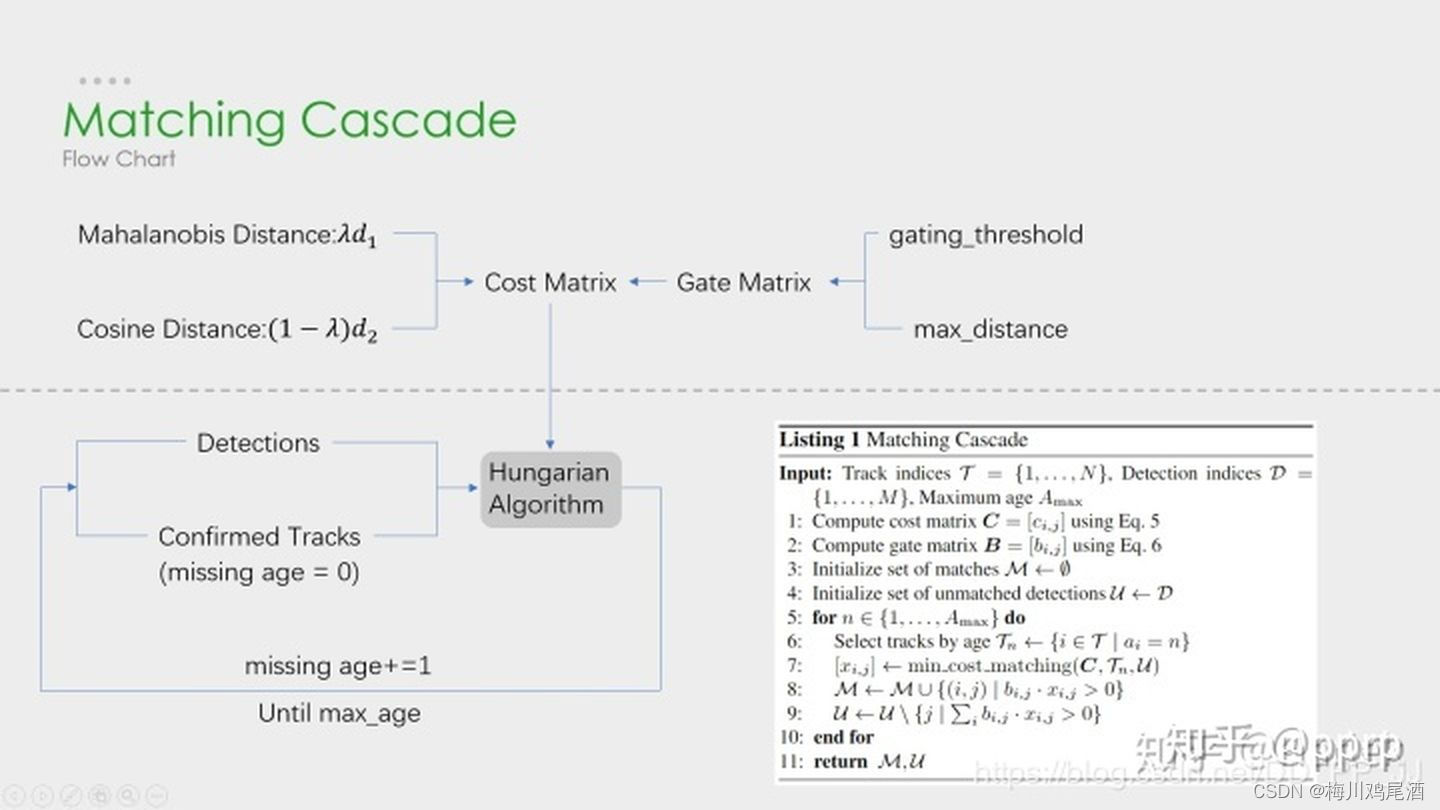
- 使用平方马氏距离来度量tracker和detection之间的距离;实际代码中没有用到运动信息(保留)
- 使用cosine距离来度量表观特征之间的距离;
- 综合匹配度通过运动模型和外观模型加权得到。
其中
λ \lambda λ是一个超参数,在代码中默认为0。作者认为在摄像头有实质性移动的时候这样设置比较合适,也就是在关联矩阵中只使用外观模型进行计算。但并不是说马氏距离在Deep SORT中毫无用处,马氏距离会对外观模型得到的距离矩阵进行限制,忽视掉明显不可行的分配。
Mahalanobis Distance/Cosine Distance
两者分别针对运动信息和外观信息的计算。马氏距离就是加强版的欧式距离。它实际上是规避了欧氏距离中对于数据特征方差不同的风险,在计算中添加了协方差矩阵,其目的就是进行方差归一化,从而使所谓的“距离”更加符合数据特征以及实际意义。马氏距离是对于差异度的衡量中,的一种距离度量方式,而不同于马氏距离,余弦距离则是一种相似度度量方式。前者是针对于位置进行区分,而后者则是针对于方向。换句话说,我们使用余弦距离的时候,可以用来衡量不同个体在维度之间的差异,而一个个体中,维度与维度的差异我们却不好判断,此时我们可以使用马氏距离进行弥补,从而在整体上可以达到一个相对于全面的差异性衡量。而我们之所以要进行差异性衡量,根本目的也是想比较检测器与跟踪器的相似程度,优化度量方式,也可以更好地完成匹配。
代码在
linear_assaignment._match.gated_metric
下,将外观余弦距离和马氏距离进行了封装。(保留意见)。
Cascaded match
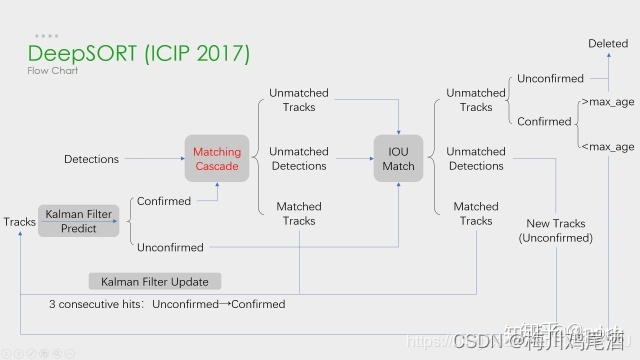
级联匹配是Deep SORT区别于SORT的一个核心算法,致力于解决目标被长时间遮挡的情况。为了让当前Detection匹配上当前时刻较近的Track,匹配的时候Detection优先匹配消失时间较短的Track。
当目标被长时间遮挡,之后卡尔曼滤波预测结果将增加非常大的不确定性(因为在被遮挡这段时间没有观测对象来调整,所以不确定性会增加), 状态空间内的可观察性就会大大降低。在两个Track竞争同一个Detection的时候,消失时间更长的Track往往匹配得到的马氏距离更小, 使得Detection更可能和遮挡时间较长的Track相关联,这种情况会破坏一个Track的持续性,这也就是SORT中ID Switch太高的原因之一。
使用级联匹配算法,是为每个追踪器设定一个
time_since_update参数。如果跟踪器完成匹配并进行更新,那么参数会重置为0,否则就会+1。实际上,级联匹配换句话说就是不同优先级的匹配。在级联匹配中,会根据这个参数来对跟踪器分先后顺序,参数小的先来匹配,参数大的后匹配。也就是给上一帧最先匹配的跟踪器高的优先权,给好几帧都没匹配上的跟踪器降低优先权(慢慢放弃)。
在级联匹配中,通过根据每个tracker的time_since_update是否等于max_age level来控制track更新的顺序;即有限匹配距上次出现间隔短的目标;
IOU match
在级联匹配后的IOU匹配中,更新对象是unmatch_trackers和unconfirmed trakcers,且since_time_update=1,即仅仅对上一帧的tracker进行iou匹配;
现在处理上面未参与外观匹配的新的轨迹,即uncofirmed tracks,同时把那些虽然是confirmed track,但外观匹配仅在上一帧没有成功的track放进来;那些长时间没有被匹配成功的track不用iou匹配,因为长时间没有匹配到,人早就走掉了,iou重合率也会非常低,iou比较高的也不太可能是同一个人.
Steps
说明:在deep sort代码中,
tracker.py
主要是匹配算法;
track
为每一个tracker的类属性声明;
- 检测器得到每一帧的检测结果,生成detections;
- 对
self.tracks()进行卡尔曼滤波预测,self.tracks()存放的是状态为confirmed的track;第一帧为空; - 接着进行匹配,匹配对象为
self.tracks()和detection,先进行级联匹配,然后对 - 基于当前帧的detections,校正与其关联的上一帧trackers的状态,得到一个更精确的结果,即使用卡尔曼滤波预测前一帧中的tracks在当前帧的状态:;
- 将预测后的trakers与当前帧的detecion进行匹配:级联匹配和IOU匹配;IOU匹配对象为级联匹配结束后的
unmatched_tracks和self.tracks()中未确定的track(确定状态需要连续n_init帧匹配成功);初始帧为空; - 将匹配结果进行整理,匹配成功(matchs)的卡尔曼更新,匹配未成功的(unmatched_tracks)进行标记删除;对于剩下下的detections(unmatched_detections)进行track初始化,即生成track,并加入到
self.tracks()中,但状态依然为tentative; - 接着开始第二帧,同理。
总而言之,DeepSORT的级联匹配主要是为了解决SORT算法中,对于长时间遮挡目标IDs较高的问题;因为SORT匹配原则是基于IOU;而级联匹配就是根据特征的余弦距离,然后经过马氏距离进行门限,根据since_time_update的数目来进行级联匹配,也就是说,除了优先考虑最近一帧的tracker,还考虑之前帧的tracker,而这个值最大默认设置为30;然后再将没有匹配成功的tracker和detections进行IOU匹配。
代码
min_cost_matching
: 根据不同度量尺寸来计算cost_matrix, 然后调用linear_assignment()来进行匈牙利匹配算法;distance_metric是度量函数,为余弦距离函数或IOU距离函数;
参考:
多目标跟踪DeepSORT
Deep SORT多目标跟踪算法代码解析(上) - 知乎 (zhihu.com)
分步解析deepsort代码
马氏距离与欧氏距离
*多目标跟踪入门篇(1):SORT算法详解
DeepSort论文阅读总结
DeepSORT多目标算法笔记
SORT 多目标跟踪算法笔记
匈牙利算法
ByteTrack
在byte之前, 利用上游检测结果送入卡尔曼滤波进行融合处理;在对于遮挡的情况下,检测结果置信度较低, 会直接排除不进行后者的滤波;
而byte认为, 遮挡只是短期的,在目标检测中丢弃置信度的结果无可厚非;但是在追踪中,这就是先验信息,仅凭置信度阈值就丢弃显得不够合理;

以上图举例的话,这里我们假设把阈值设置为0.3,在第一帧和第二帧中都可以将图片中的三个行人正确识别,但当第三帧中出现了遮挡现象,其中一个行人的置信度则变为0.1,这样这个行人则会在遮挡的情况下,失去了跟踪信息,但对与目标检测来说,他确实被检测出来了,只是置信度较低而已。
Byte算法则是用来解决如何充分利用,由于遮挡导致置信度变低的得分框问题。
同时ByteTrack没有用到ReID模型, 作者解释是因为第一点是为了尽可能做到简单高速,第二点是发现在检测结果足够好的情况下,卡尔曼滤波的预测准确性非常高,能够代替 ReID 进行物体间的长时刻关联。实验中也发现加入 ReID 对跟踪结果没有提升。
ref:
多目标跟踪(三) ByteTrack —— 利用低分检测框信息Byte算法
目标跟踪之 MOT 经典算法:ByteTrack 算法原理以及多类别跟踪
匹配流程
bytetrak匹配流程如下:
- 将高置信度的检测结果与confirmed tracked_stracks进行匹配,得到matches,u_track, u_detections;
- 将低置信度的检测结果second_detections与第一步得到u_track且状态为Tracked的tracker进行IOU匹配,得到新的matches,u_track,u_detections_second; 因为只有之前确定的tracker与低置信度的结果匹配才有意义;
- 将第一步的高置信度的u_detecions与unconfirmed tracks进行匹配,得到最终的matches, u_unconfirmed, u_detection;对于此步得到的u_detetion进行track初始化;u_track进行mark lost处理; 这一步不同于deepsort需要连续几帧(3)匹配才能将状态从unconfirm状态转换为confirm状态,而是直接使用IOU匹配;如果能匹配上,则是confirmed,否则直接进行track初始化;
- unconfirmed track状态都是Tracked, 但是不一定全部都是is_activated;当frame-id不是第一帧时, tracker不是activated;所以对于中途新建的tracker, 默认状态都是unconfirmed, unconfirmed筛选如下:
for track in self.tracked_stracks:ifnot track.is_activated: unconfirmed.append(track)else: tracked_stracks.append(track)
版权归原作者 梅川鸡尾酒 所有, 如有侵权,请联系我们删除。