
1. TensorRT及其工作流程介绍
TensorRT基本介绍
TensorRT是可以在NVIDIA各种GPU硬件平台下运行的一个C++推理框架。我们利用Pytorch、TF或者其他框架训练好的模型,可以转化为TensorRT的格式,然后利用TensorRT推理引擎去运行我们这个模型,从而提升这个模型在英伟达GPU上运行的速度。速度提升的比例是比较可观的。
- 高性能深度学习推理 优化器和加速库;
- 低延迟和高吞吐量;
- 部署到超大规模数据中心、嵌入式或汽车产品。

TensorRT是由C++、CUDA、python三种语言编写成的一个库,其中核心代码为C++和CUDA,Python端作为前端与用户交互。当然,TensorRT也是支持C++前端的,如果我们追求高性能,C++前端调用TensorRT是必不可少的。
下面是网上有人总结的具体TensorRT的加速效果:
- SSD检测模型,加速3倍(Caffe)
- CenterNet检测模型,加速3-5倍(Pytorch)
- LSTM、Transformer(细op),加速0.5倍-1倍(TensorFlow)
- resnet系列的分类模型,加速3倍左右(Keras)
- GAN、分割模型系列比较大的模型,加速7-20倍左右(Pytorch)
TensorRT工作流程
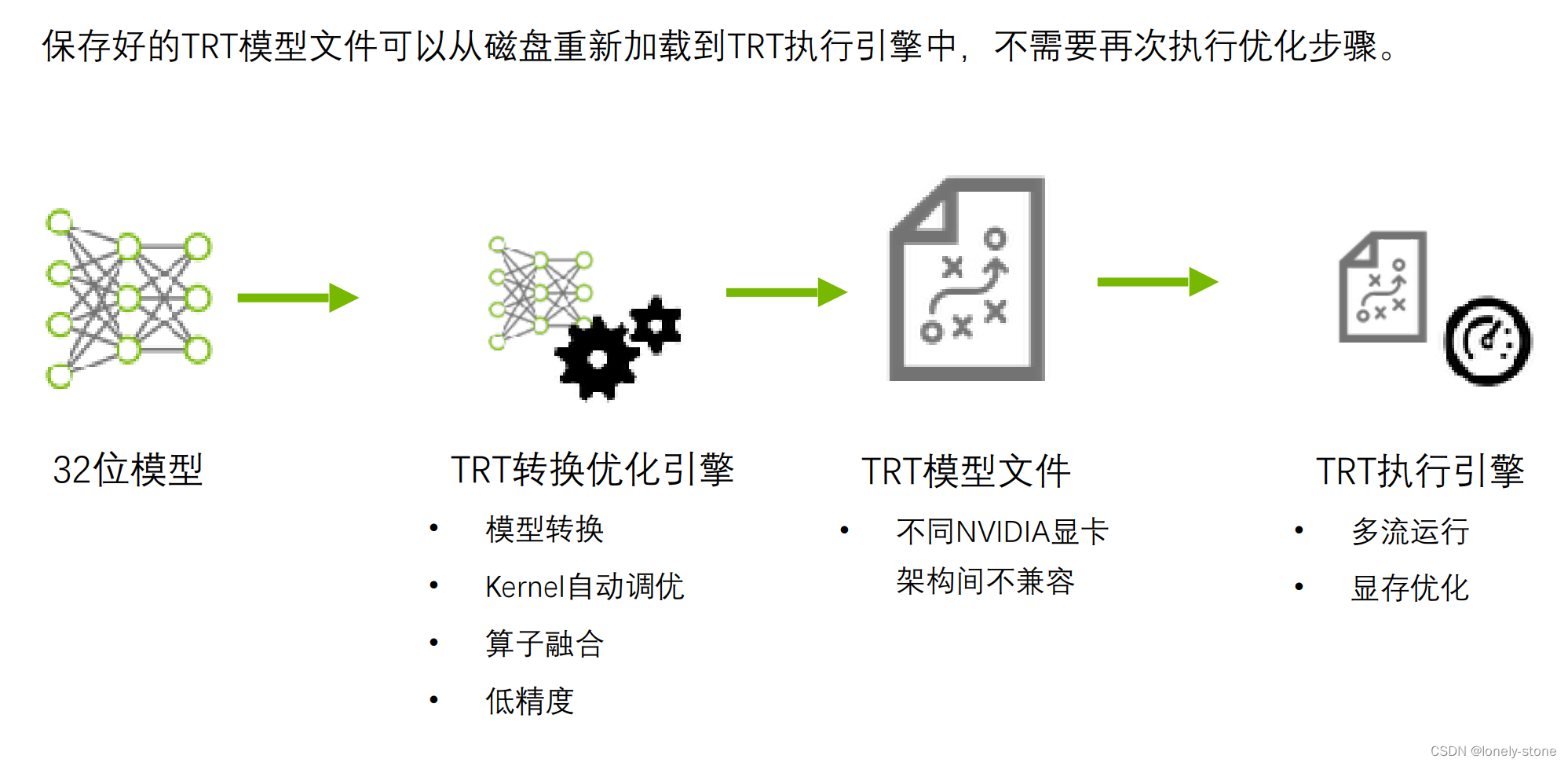
训练框架得到的模型通过第二步的一系列转换优化,得到一个序列存下来,然后实际线上运行的时候再通过反序列出TRT的engine模型进行运行。
第二步中TensorRT优化策略介绍
- 算子融合(层与张量融合):简单来说就是通过融合一些计算op或者去掉一些多余op来减少数据流通次数以及显存的频繁使用来提速
- 量化:量化即IN8量化或者FP16以及TF32等不同于常规FP32精度的使用,这些精度可以显著提升模型执行速度并且不会保持原先模型的精度
- 内核自动调整:根据不同的显卡构架、SM数量、内核频率等(例如1080TI和2080TI),选择不同的优化策略以及计算方式,寻找最合适当前构架的计算方式
- 动态张量显存:我们都知道,显存的开辟和释放是比较耗时的,通过调整一些策略可以减少模型中这些操作的次数,从而可以减少模型运行的时间
- 多流执行:使用CUDA中的stream技术,最大化实现并行操作
TensorRT基本使用流程
- 创建Builder
- 创建Network
- 使用API or Parser 构建network
- 优化网络
- 序列化和反序列化模型
- 传输计算数据(host->device)
- 执行计算
- 传输计算结果(device->host)
其中1–4属于上面的第二步,6–8属于第四步,下面是具体的代码过程:
然后具体的代码案例可到其开源代码中的sample文件夹中进行查看。
2. 进阶:Dynamic Shape模式介绍
TRT 6.0 版本之前,只支持固定大小输入。
implicit(隐式) batch
Build 阶段设置:
IBuilder:: createNetwork();
IBuilder:: setMaxBatchSize(maxBatchSize);
(这里面的maxBatchSize根据显卡显存确定)
Infer阶段:
enqueue(batchSize, data, stream, nullptr);
(在infer阶段batchSize不必对应上面的maxBatchSize,可以是具体运行中的batch)
TRT6.0 后,支持动态大小输入。
explicit(显式) batch
Build 阶段设置:
IBuilder::createNetworkV2(1U <<
static_cast(NetworkDefinitionCreationFlag::kEXPLICIT_BATCH))
builder->setMaxBatchSize(maxBatchSize);
(以上几步没有变化)
IOptimizationProfile* profile = builder.createOptimizationProfile();
profile->setDimensions(“foo”, OptProfileSelector::kMIN, Dims3(3,100,200); // 运行中使用到的最小batch
profile->setDimensions(“foo”, OptProfileSelector::kOPT, Dims3(3,150,250); // 运行中最多使用的batch
profile->setDimensions(“foo”, OptProfileSelector::kMAX, Dims3(3,200,300); // 运行中使用到的最大batch
config.addOptimizationProfile(profile)
context.setOptimizationProfile(0)
Infer阶段:
context->setBindingDimensions(i, input_dim);
context->allInputDimensionsSpecified();
context->enqueueV2(data, stream, nullptr);
3. TensorRT模型转换
ONNX :https://github.com/NVIDIA/TensorRT/tree/main/parsers
Pytorch:https://github.com/NVIDIA-AI-IOT/torch2trt
对于pytorch还可以通过pytorch->onnx->TRT
TensorFlow:
https://github.com/tensorflow/tensorflow/tree/1cca70b80504474402215d2a4e55bc44621
b691d/tensorflow/compiler/tf2tensorrt
Tencent Forward:https://github.com/Tencent/Forward
版权归原作者 lonely-stone 所有, 如有侵权,请联系我们删除。