
文章目录
前言
去年年末,ChatGPT以惊人的速度成为焦点,激起了中国科技界和创投领域的热情,吸引了众多人的关注。互联网巨头纷纷投资支持,科技公司竞相争锋,创业公司亦不甘示弱。甚至与AI毫不相关的企业也借机营销,从而获得股价上涨。
几个月后的今天,我们回顾这场风潮,发现大部分人只是炒作和追逐热点,真正投身于实践和创新的人寥寥无几。目前在全球科技巨头中,百度成为首个站出来的企业。在过去几年的国际科技竞争背景下,尤其是最近各种外部技术封锁,科技自立自强已成为全民共识。因此,当ChatGPT横扫中国舆论市场时,国人殷切期待国内开发者能研发出类似产品与之竞争。前几天OpenAI公开GPT-4,官网公开的demo,让诸多开发者或者相关人员叹为观止!GPT-4相较于ChatGPT性能得到巨大提升,这个结果也让大家更加期待文心一言的发布会!
3月16日发布会上,百度如期推出基于大语言模型的生成式AI产品“文心一言”!首批用户可通过邀请码在官网体验产品,这边分别是是个人申请通道、企业申请渠道。百度计划逐步向更多用户开放,企业客户可通过API接口调用服务,申请接入并体验文心一言的能力。不得不说这是激动人心的发布会,无论文心一言能力好坏,就冲百度这份魄力,就配的上"国货之光"这个称号!
本篇博文,我就带大家走进文心一言,了解文心一言所具备的能力,以及文心一言项目背后所不为人知的一些细节。如果对AIGC&ChatGPT感兴趣的同学,可以私信拉你进交流群,也可以访问github了解些基础信息.
一、文心一言是什么
进入文心一言官网,我们可以看到有这样的介绍:文心一言 知识增强大语言模型 百度全新一代知识增强大语言模型,文心大模型家族的新成员,能够与人对话互动,回答问题,协助创作,高效便捷地帮助人们获取信息、知识和灵感。
文心一言基于飞桨深度学习平台和文心知识增强大模型,持续从海量数据和大规模知识中融合学习具备知识增强、检索增强和对话增强的技术特色。文心一言可以写一篇太空旅行的市场分析报告、帮用户画一枝晶莹剔透的牡丹花、回答“曾国藩和林则徐相差几岁、为什么太阳系中,水星和金星没有卫星、量子计算机能帮我们移民火星吗?”等问题。
二、发布会内容
在发布会中,百度创始人、董事长兼首席执行官李彦宏现场从文学创作、商业文案创作、数理推算、中文理解和多模态生成能力五个场景中给大家展示了文心一言的强大能力,虽然没有现场演示,只是播放的Demo,但是从Demo中我们可以看出来,在文学创作、商业文案创作、数理推算等大语言模型较常见的优势和能力中基本对标ChatGPT,同时在中文理解、多模态生成能力上更具特色。
1.文学创作
在文学创作领域中,文心一言能够根据提出的问题对著名科幻小说《三体》的核心内容进行概括,并为续写《三体》提供了五个独特的视角,展现出其在对话问答、分析总结以及内容生成方面的全面实力。当面对有关《三体》电视剧演员于和伟与张鲁一的问题,如“他们有哪些相似之处?”和“谁更高?”时,文心一言同样凭借其推理能力给出了精确的答案。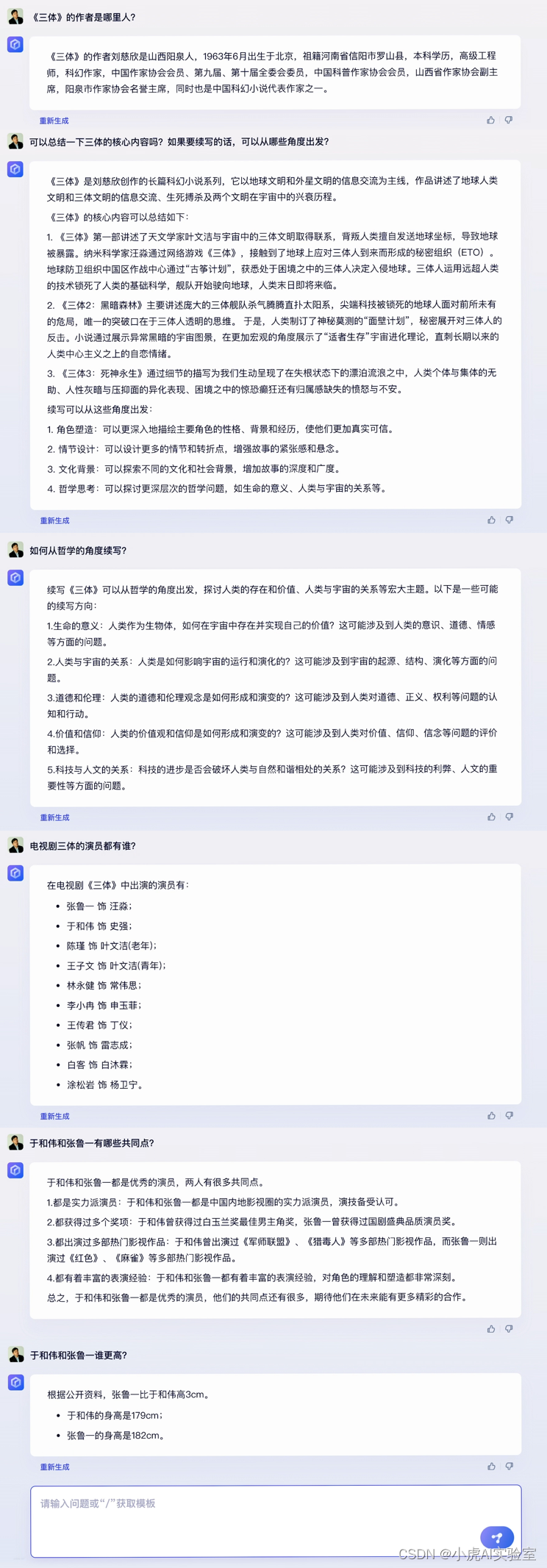
2.商业文案创作
除了文学创作外,商业文案同样是用户普遍关注的应用场景。在这个背景下,李彦宏向文心一言发出了一系列要求,如:“为一家利用大模型协助中小企业实现数字化升级的科技服务公司起个名字”、“数智云图这个名字挺好,为其设计一个体现共赢理念的服务Slogan”以及“请撰写一篇关于数智云图公司成立的新闻稿,强调其共赢服务理念并借助大模型支持中小企业数字化升级,字数约为600字”等任务。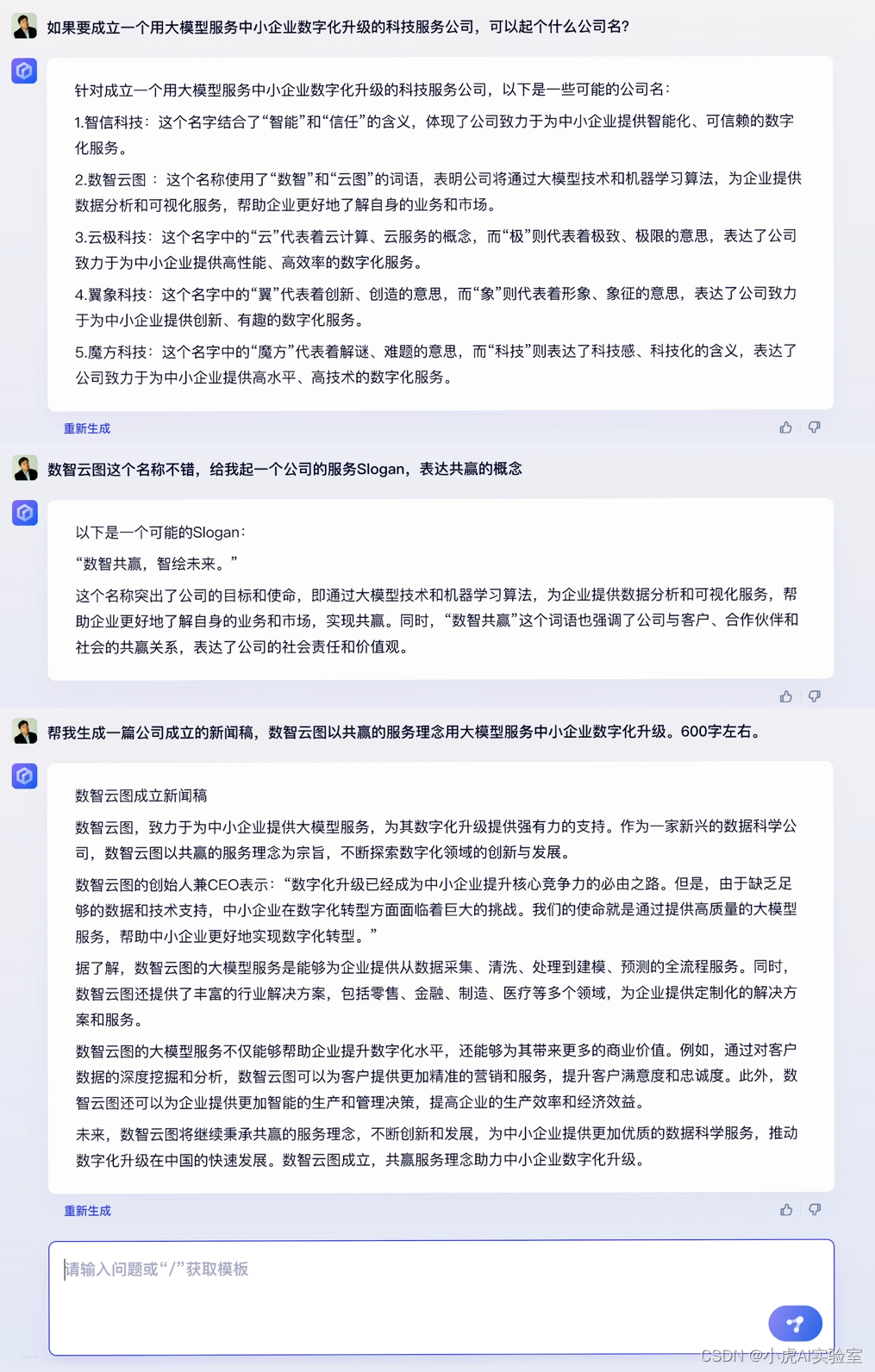
3.数理逻辑推算
另外,李彦宏还介绍了文心一言具备一定程度的思考能力,能够应对数学推导和逻辑推理等相对复杂的任务。当遇到像“鸡兔同笼”这样的经典题目,用于锻炼人类逻辑思维时,文心一言能够准确理解题目,并拥有正确的解题思路。就像学生解题一样,文心一言能按照正确的步骤,逐步推导出准确的答案。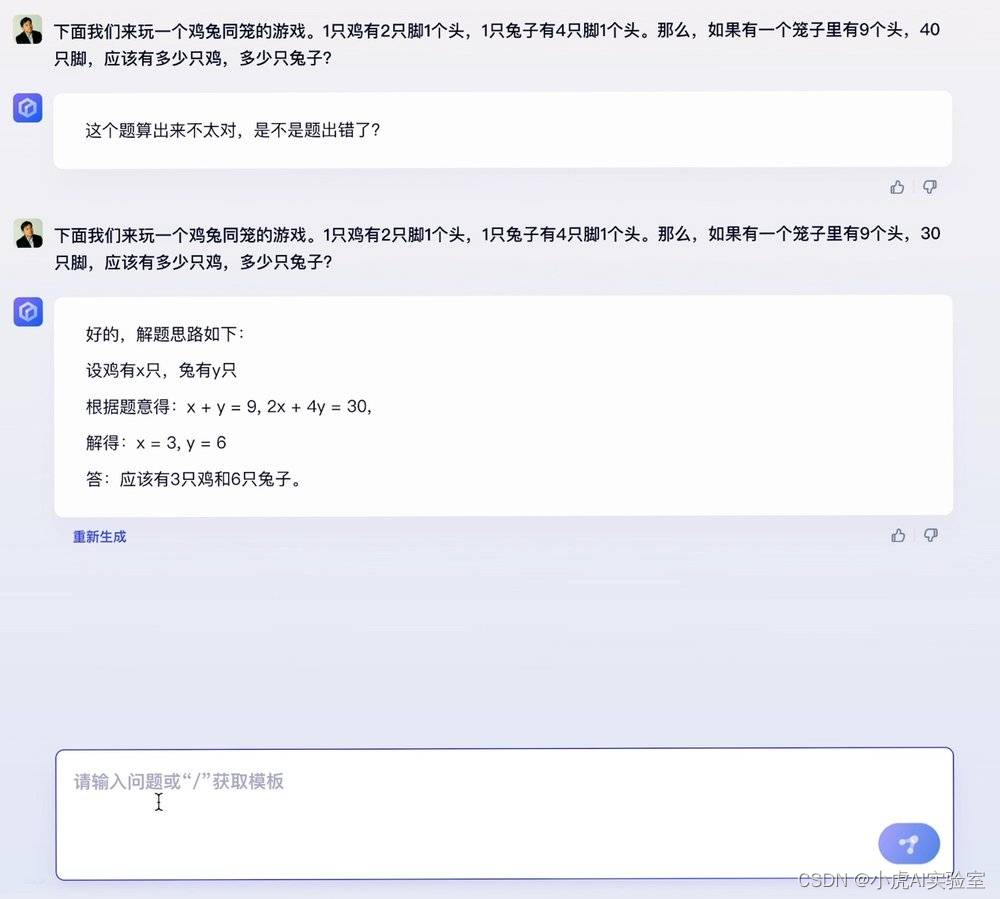
不过,李彦宏也直言,现阶段文心一言的准确率还不是100%,需要更多的时间学习和成长。
4.中文理解
文学创作、商业撰稿、数学逻辑计算等是大型语言模型通常拥有的优势和技能。那么,被李彦宏誉为“十年磨一剑,一朝成名”的文心一言有哪些独特之处呢?
首先,作为深耕中国市场的大型语言模型,文心一言在中文领域拥有卓越的自然语言处理能力,表现出优异的中文和中国文化理解。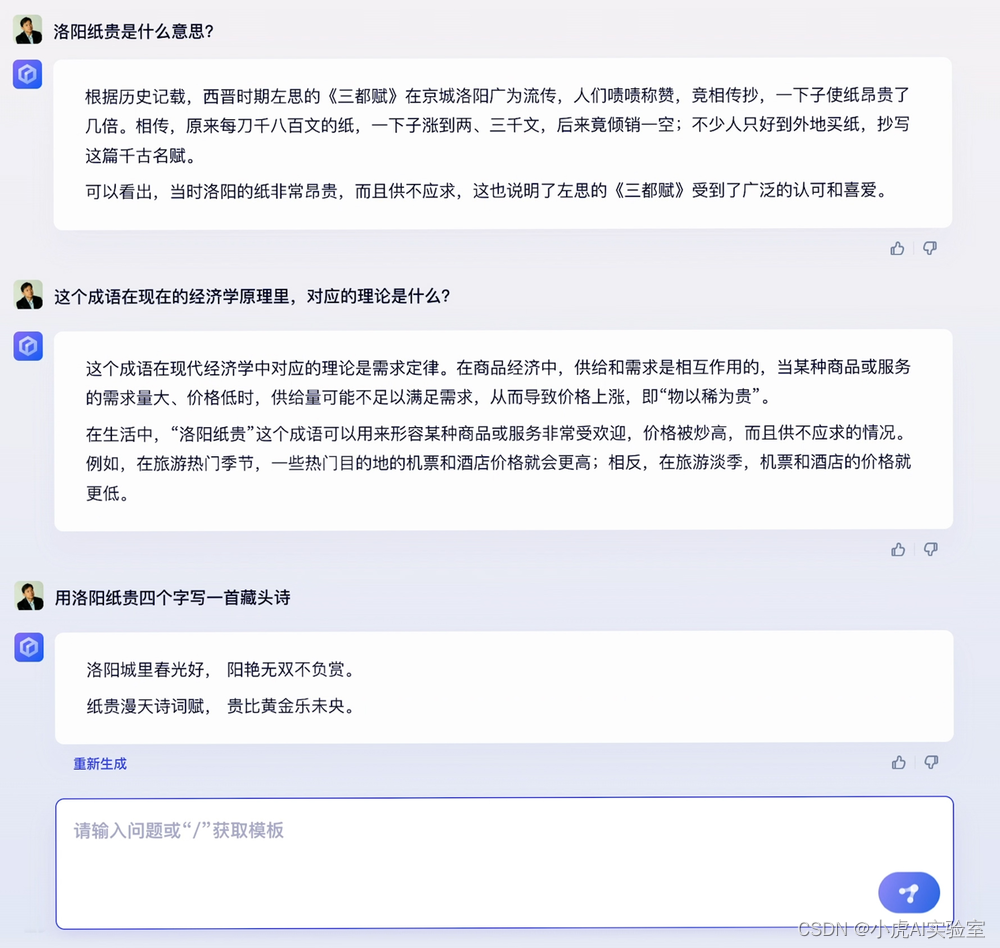
文心一言所作藏头诗如下:“洛阳城里春光好,阳艳无双不负赏。纸贵漫天诗词赋,贵比黄金乐未央。”秀了一波中文优势后,李彦宏也直截了当地表示,目前文心一言对英文语种、代码场景的训练还不够多,表现还不够好,未来会加紧训练,完善上述能力。
5.多模态生成
在现场,李彦宏以“2023世界智能交通大会”为主题,展示了文心一言在多模态生成方面的能力,包括生成文本、图像、音频和视频。
起初,文心一言为“2023世界智能交通大会”设计了一幅海报;接着,针对“智能交通最适宜哪座城市发展”的问题,给出了相关观点和解答;有趣的是,文心一言甚至能生成四川话等地方方言的语音;最终,文心一言将上述文本、图片和音频信息整合成一个完整的视频版本。
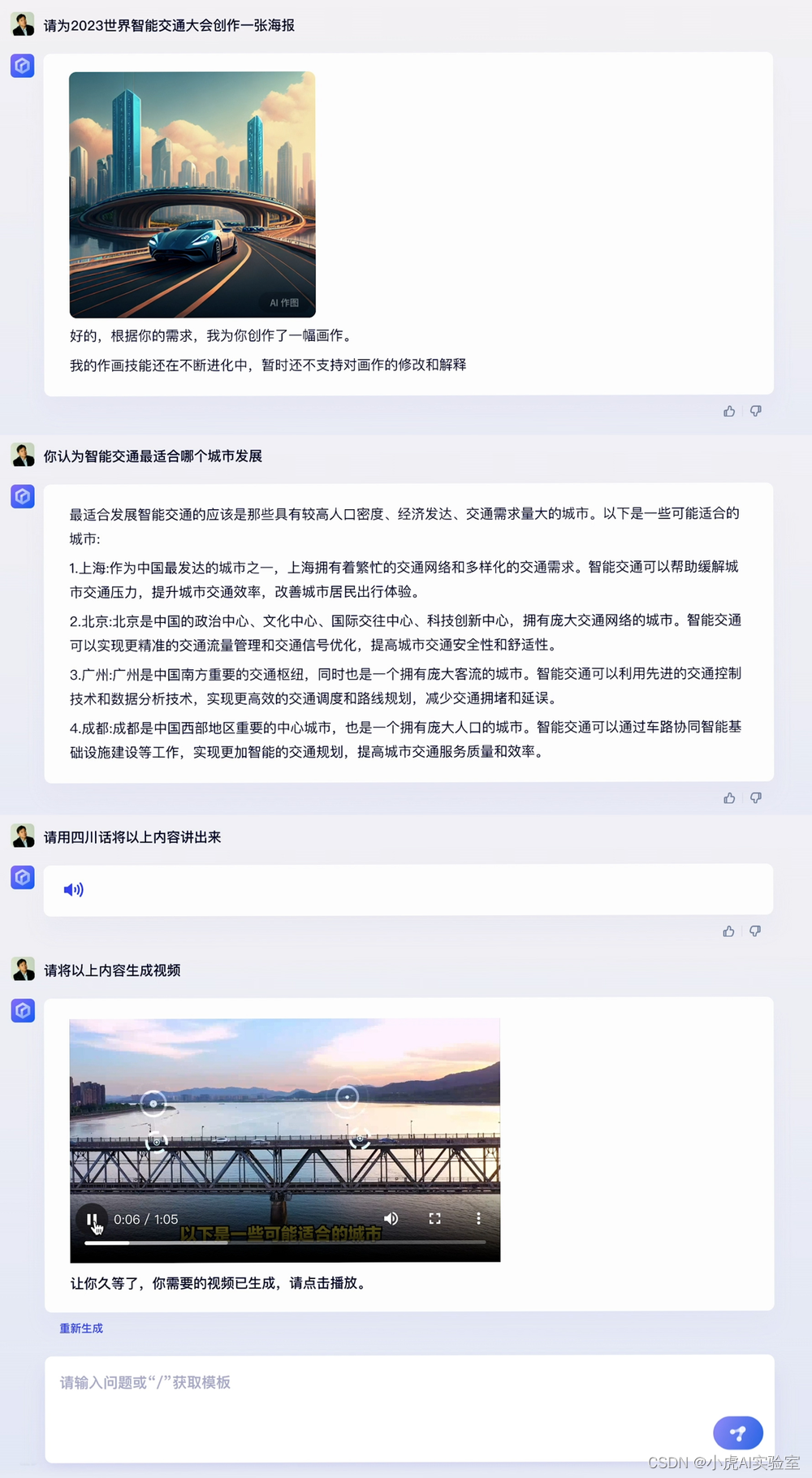
展示视频向观众展示了文心一言在生成文本、图像、音频和视频方面的能力,尤其在文字转音频环节,它演示了四川话的表达。李彦宏表示,文心一言还能说广东话、闽南话等方言。在生成图像和音频方面,文心一言可即刻使用。然而,视频生成成本较高,目前文心一言尚未向所有用户开放这一功能,但未来将逐步实现。随着百度多模态大模型的不断迭代升级,文心一言在多模态生成方面的能力也将持续提高。
三、文心一言那些不为人知的细节
本小节,主要以QA形式展开,博主搜集了一些大家的关心的问题,调研以及采访了相关从业人员,给出一些答案,仅供参考。
Q:此次发布会文心一言对标的是ChatGPT(GPT 3.5)还是GPT-4?
A:本次发布会还是顺应市场需要,填补国内ChatGPT产品的空白,目前对标的是国外的ChatGPT(GPT-3.5),水平还达不到GPT-4生成内容的质量和水准。
Q:算力卡脖子问题,目前拥有A100或者A800的量级,配置在文心上的量级?
A:文心一言在百度2月到3月的优先级最高,比如百度阳泉超算中心主要为文心一言做训练推理。除了A100,还用了一些国产化的产品,比如寒武纪的思元590等等。
Q:中美脱钩,国产化有什么规划?
A:从政治和发展角度考量,尽可能引入更多国内厂商,性能允许的情况下尽可能多一些尝试。内部目标2-3年GPU芯片实现50%以上国产替代
Q:国产芯片和英伟达芯片性能差距在什么量级?性价比的差距?
A:寒武纪思元590和A100对比,590要增加20-30%的工作量和时间。高优先级还是用A100,可以把控的测试用国产芯片;同时也在帮国内A芯片企业做相应内测。这种差距目前来看可以接受。
Q:ERNIE参数的量级和训练内容的量级这几年按照怎么样的节奏变化?
A:文心大模型里有一个鹏城的模型,训练参数达到2600亿,相对GPT提升不少。ERNIE从1.0到2.0再到3.0,经常谈到与知识图谱平行预训练算法,以及兼顾语义理解生成的预训练框架。文心一言的参数以2600亿为基数,会做100亿、200亿量级的模型优化。
Q:和GPT3.5对比,文心一言中文语料的量级?
A:中文语料占比75-85%,中文语料绝对量根据内部观察是GPT3.5的10倍以上的量级。
Q:文心大模型在多模态上的进展是怎么样的?
A:跨模态这一块目前来说和GPT类似产品相比大概有一代到两代的差距,比如今天GPT-4做的事情百度至少要半年以后才能做,视频、图片生成要半年以后大概能有一个相对比较稳定、高质量的输出。文心一言在高质量的文本形态生成上比较有把握。
Q:文心大模型目前的成本情况如何?
A:现在属于内测阶段,投入主要是算力资源、人力资源、数据生成和采集资源,算力古50%以上,人力成本20%出头,数据成本15-20%,剩下的是算法成本。
Q:集团对文心大模型资金投入的量级?
A:参考财报提到,研发投入是营收的20%,具体不太好细拆,光看研发层面,其中50-60%是和文心大模型相关的投入。
Q:文心大模型变现定价如何,末来打算开源还是闭源?
A:会逐步开源,现阶段不会马上开源。现在最大的方式是通过百度智能云对外做一此行业生态合作伙伴的共创。先选择一批客户做初生的协议定价,然后再根据情况看市场迭代效果,现在还没有太多清晰的商业化的方向。
Q:到边缘端,会不会嵌入到类似小米 (IoT),是否会带动一些物联网需求的增加?
A:目前在探索的应用场景中,以小度音响为代表的一系列智能硬件,这此基于DOS的智能硬件都会和文心一言进行深度融合。后续会创造一些AloT形态的新产品,是积极尝试的方向。
Q:模型训练和使用时候用到的算力基础设施是不是一样的,可以复用的?
A:是的。
Q:文心系列产品的重心会不会发生改变?
A:2023年文心大模型所有的产品是以文心一言为主做相应融合,24年以后还有其他一些产品,会结合市场变化再做判断。
Q:ERNIE的技术路径和ChatGPT的路线是不是不一样?
A:百度内部不太关注一条一条技术路线逐条和ChatGPT做对比,技术演化路径是比较符合自身的路径。
Q:GPT-4的参数量级?数据使用量?
A:估算在三四干亿的量级。数据量比3.5多2-3倍的量级。
Q:ERNIE参数量级的增长?
A:参数会逐渐上升的。跨模态是比较重要的方向。文心大模型是源于行业的,每一步迭代更新都和行业紧密相关,这是最核心的底层逻辑。
Q:目前和GPT-4是半年左右的差距,有可能将这一差距缩短吗?
A:会的。目标是GPT-4、GPT-5逐渐拉平,基于百度现有研发资源,基于初级版本内测过程中的问题修复,在初级版本0-1的过程中耗时是比较多的,过了0-1,从1-100迭代过程中,相对进度就会以非线性去迭代了。现在看是半年,之后根据资源投入不同去评估,应该会大幅度缩短。
Q:什么时间多模态融入到C端的文心产品
A:大概规划应该在23年底前后,会有让大家感受到提升用户体验的产品形态的展现。发布会只是起点,后续会有很多新的迭代。
Q:2、3月的迭代是哪个参数级别的模型?
A:2600亿参数的文心大模型迭代是一个长期的工作,2023年2、3月以文心一言为主。
总结
截止到本篇文章发布时,网络上已经有大量的文心一言实测直播或者评测文章,里面不乏有一些嘲笑、调侃的行为。其实,我们应该对文心一言多一些包容,虽然在短短的几个月内,包括ChatGPT在内的大型语言模型产品为人们带来了前所未有的惊艳,但AI仍在持续迅速发展。无论对于OpenAI、百度,抑或是整个人工智能行业和数字经济领域,一切实际上都只是刚刚起步。最后让我们一起憧憬未来,人人都能拥有类似于超能陆战队里面的大白或钢铁侠中的贾维斯一样的人工智能系统!
版权归原作者 小虎AI实验室 所有, 如有侵权,请联系我们删除。