
文章目录
1. kafka 架构
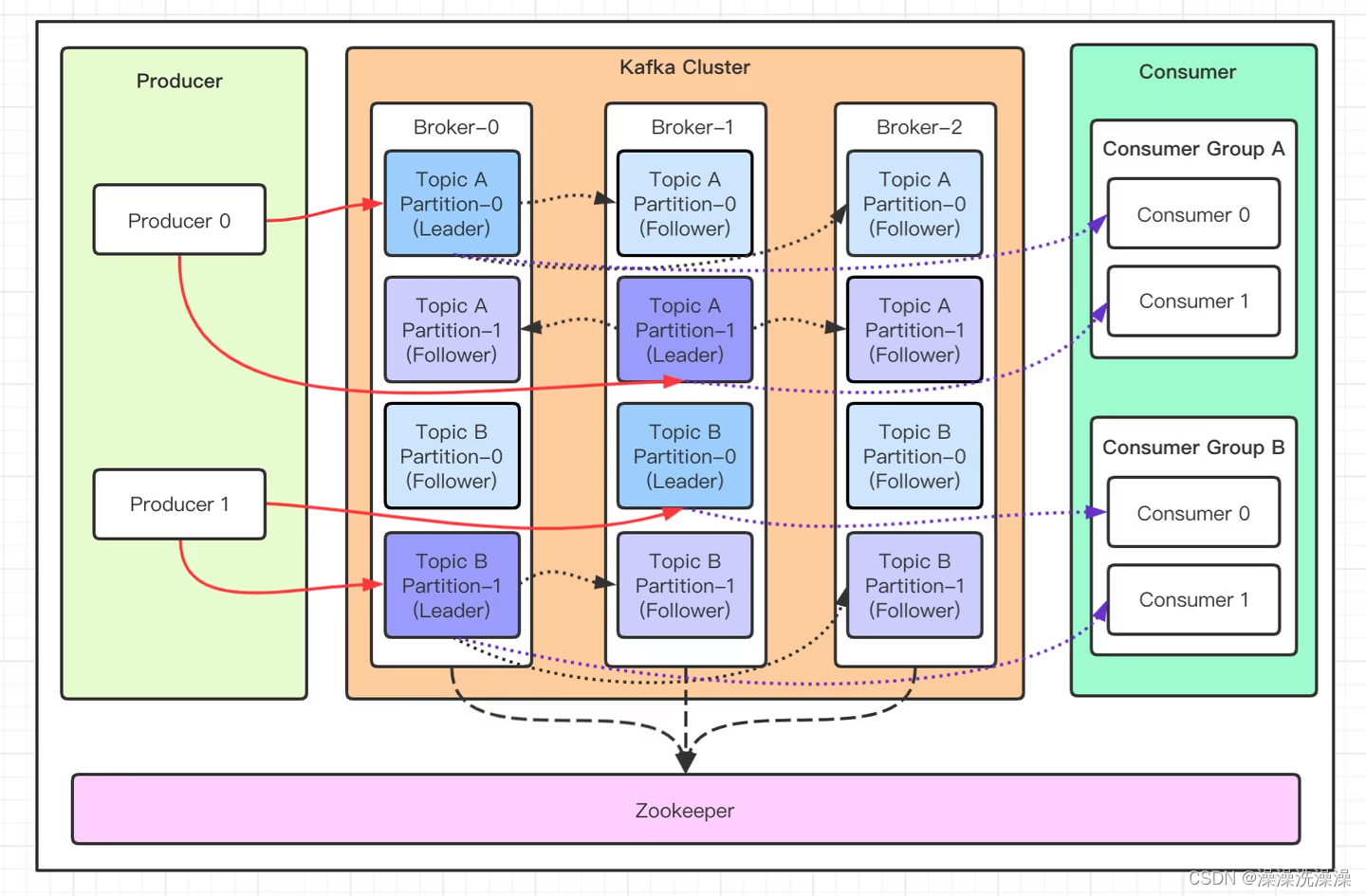
Producer:生产者,发送消息的一方。生产者负责创建消息,然后将其发送到 Kafka。
Consumer:消费者,接受消息的一方。消费者连接到 Kafka 上并接收消息,进而进行相应的业务逻辑处理。
Consumer Group:将多个消费者组成一个消费者组,一个消费者组可以包含一个或多个消费者。使用多分区 + 多消费者方式可以极大提高数据下游的处理速度,同一消费组中的消费者不会重复消费消息,同一个消费者组的消费者可以消费同一个topic的不同分区的数据。Kafka 就是通过消费组的方式来实现消息 P2P 模式和广播模式。
Broker:服务代理节点。Broker 是 Kafka 的服务节点,是 kafka 一个实例,每个服务器上有一个或多个 kafka 的实例,简单的理解就是一台 kafka 服务器,kafka cluster表示集群的意思
Topic:消息的主题,可以理解为消息队列,kafka的数据就保存在topic。Kafka 中的消息以 Topic 为单位进行划分,生产者将消息发送到特定的 Topic,而消费者负责订阅 Topic 的消息并进行消费。
Partition:Topic 是一个逻辑的概念,它可以细分为多个分区,每个 topic 可以有多个分区,分区的作用是做负载,提高 kafka 的吞吐量。每个分区只属于单个主题,同一个主题下不同分区包含的消息是不同的,partition 的表现形式就是一个一个的文件夹,分区在存储层面可以看作一个可追加的日志(Log)文件,消息在被追加到分区日志文件的时候都会分配一个特定的偏移量(offset)。
Offset:offset 是消息在分区中的唯一标识,Kafka 通过它来保证消息在分区内的顺序性,不过 offset 并不跨越分区,也就是说,Kafka 保证的是分区有序性而不是主题有序性。
Replication:副本,是 Kafka 保证数据高可用的方式,Kafka 同一 Partition 的数据可以在多 Broker 上存在多个副本,通常只有主副本对外提供读写服务,当主副本所在 broker 崩溃或发生网络异常,Kafka 会在 Controller 的管理下会重新选择新的 Leader 副本对外提供读写服务。
Leader:在kafka中默认副本的最大数量是10个,且副本的数量不能大于Broker的数量,follower和leader绝对是在不同的机器,同一机器对同一个分区也只可能存放一个副本。
Message:每一条发送的消息主体。
Record:实际写入 Kafka 中并可以被读取的消息记录。每个 record 包含了 key、value 和 timestamp。
Zookeeper:kafka 集群依赖 zookeeper 来保存集群的的元信息,来保证系统的可用性。
kafka 本质就是一个消息系统,与大多数的消息系统一样,主要的特点:
- 使用推拉模型将生产者和消费者分离
- 为消息传递系统中的消息数据提供持久性,以允许多个消费者
- 提供高可用集群服务,主从模式,同时支持横向水平扩展
与 ActiveMQ、RabbitMQ、RocketMQ 不同的地方在于,它有一个
分区Partition
的概念。
如果你创建的topic有5个分区,当你一次性向 kafka 中推 1000 条数据时,这 1000 条数据默认会分配到 5 个分区中,其中每个分区存储 200 条数据。
这样做的好处,方便消费者从不同的分区拉取数据,假如你启动 5 个线程同时拉取数据,每个线程拉取一个分区,消费速度会非常非常快!
这是 kafka 与其他的消息系统最大的不同!
在使用消息队列时,数据不丢失是至关重要的。Kafka 作为一款主流的消息队列系统,提供了多方面的机制来保障数据不丢失,针对生产者、消费者和代理节点三个层面,是如何保证数据不丢失的
2. producer端是如何保证数据不丢失的
2.1 同步发送
同步发送模式下,生产者会阻塞等待 broker 的确认,直到消息被成功写入 ISR 中,才算发送成功。这种方式可以保证数据强一致性,但也降低了吞吐量。
2.2 异步发送
异步发送模式下,生产者不会等待 broker 的确认,而是直接将消息发送给 broker。这种方式可以提高吞吐量,但也存在数据丢失的风险,例如当 broker 宕机时,未确认的消息可能会丢失。
2.3 批量发送
批量发送可以减少发送消息的次数,提高吞吐量。Kafka 支持批量发送,生产者可以将多个消息组合成一个批次发送,以减少网络开销和提高效率。
3. consumer端是如何保证数据不丢失的
3.1 手动提交
消费者端默认自动提交模式,但这种模式下,如果消费者在消费消息后还未提交偏移量,就宕机了,那么这部分消息就会被重复消费。为了避免这种情况,可以设置手动提交模式,由消费者程序显式提交偏移量,确保消息只被消费一次。
3.2 幂等性消费
在某些情况下,即使消息只被消费一次,也可能导致数据不一致。为了解决这个问题,可以对消费逻辑进行改造,使其具有幂等性,保证即使消息被重复消费,也不会产生错误结果。
4. broker端是如何保证数据不丢失的
4.1 副本机制
Kafka 每个消息都会保存多个副本,即使一个副本所在的代理节点宕机,其他副本仍然可以提供数据。副本机制可以有效提高数据的可靠性,但也会增加存储空间和资源开销。
4.2 ISR机制
ISR(in-sync replica)列表包含所有与 leader 副本保持同步的副本。只有 ISR 列表中的副本才能接收写请求,保证数据的完整性和一致性。
4.3 刷盘机制
Kafka 将消息写入内存页缓存后,会异步刷盘到磁盘。为了保证数据持久性,可以配置刷盘策略,例如同步刷盘或异步刷盘。同步刷盘会降低吞吐量,但可以保证数据即使在 broker 宕机的情况下也不丢失。异步刷盘可以提高吞吐量,但存在数据丢失的风险,例如当 broker 宕机时,未刷盘到磁盘的数据可能会丢失。
版权归原作者 澡澡洗澡澡 所有, 如有侵权,请联系我们删除。