
人工智能(AI)技术的崛起,犹如一股强大的催化力量,正在驱动各行各业经历前所未有的变革性转型。光学收发器市场作为这一范式转变的重要领域之一,正见证着由ChatGPT等先进模型引领的AI革命所带来的深刻影响。本文将深度剖析AI技术,特别是由ChatGPT等标志性模型引发的AI新浪潮,如何重塑数据中心网络架构,并有力推动高性能光模块市场的蓬勃发展。聚焦于2024年预期将迎来井喷式增长的800G光模块产品,我们将详尽探讨其在提升数据传输效能、适应日益增长的AI算力需求等方面所发挥的关键作用及其对整个行业生态的影响。
一场由ChatGPT触发的AI浪潮
ChatGPT等尖端AI模型的创新研发与广泛应用开启了全新纪元,释放出前所未有的可能性。这些基于先进深度学习技术构建的模型展现出理解和生成类似人类文本的独特能力。作为当前AI浪潮的典范,ChatGPT以其卓越表现揭示了改进沟通方式和优化数据处理流程的巨大潜力。其强大的自然语言处理能力有力地促进了人机交互效率的提升,并在优化数据中心运营效能方面成为一项宝贵的资产。因此,AI技术的发展浪潮已然成为推动对更快、更可靠且具有更高容量光模块需求不断增长的核心驱动力。
运行ChatGPT这样的大型AI模型,离不开强大云计算资源的支撑。回顾2018年OpenAI发布的GPT模型,其参数数量达到了1.17亿,预训练阶段的数据规模约为5GB。而后的GPT-3则以令人震撼的1750亿参数量和45TB训练数据再创纪录。仅在模型训练阶段,ChatGPT就消耗了约3640PF天的计算力,对应的训练成本高达1200万美元。而在服务访问阶段,所需的计算资源更是显著增加。据估计,为了满足当前用户对ChatGPT搜索和访问的需求,初期在计算基础设施方面的投入需达到大约30-40亿美元,尤其是依赖于服务器(GPU)的强大性能。这一现实无疑为高性能光模块市场带来了前所未有的市场需求和发展机遇。
人工智能如何重塑数据中心网络
将AI技术深度融入数据中心体系,已经从根本上重塑了数据传输的格局。传统数据中心原本是为应对常规计算负载而设计构建,如今正经历着一场深刻转型,以更好地适应由AI驱动应用日益增长的需求。其中的关键差异体现在对数据处理与传输模式的革新上。
传统数据中心与AI数据中心
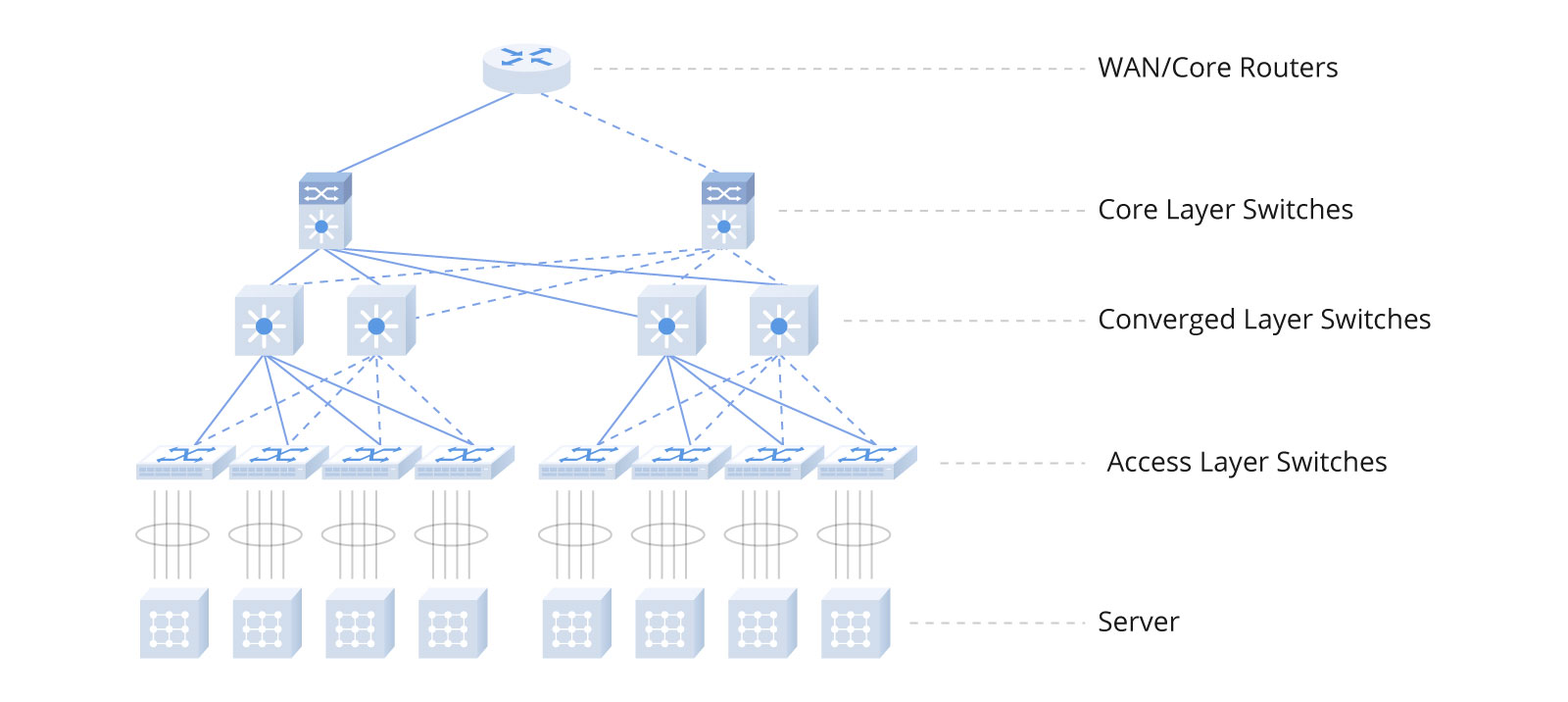
传统数据中心与AI优化的数据中心在设计理念和架构上有所不同。在传统数据中心中,数据传输依赖于分层网络结构,这一结构包括接入层、汇聚层以及核心层。接入层实现计算节点与机柜交换机的连接,汇聚层负责各接入层间的互连,而核心层则管理着汇聚层到外部网络的通信链路。然而,每一层级都可能引入额外延迟,并且随着东西向流量在数据中心内部激增,传统的三层网络架构中的核心层与汇聚层压力陡增,对性能要求不断提高,设备成本也随之显著攀升。
因此,在适应数据中心内大规模东西向流量需求的过程中,一种更为精简高效的叶脊网络架构应运而生。该架构下,叶交换机直接与计算节点建立连接,而脊交换机作为核心角色,通过等价多路径(ECMP)技术动态选择并分配多条传输路径,从而有效提升数据传输效率。
叶脊架构凭借其众多优势,如高带宽使用率、卓越的可扩展性、稳定的低延迟以及增强的安全防护特性,已广泛应用于各类数据中心场景,并表现出明显的优势。对于高度依赖快速处理和高效传输海量数据的AI数据中心而言,叶脊架构能够更好地满足此类严苛需求,为AI工作负载提供强有力的支持。
另一方面,AI数据中心利用并行处理技术、分布式计算体系以及高速互联手段,确保了数据流的无缝传输和最小化延迟。鉴于内部数据流量规模庞大,采用无阻塞的胖树网络架构成为了一项至关重要的需求。NVIDIA的人工智能数据中心便采纳了这一无阻塞胖树网络架构,以保证其高效流畅运作。
该架构的核心思想是通过大量部署低功耗交换机设备,构建一个广泛且无瓶颈的网络结构。这种设计确保在任何通信模式下,都能提供与网卡(NIC)带宽相匹配的通信路径,并且架构内所有交换机保持一致性能配置。无阻塞胖树网络架构已在对网络性能要求极高的环境中广泛应用,特别是在高性能计算中心和人工智能数据中心领域。
以NVIDIA的DGX A100 SuperPOD AI数据中心系统为例,其三层交换机构建完全由NVIDIA Quantum QM8790 40端口交换机构成。第一层交换机直接连接至1120块Mellanox HDR 200G InfiniBand网卡。在此配置中,第二层交换机的下行端口与第一层交换机相连,而上行端口则向上连接至第三层交换机。第三层交换机仅配备下行端口,通过这些端口彼此间相互连接至第二层交换机。
此外,在系统存储部分采用了独立的网络架构设计,与计算部分进行物理隔离。为了实现这种分离性,需要特定数量的交换机和光模块支持。因此,相较于传统数据中心,人工智能数据中心中的交换机及光模块数量呈现显著增长态势。
800G光模块发挥重要的作用
800G光模块在当前变革中发挥着至关重要的作用。单个800G光模块能够在光纤端口实现对两个400G光模块的替代,并且在电接口端,能够集成8个SerDes通道,与光纤端口中的8条100G通道对应匹配。这种设计提升了交换机内部的通道密度,并有效缩小了物理空间占用。e.
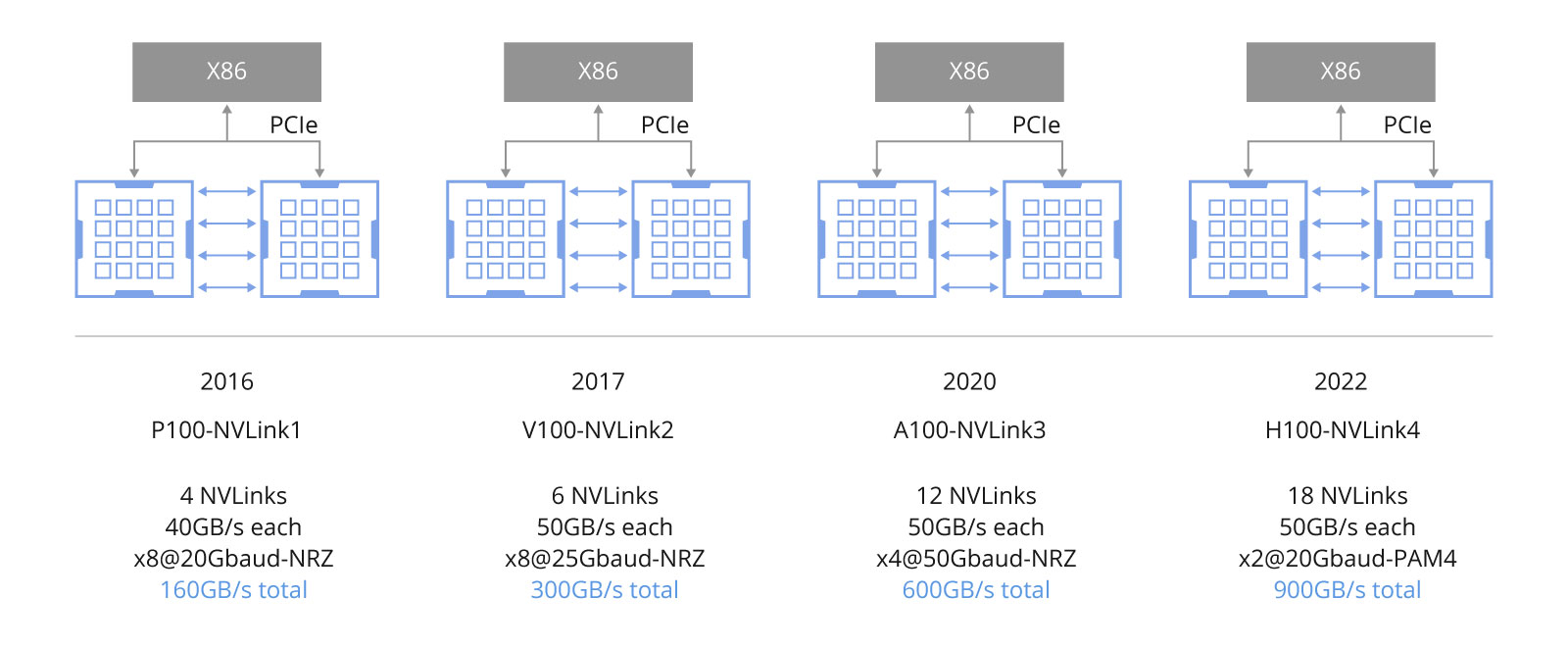
光模块的速度受到网络适配卡性能的影响,而适配卡速率则受限于PCIe通道的速度限制。在NVIDIA A100 DGX服务器中,内部通信利用NVLink3技术实现高达300GB/s的单向带宽。然而,A100 GPU通过连接到ConnectX-6网络适配卡的16条PCIe 4.0通道,达到了约200G的总带宽,因此需要采用与之相匹配的200G光模块或DAC高速线缆以确保传输效率。
在H100 DGX服务器案例中,内部互联采用了NVLink4技术,其单向带宽提升至450GB/s。H100 GPU通过16条PCIe 5.0通道与ConnectX-7网络适配卡相连,使得单个网络适配卡可实现约400G的总带宽。值得注意的是,光模块速度直接受限于网络适配卡与GPU之间PCIe通道的带宽。
倘若未来A100和H100 DGX服务器内部能支持800G(PCIe 6.0)的PCIe通道速度,那么部署具备800G带宽的网络适配卡并配合使用800G光模块将成为现实。这一技术进步将有望大幅度提升系统的整体计算效能。
2024 —— 800G光模块的元年
展望未来,2024年预示着光模块市场的一个重要转折点,这一年将见证800G光模块解决方案的崛起与聚焦。截至2019年,当业界普遍认为向100G光模块过渡是一个标志性阶段时,市场上已呈现出两条主流升级路径,即分别向200G和400G方向发展。然而,新一代高速光通信技术的研发趋势已经明确指向了对800G光模块的深度研发与广泛应用。
随着AI(人工智能)技术和GC(广义卷积)网络推动计算性能持续突破并加剧市场竞争,预计在2024年,北美乃至全球的主要云服务提供商和技术巨头们极有可能大幅度采购及部署800G光模块,以应对日益增长的数据传输需求和优化数据中心基础设施。
面对当前变革性的市场环境,拥有一个既可靠又富有创新精神的合作伙伴显得至关重要。作为提供网络解决方案的业界信赖供应商,FS已为全球超大规模云数据中心精心打造了一整套800G产品系列。2023年,我们成功推出了全新的800G NDR InfiniBand解决方案。我们的产品组合全面覆盖了800G OSFP和800G QSFP-DD两种主流光模块类型。不仅如此,飞速(FS)的产品线进一步拓展至800G AOC(有源光缆)和DAC(高速线缆),以满足各行业客户对高速数据传输的需求,并确保持续提供优质、可靠的光网络产品与解决方案。
总之,在人工智能技术不断进步与光模块市场交汇发展的大背景下,标志着高速高效数据传输新时代的开启。AI对数据中心网络架构带来的深刻变革突显了光模块在这一进程中的关键角色。随着2024年800G光模块时代的预期来临,企业可以一如既往地依赖飞速(FS)来应对AI时代所带来的复杂挑战,共同构建适应性强、性能卓越的数据中心网络,从而为迎接充满无限可能的未来奠定坚实基础。
版权归原作者 audrey-luo 所有, 如有侵权,请联系我们删除。