

VQVAE:Neural Discrete Representation Learning
原文链接:https://arxiv.org/abs/1711.00937
要看细节,强推,直接不用看论文了:VQ-VAE的简明介绍:量子化自编码器 - 科学空间|Scientific Spaces
一、问题提出
一些具有挑战性的任务,如few-shot learning,严重依赖从原始数据学习的表示,但在无监督的方式下训练的通用表示的有用性仍然远远不是主流方法。
极大似然和重构误差是训练像素域无监督模型的两个常用目标,但它们的有用性取决于特征所用于的特定应用。
目标:实现一个模型,在潜在空间中保留数据的重要特征,同时优化最大似然。最好的生成模型(通过对数似然度量)将是那些没有潜在功能但具有强大解码器的模型(如PixelCNN)。
二、模型
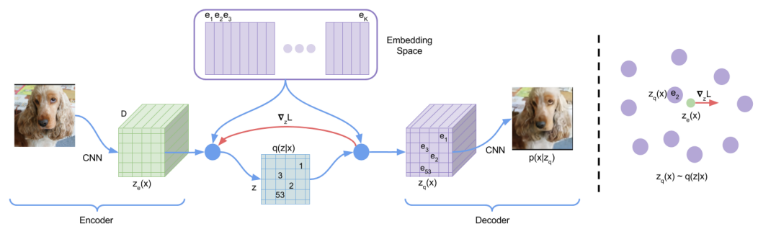

1、VAEs
包含两部分,
编码器:在输入数据x的条件下参数化离散潜在随机变量z的后验分布q(z|x),先验分布p(z)
解码器:重构p(x|z)
后验和先验假设服从正态分布,具有对角协方差,这允许使用高斯重参数化技巧
2、 Discrete Latent variables
定义一个潜在空间e,e的维度为(K,D),K为离散潜在空间的大小(即K个向量),D为每个潜在向量的维度。模型接受输入x,经过encoder得到ze(x),利用 shared embedding space e通过最近邻查找计算离散潜变量z(下面公式1),decoder的输入是对应的embedding向量ek(下面公式2)
可以将这个前向计算pipeline看作AE,它具有特定的非线性,将潜在向量映射到1-of-k的embedding向量。模型的完整参数集是encoder、decoder和embedding space e的参数的联合。
后验分类分布q(z|x)概率定义为one-hot如下:

可以看出是一个VAE,用ELBO约束log p(x)。建议分布q(z = k|x)是确定的,通过定义一个简单的对z的一致先验,得到一个KL发散常数,等于log k:

表示ze(x)通过离散化bottleneck,然后映射到最近的embedding e的元素

3、learning
公式2没有梯度,因此采用量化操作来使用次梯度。在正向计算过程中,最接近的embedding zq(x)(公式2)被传递给解码器,而在向后传递过程中,梯度∇zL被不改变地传递给编码器。由于编码器的输出表示和解码器的输入共享相同的D维空间,因此梯度包含了编码器如何改变输出以降低重构损耗的有用信息。
如图1(右)所示,梯度可以推动encoder的输出在下一个正向传递中进行不同的离散化,因为方程1中的赋值将会不同。
损失函数:
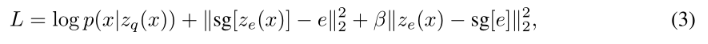

三、实验(Images)
可以通过一个纯反卷积p(x|z)将x = 128 × 128 × 3图像压缩到一个z = 32 × 32 × 1的离散空间(K=512)来建模x = 128 × 128 × 3图像。所以缩减为(128×128×3×8)/(32×32×9)≈42.6位。通过学习强大的先验PixelCNN对图像进行建模,
即使考虑到离散编码大大降低了维数,重构的图像看起来也只是比原始图像略模糊。在这里,可以使用比像素上的MSE更感性的损失函数。

参考链接(部分内容为更好的理解直接拷过来的,推荐一看):VQ-VAE解读 - 知乎
版权归原作者 羊飘 所有, 如有侵权,请联系我们删除。