
💟作者简介:大家好,我是锡兰Ceylan_,可以叫我CC ❣️
📝个人主页:锡兰Ceylan_的博客
🏆博主信息:平凡的大一学生,有着不平凡的梦**专栏**
- 【备战蓝桥,冲击省一】
- 【开卷数据结构】
⚡希望大家多多支持😘一起进步~❤️
🌈若有帮助,还请【关注➕点赞➕收藏】,不行的话我再努努力💪
前言
在这里【开卷数据结构 】- 2 - 链表我们了解了链表的定义,初始化,以及查找删除操作。
❓提出问题
之前讲到的链表结点中只有一个指向后续结点的指针域,若从某个结点出发只能顺指针向后一个一个寻查其他结点。若要访问某个结点的前驱节点,只能从头开始遍历。
有什么方法可以克服单链表这种单向性的缺点呢?
** 答案就是我们今天要介绍的循环链表,双向链表。**
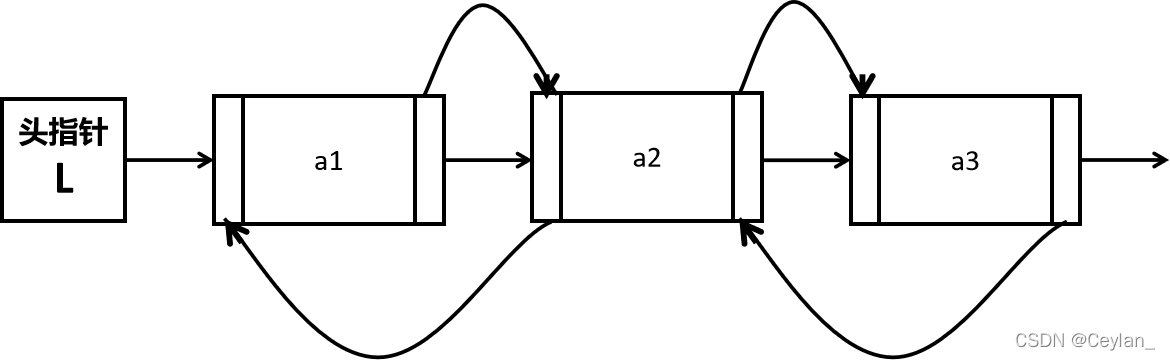
🌺循环链表
🔺实现原理
将单链表中终端结点的指针端由空指针改为指向头结点,就使整个单链表形成一个环,这种头尾相接的单链表称为单循环链表,简称循环链表,由此,从循环链表中任意一个结点出发都能找到其他结点。

对于这个循环链表,可以用O(1)的时间访问第一个结点,但是要访问最后一个结点,却需要O(n)时间,因为需要将单链表全部扫描一遍。
❓有没有什么方法可以用O(1)的时间由链表指针访问到最后一个结点呢?
我们需要对这个循环链表进行改造,不用头指针,而是用指向终端结点的尾指针来表示循环链表,此时查找开始结点和终端结点都为O(1)的时间了。

🌷循环链表的插入和删除
循环链表的插入,删除算法和单链表的一致,这里就不再赘述了
不了解的可以看看这篇文章【开卷数据结构 】- 2 - 链表
🌷循环链表与单链表的差别
他们的差别在于:
当链表遍历时,判别终止的条件不同。假设当前指针为p,在单链表中判断是否到达终点条件为【p!= NULL】或【p->!= NULL】,循环链表的判断条件为【p->next!= L】
🌺双向链表
🔺实现原理
双链表的结点中有两个指针域,一个指向后一结点,一个指向前一结点,结点结构如图所示
💬 代码演示
双链表结点:
typedef struct DNode
{
ElemType data;
struct DNode *prior,*next;
}DNode, *DLinklist;
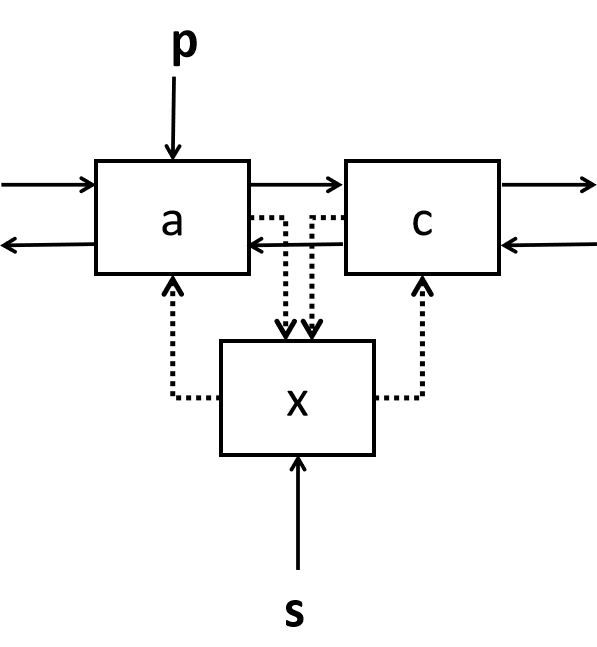
🌷双向链表插入
在双链表中p所指的结点之后插入结点*s
💬 代码演示
s->next=p->next; //将结点*插入到结点*p之后
p->next->prior=s;
s->prior=p;
p->next=s;
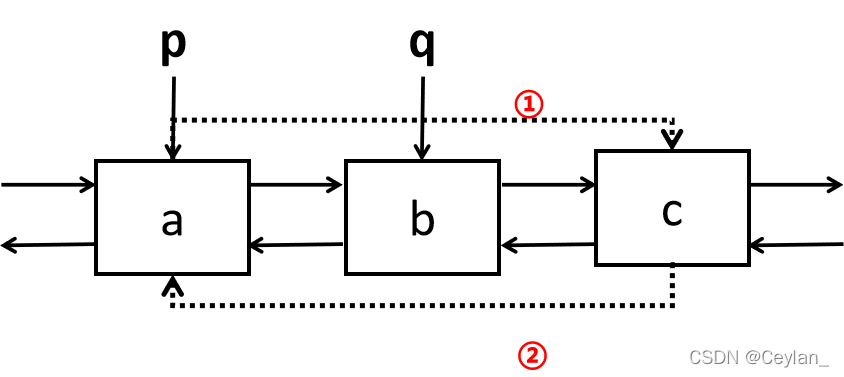
🌷双向链表删除
删除双链表中结点p的后续结点q
💬 代码演示
p->next=q->next; //操作一
q->next->prior=p; //操作二
free(p); //释放结点空间
🌺结束语
** 本人不才,如有错误,欢迎各位大佬在评论区指正。有帮助的话还请【关注➕点赞➕收藏】,不行的话我再努努力💪💪💪**
版权归原作者 锡兰Ceylan_ 所有, 如有侵权,请联系我们删除。