
需要源码请点赞关注收藏后评论区留言并且私信~~~
在本案例中,利用逻辑回归分类器对乳腺肿瘤进行良性/恶行预测,并对预测模型进行指标测算与评价。
一、数据集准备与处理
本案例数据集采用乳腺癌数据集,原始数据集的下载地址为数据集下载地址
数据特征包括细胞厚度、细胞大小、形状等九个属性,将每个属性的特征量化为1-10的数值进行表示,首先导入数据 并显示前五条数据

可以浏览数据的基本信息如下

调用describe函数查看数据的基本的统计信息如下

统计数据属性中的空缺值

如果数据中存在空缺数据需要丢弃或填充。该数据集中包含了16个缺失值用“?”标出。因此要删除有缺失值的数据

.将数据划分为训练集和测试集

标准化数据,每个维度的特征数据方差为1,均值为0,使得预测结果不会被某些维度过大的特征值主导
二、模型训练与性能评估
分别用LogisticRegression与SGDClassifier构建分类器
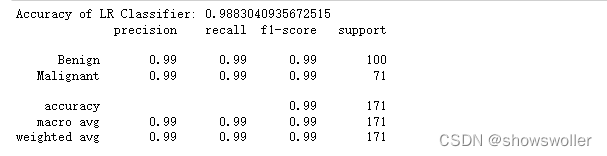
LR分类器性能分析 如下图所示 精度可以达到百分之九十八点八左右
SGD分类器性能分析 如下图所示 精度可以达到百分之九十六左右
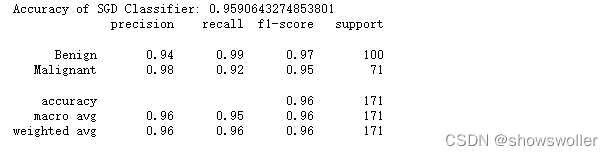
LogisticRegression较SGDClassifier在测试集上有更高的准确率,这时因为scikit-learn中采用解析的方法精确计算LogisticRegression的参数,而使用梯度法估计SGDClassifier中的参数
三、代码
部分代码如下 需要全部代码请点赞关注收藏后评论区留言并且私信
import pandas as pd
import numpy as np
column_names=['number','Cl_Thickness','Unif_cell_size','Unif_cell_shape','Marg_Adhesion','Sing_epith_cell_size','Bare_nuclei','Bland_chromation','Norm_nuclei','Mitoses','Class']
data=pd.read_csv('breast-cancer-wisconsin.data',names=column_names)
display(data.head())
data=data.replachow='any')
print(data.shape)
from sklearn.model_selection import train_test_split
# 划分训练集与测试集
X_train,X_test,y_train,y_test=train_test_split(data[column_names[1:10]],data[column_names[10]],test_size=0.25,random_state=33)
printlearn.preprocessing import StandardScaler
ss=StandardScaler()
X_train=ss.fit_transform(X_train)
X_test=ss.transform(X_test)
print(X_train.mean())
from sklearn.linear_model import LogisticRegression
from sklearn.linear_model import SGDClassifier
lr=Logitrain,y_train)
lr_y_predict=lr.predict(X_test)
sgdc.fit(X_train,y_train)
sgdc_y_predict=sgdc.predict(X_test)
from sklearn.metrics import classification_report
print('Accuracy of LR Classifier:',lr.score(X_test,y_test))
print(classification_report(y_test,lr_y_predict,target_names=['Benign','Malignant']))
print('Accuracy of SGD Classifier:',sgdc.score(X_test,y_test))
print(classification_report(y_test,sgdc_y_predict,target_names=['Benign','Malignant']))
创作不易 觉得有帮助请点赞关注收藏~~~
本文转载自: https://blog.csdn.net/jiebaoshayebuhui/article/details/128654222
版权归原作者 showswoller 所有, 如有侵权,请联系我们删除。
版权归原作者 showswoller 所有, 如有侵权,请联系我们删除。