
PS:大四写毕业论文的纯小白一枚,这篇文章也只是纯纯记录一下学习他人论文的思路,非专业!!!
基准回归
文章及代码来源:中国工业经济《税收征管数字化与企业内部薪酬差距》
xtset
xtset code year//定义面板数据
xtset定义面板数据
code为界面
year为时间序列
xtreg
xtreg gap gtp i.year i.ind,fe vce(cluster code)
est store m1
xtreg固定效应模型。
gap为因变量
gtp为自变量
i.year、i,ind表示虚拟变量
fe表示fixed effect固定效应
**vce(cluster code) **表示按公司层面聚类调整标准误
结合文献,此时应该是控制了年份固定效应和企业、行业固定效应?文章并没有说year\ind表示什么,猜测应该是年份和行业
结果解读:
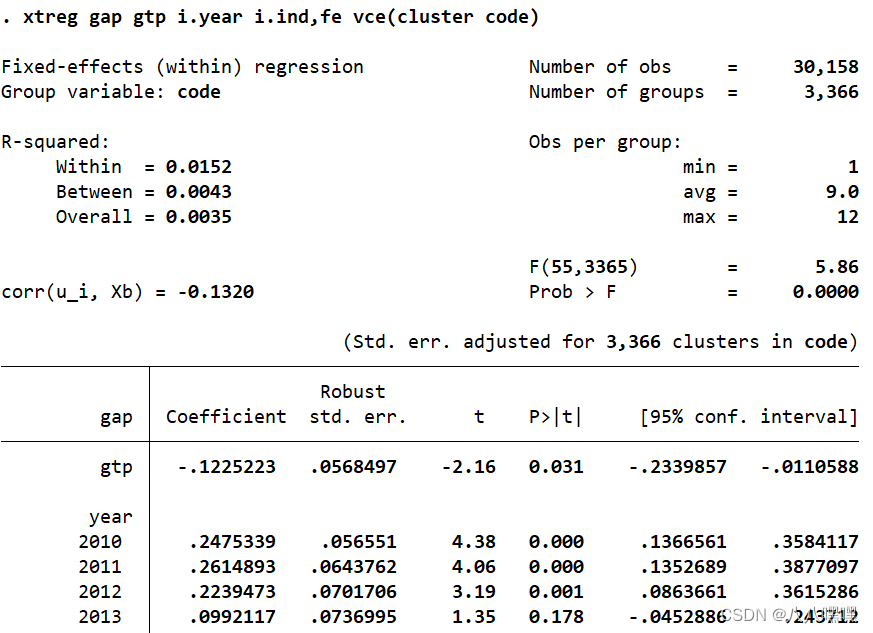
number of obs是样本数
R2中within\between\overall表示组内、组间、总体的拟合优度。一般固定效应看组内,随机效应看组间
Obs per group表示每组观测值?
**corr(u_i,xb) **是个体效应u_i与拟合值的相关系数。如果把个体效应当作不随时间改变的固定性因素,如个人的消费习惯、国家的社会制度、地区的特征、性别等,相应的模型称为“固定效应”模型。如果把个体效应视为随机因素,即把个体效应设定为干扰项的一部分,则称为“随机效应”模型。随机效应模型严格要求个体效应与解释变量不相关,即corr(u_i,xb)=0,所以本文使用固定效应模型。
**F(55,3365) **55是参数个数k,3365为n-k?
Prob > F=0.0000因为F检验的原假设是各个变量前面的系数为零。所以是拒绝原假设,接受这个模型。
Coefficient 系数
**Robust std. err.**指的是聚类调整标准误。
关于介绍参考链接Cluster Robust Standard Error到底调整的是什么?,文章对聚类调整标准误理解很透彻,有计量基础的可以康康。
t值一般用来检验个别偏回归系数。p>|t|说明发生了小概率事件,拒绝原假设。H0假设:变量前面的系数为零。
95% Conf. Interval指置信区间Confidence Interval 95%。
xtreg gap gtp size lev roa labor age cash indratio top1 soe i.year i.ind ,fe vce(cluster code)
est store m2
在m1基础上增添了控制变量,控制了企业层面(size lev roa labor age cash indratio top1 soe)
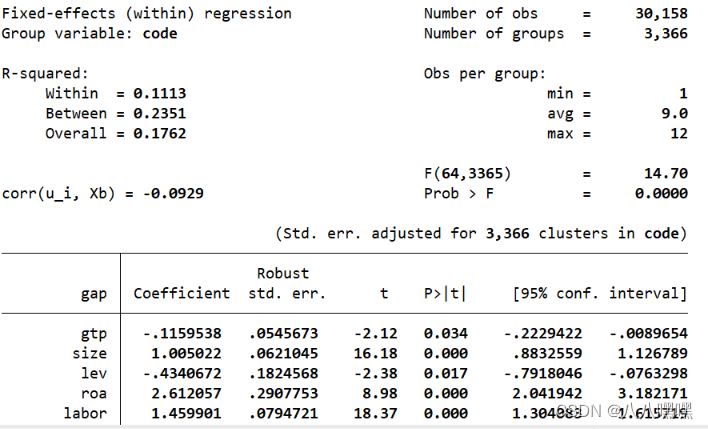
xtreg gap gtp size lev roa labor age cash indratio top1 soe olddep avgwage lnpgdp i.year i.ind i.prov,fe vce(cluster code)
est store m3
m3进一步控制了省份固定效应和地区经济发展特征变量(olddep avgwage lnpgdp)

发现有共线性问题,目前不知道怎么搞?下次去问问我导(●'◡'●)
esttab
esttab m1 m2 m3 using 基准回归.rtf,scalar(N r2_a) drop(*.year *.prov *.ind) compress star(* 0.1 ** 0.05 *** 0.01) mtitles nogap b(%6.4f) t(%6.4f)
esttab m1 m2 m3:显示指定的回归结果
scalars (r2_a N) 表示在表中展示调整后的R2 、样本量
drop删除
compress使得结果呈现更加紧凑
star(* 0.1 ** 0.05 *** 0.01)用小星星标注显著性水平
mtitles(titlelist) 在表标题中指定模型的标题
nogap命令使得两个自变量之间的空行删除
b(%6.4f)浮点数输出格式,表示无论结果有多少位,输出结果至少占六个制表符,即六个位置,不够的用空格补满,可以超过(这6个位置),且保留四位小数位。

版权归原作者 八八嘿嘿 所有, 如有侵权,请联系我们删除。