
Redis作为K-V数据库,应用非常广泛,在各大厂的面试中,redis也是绕不开的一个话题。我们说redis快,常规的解释是redis是基于内存实现的以及它的高效的数据结构,其实redis快的原因还有一个是因为使用了合适的IO模型,下面带大家分析一下。
**一.redis为什么要使用单线程**
在多线程并发大行其道的今天,为什么redis要另辟蹊径选择单线程,要理解这一点我们就要先了解多线程的开销。
首先我们先明确两个概念,并行与并发:
并发(concurrency):指在同一时刻只能有一条指令执行,但多个进程指令被快速的轮换执行,使得在宏观上具有多个进程同时执行的效果,但在微观上并不是同时执行的,只是把时间分成若干段,使多个进程快速交替的执行。
并行(parallel):指在同一时刻,有多条指令在多个处理器上同时执行。所以无论从微观还是从宏观来看,二者都是一起执行的。
可以看到对于并发场景来说在同一时刻只能有一条指令被执行,只不过处理器的处理速度极快,处理器在不同的线程来回中**切换**,给我们造成了一种所有指令同时运行的假象,这也就是为什么我们能够在电脑中同时运行超过我们CPU核心数的进程。注意到我们前面说的**线程的切换**,实际上这个操作**是需要花费很多时间的。**
CPU分配给每个线程的执行时间,我们一把称作时间片。时间片一般为几十毫秒。CPU通过时间片分配算法来循环执行任务,当前任务执行一个时间片后切换到下一个任务。但是我们思考一个这样的问题,时间片是一定的,但是任务所需时间是不一定的,也就是在时间片结束前,任务可能不能完全完成,那么我们就需要保存上一次任务的状态,以便下一次的再处理。所以**任务从保存到再加载的过程就是我们常说的线程的上下文切换**。对于redis这种应用于经常要处理海量数据的数据库来说,这个消耗成本是不可接受的。另外多线程编程模式下,还会面临对共享资源的并发访问的控制问题。
**二.单线程的redis为什么快**
通常来说,单线程的处理能力要比多线程差很多,但是 Redis 却能使用单线程模型达到每秒数十万级别的处理能力,这是为什么呢?其实,这是 Redis 多方面设计选择的一个综合结果。
一方面,Redis 的大部分操作在内存上完成,再加上它采用了高效的数据结构,例如哈希表和跳表,这是它实现高性能的一个重要原因。另一方面,就是 Redis 采用了**多路复用机制**,使其在网络 IO 操作中能并发处理大量的客户端请求,实现高吞吐率。
下面我们深入的探讨一下网络中的基本IO模型,和多路复用机制的优点。
**三.redis用的多路复用机制好在哪?**
在这里我们主要介绍:阻塞式IO、非阻塞式IO和多路复用。
(1)阻塞式IO
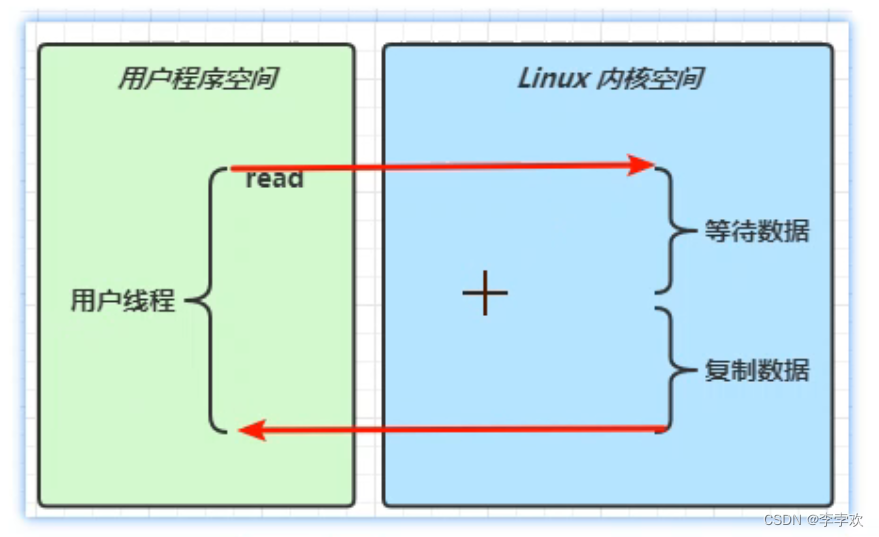 如上图所示,首先解释用户程序空间和内核空间:在java中用read方法从网络上读取数据,需要由操作系统来做这个事情,这里就涉及到用户空间和内核空间的切换,操作系统中有一个read方法来真正完成数据读取。而真正读取数据又分为两个阶段,等待数据和复制数据(从网卡读到内存),等复制结束了再从操作系统内核空间将数据传输到用户程序空间。所谓阻塞式IO模式就是在读取数据期间,内核空间等待数据和复制数据的过程中,用户线程啥活都做不了。
(2)非阻塞式IO
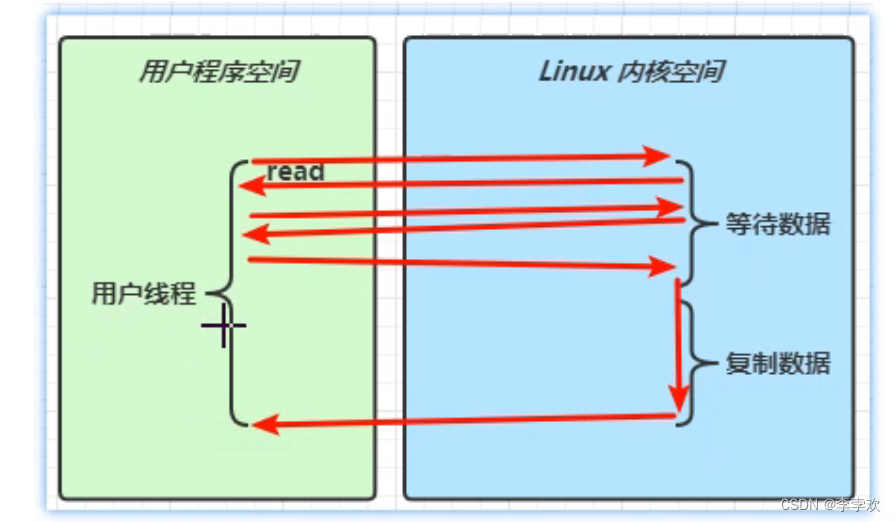
如上图所示,非阻塞IO在等待数据阶段没有读取到数据会直接返回,然后不断地重复这个过程,用户线程始终是运行状态。不过,真正在复制数据的阶段用户线程依然是阻塞住的。
(3)多路复用
可以看到,阻塞式IO会一直阻塞住等待内核的返回结果,这一等不仅可能会等到海枯石烂,而且还干不了其他活啊,于是出现了非阻塞式IO,我不能傻傻的等着啊,于是乎,在非阻塞的情况下,我们需要在一个循环中不断地查询内核,“哥,数据准备好没有啊?”,如果没有准备好,内核会返回给我们一个EWOULDBLOCK的错误,相比于阻塞式IO呆呆地等在原地啥也不干,非阻塞显然可以在循环中处理一些其他事情,当然,频繁的进行系统调用,这是会耗费大量的CPU资源的。那么,阻塞式IO和非阻塞式IO都存在相应的问题,不过我们细细分析一下可以发现,不对啊,为啥要我一直来问内核呢,内核你数据准备好通知我一声不就好了嘛。
没错,这就是IO多路复用的设计初衷,我们熟悉的select/poll/epoll就是为了实现这种想法,同时能够支持多个套接字的网络事件,具体差别不展开讲了。简单来说,在 Redis 只运行单线程的情况下,该机制允许内核中,同时存在多个监听套接字和已连接套接字。内核会一直监听这些套接字上的连接请求或数据请求。一旦有请求到达,就会交给 Redis 线程处理,这就实现了一个 Redis 线程处理多个 IO 流的效果。看到没,redis使用单线程+多路复用的机制实现了并发处理海量数据的目的。redis并不会阻塞在某一个特定客户端请求处理上,也不会像非阻塞式IO一样不断轮询看是否有请求发生,而是不断地去对内核通知的请求进行处理。
四.启示
最后提醒一点,我们通常说,Redis 是单线程,主要是指 Redis 的网络 IO 和键值对读写是由一个线程来完成的,这也是 Redis 对外提供键值存储服务的主要流程。但 Redis 的其他功能,比如持久化、异步删除、集群数据同步等,其实是由额外的线程执行的。
这给我们带来什么启示?在生活中难免遇到各种各样的琐事,我们应该像redis一样,理清楚主要矛盾,将主要精力集中在你最想做的事情上,而不是什么事情都耗费很大的精力,这样才能做出成绩,加油吧。
本文转载自: https://blog.csdn.net/weixin_61543601/article/details/124696086
版权归原作者 李孛欢 所有, 如有侵权,请联系我们删除。
版权归原作者 李孛欢 所有, 如有侵权,请联系我们删除。