
1、初期检查
前期环境准备:anaconda、pycharm版本不作具体要求
windows10打开命令行
1.1 检查conda是否安装好

1.2 检查pycharm是否安装好,直接看自己是否安装过就好
Windows用户: win+R -> 输入cmd 然后点击“运行” -> 输入nvidia-smi 检查是否有显卡信息


1.2 CUDA版本
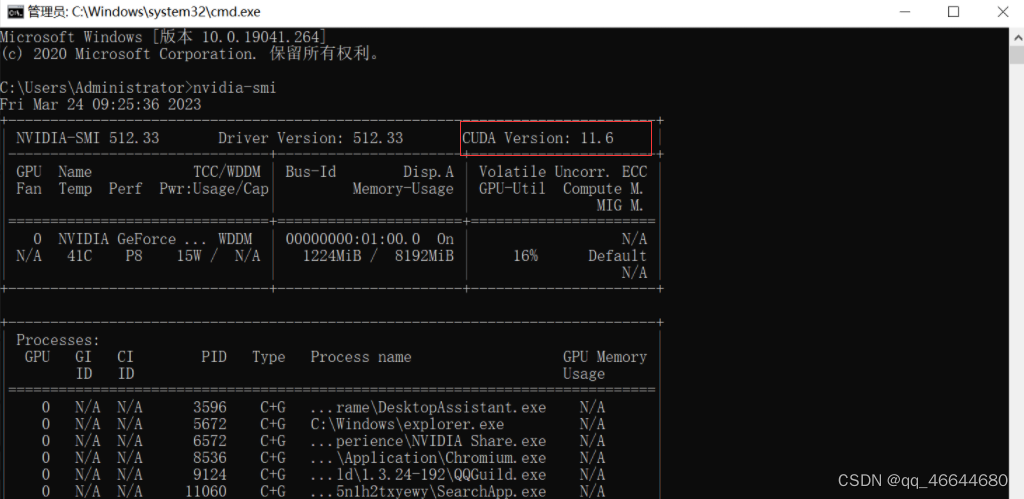
如果你打不开
nvidia-smi
或者cuda查看不了, 那么请官网安装下驱动和应该有的工具包.
NVIDIA GeForce 驱动程序 - N 卡驱动 | NVIDIA https://www.nvidia.cn/geforce/drivers/
安装cuda
CUDA Toolkit Archive | NVIDIA Developer
安装驱动的时候安装合适的cuda版本和cuDNN版本 (用于神经网络加速. 但是这里似乎不用着急下载, 因为PyTorch自带cuDNN, 所以可能只下载安装cuda即可).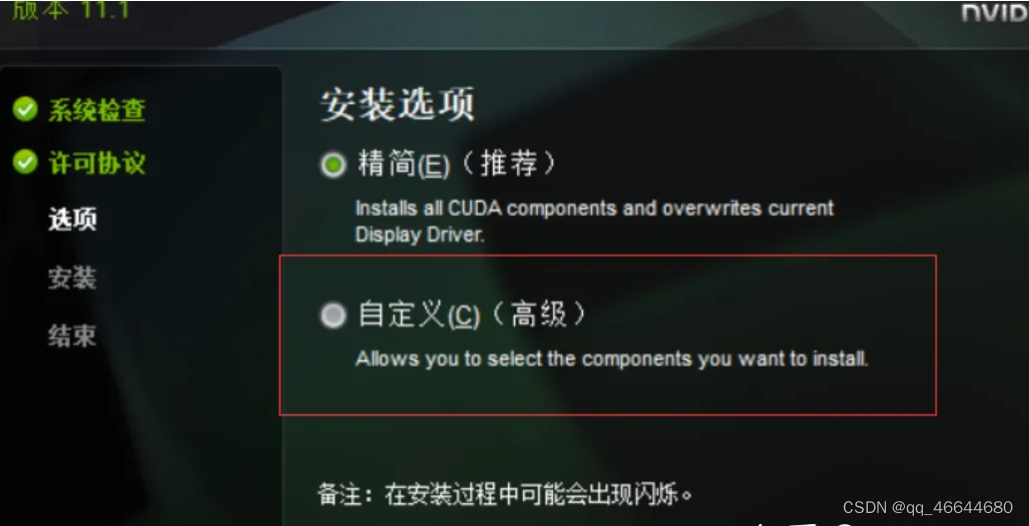
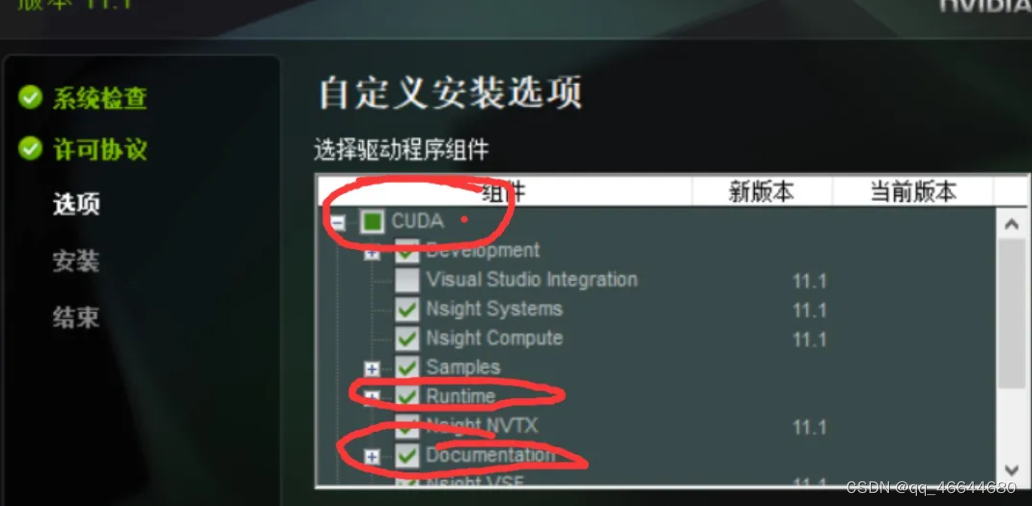
只需要安装红框里的就可以. 其他的应该是不需要安装的. 当然如果为了保险起见那就都安装吧.
runtime是运行时dll, 用于Python调用, 我们用的是这个
development看名字就知道是用来搞开发的, 比如做游戏或者游戏引擎?
visual studio integration看名字就知道是vs插件, 这里不需要
nsight这个系统应该也是开发英伟达显卡特殊程序的, 不需要.
samples是样例程序. 不需要(用于显卡应用开发)
documentation是文档, 其实也可以不需要, 但是这东西体积不大, 下载下来就当练英语阅读了.
安装完成后运行
nvidia-smi
查看版本.
2.1. 国内拉跨外网访问的下载拯救办法
把那个命令后面的网址, 复制一下, 直接浏览器打开(也可以在清华源下载,这里放上链接Simple Indexhttps://pypi.tuna.tsinghua.edu.cn/simple)

打开后是这个样子

然后看PyTorch生成的命令让我们安装什么?

那就分别安装这三个即可.
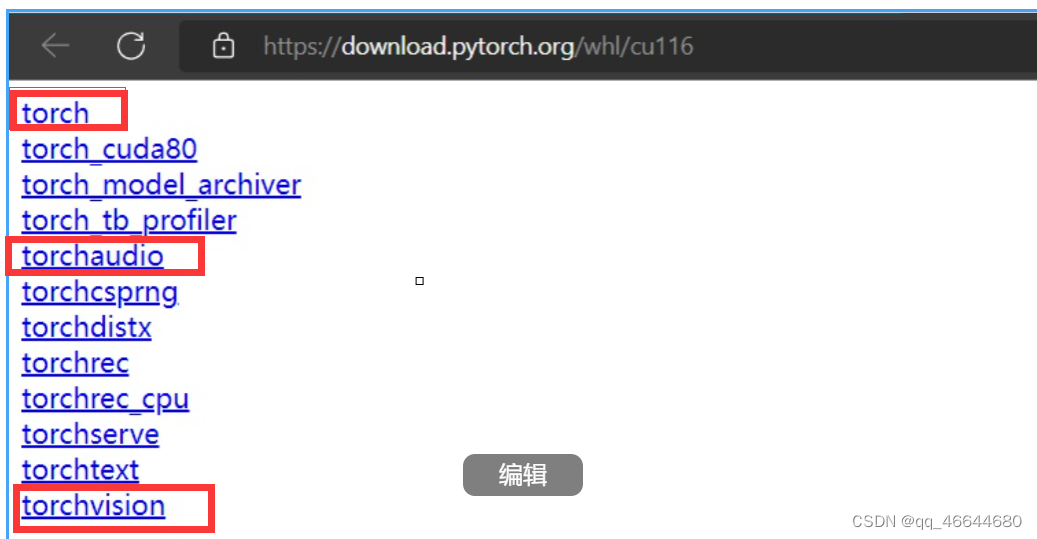
如果下载太慢请使用迅雷之类的工具加速.
比如先安装torch, 点击进去, 会看到一溜子.whl文件, 你要挑一个合适的版本下载
首先肯定下载最新版, 其次必须匹配你的cuda版本, 然后Python版本也得合适, 然后操作系统也得匹配, 最后, 处理器架构得合适.
比如我的计算机是cuda11.6, Python3.8.5(py3.8), Windows10系统(WindowsNT内核), i5-9300H处理器(英特尔的x86处理器), 那么就选择这个就好了.
单击下载. 如果下载太慢请使用迅雷之类的工具加速.

cu116就是cuda11.6的缩写.
cp38的意思是cpython解释器的Python3.8.x版本(如果是独立的Python, 不是基于anaconda的那种那么一般你也安装的就是cpython解释器的Python(就是Python运行时的解释器是拿c语言编写的解释器的那个版本. 还有拿java编译的解释器, 和Python编译的解释器的pypy, 这里这不重要))
**win_amd64指的就是系统是Windows系统, 处理器是64位的复杂指令集的处理器(因为64位是最早AMD搞的, 所以叫
AMD64
, 当然也有叫
x86-64
的. 一般32位操作系统写成只有
x86
或者
IA32
字样.**
2.2 安装方法
这里拿pip举例, 其他包管理器请网上查阅安装方法.
使用pip指定安装的包的路径即可.
最简单的方法
- 打开.whl文件的文件夹
- 按住shift, 右键, 选择"在此处打开PowerShell" (反正就是在这个路径下打开一个终端就行了. 你也可以用cd命令change dir 过去)、进行如下操作
- 键入, 运行
pip install ./torch-1.12.0+cu116-cp38-cp38-win_amd64.whl就可以安装torch了. - 同理, 安装其他包(使用.whl的包名字, 可以tab自动补全)
3. 安装就绪, 开始测试
首先用Python运行下这个指令:
torch.cuda.is_available()
具体方法:
- 打开一个终端
- 运行Python
import torchtorch.cuda.is_available()
如图

返回True那么就是好了. 可以跑显卡了.
如果不行那么就是没安装对, 只能用cpu跑. 肯定是哪里出错了. 回头检查吧......
使用一个程序测试下执行时间, 要不然我不放心
我也是初学者, 可能写的不太行, 但是这个程序很能证明显卡在工作.
import torch
import time
gpu = torch.device('cuda')
# 如果用cpu测试那么注释掉上面的代码, 用下面的
# gpu = torch.device('cpu')
beginTime=time.time()
a=torch.rand(2048,2048)
b=torch.rand(2048,2048)
c=torch.rand(2048,2048)
x = a.to(gpu)
y = b.to(gpu)
z = c.to(gpu)
initTime=time.time()
print("ok")
i=0
while i<10000:
z=(z+x+y)
i+=1
endTime=time.time()
print(z)
print("运行结束, 初始化使用了 {} 秒, 循环用了 {} 秒".format(initTime-beginTime,endTime-beginTime))
版权归原作者 TechMasterPlus 所有, 如有侵权,请联系我们删除。