

在人工智能领域,Meta 近日发布了一款名为“变色龙”(Chameleon)的新型多模态 AI 模型,旨在挑战 OpenAI 的 GPT-4o,并刷新了当前的技术标准(SOTA)。这款拥有 34B 参数的模型通过 10 万亿 token 的训练,不仅展现了强大的跨模态处理能力,还预示着多模态模型未来的发展方向。
AIGC专区:
https://heehel.com/category/aigc
更多消息:
https://heehel.com/category/ai-news
一、Chameleon 模型简介
Chameleon 模型是 Meta AI 推出的新型多模态基础模型,其最大特点在于采用统一的 Transformer 架构,将文本、图像和代码等不同模态的信息作为离散标记进行处理。与以往的模型不同,Chameleon 摒弃了针对不同模态的单独编码器或解码器,通过“早期融合”方法将所有模态从一开始就投影到一个共同的表示空间中,实现了跨模态的无缝推理和生成。
二、技术挑战与创新
虽然“早期融合”方法带来了显著的性能提升,但也给 Meta 团队带来了重大的技术挑战。在训练稳定性和可扩展性方面,Meta 引入了架构创新和训练技术,如 QK 归一化和 Zloss 等训练技巧,以优化模型的性能。
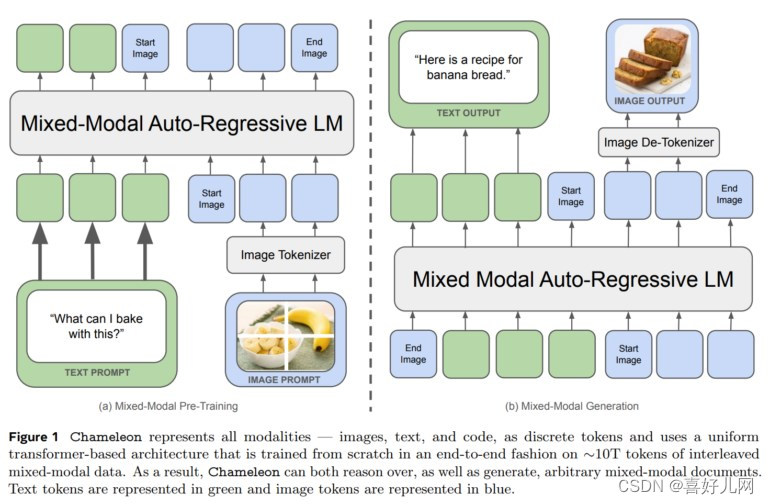
三、性能评估与比较
在纯文本任务中,Chameleon 的性能与 Gemini-Pro 相当,而在视觉问答和图像标注基准测试中,Chameleon 刷新了 SOTA,性能接近 GPT-4V。这表明 Chameleon 在多模态处理方面已经取得了显著的进展。
四、模型特点与开源
虽然 Chameleon 目前还不支持语音能力,但它支持生成图像文本模态,并展现出强大的跨模态生成能力。Meta 表示,他们希望将 GPT-4o 的知识更接近地分享给开源社区,以促进多模态模型的发展。
五、技术细节与训练
Chameleon 采用“混合模态”基座模型,能够生成文本和图像内容任意交织的内容。通过使用 token 将所有模态信息映射到同一向量空间,Chameleon 实现了跨模态的无缝融合。在训练过程中,Meta 采用了两阶段的方法,首先进行无监督学习,然后混合更高质量的数据进行训练。
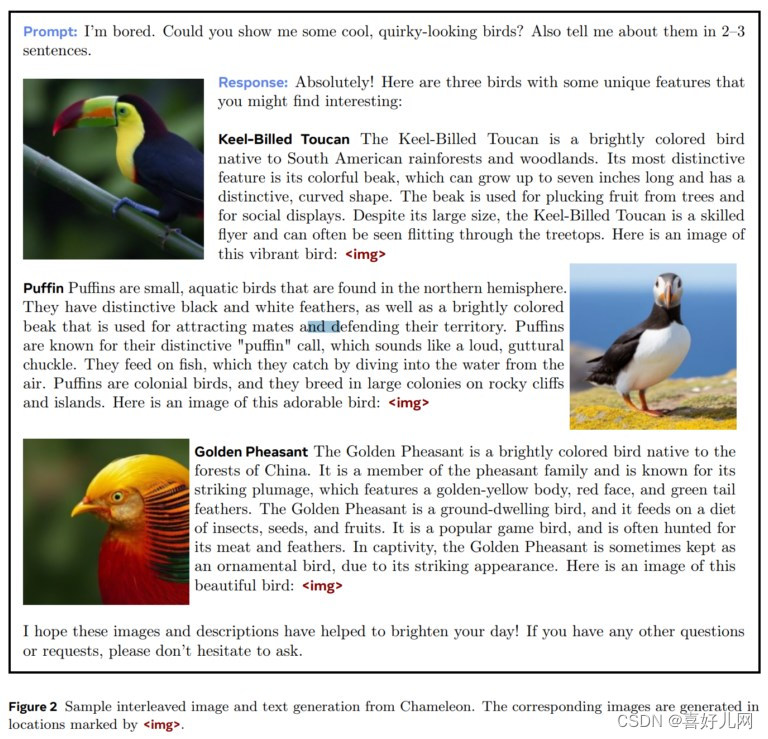
六、图像分词器与预训练
为了将图像信息转化为模型可处理的离散标记,Meta 开发了基于 8192 大小 codebook 的图像分词器。同时,文字分词器则基于 sentencepiece 开源库。在预训练阶段,训练数据包含纯文本、文本-图像对以及文本和图像交错的多模态文档。
七、前景展望
Meta 的人工智能研究员 Armen Aghajanyan 表示,Chameleon 只是 Meta 分享有关下一个规模范式的知识的开始。他们相信“早期融合”多模式模型才是未来。随着技术的不断进步和模型的持续优化,我们有理由期待多模态模型将在未来发挥更加重要的作用。
版权归原作者 喜好儿网 所有, 如有侵权,请联系我们删除。