
GPT在网络安全领域的应用案例
写在最前面
活动介绍
ChatGPT已流行一段时间,各个平台都推出了自己的GPT,比如百度上线了【文心一言】,CSDN推出了【C知道】,在创作的时候也可以使用【AI助手】帮助创作,很多人说GPT的广泛使用可能会使人们失业,会对一些互联网公司的存活造成挑战,那么这个说法是真的吗,你们平时都是在什么情况下使用GPT的呢?为何使用?都使用什么平台的,可以一起聊聊这个话题
活动链接:https://activity.csdn.net/creatActivity
日常生活中,我个人也经常使用GPT技术。
但与此同时,一些行业的大佬们已经将GPT应用到了更高级别的科研任务,并将其发表在行业的顶级期刊中。
在网安领域,GPT技术也展现出巨大的潜力。下面,我们将一同深入研究GPT在网络安全领域的应用案例,探讨其在这一领域的重要性和未来发展趋势。
如果您对GPT技术的广泛应用和在网络安全领域的具体应用感兴趣,欢迎阅读下文,一同学习并探讨这一激动人心的话题。
论文1:Chatgpt/CodeX引入会话式 APR 范例+利用验证反馈+LLM 的长期上下文窗口:更智能的反馈机制、更有效的信息合并策略、更复杂的模型结构、鼓励生成多样性
Conversational Automated Program Repair《对话式自动程序修复》
论文:https://arxiv.org/abs/2301.13246
代码:https://github.com/ASSERT-KTH/RapidCapr
之前对该论文的详情介绍:
https://blog.csdn.net/wtyuong/article/details/134043342
- 引入会话式 APR 范例:引入了一种新的程序修复方法——会话式 APR。与以前的 LLM for APR 方法不同,它采用交互式的生成和验证过程,以提高修复效率和准确性。
- 利用验证反馈:会话式 APR 利用
验证反馈,将先前生成的补丁与测试集进行验证,以改善模型的生成补丁。这种方法有助于模型理解先前错误补丁的问题,并避免重复生成相同的错误补丁。 - LLM 的长期上下文窗口:会话式 APR 允许利用 LLM 的长期上下文窗口,以更好地理解被测程序的语义含义,而
不仅仅是代码片段的信息。 - 广泛的模型评估:作者对包括新开发的 ChatGPT 模型在内的 10 种不同 LLM 进行了广泛评估,证明了会话式 APR 方法相对于以前的 LLM for APR 方法的改进。
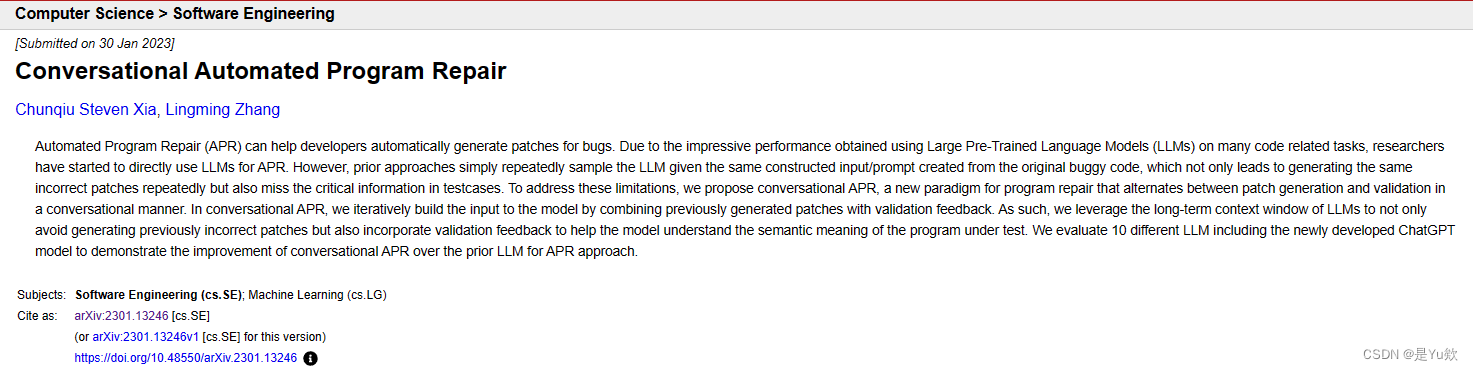
和GPT类似的步骤:Conversational APR 对话式APR
Conversational APR是一种新的APR范式,通过交互式的补丁生成和验证过程提高了程序修复的效率和准确性。
过程:
- 修复生成和验证交错进行,每个回合提供新的输入,包括以前的错误补丁和测试反馈。
- 通过多轮顺序回合(对话链)生成候选修复补丁,直到找到通过所有测试用例的有效补丁或达到最大迭代次数。
好处:
- 反馈的多样性:对话式APR可以应用多种可能的反馈信息,例如人类对补丁的评估。
- 效果改善:与之前只使用buggy code片段作为输入的LLM工具相比,对话式APR通过补丁验证形式的验证反馈来帮助模型理解先前生成的补丁为什么是错误的。通过这种方式,LLM可以识别先前的生成内容,避免重复生成已经验证过的错误补丁。
- 性能提升:通过使用10个流行的LLM进行评估,发现这种方法不仅提高了修复bug的数量,而且与基于采样的基线相比,可以更快地找到正确的补丁。

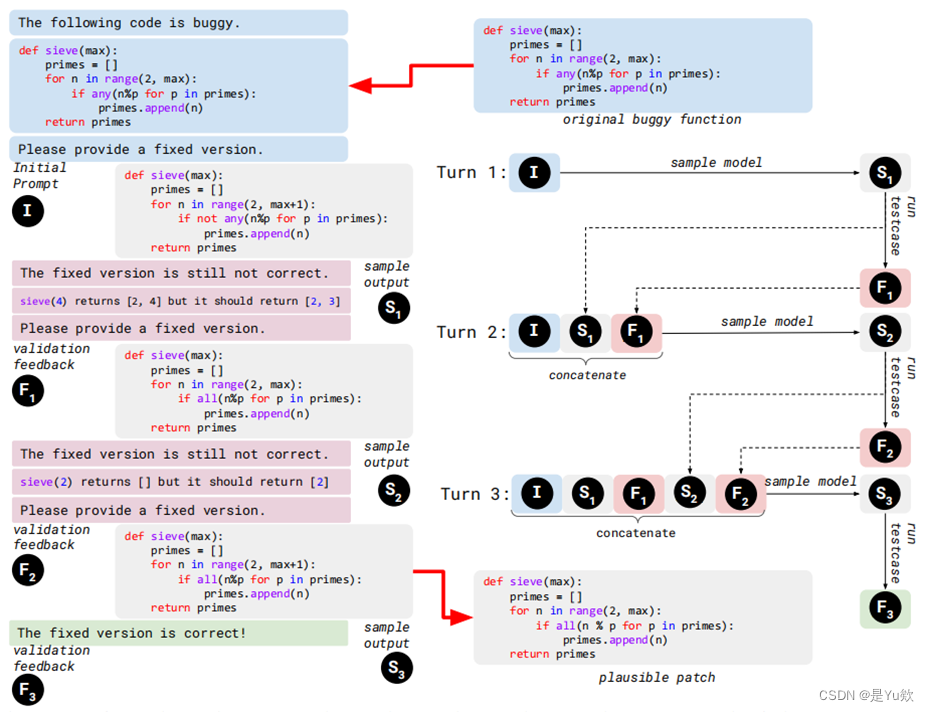
通过使用先前生成的补丁/验证结果作为反馈,从 LLM 迭代获取新的候选补丁,此过程称为轮次。每个轮次包括三个不同的步骤:
(1)根据先前的反馈构建新的提示;
(2)对模型采样以产生样本输出函数;
(3)根据测试用例验证样本输出函数来获取验证反馈。多个按顺序排列执行的轮次称为链。
终止条件是
样本输出补丁能够通过所有测试用例(即获得合理的补丁)
或
达到最大轮数(即链达到最长的长度)
。
Turn 1:
首先使用原始buggy function创建一个初始提示I,这个提示使用自然语言来表明该函数有缺陷(e.g. The following code is buggy)以及希望LLM解决的任务(e.g. Please provide a fixed version)。
然后,使用初始提示 I 对模型进行采样,获得第一个样本输出函数 S1 。 对第 4 行进行了更改: S1 中的函数否定了原始 if 条件。
然后,根据测试列表验证 S1:新补丁能够成功通过先前失败的 sieve(2) = [2] 测试,但是无法 通过sieve(4) 测试。 该验证信息 F1 被收集作为反馈,在下一个对话轮次期间使用。
Turn 2:
使用Turn 1中失败的测试用例构建验证反馈 F1,并向模型表明之前的样本 S1 仍然不正确(The fixed version is still not correct)和新任务(Please provide another fixed version)。
然后将初始提示、第一个样本输出函数和验证反馈 { I , S1 , F1 } 连接在一起作为 LLM 的输入。
该模型不仅能够使用原始的buggy function,还能够使用先前生成的样本及其测试用例反馈来生成新的修补函数。
与Turn 1一样,本轮结果获得 S2 和 F2,在保证第4行是正确的前提下,候选补丁函数将 for 循环的上限范围减小了 1。
Turn 3:
首先根据之前失败的测试用例构建新的验证反馈 F2。
然后按顺序连接所有先前采样的输出及其验证反馈,生成 { I , S1 , F1 , S2 , F2 } 。
使用此输入再次对 LLM 进行采样以生成下一个候选补丁 S3 。
这时候选补丁修复了bug,并且能够通过所有测试用例,即S3是本次的plausible 补丁至此,程序修复过程终止。
设计决策
Prompt engineering
Prompt是在各种downstream任务中利用LLM的有效方法,并且不需要任何明确的微调。
在会话式 APR 中,本文提供的任务提示遵循Xia et al.[1]的风格。本文还遵循先前的指导方针,保证prompt是开放式的,避免generation被限制。
[1]. Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V. Le, Denny Zhou: Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. NeurIPS 2022
Maximum chain length
最大链长度是终止条件之一。所使用的 LLM 具有最大上下文窗口并且不能采用任意长度输入。 一旦达到最大链长度,会话 APR 将从头开始(即通过再次制作initial prompt)并使用新的链会话。 最大链长度是控制 LLM 可以接收多少历史记录的参数。 较小的最大链长度意味着模型生成的不正确补丁较少,对最终的结果的正确性有影响。 较大的最大链长度意味着模型可以看到多个先前失败的补丁,但这也可能没有好处,因为它可能导致 LLM 重复一些早期的补丁或卡在函数的特定实现上。
论文2:ChatGPT+自协作代码生成+角色扮演+消融实验
Yihong Dong∗, Xue Jiang∗, Zhi Jin†, Ge Li† (Peking University)
arXiv May 2023
Self-collaboration Code Generation via ChatGPT《基于ChatGPT的自协作代码生成》
这篇论文是chatgpt的黑盒api调用,因此没有关于模型的微调等操作,更多的是提示工程的框架设计(后面同学提到,和思维链的工作有相通之处)
论文:https://arxiv.org/pdf/2304.07590.pdf
之前对这篇论文的详情介绍:
https://blog.csdn.net/wtyuong/article/details/133905690
1.框架性的idea也是一种方向,有时也可以带来显著的结果,在AI领域不止有提升算法的思路。
2.实现这种idea也需要严谨完整的推理和验证,将high-level的想法落到细节
3.作者的结论里说明了自协作架构还是要结合人类程序员的指导,避免系统脱离需求,这说明ChatGPT暂时还不能完全自主地工作
代码生成与自协作框架 摘要
目的: 代码生成旨在生成符合特定规范、满足人类需求的代码,以提高软件开发效率和质量,甚至推动生产模式的转变。
创新点: 本研究提出了一种自协作框架,使大型语言模型(LLM,例如ChatGPT)能够应对复杂的代码生成任务。
方法: 该框架首先为三个不同角色的大型语言模型分配任务,包括分析员(analyst,负责需求分析)、程序员(coder,负责编写代码)、测试员(tester,负责检验效果),然后通过软件开发方法(SDM)规定了这些角色之间的交互方式。
结果: 通过所提出的自协作框架,相较于ChatGPT3.5,实验结果显示在四种不同基准测试中,Pass@1的性能提高了29.9%至47.1%。

自协作框架原理
1、DOL任务分配
根据任务分配角色指令,然后将对应的任务传递给角色
2、共享黑板协作
不同角色间,将输出的信息共享
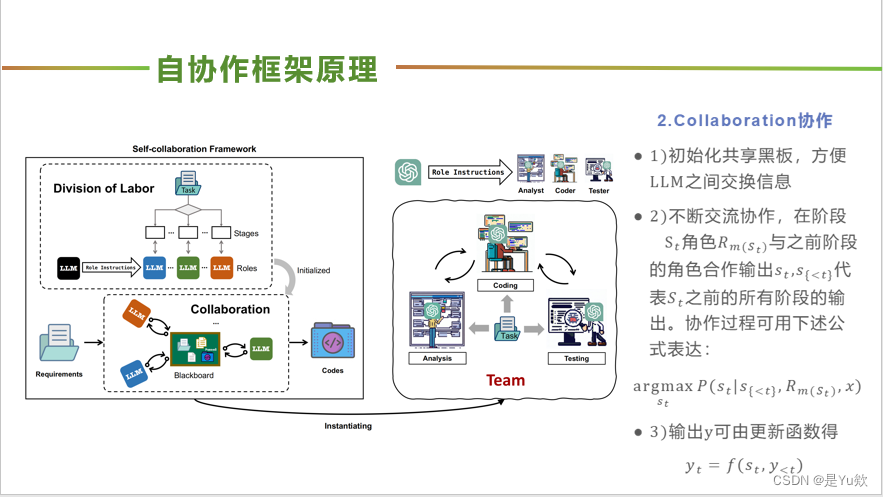
3、Instance实例化
3.Instance实例化
1)采用SDM中的经典瀑布模型 [Petersen et al., 2009],简化为三个阶段:分析、编码、测试。
2)分析员:生成一个高维的计划,着重指导程序员。程序员:根据分析员的计划写代码;根据测试员的测试报告修改代码。测试员:从功能性、可读性和可维护性评判程序员的代码
3)终止条件:达到最大交互次数n或者测试员报告没有错误
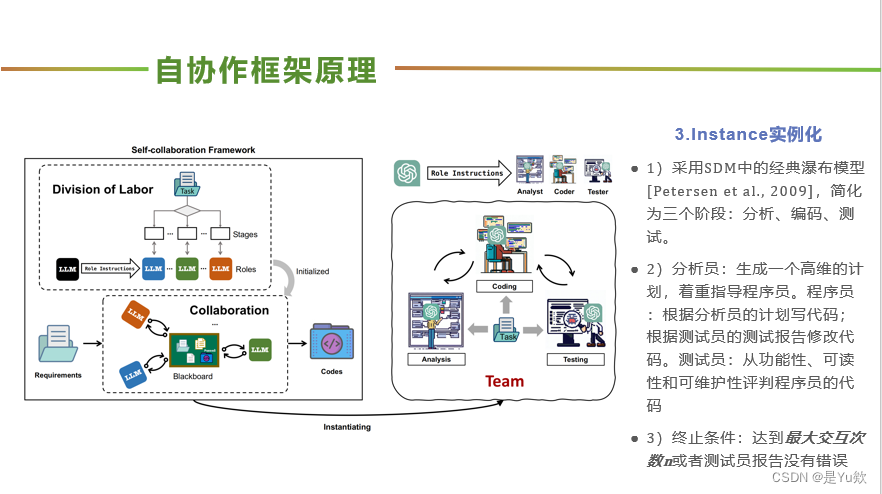
案例说明
简单任务:基本操作
1)分析员:分解任务
+制定high-level计划
2)程序员:按照计划生成对应代码
3)测试员:检验代码的功能性和边缘测试情况,反馈错误让程序员修改

复杂任务:游戏开发
未展示训练过程,仅说明结果
满足所有游戏逻辑,保障了精确的角色控制,设置正确的碰撞检测,必要的游戏资产加载和适当的图像缩放。此外,注意到了没有直接规定但是符合常识的游戏逻辑,比如炸弹掉落至底部后会被重置位置
单个LLM只能生成脚本的粗略草稿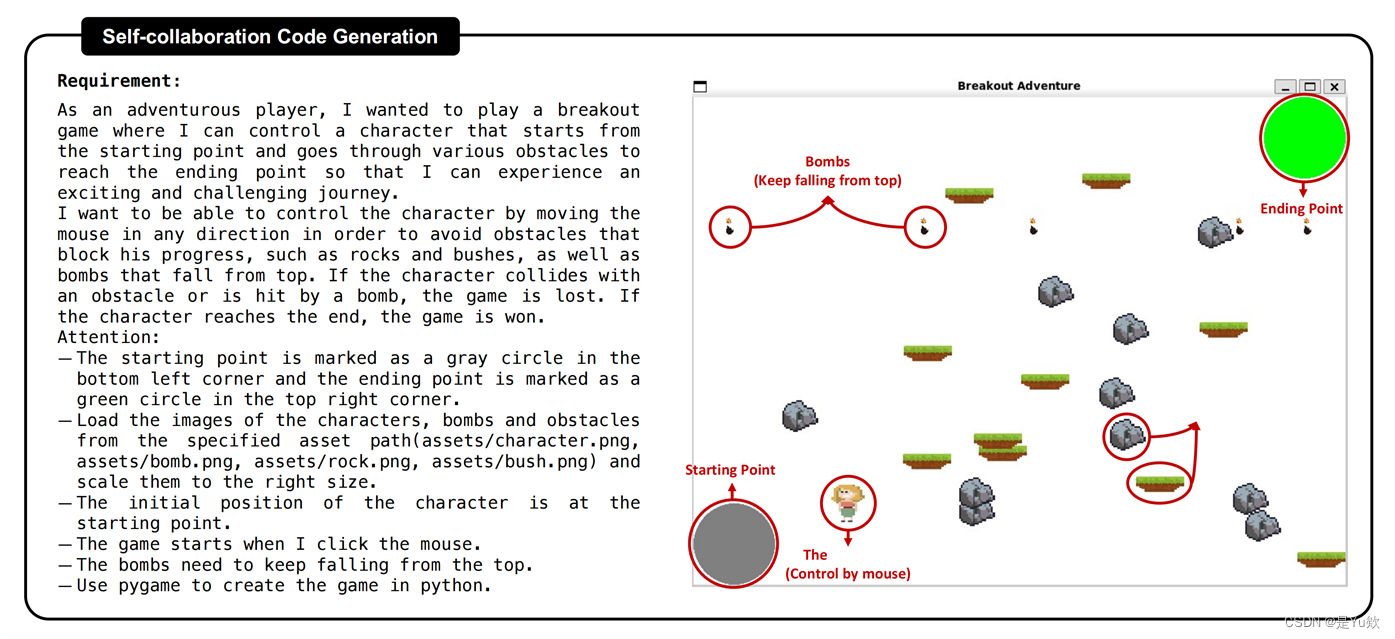
论文3:ChatGPT+漏洞定位+补丁生成+补丁验证+APR方法+ChatRepair+不同修复场景+修复效果(韦恩图展示)
Chunqiu Steven Xia, University of Illinois Urbana-Champaign
Lingming Zhang, University of Illinois Urbana-Champaign
Keep the Conversation Going: Fixing 162 out of 337 bugs for $0.42 each using ChatGPT
arXiv 2023.4.1
论文:https://arxiv.org/pdf/2304.00385.pdf
之前对这篇论文的详情介绍:
https://blog.csdn.net/wtyuong/article/details/133906940
方法概述overview
这页PPT:将总览图黑色虚线框出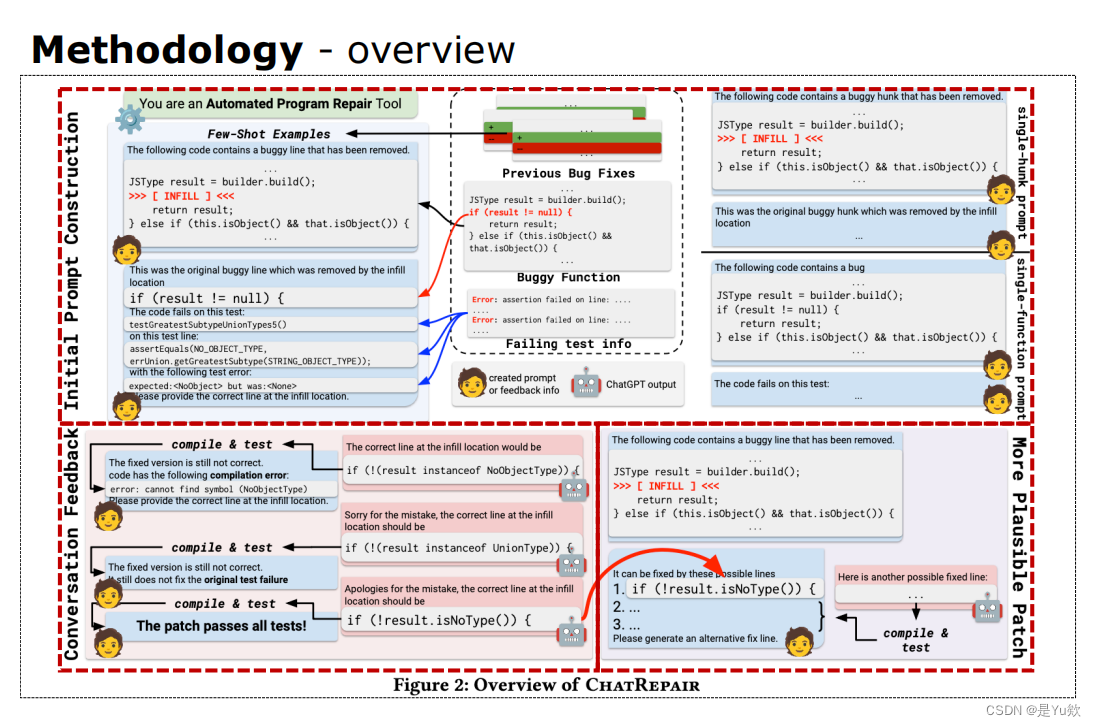
建立初始 prompt,得到第一个 patch
通过 test suite 判断 patch 是否成立
- 如果成立进入下一阶段
- 如果不成立持续询问 Chatgpt 直到获取一个 plausible patch
输入已经获取的 plausible patch 及相关信息,获取更多 plausible patch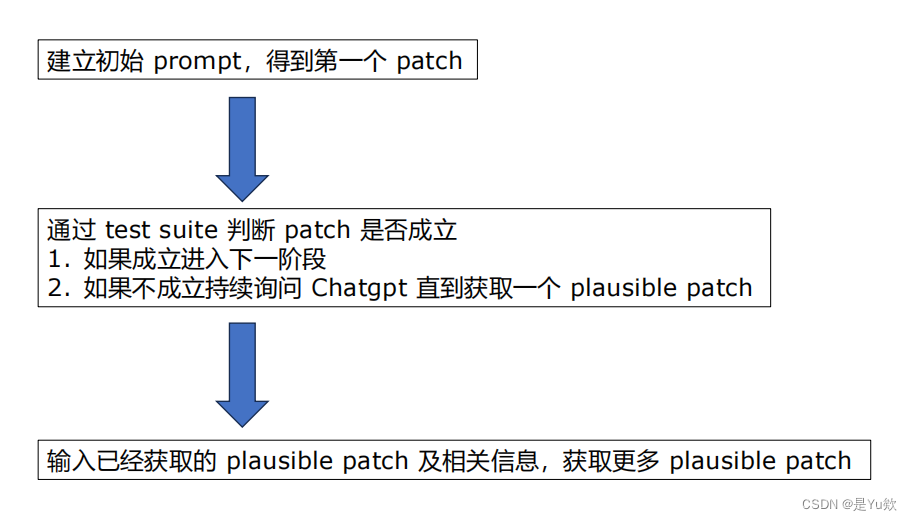
可信的补丁:通过测试套件的补丁
plausible patches: patches that pass the test suite
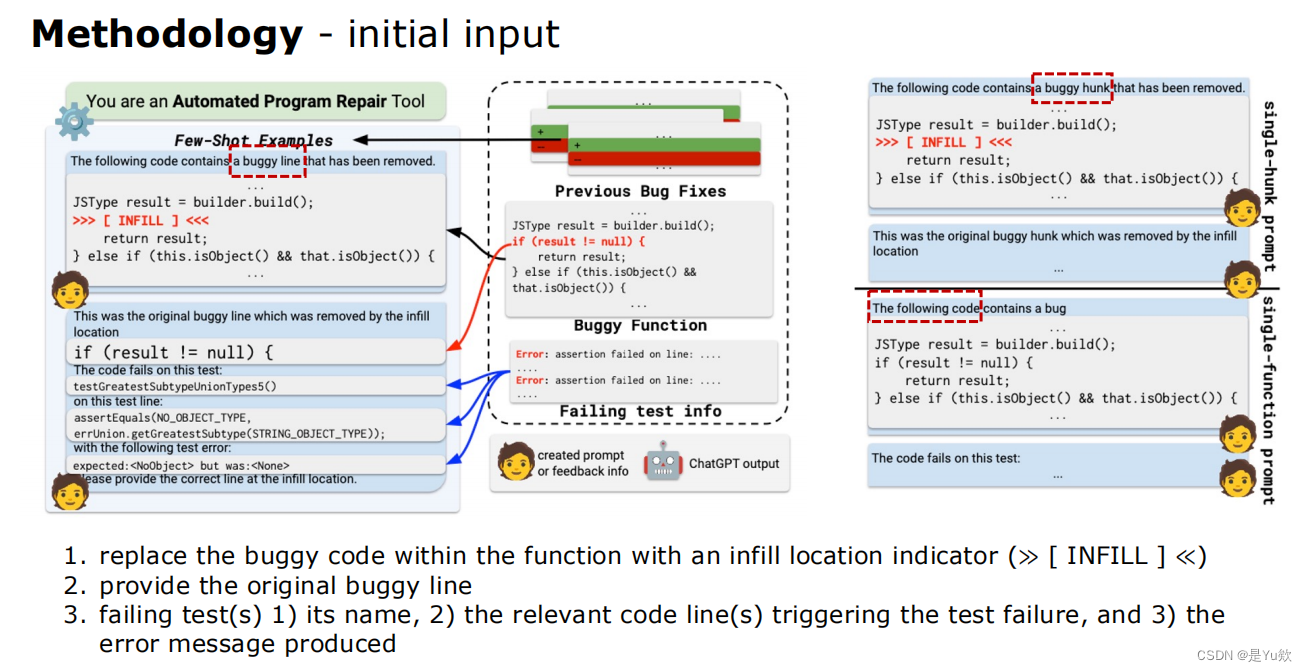
① 建立初始 prompt,得到第一个 patch
初始输入initial input(通过红色虚线方框突出重点)
1、
初始提示符:您是一个自动程序修复工具
初始 prompt:You are an Automated Program Repair Tool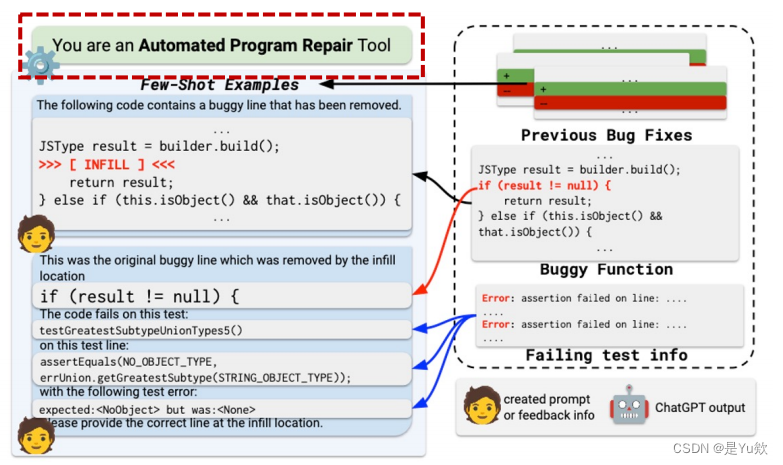
2、
在同一个bug项目中包含一些历史bug修复的例子
include a few examples of historical bug fixes within the same buggy project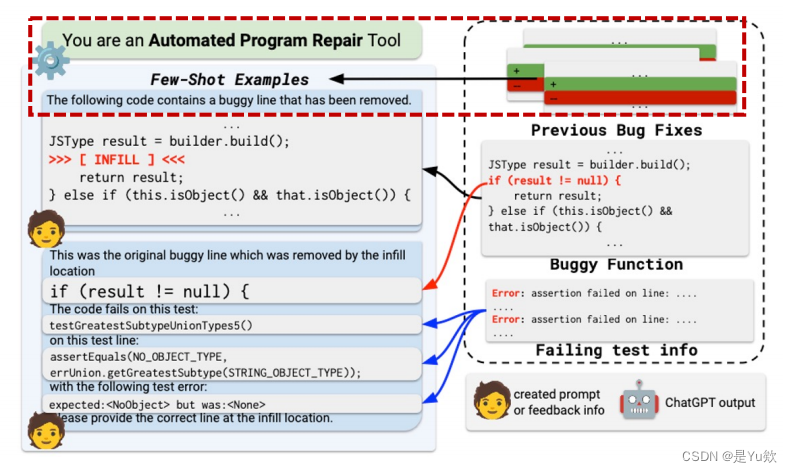
少样本通过这样做,我们将模型调整到修复任务并允许它
few-shot examples By doing so, we gear the model towards the repair task and allow it
学习任务的所需输出格式(即补丁)。
to learn the desired output format (i.e. a patch) of the task.
3、
用填充的位置指示器替换函数中有错误的代码完全≪≫
replace the buggy code within the function with an infill location indicator (≫ [ INFILL ] ≪)
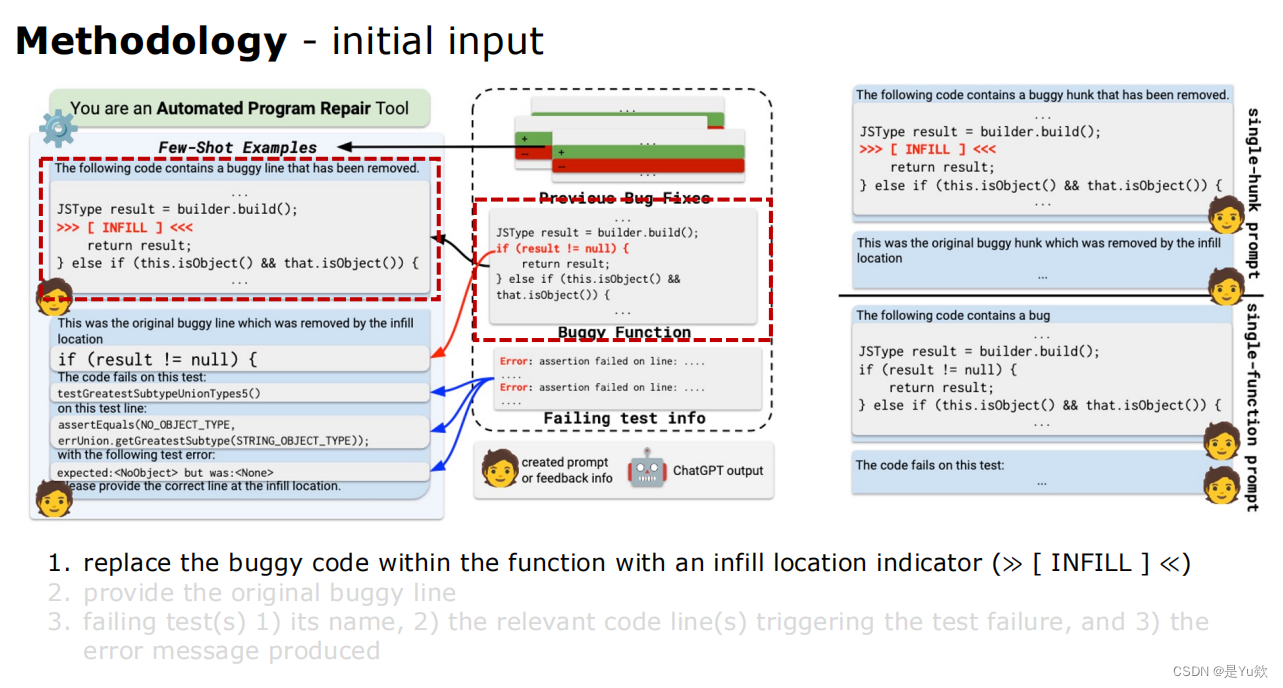
4、
提供原始的bug行
provide the original buggy line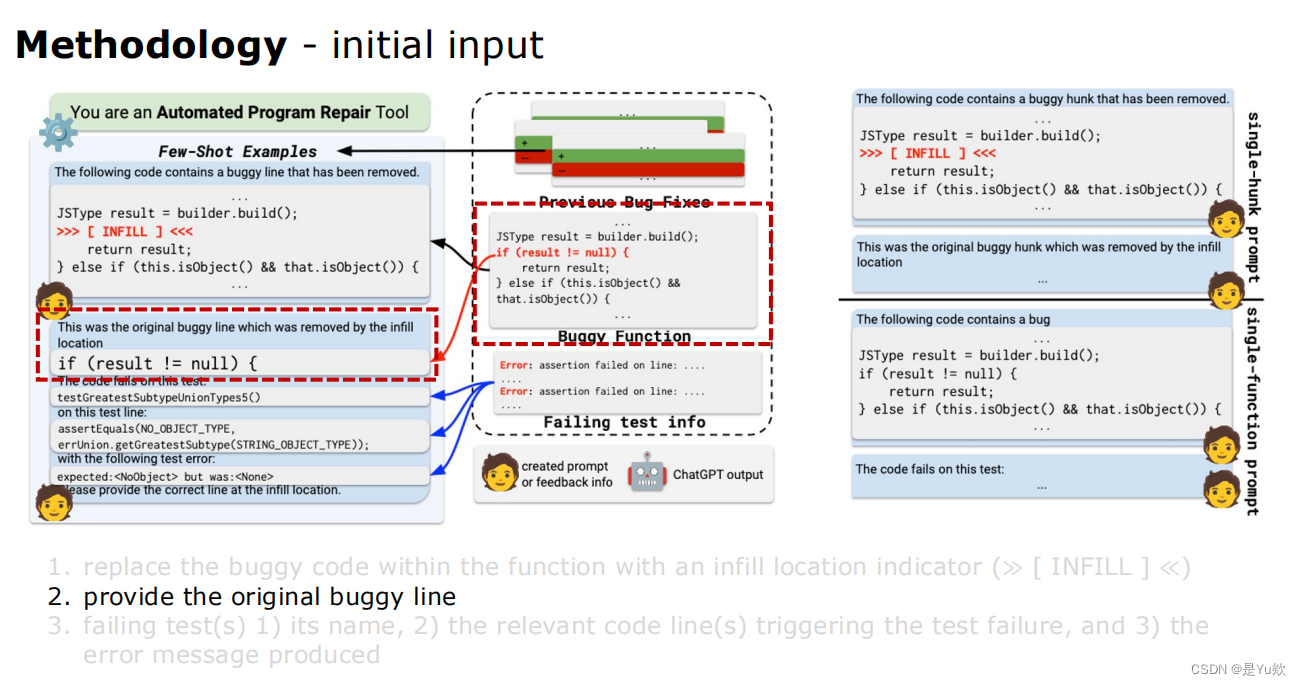
5、
失败的测试1)它的名称,2)触发测试失败的相关代码行,以及3)产生的错误信息
failing test(s) 1) its name, 2) the relevant code line(s) triggering the test failure, and 3) the error message produced
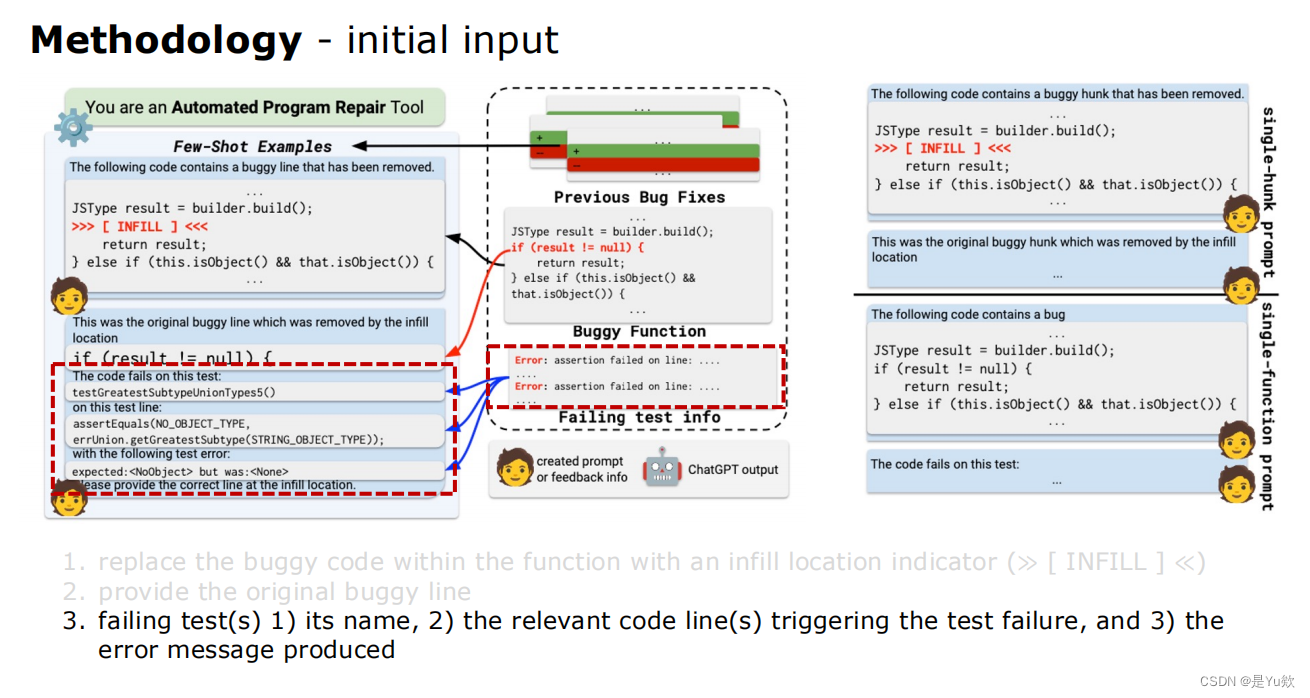
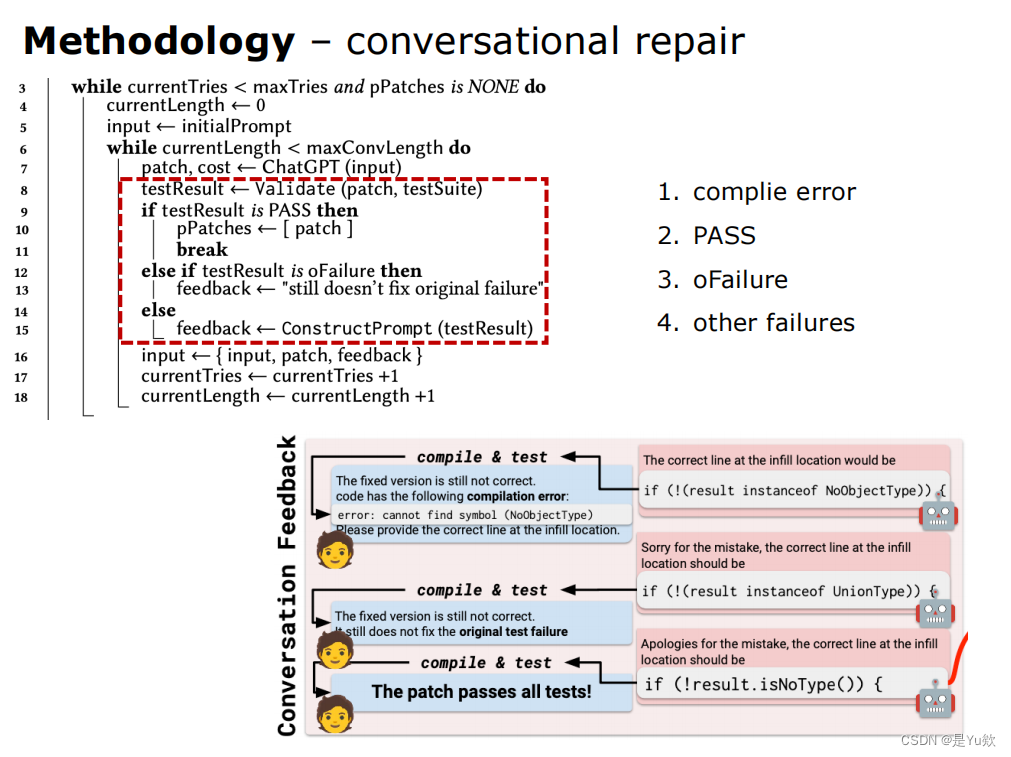
②通过 test suite 判断 patch 是否成立
- 如果成立进入下一阶段
- 如果不成立持续询问 Chatgpt 直到获取一个 plausible patch
可信的补丁:通过测试套件的补丁
plausible patches: patches that pass the test suite
③ 输入已经获取的 plausible patch 及相关信息,获取更多 plausible patch
可信的补丁:通过测试套件的补丁
plausible patches: patches that pass the test suite
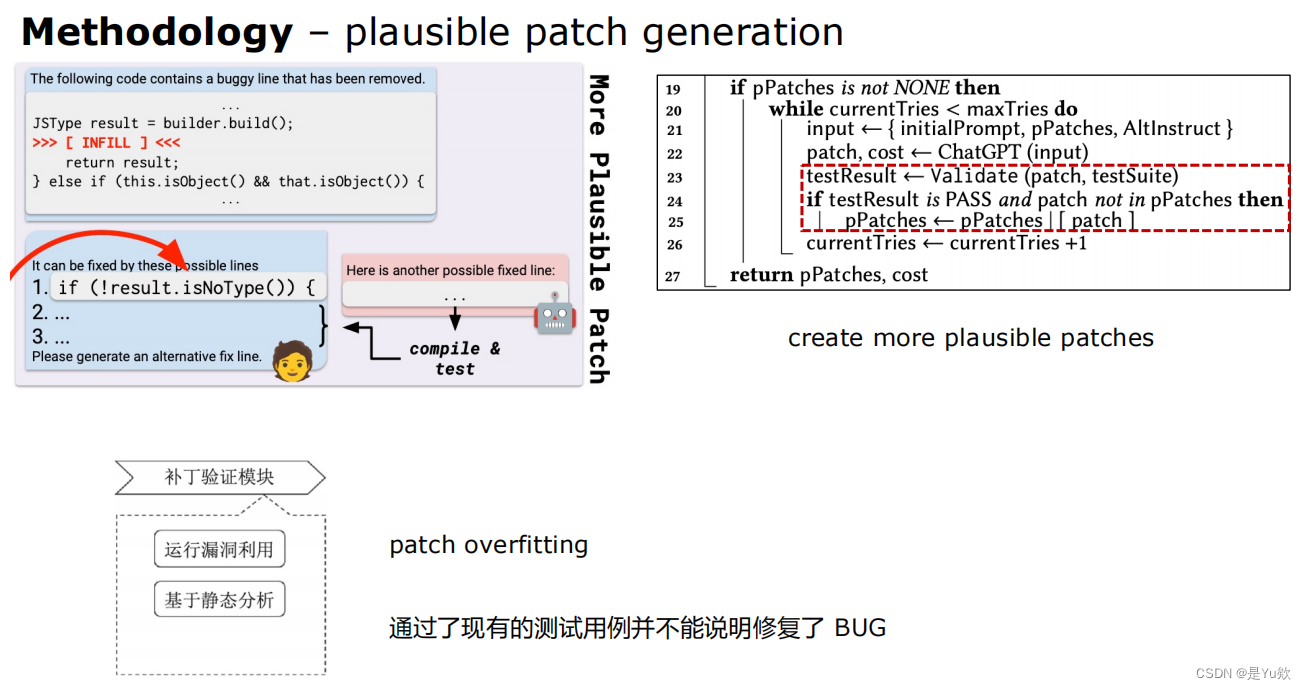
最后两个步骤

版权归原作者 是Yu欸 所有, 如有侵权,请联系我们删除。