
正则化——参数范数惩罚
正则化的定义:“对学习算法的修改——旨在减少泛化误差而不是训练误差。”
直观理解:正则化就是用来减少模型过拟合的一种策略。
接下来介绍的是正则化最常见的方法之一——对模型的权重进行
L
1
L^1
L1 和
L
2
L^2
L2 正则化。
所谓的
L
1
L^1
L1 和
L
2
L^2
L2 正则化,其实就是利用了
L
1
L^1
L1 和
L
2
L^2
L2 范数,来规范模型参数(权重
w
w
w)的一种方法。
范数,我们可以理解为就是对空间中两点的距离这个概念进行了扩充。例如权重
w w w,它是一个高维向量,也可以理解为是空间中的一个点,它到原点的距离,如果是曼哈顿距离的话就是 L 1 L^1 L1 范数,如果是欧氏距离的话就是 L 2 L^2 L2 范数。
L 0 L^0 L0 范数:向量中非零元素的个数。L 1 L^1 L1 范数: ∣ ∣ W ∣ ∣ 1 = ∣ w 1 ∣ + ∣ w 2 ∣ + . . . + ∣ w i ∣ ||W||_1 = |w_1| + |w_2| + ... + |w_i| ∣∣W∣∣1=∣w1∣+∣w2∣+...+∣wi∣ (曼哈顿距离)L 2 L^2 L2 范数: ∣ ∣ W ∣ ∣ 2 = ∣ w 1 ∣ 2 + ∣ w 2 ∣ 2 + . . . + ∣ w i ∣ 2 ||W||_2 = \sqrt{|w_1|^2 + |w_2|^2 + ... + |w_i|^2} ∣∣W∣∣2=∣w1∣2+∣w2∣2+...+∣wi∣2 (欧氏距离)
由于真正带来过拟合问题的是权重
w
w
w,为了简单起见,在下面的讨论中,我们只重点考虑
w
w
w。
1. L2 参数正则化
L
2
L^2
L2 参数正则化通常被称为**权重衰减**,它通过向目标函数添加一个 正则项
Ω
(
θ
)
=
1
2
∣
∣
w
∣
∣
2
2
\Omega(\theta) = \frac{1}{2}||\pmb{w}||^2_2
Ω(θ)=21∣∣www∣∣22 ,使权重更加接近原点。
那么问题来了:
L
2
L^2
L2 参数正则化为什么被称为权重衰减呢?他是怎么使权重得到衰减的呢?
损失函数:
J ( w , b ) J(\pmb{w}, b) J(www,b)权重更新:
w = w − ϵ ⋅ ▽ w J ( w ) \pmb{w} = \pmb{w} -\epsilon\cdot\bigtriangledown_w{J(\pmb{w})} www=www−ϵ⋅▽wJ(www)对于损失函数
J ( W , b ) J(W, b) J(W,b) ,我们想要找到一组参数 ( w ∗ , b ∗ ) (\pmb{w}^*, b^*) (www∗,b∗) 来 minimize J ( w , b ) J(\pmb{w}, b) J(www,b) 。
为了简单起见,我们只考虑权重
w
w
w,这样模型的目标函数就是:
J
~
(
w
;
X
,
y
)
=
α
2
w
T
w
+
J
(
w
;
X
,
y
)
\widetilde{J}(\pmb{w}; \pmb{X}, \pmb{y}) = \frac{\alpha}{2}w^Tw + J(\pmb{w}; \pmb{X}, \pmb{y})
J(www;XXX,yyy)=2αwTw+J(www;XXX,yyy)其中,
α
∈
[
0
,
∞
)
\alpha \in [0, \infty)
α∈[0,∞) 被称为衰减率,是权衡范数惩罚项
Ω
\Omega
Ω 和 标准目标函数
J
J
J 相对贡献的超参数。将
α
\alpha
α 设置为0表示没有正则化;
α
\alpha
α 越大,对应正则化惩罚越大。在求解过程中,我们通过缩放惩罚项
Ω
\Omega
Ω 的超参数
α
\alpha
α 来控制
L
2
L^2
L2 权重衰减的强度。
与目标函数对应的梯度为:
▽
w
J
~
(
w
;
X
,
y
)
=
α
w
+
▽
w
J
(
w
;
X
,
y
)
\bigtriangledown_w\widetilde{J}(\pmb{w}; \pmb{X}, \pmb{y}) =\alpha w + \bigtriangledown_wJ(\pmb{w}; \pmb{X}, \pmb{y})
▽wJ(www;XXX,yyy)=αw+▽wJ(www;XXX,yyy)
使用单步梯度下降来更新权重:
w
←
w
−
ϵ
(
α
w
+
▽
w
J
(
w
;
X
,
y
)
)
w \leftarrow w - \epsilon(\alpha w + \bigtriangledown_wJ(\pmb{w}; \pmb{X}, \pmb{y}))
w←w−ϵ(αw+▽wJ(www;XXX,yyy))
换种写法就是:
w
←
(
1
−
ϵ
α
)
w
−
ϵ
▽
w
J
(
w
;
X
,
y
)
w \leftarrow (1 - \epsilon\alpha)w - \epsilon\bigtriangledown_wJ(\pmb{w}; \pmb{X}, \pmb{y})
w←(1−ϵα)w−ϵ▽wJ(www;XXX,yyy)
我们可以看到,加入权重衰减后会引起学习规则的修改,在每次执行梯度更新前都会先收缩权重向量。
这样,对于权重衰减,我们可以直观地理解为:权重衰减就是增加了一些惩罚项去惩罚权重,每一次学习都惩罚一点,让权重不至于取值太大。
前面介绍的是
L
2
L^2
L2 正则化在单步梯度下降中对权重的影响,那么它在训练的整体过程会产生什么样的影响呢?
首先先要明确一下我们的目标,我们的目标是想要控制一下参数,使参数的取值不要太大。按照这种思路,我们可以给
w
w
w 划定一个可行域,让
w
w
w 这个区域内进行取值。
可行域:
∣
∣
w
∣
∣
2
−
C
≤
0
||\pmb{w}||_2 - C \leq 0
∣∣www∣∣2−C≤0 (即
w
\pmb{w}
www 在空间中对应的点到原点的距离是
≤
C
\leq C
≤C 的。)
接下来我们从拉格朗日乘数法的角度来理解
L
2
L^2
L2 正则化在整体训练过程中的影响。
目标函数我们可以写成:
J
~
(
w
,
λ
)
=
J
(
w
)
+
λ
(
∣
∣
w
∣
∣
2
−
C
)
\widetilde{J}(\pmb{w},\lambda) = J(\pmb{w}) + \lambda(||\pmb{w}||_2 - C)
J(www,λ)=J(www)+λ(∣∣www∣∣2−C)
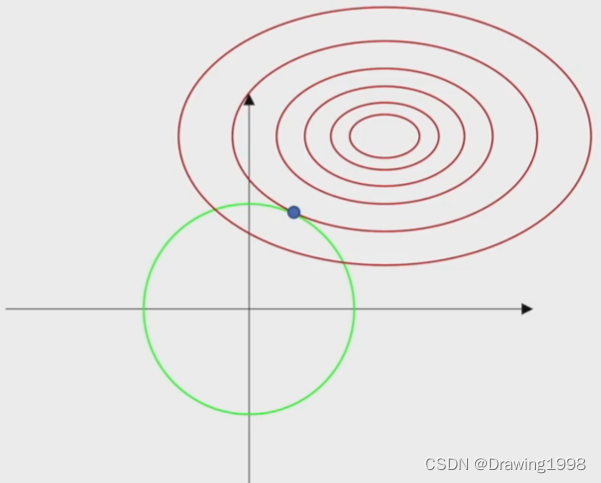
在这个图中,红色的线是损失函数的等高线,绿色的线是我们给
w
w
w 划定的可行域范围。
- 目标函数中的 C C C 决定了我们给权重 w w w 划定的可行域范围的大小;
λ \lambda λ 是拉格朗日乘子,它的作用就是用来调节约束条件对应的梯度,使其与损失函数的梯度大小相等。
通过这张图我们可以很明显地看出,通过
L
2
L^2
L2 范数来限制 权重
w
w
w 的取值范围,可以避免
w
w
w 取值太大,从而减少模型的过拟合现象。
因为
L
2
L^2
L2 范数对应的可行域是一个凸集,梯度下降法本身也是一个凸优化方法,因此我们用
L
2
L^2
L2 范数对
w
w
w 进行约束,我们要解决的问题就还是一个凸优化问题。
2. L1 参数正则化
与
L
2
L^2
L2 正则化类似,利用
L
1
L^1
L1 正则化对权重进行衰减时,我们也是通过缩放惩罚项
Ω
\Omega
Ω 的超参数
α
\alpha
α 来控制
L
1
L^1
L1 权重衰减的强度。
惩罚项
Ω
\Omega
Ω 可以表示为:
Ω
=
∣
∣
w
∣
∣
1
=
∑
∣
w
i
∣
\Omega = ||w||_1 = \sum|w_i|
Ω=∣∣w∣∣1=∑∣wi∣
模型的目标函数可以表示为:
J
~
(
w
;
X
,
y
)
=
α
∣
∣
w
∣
∣
1
+
J
(
w
;
X
,
y
)
\widetilde{J}(\pmb{w}; \pmb{X}, \pmb{y}) = \alpha ||\pmb{w}||_1 + J(\pmb{w}; \pmb{X}, \pmb{y})
J(www;XXX,yyy)=α∣∣www∣∣1+J(www;XXX,yyy)
对应的梯度:(实际上是次梯度)
▽
w
J
~
(
w
;
X
,
y
)
=
α
s
i
g
n
(
w
)
+
▽
w
J
(
w
;
X
,
y
)
\bigtriangledown_w\widetilde{J}(\pmb{w}; \pmb{X}, \pmb{y}) =\alpha sign(\pmb{w}) + \bigtriangledown_wJ(\pmb{w}; \pmb{X}, \pmb{y})
▽wJ(www;XXX,yyy)=αsign(www)+▽wJ(www;XXX,yyy)其中,
s
i
g
n
(
w
)
sign(\pmb{w})
sign(www) 只是简单地取
w
w
w 各个元素的正负号。
使用单步梯度下降来更新权重:
w
←
w
−
ϵ
(
α
s
i
g
n
(
w
)
+
▽
w
J
(
w
;
X
,
y
)
w \leftarrow w - \epsilon(\alpha sign(\pmb{w}) + \bigtriangledown_wJ(\pmb{w}; \pmb{X}, \pmb{y})
w←w−ϵ(αsign(www)+▽wJ(www;XXX,yyy)
换种写法就是:
w
←
w
−
ϵ
α
s
i
g
n
(
w
)
−
ϵ
▽
w
J
(
w
;
X
,
y
)
w \leftarrow w - \epsilon\alpha sign(\pmb{w}) - \epsilon\bigtriangledown_wJ(\pmb{w}; \pmb{X}, \pmb{y})
w←w−ϵαsign(www)−ϵ▽wJ(www;XXX,yyy)
我们可以看出,
L
1
L^1
L1 正则化的效果和
L
2
L^2
L2 不大一样,
L
2
L^2
L2 正则化是在每次更新参数前先对
w
w
w 进行线性缩放,而
L
1
L^1
L1 正则化则是添加了一个与
s
i
g
n
(
w
)
sign(\pmb{w})
sign(www) 同号的常数。
简单线性模型具有二次代价函数,我们可以通过泰勒级数表示。
我们设想 该目标函数对应的梯度是逼近更复杂模型的代价函数的阶段泰勒级数,那么梯度可以写成:
▽
w
J
~
(
w
)
=
H
(
w
−
w
∗
)
\bigtriangledown_w\widetilde{J}(\pmb{w}) = H(w - w^*)
▽wJ(www)=H(w−w∗)
其中,
H
H
H 是 损失函数
J
J
J 在
w
∗
w^*
w∗ 处的 Hessian矩阵。
我们假设 Hessian是对角的,且模型的输入数据已经经过了预处理,去除了输入特征之间的相关性。那么我们可以就将
L
1
L^1
L1 正则化的目标函数的二次近似分解成关于参数的求和:
J
~
(
w
;
X
,
y
)
=
J
(
w
∗
;
X
,
y
)
+
∑
[
1
2
H
i
,
i
(
w
i
+
w
i
∗
)
2
+
α
∣
w
i
∣
]
\widetilde{J}(\pmb{w}; \pmb{X}, \pmb{y}) =J(\pmb{w}^*; \pmb{X}, \pmb{y}) + \sum[\frac{1}{2}H_{i,i}(w_i + w^*_i)^2 + \alpha|w_i|]
J(www;XXX,yyy)=J(www∗;XXX,yyy)+∑[21Hi,i(wi+wi∗)2+α∣wi∣]
函数的解析解(对每一维
i
i
i)可以表示为:
w
i
=
s
i
g
n
(
w
i
∗
)
m
a
x
(
∣
w
i
∗
∣
−
α
H
i
,
i
,
0
)
w_i = sign(w^*_i)max(|w^*_i| - \frac{\alpha}{H_{i,i}}, 0)
wi=sign(wi∗)max(∣wi∗∣−Hi,iα,0)
这样的话就会有两种可能的结果:
∣ w i ∗ ∣ − α H i , i ≤ 0 |w^*_i| - \frac{\alpha}{H_{i,i}} \leq 0 ∣wi∗∣−Hi,iα≤0 时,正则化后目标函数中 w i w_i wi 的最优值是 w i = 0 w_i = 0 wi=0, L 1 L^1 L1 正则化项将 w i w_i wi 推至0,这样的话第 i i i 个特征的贡献将会被抵消。∣ w i ∗ ∣ − α H i , i ≥ 0 |w^*_i| - \frac{\alpha}{H_{i,i}} \geq 0 ∣wi∗∣−Hi,iα≥0 时, L 1 L^1 L1 正则化项不会将 w i w_i wi 推至0,而仅仅是在 w i w_i wi 方向上移动 α H i , i \frac{\alpha}{H_{i,i}} Hi,iα 的距离。
这样,经过
L
1
L^1
L1 正则化后我们会得到更**稀疏**(sparse) 的解,因此
L
1
L^1
L1 正则化 也被广泛应用于**特征选择**(feature selection)机制。
接下来我们看一下
L
1
L^1
L1 正则化在训练的整体过程中的影响:
与
L
2
L^2
L2 正则化类似,我们我们给
w
w
w 划定一个可行域,让
w
w
w 这个区域内进行取值。
可行域:
∣
∣
w
∣
∣
1
−
C
≤
0
||\pmb{w}||_1 - C \leq 0
∣∣www∣∣1−C≤0 (即
w
\pmb{w}
www 在空间中对应的点到原点的距离是
≤
C
\leq C
≤C 的。)

在这个图中,红色的线是损失函数的等高线,绿色的线是我们给
w
w
w 划定的可行域范围。
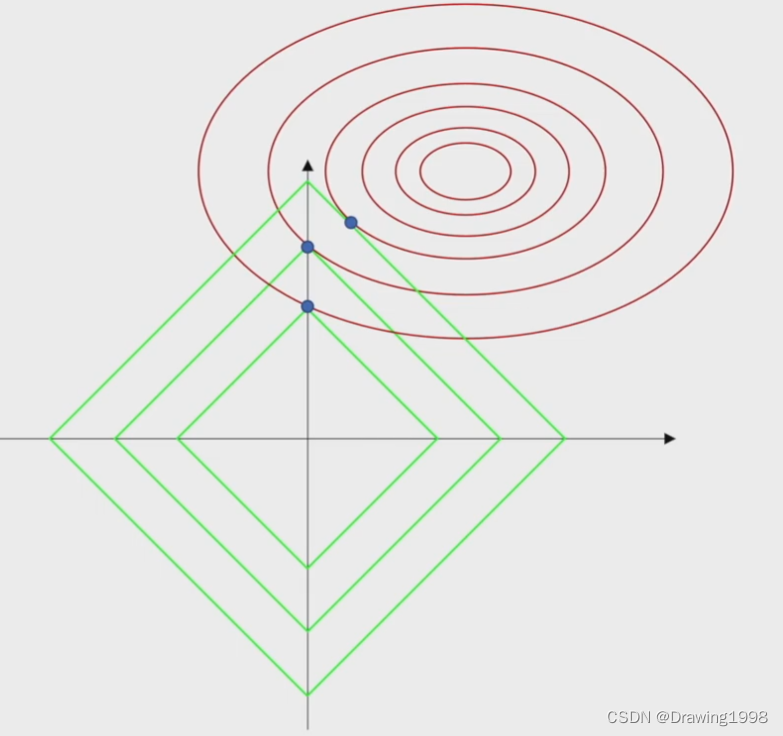
从这个图中我们也可以看出,
L
1
L^1
L1 正则化给参数划定的范围 与 损失函数的等高线 相切的点更容易是在坐标轴上,这样就会使得 权重
w
w
w 的某些项上有值,某些项上是0,这样就会导致输入的特征只有一部分起作用,而不是所有的特征都起作用。
3. 参数范数惩罚
对上面的讨论进行总结:基于参数范数惩罚的正则化策略 通过对目标函数
J
J
J 添加一个惩罚项
Ω
(
θ
)
\Omega(\theta)
Ω(θ) 来限制模型的学习能力,从而减少过拟合现象的发生。
我们将正则化后的目标函数记为
J
~
\widetilde{J}
J :
J
~
(
w
;
X
,
y
)
=
J
(
w
;
X
,
y
)
+
α
Ω
(
θ
)
\widetilde{J}(\pmb{w}; \pmb{X}, \pmb{y}) = J(\pmb{w}; \pmb{X}, \pmb{y}) + \alpha\Omega(\theta)
J(www;XXX,yyy)=J(www;XXX,yyy)+αΩ(θ)其中,
α
∈
[
0
,
∞
)
\alpha \in [0, \infty)
α∈[0,∞) 被称为衰减率,是权衡范数惩罚项
Ω
\Omega
Ω 和 标准目标函数
J
J
J 相对贡献的超参数。将
α
\alpha
α 设置为0表示没有正则化;
α
\alpha
α 越大,对应正则化惩罚越大。在求解过程中,我们通过缩放惩罚项
Ω
\Omega
Ω 的超参数
α
\alpha
α 来控制
L
2
L^2
L2 权重衰减的强度。
在神经网络的情况下,有时会希望对每一层使用单独的惩罚,并分配不同的
α
\alpha
α 系数。由于寻找合适的多个超参数代价很大,因此为了减少搜索空间,我们会在所有层使用相同的权重衰减。
版权归原作者 Drawing1998 所有, 如有侵权,请联系我们删除。