
文章目录
一、目标检测
**目标检测的任务是找出图像中所有感兴趣的目标并用矩形框确定它们的位置、大小和类别。**
二、评价指标
在目标检测领域需要衡量每个检测算法的好坏,因此定义了很多指标。各个算法经过检测后得到每个物体的检测框和置信度,然后根据该值来计算指标值,从而来评估各个算法的优劣。每个指标各不相同,下面详细阐述每个指标的概念和计算方法。
三、IoU(交并比)
loU全称为Intersection Over Union,意思是“并集里面的交集”。它的计算可以简单的用下图表示:
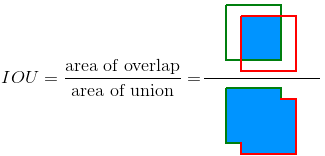
一个物体它会有一个真值框,英文称为ground truth,也就是我们实际为它标注的真实矩形框(一般情况下该矩形框是物体的最小外接矩形框,手工标注)。在评价一个算法的时候首先用该算法对图片进行检测,得到该物体的预测框,这个预测框是算法生成的,我们接下来就需要计算这个预测框和真值框之间的loU指标。计算原理就是首先计算两个框的并集区域面积,再计算两个框的交集区域面积,然后交集除以并集就是对应的loU值。loU值越大说明预测框和真值框越吻合,如果完全吻合,此时loU值为1。
四、Precision(查准率)和Recall(查全率)
首先,Precision和Recall是针对所有图片中的某一类来说的。
Precision (查准率):预测出来符合阈值的框的数目。所谓精度就是我们得到的预测框到底有多少面积是在真值框里面的,这个重叠面积除以检测框面积就是精度。形象化理解可以理解成“命中率”,即我预测的有多少在真值框里面。
具体可以解释为:预测结果中,有多少是真的正(找出来的对的比例)
Recall (查全率):预测出来的正确类别的框。从字面意思比较好理解,就是我发出去多少最终收回来多少,即预测框与真值框的重叠面积除以真值框面积。
具体可以解释为:所有正样本中,你究竟预测对了多少(找出来了几个)
为了方便理解,我们用图来进行示意:
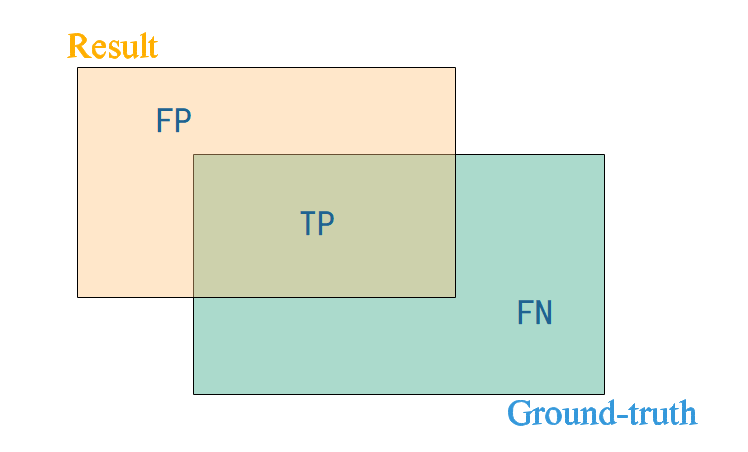
从上述概念上可以看出,精度和召回率是一般是反的。精度高了,召回率一般会低;召回率高了,精度一般会低。想象一下,如果我们需要提出一种目标检测算法来检测图像中的狗,为了尽可能的提高召回率,我们可以检出处很多很多框以尽可能的来包含图片中可能出现狗的地方,甚至可以直接以整幅图像为预测框,这时候召回率是最高的接近于1,但是很明显,精度很低。
五、TP、FP、FN、TN
其中,字母T和F分别表示检测对和检测错,P和N分别表示正样本和负样本。以图片中识别狗为例,如果检测框里面还有狗说明这个检测框是正样本,反之则为背景(负样本)。下面同样以识别狗为例,讲解详细含义和计算方式:
True Positive (TP):是—种正确的检测,检测的IOU ≥ threshold
False Positive (FP):是—种错误的检测,检测的IOU < threshold
False Negative (FN):遗漏的Ground truth区域
True Negative (TN):没有真值,并且没有检测出来
六、AP、mAP
在讲解AP之前,首先我们继续深入探讨前面提到的precision和recall的概念。在计算precision和recall时一般先计算TP、FP和FN,但是计算这三个值时我们需要先计算每个检测框和真值框的loU,再根据设定的阈值threshold来计算这三个值。这里很明显,阈值的选择会直接影响TP、FP和FN的结果,进而影响precision和recall的结果。也就是说precision和recall会随着阈值threshold的不同而不同。如果我们将阈值从0开始,逐步递增到1,很明显会产生一组precision和recall值,并且precision和recal这两组值是一一对应的,此时,我们以precision为纵坐标,以recall为横坐标进行画图,就会得到一个如下图所示的曲线,这个曲线就是精度召回率曲线,简写为PR曲线:

既然precision和recall的值会随着阈值的不同而不同,那么怎么判断不同算法检测效果的优劣呢?有了上述PR曲线图就比较容易定性一个算法的好坏了。我们只要从我们的最终目的出发就可以得到答案,我们的最终检测目的是什么?我们本质上希望我们的算法不仅检测精度高,同时召回率也高,这在曲线上反映出来的效果就是这个曲线尽可能的往右上角拉伸,即固定recall值时,precision越大越好(对应往上拉伸)。同理固定precision时,recall越大越好(对应往右拉伸)。因此我们希望我们的曲线尽可能的拉向右上角。那么怎么在数值上体现这种特性呢?原理很简单,只要曲线下方的面积越大越好。因此我们可以在同一张图中绘制两种算法的PR曲线,然后计算对应曲线下方的面积,面积越大说明该曲线对应的检测算法效果较好。
AP (Average Precision):是对所有图片内的某—类来说的,也指PR曲线下方区域的面积
mAP (Mean Average Precision):上述我们整个讨论过程是以检测图片中的狗为例,注意到我们只检测了1类我们就得到了1根PR曲线,如果检测多类,那么每一类我们均可以得到—根PR曲线,也就是每类都会有1个AP值,对所有类的AP值取平均值。即其对象是所有类的所有图片,衡量的是学出的模型在所有类别上的好坏。
七、实际计算方法
实际计算时我们还需要考虑一个叫做置信度的东西。即一般深度学习检测方法在得到每个检测框时还会附带该检测框属于某个类别的概率,这里同样以识别狗为例,如果在图像中某个区域检测出狗,一般会同步的给出该区域属于狗的概率。为什么要用这种不确定的概率形式呢?这是因为深度学习最后的分类器一般使用类似sofemax的方法进行类别判断,这种方法输出的就是0~1之间的概率,如果置信度是0.8,那么可以解释为预测到这个框中可能存在狗的概率为0.8。有了置信度概率,我们在实际计算mAP时一般采用下面的步骤(以单张图片、单个类别为例):
(1) 过滤置信度低的预测框:首先遍历图片中每个真值框对象,然后读取我们通过算法检测器检测出的这种类别的检测框,接着过滤掉置信度分数低于置信度阈值的框(—般取0.5)
(2) 计算IoU: 将剩下的检测框按置信度分数从高到低排序,最先判断置信度分数最高的检测框与真值框的loU是否大于loU阈值,若loU大于设定的loUJ阈值即判断为TP,将此真值框标记为已检测(后续的同一个真值框的多余检测框都视为FP这就是为什么先要按照置信度分数从高到低排序,置信度分数最高的检测框最先去与loU阈值比较,若大于loU阈值,视为TP,后续的同一个真值框对象的检测框都视为FP),loU小于阈值的,直接判定为FP
(3) 计算AP:根据步骤(2)中得到的TP、FP和FN来计算AP
八、实例级下的AP计算
在一个图像数据集中,我们首先要计算出每个instance的preaision(i),其中i为每幅图像的instance个数,则每幅图像的精度值为下述公式分子所示。假如验证集中有N个图像,那么我们可以得到N个精度值,计算这N个精度值的平均值,得到的就是该类的平均精度:
即每幅图像平局精度值的和除以数据集中图像的数量
mAP=所有类别的平均精度求和除以所有类别,即数据集中所有类的平均精度的平均值。但是由于实例级没有类别,所以不需要求mAP。
九、待定
版权归原作者 稚晖君的头号男粉 所有, 如有侵权,请联系我们删除。