
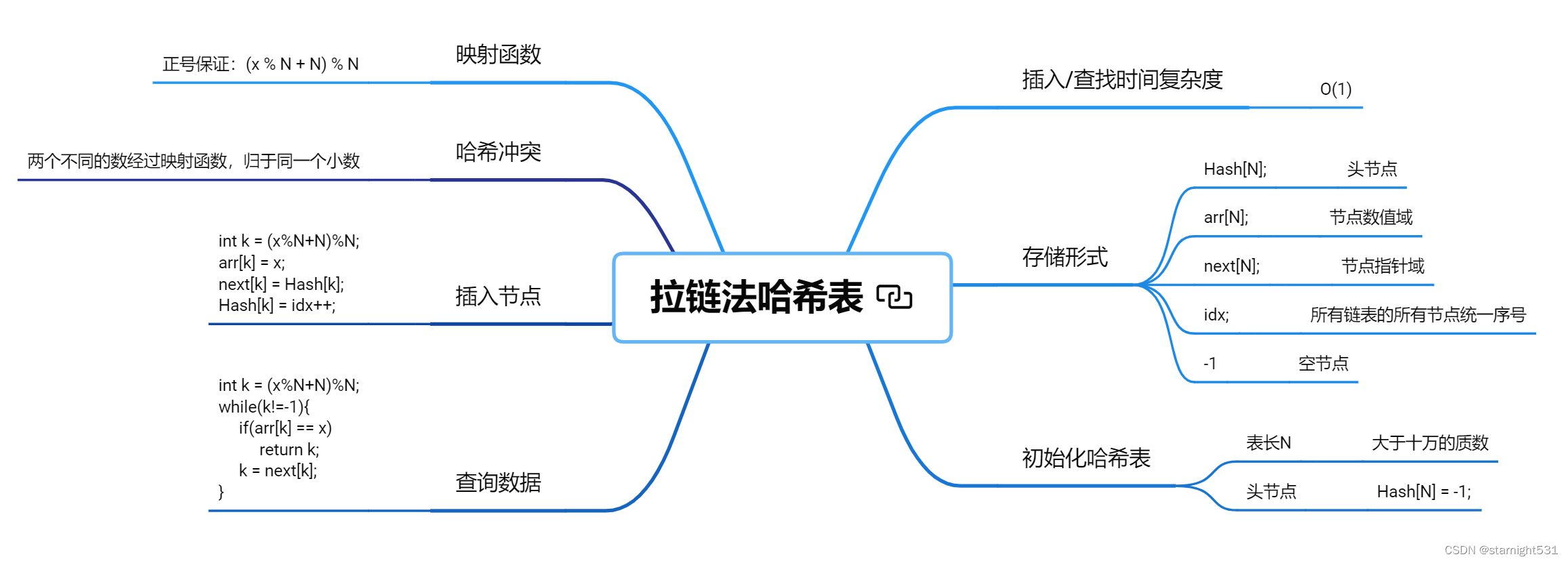
拉链法哈希表
食用指南:
对该算法程序编写以及踩坑点很熟悉的同学可以直接跳转到代码模板查看完整代码
只有基础算法的题目会有关于该算法的原理,实现步骤,代码注意点,代码模板,代码误区的讲解
非基础算法的题目侧重题目分析,代码实现,以及必要的代码理解误区
题目描述:
- 维护一个集合,支持如下几种操作: I x,插入一个数 x; Q x,询问数 x 是否在集合中出现过; 现在要进行 N 次操作,对于每个询问操作输出对应的结果。输入格式 第一行包含整数 N,表示操作数量。 接下来 N 行,每行包含一个操作指令,操作指令为 I x,Q x 中的一种。输出格式 对于每个询问指令 Q x,输出一个询问结果,如果 x 在集合中出现过,则输出 Yes,否则输出 No。 每个结果占一行。数据范围 1≤N≤105 −109≤x≤109 输入样例: 5 I 1 I 2 I 3 Q 2 Q 5 输出样例: Yes No
- 题目来源:
题目分析:
- 数x最大一亿,数组存不下输入最多十万,数组存的下
- 将无限大的数 存储在 有限大的数组/向量中 马上想到的是离散化,没毛病精确来讲,单纯用于插入和查询的数据结构叫哈希表离散化是特殊的哈希方式:需要去重+排序
- 本讲将介绍哈希表的两大实现方式:开放寻址法 & 拉链法 中的拉链法
算法原理:
1. 哈希冲突:
- 将大数映射到小范围内的最简方式就是 % 小数N
- 举例: 将 2987654321,3987654321,4987654321,5987654321…映射到0 - 5的范围内:2987654321 % 6 = 5; 3987654321 % 6 = 3; 4987654321 % 6 = 1; 5987654321 % 6 = 5;可以用arr[1]存储4987654321 arr[3]存储3987654321 但是使用arr[5]时候产生了歧义则称2987654321和5987654321发生了哈希冲突
- 含义: 模的小数N就是哈希表的表长N若两个数%表长N之后的余数相同,则称这两个数发生了哈希冲突由处理哈希冲突的方式不同,将哈希表的构建方式分为 拉链法 和 开放寻址法
哈希映射:
//将大数映射到小数范围内的最简方法是 大数 % 小数,没毛病//但是负数 % 小数 可能还是负数,但是是-小数内的负数//保证映射结果>=0int x =-2987654321;int N =6;int idx =(x%N + N)% N;
- 看到(x%N + N) % N的方法熟悉吗? 其实我们在高精度减法详细讲过哦:传送门
2. 哈希表表长:
- 为了避免哈希冲突,所以我们选取哈希表表长也需要注意开一个105长(最好为质数)的数组,作为哈希表最好代码中确定哈希表表长用到了质数打表
3. 拉链法:
- 上述arr[5]节点对应着两个数:2987654321和5987654321不妨在5这个节点拉出一条链表,链表有两个节点:2987654321 和 5987654321
 当查找这两个数时,我们先取模,找到arr[5],再遍历arr[5]拉出的单链表,就能找到这两个数反之,有未存储的数,虽然同样%6 == 5; 但是从arr[5]遍历单链表的时候找不到这个数
当查找这两个数时,我们先取模,找到arr[5],再遍历arr[5]拉出的单链表,就能找到这两个数反之,有未存储的数,虽然同样%6 == 5; 但是从arr[5]遍历单链表的时候找不到这个数
4. 数组模拟单链表:
- 不熟悉静态链表的同学看这里: 静态单链表 静态双链表 我们只需要用静态单链表即可
- 初始化: 在单链表中,若链表为空,head = -1; 在哈希表中的第i个拉链的头节点是Hash[i] 所以哈希表中未插入元素时,所有Hash[i]亦是-1
- idx变量: 在为哈希表中的一格元素拉单链表的时候,肯定采用头插法 虽然不同格元素可以拉出很多条单链表, 但是所有节点都是通过节点序号idx变量创建出来的, 现在物理地址相邻的两个节点,可以从属于不同的链表

1. 哈希表初始化代码:
//1,找一个十万后的质数作为表长,减少哈希冲突:int N =0;for(int i=100000; i++){int flag =1;for(int j=2; j*j<i; j++){if(i%j ==0){
flag =0;break;}}if(flag){
N = i;}}//2,节点初始化:int Hash[N];int arr[N], next[N],idx =0;memset(Hash,-1,sizeof(Hash));
- 哈希表中插入元素: 哈希表Hash[i]本身也存储的是节点idx,是Hash[i]拉出的链表的头节点 由于采用头插法,每次向Hash[i]所引导的链表插入元素时,新插入的节点成为了新的头节点,原头节点成为新头节点的next[] 和静态链表同理,由于开始Hash[i]=-1,所以所有链表的尾巴都指向-1现在向Hash[k]插入节点,经典问题又来:大象装进冰箱有几步? 1. 创捷新节点(创新): arr[idx] = val;
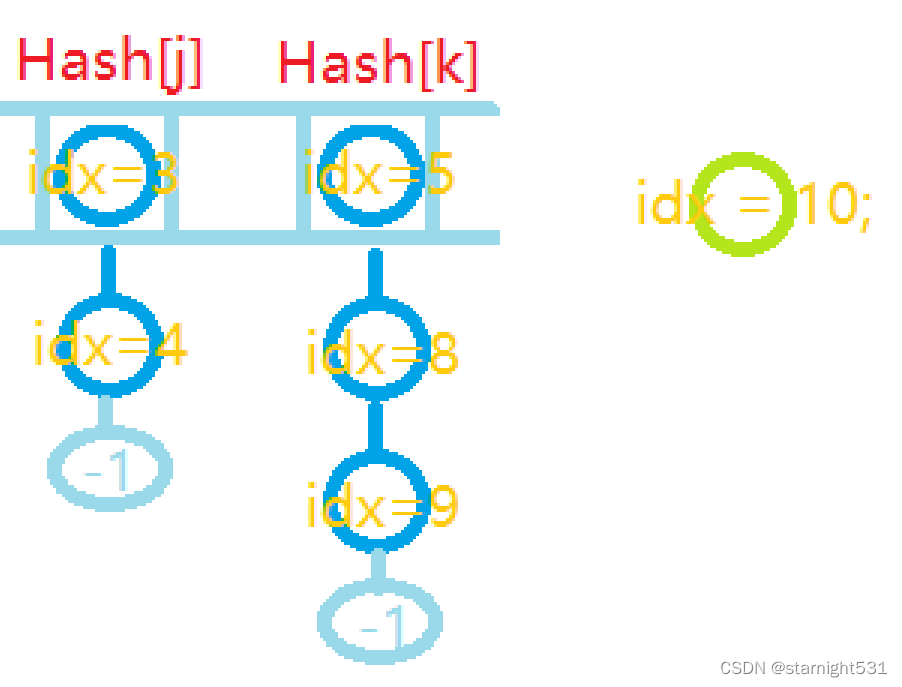 2. 老链表连接到新节点上(连旧): next[idx] = Hash[k];
2. 老链表连接到新节点上(连旧): next[idx] = Hash[k];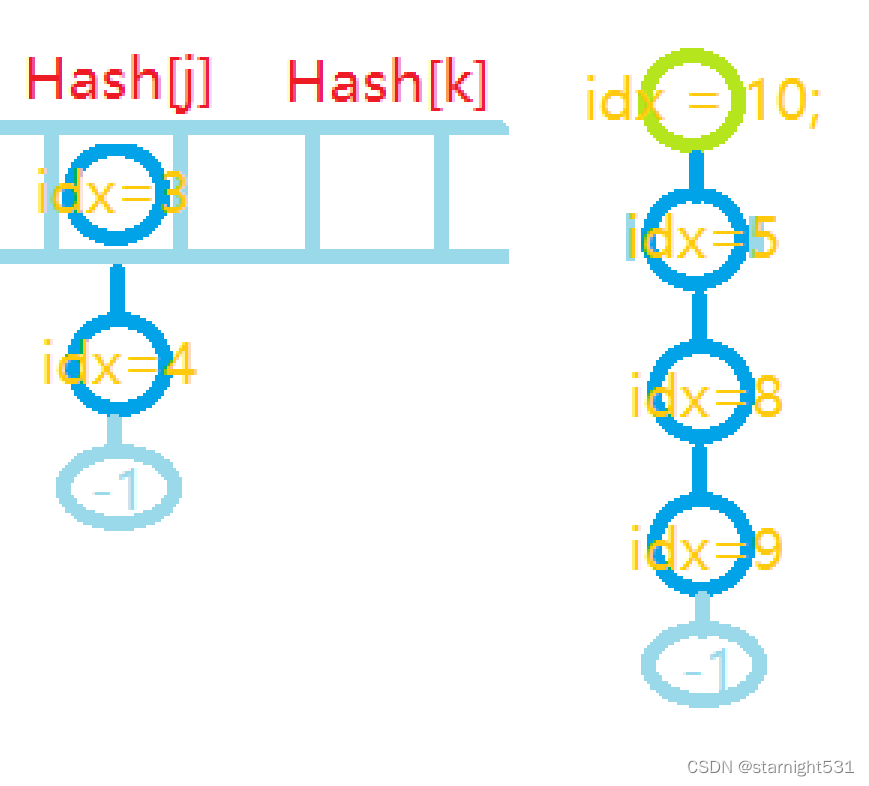 1. 新链表放回Hash[k]中 (放回): Hash[k] = idx++;
1. 新链表放回Hash[k]中 (放回): Hash[k] = idx++;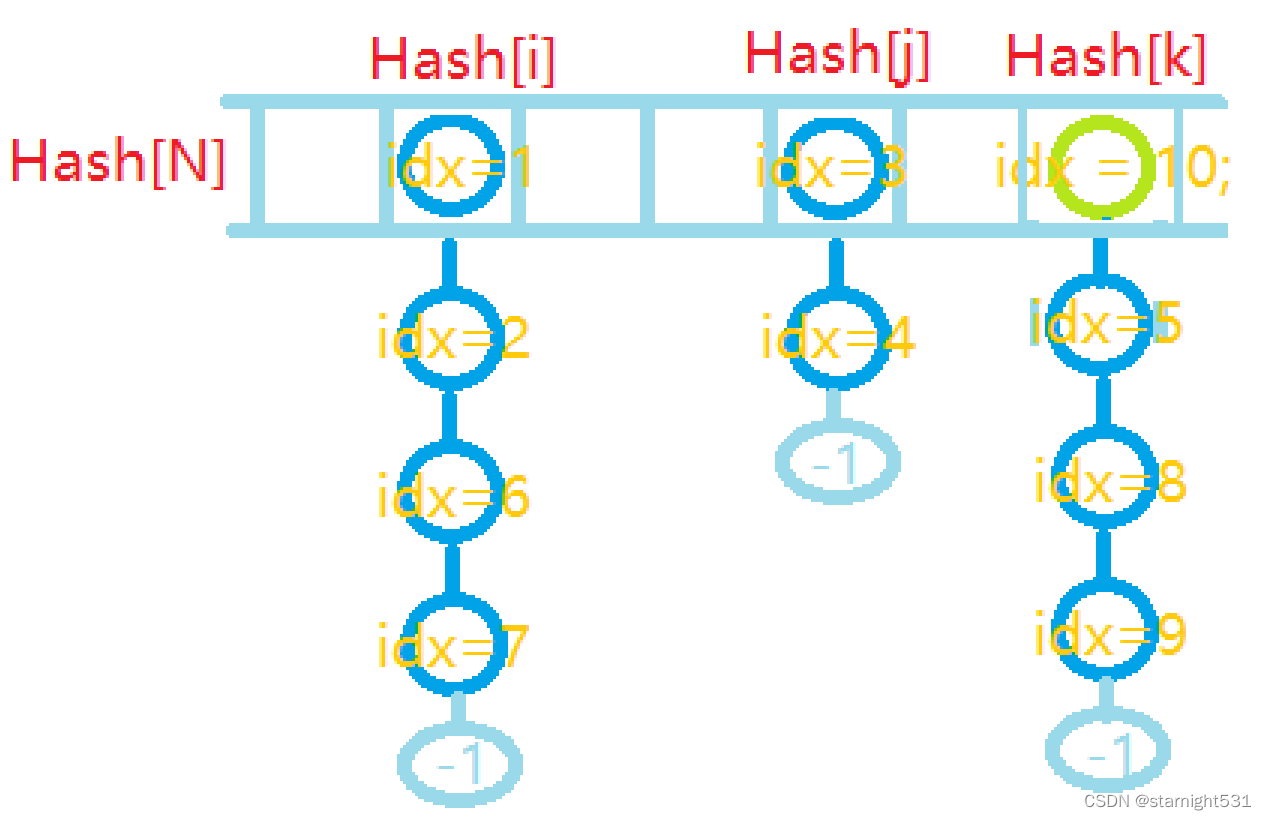
2. 插入节点代码:
voidinsert(int x){//大数x对应的小数k映射,没别哒,就是%,保证结果非负int k =(x%N + N)% N;
arr[idx]= x;
next[idx]= Hash[k];
Hash[k]= idx++;}
3. 查询哈希表代码:
- 有了上面的拉链哈希表原理介绍,那查找很简单了 一句话,遍历数x映射到的Hash[k]所连接的静态链表
intsearch(int x){//先找到是哪个链表int k =(x%N + N)% N;int t = Hash[k];//再遍历这个链表while(t !=-1){if(arr[k]== x)return k;
k = next[k];}return-1;}
代码误区:
1. 哈希表数组Hash[]存储的是什么?
- Hash[i] 表示一个数x经过映射后到达第i条链表,第i条链表的头节点序号
- 通过头节点序号可以遍历这一条链表
2. 哈希表数组Hash[]初始化为什么?
- 当所有链表中没有节点的时候,我们将所有链表的头节点初始化为-1
- 所以memset(Hash, -1, sizeof(Hash));
- 之后节点头插时,next[idx] = Hash[i],将-1变为链表的结尾标志
3. 哈希表表长为什么为大质数?
- 就一句话,避免哈希冲突
4. 为什么哈希表查询时间复杂度为O(1)?
- 现在所有的代码存储在内存中,Hash[1]和Hash[100000]到达的速度一样
- 由于本身哈希表就非常的长,所以数据存储时的哈希冲突非常少
- 每个Hash[i]下面拉出来的链表长度非常短,遍历用时非常少
- 查询时一共两步:Hash[(x%N +N)%N]; & while(t != -1) t = next[t]; 每一步的时间消耗都非常少,忽略不计是O(1)
5. 哈希表删除节点操作:
- 可以删除,和单链表去除一个节点代码一样
- 也可以不删除,用一个delete[]标记所有被删除了的节点,查询到每一个节点的时候都看一眼对应的delete[idx]是不是等于1
- 其实根本也不考删除哈希表内节点
本篇感想:
- 其实拉链法哈希就三个点:哈希映射函数,哈希数组挂单链表,单链表操作,还有一个变量初始化
- C++的STL中的map也是哈希表,但是他的表长固定,可能被出题人卡数据,自己实现就不怕啦; 另一个方法后面的大罗洞观专栏讲
- 看完本篇博客,恭喜已登 《练气境-中期》
- 讲完字符串哈希,将登练气境后期哦
 距离登仙境不远了,加油
距离登仙境不远了,加油 
本文转载自: https://blog.csdn.net/buptsd/article/details/124740778
版权归原作者 starnight531 所有, 如有侵权,请联系我们删除。
版权归原作者 starnight531 所有, 如有侵权,请联系我们删除。