

Vit比它爹Transformer步骤要简单的多,需要注意的点也要少得多,最令人兴奋的是它在代码中没有令人头疼的MASK,还有许多简化的操作,容我慢慢道来。
原理
1、打成patch+线性变化
它所解决的核心问题就是如何将图片塞入Transformer,如果每个像素作为输入的话,那么一个小小的224*224的图片的序列长度就会是50176,而nlp的Transformer最初设定长度才是512,并且attention的复杂度是平方级的,这50176令人不敢恭维。Vit无非就是将一张图片打成一个一个的patch,将每个patch作为一个输入,仅此而已。
将图片打成patch可以通过很简单的卷积实现。使用卷积核大小为16*16,步长为16,卷积核数维768。
用维度来说明一下。假如一个224224的图片,每个patch的大小是1616,那么最终只有(224/16)(224/16)=196个输入,每一个输入的dim是1616*3=768,3是rgb通道数。
2、cls token+位置编码
那么Vit怎么进行分类?可以像bert一样在最前面增加一个cls token,最后只用cls token经过Encoder的结果。
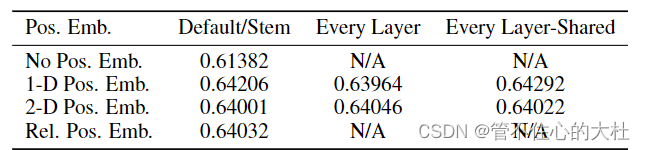
位置编码的方法使用的可学习的方法,并且作者炼丹后发现一维,二维,相对位置编码的结果差不多,为了简单使用一维位置编码。
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + self.num_tokens, embed_dim))
3、 Encoder+分类
与transformer的Encoder不同,这里是先norm再attention,并且不存在padding。并且还有一点需要注意,在这里的q,k,v通过同一个Linear得到,不像Transformer中需要分别进行Linear得到,因为它不需要解决Decoder中的交叉注意力中kv和q来源不同的情况,这样可以提高我们的训练速度。还有一点值得注意的是,在Vit中的kqv矩阵维度相同,这样可以得到全局感受野但是计算量大。
最后分类只用cls token的输出

代码
我在前人的基础上进一步增加了一些注释,补全了维度变换。
我认为想彻底搞懂Vit光靠看几个视频,几个文章肯定是不行的。强烈建议亲自调试一遍,点步入步过按钮一步一步运行,将每一步的维度变换理解才是重中之重。下面的代码你只需要在最后一行打个断点就能直接调试,希望对大家能有帮助!
"""
original code from rwightman:
https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/vision_transformer.py
"""
from functools import partial
from collections import OrderedDict
import torch
import torch.nn as nn
class PatchEmbed(nn.Module):
"""
2D Image to Patch Embedding
"""
def __init__(self, img_size=224, patch_size=16, in_c=3, embed_dim=768, norm_layer=None):
super().__init__()
img_size = (img_size, img_size) # [224,224]
patch_size = (patch_size, patch_size) # [16,16]
self.img_size = img_size # [224,224]
self.patch_size = patch_size # [16,16]
self.grid_size = (img_size[0] // patch_size[0], img_size[1] // patch_size[1]) # [14,14]
self.num_patches = self.grid_size[0] * self.grid_size[1] # 196
self.proj = nn.Conv2d(in_c, embed_dim, kernel_size=patch_size, stride=patch_size) # 3,768,(16,16),16
self.norm = norm_layer(embed_dim) if norm_layer else nn.Identity()
def forward(self, x):
B, C, H, W = x.shape
assert H == self.img_size[0] and W == self.img_size[1], \
f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
# proj:[B,3,224,224] -> [B,768,14,14]
# flatten: [B, 768, 14, 14] -> [B, 768, 196]
# transpose: [B, 768, 196] -> [B, 196, 768]
x = self.proj(x).flatten(2).transpose(1, 2)
x = self.norm(x)
return x
class Attention(nn.Module):
def __init__(self,
dim, # 输入token的dim 768
num_heads=8, # multi-head 12
qkv_bias=False, # True
qk_scale=None, # 和根号dimk作用相同
attn_drop_ratio=0., # dropout率
proj_drop_ratio=0.):
super(Attention, self).__init__()
self.num_heads = num_heads
head_dim = dim // num_heads # 768 // 12 = 64
self.scale = qk_scale or head_dim ** -0.5
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias) # qkv经过一个linear得到。 768 --> 2304
self.attn_drop = nn.Dropout(attn_drop_ratio)
self.proj = nn.Linear(dim, dim) # 一次新的映射
self.proj_drop = nn.Dropout(proj_drop_ratio)
def forward(self, x):
# [batch_size, num_patches + 1, total_embed_dim]
B, N, C = x.shape
# qkv(): -> [batch_size, num_patches + 1, 3 * total_embed_dim]
# reshape: -> [batch_size, num_patches + 1, 3, num_heads, embed_dim_per_head]
# permute: -> [3, batch_size, num_heads, num_patches + 1, embed_dim_per_head]
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
# [batch_size, num_heads, num_patches + 1, embed_dim_per_head]
q, k, v = qkv[0], qkv[1], qkv[2] # 在Vit中qkv维度相同,都是[B,12,197,64]
# transpose: -> [batch_size, num_heads, embed_dim_per_head, num_patches + 1]
# @: multiply -> [batch_size, num_heads, num_patches + 1, num_patches + 1]
attn = (q @ k.transpose(-2, -1)) * self.scale
# 按行进行softmax
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
# @: multiply -> [batch_size, num_heads, num_patches + 1, embed_dim_per_head]
# transpose: -> [batch_size, num_patches + 1, num_heads, embed_dim_per_head]
# reshape: -> [batch_size, num_patches + 1, total_embed_dim]
# C就是total_embed_dim
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
# 再通过一次映射使其更好的融合
x = self.proj(x)
x = self.proj_drop(x)
return x
class Mlp(nn.Module):
"""
MLP as used in Vision Transformer, MLP-Mixer and related networks
"""
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features # 768
hidden_features = hidden_features or in_features # 3072
self.fc1 = nn.Linear(in_features, hidden_features) # 768 --> 3072
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features) # 3072 --> 768
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class Block(nn.Module):
def __init__(self,
dim,
num_heads,
mlp_ratio=4.,
qkv_bias=False,
qk_scale=None,
drop_ratio=0.,
attn_drop_ratio=0.,
drop_path_ratio=0.,
act_layer=nn.GELU,
norm_layer=nn.LayerNorm):
super(Block, self).__init__()
self.norm1 = norm_layer(dim) # 与Transformer不同,这里先norm
self.attn = Attention(dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale,
attn_drop_ratio=attn_drop_ratio, proj_drop_ratio=drop_ratio)
# NOTE: drop path for stochastic depth, we shall see if this is better than dropout here
self.drop_path = DropPath(drop_path_ratio) if drop_path_ratio > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio) # 隐藏层神经元数
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop_ratio) # MLP
def forward(self, x):
# 残差连接
x = x + self.drop_path(self.attn(self.norm1(x)))
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
class VisionTransformer(nn.Module):
def __init__(self, img_size=224, patch_size=16, in_c=3, num_classes=1000,
embed_dim=768, depth=12, num_heads=12, mlp_ratio=4.0, qkv_bias=True,
qk_scale=None, representation_size=None, distilled=False, drop_ratio=0.,
attn_drop_ratio=0., drop_path_ratio=0., embed_layer=PatchEmbed, norm_layer=None,
act_layer=None):
"""
Args:
img_size (int, tuple): input image size
patch_size (int, tuple): patch size
in_c (int): 输入通道数
num_classes (int): 多分类数量
embed_dim (int): embedding后维度
depth (int): Encoder数量
num_heads (int): multi-head头数
mlp_ratio (int): mlp隐藏层维度是输入的多少倍
qkv_bias (bool): qkv的Linear过程有没有偏置?
qk_scale (float): 类似根号dimk
representation_size (Optional[int]): MLP head是否只有一个全连接层,对应Pre-logits,是一个可选项
distilled (bool): 用于Deit的,与Vit无关
drop_ratio (float): dropout rate
attn_drop_ratio (float): attention dropout rate
drop_path_ratio (float): stochastic depth rate
embed_layer (nn.Module): Embedding层
norm_layer: (nn.Module): normalization层
"""
super(VisionTransformer, self).__init__()
self.num_classes = num_classes # 1000
self.num_features = self.embed_dim = embed_dim # 768
self.num_tokens = 2 if distilled else 1 # 不管
norm_layer = norm_layer or partial(nn.LayerNorm, eps=1e-6)
act_layer = act_layer or nn.GELU
# 224,16,3,768
self.patch_embed = embed_layer(img_size=img_size, patch_size=patch_size, in_c=in_c, embed_dim=embed_dim)
num_patches = self.patch_embed.num_patches # 196
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim)) # 1,1,768
self.dist_token = nn.Parameter(torch.zeros(1, 1, embed_dim)) if distilled else None # 不管
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + self.num_tokens, embed_dim)) # 位置编码,注意要+1(cls token)
self.pos_drop = nn.Dropout(p=drop_ratio) # 位置编码后的dropout
dpr = [x.item() for x in torch.linspace(0, drop_path_ratio, depth)] # 构建一个dropout的等差序列,但默认为0
# *可以解引用
self.blocks = nn.Sequential(*[
Block(dim=embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,
drop_ratio=drop_ratio, attn_drop_ratio=attn_drop_ratio, drop_path_ratio=dpr[i],
norm_layer=norm_layer, act_layer=act_layer)
for i in range(depth)
])
self.norm = norm_layer(embed_dim)
# 之前所说的可选项,略过
if representation_size and not distilled:
self.has_logits = True
self.num_features = representation_size
self.pre_logits = nn.Sequential(OrderedDict([
("fc", nn.Linear(embed_dim, representation_size)),
("act", nn.Tanh())
]))
else:
self.has_logits = False
self.pre_logits = nn.Identity() # 什么也不做
# 分类,不用管else 768 --> 1000
self.head = nn.Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity()
# 以下与Vit无关 //开始
self.head_dist = None
if distilled:
self.head_dist = nn.Linear(self.embed_dim, self.num_classes) if num_classes > 0 else nn.Identity()
# 结束//
# 权重初始化
nn.init.trunc_normal_(self.pos_embed, std=0.02) # 位置编码
if self.dist_token is not None:
nn.init.trunc_normal_(self.dist_token, std=0.02)
nn.init.trunc_normal_(self.cls_token, std=0.02) # cls token
self.apply(_init_vit_weights)
def forward_features(self, x):
# [B, C, H, W] -> [B, num_patches, embed_dim]
x = self.patch_embed(x) # [B, 196, 768]
# [1, 1, 768] -> [B, 1, 768]
cls_token = self.cls_token.expand(x.shape[0], -1, -1)
if self.dist_token is None:
x = torch.cat((cls_token, x), dim=1) # [B, 197, 768]
else:
x = torch.cat((cls_token, self.dist_token.expand(x.shape[0], -1, -1), x), dim=1)
x = self.pos_drop(x + self.pos_embed)
x = self.blocks(x)
x = self.norm(x)
if self.dist_token is None:
return self.pre_logits(x[:, 0])
else:
return x[:, 0], x[:, 1]
def forward(self, x):
x = self.forward_features(x)
if self.head_dist is not None:
x, x_dist = self.head(x[0]), self.head_dist(x[1])
if self.training and not torch.jit.is_scripting():
# during inference, return the average of both classifier predictions
return x, x_dist
else:
return (x + x_dist) / 2
else:
x = self.head(x)
return x
def _init_vit_weights(m):
"""
ViT weight initialization
:param m: module
"""
if isinstance(m, nn.Linear):
nn.init.trunc_normal_(m.weight, std=.01)
if m.bias is not None:
nn.init.zeros_(m.bias)
elif isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode="fan_out")
if m.bias is not None:
nn.init.zeros_(m.bias)
elif isinstance(m, nn.LayerNorm):
nn.init.zeros_(m.bias)
nn.init.ones_(m.weight)
def drop_path(x, drop_prob: float = 0., training: bool = False):
"""
Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
This is the same as the DropConnect impl I created for EfficientNet, etc networks, however,
the original name is misleading as 'Drop Connect' is a different form of dropout in a separate paper...
See discussion: https://github.com/tensorflow/tpu/issues/494#issuecomment-532968956 ... I've opted for
changing the layer and argument names to 'drop path' rather than mix DropConnect as a layer name and use
'survival rate' as the argument.
"""
if drop_prob == 0. or not training:
return x
keep_prob = 1 - drop_prob
shape = (x.shape[0],) + (1,) * (x.ndim - 1) # work with diff dim tensors, not just 2D ConvNets
random_tensor = keep_prob + torch.rand(shape, dtype=x.dtype, device=x.device)
random_tensor.floor_() # binarize
output = x.div(keep_prob) * random_tensor
return output
class DropPath(nn.Module):
"""
Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
"""
def __init__(self, drop_prob=None):
super(DropPath, self).__init__()
self.drop_prob = drop_prob
def forward(self, x):
return drop_path(x, self.drop_prob, self.training)
def vit_base_patch16_224(num_classes: int = 1000):
"""
ViT-Base model (ViT-B/16) from original paper (https://arxiv.org/abs/2010.11929).
ImageNet-1k weights @ 224x224, source https://github.com/google-research/vision_transformer.
weights ported from official Google JAX impl:
链接: https://pan.baidu.com/s/1zqb08naP0RPqqfSXfkB2EA 密码: eu9f
"""
model = VisionTransformer(img_size=224,
patch_size=16,
embed_dim=768,
depth=12,
num_heads=12,
representation_size=None,
num_classes=num_classes)
return model
vit_base_patch16_224()
文章仅供学习使用
版权归原作者 管不住心的大杜 所有, 如有侵权,请联系我们删除。