
NVIDIA&GRID vGPU软件-中文用户指南第一章、第二章内容请看NVIDIA&GRID vGPU软件-中文用户指南(上)_nvidia-uvm mps vgpu-CSDN博客
NVIDIA&GRID vGPU软件-中文用户指南第三章、第四章、第五章内容请看NVIDIA&GRID vGPU软件-中文用户指南(中)-CSDN博客
本文暂时未将第六章(移除vGPU配置)内容整理翻译,后续会加入到指南中去
第七章、监控GPU性能
NVIDIA vGPU软件使您能够从虚拟机监控物理GPU和虚拟GPU的性能。您可以使用几种工具来监控GPU性能:
‣ 从任何支持的虚拟化管理程序,以及从运行64位版本的Windows或Linux的客户虚拟机中,您可以使用NVIDIA系统管理接口nvidia-smi。
‣ 从Citrix Hypervisor,您可以使用Citrix XenCenter。
‣ 从Windows客户虚拟机,您可以使用以下工具:
‣ Windows性能监视器
‣ Windows管理工具(WMI)
7.1 NVIDIA系统管理接口nvidia-smi
NVIDIA系统管理接口nvidia-smi是一个命令行工具,用于报告NVIDIA GPU的管理信息。nvidia-smi工具包含在以下软件包中:
‣ 针对每个支持的虚拟化管理程序的NVIDIA虚拟GPU管理程序包
‣ 针对每个支持的客户操作系统的NVIDIA驱动程序包
报告的管理信息的范围取决于您从何处运行nvidia-smi:
‣ 从虚拟化管理程序命令行,如Citrix Hypervisor的dom0 shell或VMware ESXi主机shell,nvidia-smi报告系统中存在的NVIDIA物理GPU和虚拟GPU的管理信息。
注意:当从虚拟化管理程序命令行运行时,nvidia-smi不会列出当前分配给GPU透传的任何GPU。 从客户虚拟机中,nvidia-smi检索分配给虚拟机的vGPU或透传GPU的使用统计信息。 在Windows客户虚拟机中,nvidia-smi安装在默认可执行路径中的一个文件夹中。因此,您可以通过运行nvidia-smi.exe命令从任何文件夹的命令提示符中运行nvidia-smi。
7.2 从虚拟化管理程序监控GPU性能
您可以通过使用NVIDIA系统管理接口nvidia-smi命令行实用程序从任何支持的虚拟化管理程序监控GPU性能。在Citrix Hypervisor平台上,您还可以使用Citrix XenCenter来监控GPU性能。
注意:您无法从虚拟化管理程序监控正在用于GPU透传的GPU的性能。您只能从使用这些GPU的客户虚拟机内监控透传GPU的性能。
7.2.1 使用nvidia-smi从虚拟化管理程序监控GPU性能
通过从虚拟化管理程序命令行(如Citrix Hypervisor dom0 shell或VMware ESXi主机shell)
运行nvidia-smi,您可以获取系统中存在的NVIDIA物理GPU和虚拟GPU的管理信息。 没有子命令时,nvidia-smi提供物理GPU的管理信息。要更详细地查看虚拟GPU,请使用带有vgpu子命令的nvidia-smi。 从命令行可以获取有关nvidia-smi工具和vgpu子命令的帮助信息。
帮助信息命令 nvidia-smi工具支持的子命令列表。请注意,并非所有子命令都适用于支持NVIDIA vGPU软件的GPU。nvidia-smi -hvgpu子命令支持的所有选项列表。nvidia-smi vgpu –h
7.2.1.1 获取系统中所有物理GPU的摘要
要获取系统中所有物理GPU的摘要,包括PCI总线ID、电源状态、温度、当前内存使用情况等,请运行nvidia-smi而不添加额外参数。
每个vGPU实例都在“计算进程”部分中报告,同时显示其物理GPU索引和分配给它的帧缓冲内存量。
在接下来的示例中,系统中正在运行三个vGPU:一个vGPU在每个物理GPU 0、1和2上运行。
[root@vgpu ~]# nvidia-smi
Fri Jul 14 09:26:18 2023
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 525.125.03 Driver Version: 525.125.03 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla M60 On | 0000:83:00.0 Off | Off |
| N/A 31C P8 23W / 150W | 1889MiB / 8191MiB | 7% Default |
+-------------------------------+----------------------+----------------------+
| 1 Tesla M60 On | 0000:84:00.0 Off | Off |
| N/A 26C P8 23W / 150W | 926MiB / 8191MiB | 9% Default |
+-------------------------------+----------------------+----------------------+
| 2 Tesla M10 On | 0000:8A:00.0 Off | N/A |
| N/A 23C P8 10W / 53W | 1882MiB / 8191MiB | 12% Default |
+-------------------------------+----------------------+----------------------+
| 3 Tesla M10 On | 0000:8B:00.0 Off | N/A |
| N/A 26C P8 10W / 53W | 10MiB / 8191MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 4 Tesla M10 On | 0000:8C:00.0 Off | N/A |
| N/A 34C P8 10W / 53W | 10MiB / 8191MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 5 Tesla M10 On | 0000:8D:00.0 Off | N/A |
| N/A 32C P8 10W / 53W | 10MiB / 8191MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| 0 11924 C+G /usr/lib64/xen/bin/vgpu 1856MiB |
| 1 11903 C+G /usr/lib64/xen/bin/vgpu 896MiB |
| 2 11908 C+G /usr/lib64/xen/bin/vgpu 1856MiB |
+-----------------------------------------------------------------------------+
[root@vgpu ~]#
7.2.1.2 获取系统中所有vGPU的摘要
要获取当前在系统中每个物理GPU上运行的vGPU的摘要,请运行nvidia-smi vgpu而不添加额外参数。
[root@vgpu ~]# nvidia-smi vgpu
Fri Jul 14 09:27:06 2023
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 525.125.03 Driver Version: 525.125.03 |
|-------------------------------+--------------------------------+------------+
| GPU Name | Bus-Id | GPU-Util |
| vGPU ID Name | VM ID VM Name | vGPU-Util |
|===============================+================================+============|
| 0 Tesla M60 | 0000:83:00.0 | 7% |
| 11924 GRID M60-2Q | 3 Win7-64 GRID test 2 | 6% |
+-------------------------------+--------------------------------+------------+
| 1 Tesla M60 | 0000:84:00.0 | 9% |
| 11903 GRID M60-1B | 1 Win8.1-64 GRID test 3 | 8% |
+-------------------------------+--------------------------------+------------+
| 2 Tesla M10 | 0000:8A:00.0 | 12% |
| 11908 GRID M10-2Q | 2 Win7-64 GRID test 1 | 10% |
+-------------------------------+--------------------------------+------------+
| 3 Tesla M10 | 0000:8B:00.0 | 0%
+-------------------------------+--------------------------------+------------+
| 4 Tesla M10 | 0000:8C:00.0 | 0% |
+-------------------------------+--------------------------------+------------+
| 5 Tesla M10 | 0000:8D:00.0 | 0% |
+-------------------------------+--------------------------------+------------+
[root@vgpu ~]#
7.2.1.3 获取物理GPU详细信息
要获取关于平台上所有物理GPU的详细信息,请使用nvidia-smi运行-q或--query选项。
[root@vgpu ~]# nvidia-smi -q
==============NVSMI LOG==============
Timestamp : Tue Nov 22 10:33:26 2022
Driver Version : 525.60.06
CUDA Version : Not Found
vGPU Driver Capability
Heterogenous Multi-vGPU : Supported
Attached GPUs : 3
GPU 00000000:C1:00.0
Product Name : Tesla T4
Product Brand : NVIDIA
Product Architecture : Turing
Display Mode : Enabled
Display Active : Disabled
Persistence Mode : Enabled
vGPU Device Capability
Fractional Multi-vGPU : Supported
Heterogeneous Time-Slice Profiles : Supported
Heterogeneous Time-Slice Sizes : Not Supported
MIG Mode
Current : N/A
Pending : N/A
Accounting Mode : Enabled
Accounting Mode Buffer Size : 4000
Driver Model
Current : N/A
Pending : N/A
Serial Number : 1321120031291
GPU UUID : GPU-9084c1b2-624f-2267-4b66-345583fbd981
Minor Number : 1
VBIOS Version : 90.04.38.00.03
MultiGPU Board : No
Board ID : 0xc100
Board Part Number : 900-2G183-0000-001
GPU Part Number : 1EB8-895-A1
Module ID : 0
Inforom Version
Image Version : G183.0200.00.02
OEM Object : 1.1
ECC Object : 5.0
Power Management Object : N/A
GPU Operation Mode
Current : N/A
Pending : N/A
GSP Firmware Version : N/A
GPU Virtualization Mode
Virtualization Mode : Host VGPU
Host VGPU Mode : Non SR-IOV
IBMNPU
Relaxed Ordering Mode : N/A
PCI
Bus : 0xC1
Device : 0x00
Domain : 0x0000
Device Id : 0x1EB810DE
Bus Id : 00000000:C1:00.0
Sub System Id : 0x12A210DE
GPU Link Info
PCIe Generation
Max : 3
Current : 1
Device Current : 1
Device Max : 3
Host Max : N/A
Link Width
Max : 16x
Current : 16x
Bridge Chip
Type : N/A
Firmware : N/A
Replays Since Reset : 0
Replay Number Rollovers : 0
Tx Throughput : 0 KB/s
Rx Throughput : 0 KB/s
Atomic Caps Inbound : N/A
Atomic Caps Outbound : N/A
Fan Speed : N/A
Performance State : P8
Clocks Throttle Reasons
Idle : Active
Applications Clocks Setting : Not Active
SW Power Cap : Not Active
HW Slowdown : Not Active
HW Thermal Slowdown : Not Active
HW Power Brake Slowdown : Not Active
Sync Boost : Not Active
SW Thermal Slowdown : Not Active
Display Clock Setting : Not Active
FB Memory Usage
Total : 15360 MiB
Reserved : 0 MiB
Used : 3859 MiB
Free : 11500 MiB
BAR1 Memory Usage
Total : 256 MiB
Used : 17 MiB
Free : 239 MiB
Compute Mode : Default
Utilization
Gpu : 0 %
Memory : 0 %
Encoder : 0 %
Decoder : 0 %
Encoder Stats
Active Sessions : 0
Average FPS : 0
Average Latency : 0
FBC Stats
Active Sessions : 0
Average FPS : 0
Average Latency : 0
Ecc Mode
Current : Enabled
Pending : Enabled
ECC Errors
Volatile
SRAM Correctable : 0
SRAM Uncorrectable : 0
DRAM Correctable : 0
DRAM Uncorrectable : 0
Aggregate
SRAM Correctable : 0
SRAM Uncorrectable : 0
DRAM Correctable : 0
DRAM Uncorrectable : 0
Retired Pages
Single Bit ECC : 0
Double Bit ECC : 0
Pending Page Blacklist : No
Remapped Rows : N/A
Temperature
GPU Current Temp : 35 C
GPU Shutdown Temp : 96 C
GPU Slowdown Temp : 93 C
GPU Max Operating Temp : 85 C
GPU Target Temperature : N/A
Memory Current Temp : N/A
Memory Max Operating Temp : N/A
Power Readings
Power Management : Supported
Power Draw : 16.57 W
Power Limit : 70.00 W
Default Power Limit : 70.00 W
Enforced Power Limit : 70.00 W
Min Power Limit : 60.00 W
Max Power Limit : 70.00 W
Clocks
Graphics : 300 MHz
SM : 300 MHz
Memory : 405 MHz
Video : 540 MHz
Applications Clocks
Graphics : 585 MHz
Memory : 5001 MHz
Default Applications Clocks
Graphics : 585 MHz
Memory : 5001 MHz
Deferred Clocks
Memory : N/A
Max Clocks
Graphics : 1590 MHz
SM : 1590 MHz
Memory : 5001 MHz
Video : 1470 MHz
Max Customer Boost Clocks
Graphics : 1590 MHz
Clock Policy
Auto Boost : N/A
Auto Boost Default : N/A
Voltage
Graphics : N/A
Fabric
State : N/A
Status : N/A
Processes
GPU instance ID : N/A
Compute instance ID : N/A
Process ID : 2103065
Type : C+G
Name : Win11SV2_View87
Used GPU Memory : 3810 MiB
[root@vgpu ~]#
7.2.1.4 获取vGPU详细信息
要获取关于平台上所有vGPU的详细信息,请使用nvidia-smi vgpu运行-q或--query选项。 要将检索到的信息限制为平台上一部分GPU,请使用-i或--id选项选择一个或多个vGPU。
[root@vgpu ~]# nvidia-smi vgpu -q -i 1
GPU 00000000:C1:00.0
Active vGPUs : 1
vGPU ID : 3251634327
VM ID : 2103066
VM Name : Win11SV2_View87
vGPU Name : GRID T4-4Q
vGPU Type : 232
vGPU UUID : afdcf724-1dd2-11b2-8534-624f22674b66
Guest Driver Version : 527.15
License Status : Licensed (Expiry: 2022-11-23 5:2:12 GMT)
GPU Instance ID : N/A
Accounting Mode : Disabled
ECC Mode : Enabled
Accounting Buffer Size : 4000
Frame Rate Limit : 60 FPS
PCI
Bus Id : 00000000:02:04.0
FB Memory Usage
Total : 4096 MiB
Used : 641 MiB
Free : 3455 MiB
Utilization
Gpu : 0 %
Memory : 0 %
Encoder : 0 %
Decoder : 0 %
Encoder Stats
Active Sessions : 0
Average FPS : 0
Average Latency : 0
FBC Stats
Active Sessions : 0
Average FPS : 0
Average Latency : 0
[root@vgpu ~]#
7.2.1.5 监控vGPU引擎使用情况
要跨多个vGPU监控vGPU引擎使用情况,请使用nvidia-smi vgpu运行-u或--utilization选项。 对于每个vGPU,以下表中的使用统计数据每秒报告一次。 表还显示了命令输出中每个统计数据所报告的列的名称。
统计列3 d /计算sm存储器控制器带宽mem视频编码器enc视频解码器dec
每个报告的百分比是vGPU正在使用的物理GPU容量的百分比。例如,使用GPU图形引擎容量的20%的vGPU将报告20%。 要修改报告频率,请使用-l或--loop选项。 要将监视限制为平台上一部分GPU,请使用-i或--id选项选择一个或多个vGPU。
[root@vgpu ~]# nvidia-smi vgpu -u

7.2.1.6 应用程序监控vGPU引擎使用情况
要监控跨多个vGPU的应用程序对vGPU引擎的使用情况,请运行nvidia-smi vgpu,并使用-p选项。 对于每个vGPU上的每个应用程序,以下表中的使用统计数据每秒报告一次。每个应用程序由其进程ID和进程名称标识。 表还显示了命令输出中每个统计数据报告的列名。
统计列3 d /计算sm存储器控制器带宽mem视频编码器enc视频解码器dec
每个报告的百分比是应用程序在运行在物理GPU上的vGPU上的使用的物理GPU容量的百分比。例如,使用GPU图形引擎容量的20%的应用程序将报告20%。 要修改报告频率,请使用-l或--loop选项。 要将监视限制为平台上的一部分GPU,请使用-i或--id选项选择一个或多个vGPU。
[root@vgpu ~]# nvidia-smi vgpu -p

7.2.1.7 监控编码器会话
注意:只能监视分配给Windows虚拟机的vGPU的编码器会话。不会报告分配给Linux虚拟机的vGPU的编码器会话统计数据。 要监视在多个vGPU上运行的进程的编码器会话,请运行nvidia-smi vgpu,并使用-es或--encodersessions选项。 对于每个编码器会话,以下统计数据每秒报告一次:
- GPU ID
- vGPU ID
- 编码器会话ID
- 创建编码器会话的虚拟机中进程的PID
- 编解码器类型,例如H.264或H.265
- 编码水平分辨率
- 编码垂直分辨率
- 一秒钟的平均编码帧率
- 一秒钟的平均编码延迟(以微秒为单位) 要修改报告频率,请使用-l或--loop选项。 要将监视限制为平台上的一部分GPU,请使用-i或--id选项选择一个或多个vGPU。
[root@vgpu ~]# nvidia-smi vgpu -es

7.2.1.8 监控帧缓冲区捕获(FBC)会话
要监视在多个vGPU上运行的进程的FBC会话,请运行nvidia-smi vgpu,并使用-fs或--fbcsessions选项。 对于每个FBC会话,以下统计数据每秒报告一次:
- GPU ID
- vGPU ID
- FBC会话ID
- 创建FBC会话的虚拟机中进程的PID
- 与FBC会话相关联的显示序数。
- FBC会话类型
- FBC会话标志
- 捕获模式
- 会话支持的最大水平分辨率
- 会话支持的最大垂直分辨率
- 调用者在捕获调用中请求的水平分辨率
- 调用者在捕获调用中请求的垂直分辨率
- 会话每秒捕获的新帧的移动平均值
- 会话的新帧捕获延迟的移动平均值(以微秒为单位) 要修改报告频率,请使用-l或--loop选项。 要将监视限制为平台上的一部分GPU,请使用-i或--id选项选择一个或多个vGPU。
[root@vgpu ~]# nvidia-smi vgpu -fs


7.2.1.9 列出支持的vGPU类型
要列出系统中GPU支持的虚拟GPU类型,请运行nvidia-smi vgpu,并使用-s或--supported选项。 要将检索到的信息限制为平台上的一部分GPU,请使用-i或--id选项选择一个或多个vGPU。
[root@vgpu ~]# nvidia-smi vgpu -s -i 0
GPU 0000:83:00.0
GRID M60-0B
GRID M60-0Q
GRID M60-1A
GRID M60-1B
GRID M60-1Q
GRID M60-2A
GRID M60-2Q
GRID M60-4A
GRID M60-4Q
GRID M60-8A
GRID M60-8Q
[root@vgpu ~]#
要查看有关支持的vGPU类型的详细信息,请添加-v或--verbose选项:
[root@vgpu ~]# nvidia-smi vgpu -s -i 0 -v | less


7.2.1.10 列出当前可以创建的vGPU类型
要列出当前可以在系统中的GPU上创建的虚拟GPU类型,请运行nvidia-smi vgpu,并使用-c或--creatable选项。 该属性是一个动态属性,因每个GPU的MIG模式是否启用而异。
- 如果GPU未启用MIG模式,或者GPU不支持MIG,则该属性反映已在GPU上运行的vGPU的数量和类型。
- 如果GPU上没有运行任何vGPU,则列出GPU支持的所有vGPU类型。
- 如果GPU上运行一个或多个vGPU,但GPU未满载,则仅列出已在运行的vGPU的类型。
- 如果GPU已满载,则不列出任何vGPU类型。
- 如果GPU启用了MIG模式,则结果反映没有运行vGPU的GPU实例的数量和类型。
- 如果没有创建任何GPU实例,则不列出任何vGPU类型。
- 如果已创建GPU实例,则仅列出与没有运行vGPU的GPU实例相对应的vGPU类型。
- 如果每个GPU实例上都有一个vGPU在运行,则不列出任何vGPU类型。 要将检索到的信息限制为平台上的一部分GPU,请使用-i或--id选项选择一个或多个vGPU。
[root@vgpu ~]# nvidia-smi vgpu -c -i 0
GPU 0000:83:00.0
GRID M60-2Q
[root@vgpu ~]#
要查看当前可以创建的vGPU类型的详细信息,请添加-v或--verbose选项。
7.2.2 使用Citrix XenCenter监控GPU性能
如果您使用Citrix Hypervisor作为您的虚拟机管理程序,可以在XenCenter中监控GPU性能。
- 点击服务器的“性能”选项卡。
- 右键单击图表窗口,然后选择“操作”和“新建图表”。
- 为图表提供一个名称。
- 在可用计数器资源列表中,选择一个或多个GPU计数器。计数器会列出每个未用于GPU直通的物理GPU。
 7.3 从客户虚拟机监控GPU性能
7.3 从客户虚拟机监控GPU性能
您可以在单个客户虚拟机内使用监控工具来监控分配给该虚拟机的vGPU或直通GPU的性能。这些工具的范围仅限于您使用它们的客户虚拟机。您无法在单个客户虚拟机内使用监控工具来监控平台上的其他GPU。 对于vGPU,仅在客户虚拟机中报告以下指标:
- 3D/计算
- 内存控制器
- 视频编码器
- 视频解码器
- 帧缓冲区使用情况
其他通常存在于GPU中的指标不适用于vGPU,并根据您使用的工具报告为零或N/A。
7.3.1 使用nvidia-smi从客户虚拟机监控GPU性能
在客户虚拟机中,您可以使用nvidia-smi命令检索虚拟机中所有应用程序的总使用情况和单个应用程序对以下资源的使用情况:
- GPU
- 视频编码器
- 视频解码器
- 帧缓冲区
要使用nvidia-smi检索虚拟机中所有应用程序的总资源使用情况,请运行以下命令:
nvidia-smi dmon
以下示例显示了在Windows客户虚拟机中运行nvidia-smi dmon的结果。

要使用nvidia-smi检索虚拟机中运行的单个应用程序的资源使用情况,请运行以下命令:
nvidia-smi pmon

7.3.2 使用Windows性能计数器监控GPU性能
在Windows虚拟机中,GPU指标作为Windows性能计数器通过NVIDIA GPU对象提供。 任何启用读取性能计数器的应用程序都可以访问这些指标。您可以通过Windows操作系统附带的Windows性能监视器应用程序直接访问这些指标。 以下示例显示了性能监视器应用程序中的GPU指标。

在vGPU上,以下GPU性能计数器的读数为0,因为它们不适用于vGPU:
- %总线使用率
- %冷却器速率
- 核心时钟 MHz
- 风扇速度
- 内存时钟 MHz
- PCI-E到GPU当前速度 Mbps
- PCI-E到GPU当前宽度
- PCI-E到GPU下游宽度
- 功耗 mW
- 温度 C
7.3.3 使用NVWMI监控GPU性能
在Windows虚拟机中,Windows管理工具(WMI)通过NVWMI在ROOT\CIMV2\NV命名空间中公开GPU指标。NVWMI包含在NVIDIA驱动程序包中。安装驱动程序后,可以通过以下路径访问Windows帮助格式的NVWMI帮助信息:
C:\Program Files\NVIDIA Corporation\NVIDIA WMI Provider>nvwmi.chm
任何启用WMI的应用程序都可以访问这些指标。以下示例显示了第三方应用程序WMI Explorer中的GPU指标,该应用程序可以从CodePlex WMI Explorer页面下载。

在vGPU上,以下类的一些实例属性不适用于vGPU:
- Gpu
- PcieLink
不适用于vGPU的Gpu实例属性
Gpu Instance PropertyValue reported on vGPUgpuCoreClockCurrent-1memoryClockCurrent-1pciDownstreamWidth0pcieGpu.curGen0pcieGpu.curSpeed0pcieGpu.curWidth0pcieGpu.maxGen1pcieGpu.maxSpeed2500pcieGpu.maxWidth0power-1powerSampleCount-1powerSamplingPeriod-1verVBIOS.orderedValue0verVBIOS.strValue-verVBIOS.value0
不适用于vGPU的PcieLink实例属性
没有报告vGPU的PcieLink实例。
第八章、更改时间(分时)切片vGPU的调度行为
基于NVIDIA Maxwell™图形架构的NVIDIA GPU实现了一种最佳努力vGPU调度器,旨在平衡各个vGPU之间的性能。最佳努力调度器允许vGPU使用其他vGPU未使用的GPU处理周期。在某些情况下,运行图形密集型应用程序的虚拟机可能会对在其他虚拟机中运行的图形轻量级应用程序的性能产生不利影响。
基于NVIDIA GPU架构(在Maxwell架构之后)的GPU还支持均等共享和固定共享vGPU调度器。这些调度器对vGPU使用的GPU处理周期施加限制,从而防止在一个虚拟机中运行的图形密集型应用程序影响在其他虚拟机中运行的图形轻量级应用程序的性能。在支持多个vGPU调度器的GPU上,您可以选择要使用的vGPU调度器。您还可以设置均等共享和固定共享vGPU调度器的时间切片长度。
注意:如果您使用均等共享或固定共享vGPU调度器,则帧速率限制器(FRL)将被禁用。
最佳努力调度器是所有支持的GPU架构的默认调度器。如果您不确定您的GPU的NVIDIA GPU架构,请查阅NVIDIA虚拟GPU软件文档中的虚拟机管理程序发布说明。
8.1 时间(分时)切片vGPU的调度策略
除了默认的最佳努力调度器外,基于NVIDIA GPU架构(在Maxwell架构之后)的GPU还支持均等共享和固定共享vGPU调度器。
均等共享调度器Equal share scheduler
物理GPU在其上运行的所有vGPU之间平均共享。随着向GPU添加或从GPU中移除vGPU,分配给每个vGPU的GPU处理周期份额相应变化。因此,当同一GPU上的其他vGPU停止时,某个vGPU的性能可能会提高,或者当同一GPU上启动其他vGPU时,某个vGPU的性能可能会降低。
固定共享调度器Fixed share scheduler
每个vGPU被分配物理GPU处理周期的固定份额,其数量取决于vGPU类型,进而确定每个物理GPU上的最大vGPU数量。例如,每个物理GPU上T4-4C vGPU的最大数量为4。当调度策略为固定共享时,每个T4-4C vGPU被分配物理GPU处理周期的四分之一,即25%。随着向GPU添加或从GPU中移除vGPU,分配给每个vGPU的GPU处理周期份额保持恒定。因此,当同一GPU上启动或停止其他vGPU时,某个vGPU的性能保持不变。
默认情况下,这些调度器实施严格的轮询调度策略。在执行此策略时,调度器通过调整为配置了NVIDIA vGPU的每个VM的时间片来维护调度公平性。严格的轮询调度策略确保为配置了NVIDIA vGPU的VM更一致地调度工作,并限制在一个VM中运行的GPU密集型应用程序对其他VM中运行的应用程序的影响。
您可以通过调度工作给出现在计划状态时间最短的vGPU来确保调度公平性,而不是采用严格的轮询调度策略。这种行为是在NVIDIA vGPU软件版本15.0之前的默认调度行为。要控制调度器是否实施严格的轮询调度策略,请使用RmPVMRL注册表键。
当实施严格的轮询调度策略时,时间片的调整基于调度频率和平均因子。
调度频率
为特定vGPU调度工作的每秒次数。默认调度频率取决于驻留在物理GPU上的vGPU数量:
- 如果物理GPU上的vGPU少于8个,则默认为480 Hz。
- 如果物理GPU上有8个或更多vGPU,则默认为960 Hz。 平均因子 确定为每个vGPU累积的时间片超额的移动平均值的数字。此平均值控制调度频率的执行严格程度。平均因子的高值比低值更宽松地执行调度频率。 由于调度器为VM分配的实际时间可能超过或超出为VM指定的时间片,因此会出现与指定调度频率的偏差。调度器通过缩短下一个时间片来弥补VM的累积超额时间,以强制执行调度频率。 为计算为vGPU VM缩短下一个时间片的量,调度器维护每个vGPU VM累积超额时间的运行总数。此金额等于您指定的平均因子除以的运行总数。计算的金额也从累积超额时间中减去。平均因子的高值通过在较长时间内分散对累积超额时间的补偿来更宽松地执行调度频率。 要设置调度频率和平均因子,请使用RmPVMRL注册表键。
8.2 时间(分时)切片vGPU的调度器
当多个VM访问单个GPU上的vGPU时,GPU会按顺序为每个VM执行工作。vGPU调度器时间片代表了VM的工作在GPU上允许运行的时间量,直到被抢占并执行下一个VM的工作。
对于均等共享和固定共享vGPU调度器,您可以设置时间片的长度。时间片的长度会影响延迟和吞吐量。时间片的最佳长度取决于GPU正在处理的工作负载。
- 对于需要低延迟的工作负载,较短的时间片是最佳的。通常,这些工作负载是必须以固定间隔生成输出的应用程序,例如以60 FPS帧率生成输出的图形应用程序。这些工作负载对延迟敏感,应至少每个间隔运行一次。较短的时间片减少延迟,并通过导致调度器在VM之间更频繁切换来提高响应性。
- 对于需要最大吞吐量的工作负载,较长的时间片是最佳的。通常,这些工作负载是必须尽快完成工作且不需要响应性的应用程序,例如CUDA应用程序。较长的时间片通过防止频繁在VM之间切换来增加吞吐量。
8.3 RmPVMRL注册表键
RmPVMRL注册表键通过设置调度策略和时间片的长度来控制NVIDIA vGPU的调度行为。
注意:只能在支持多个vGPU调度器的GPU上更改vGPU调度行为,即基于Maxwell架构之后的NVIDIA GPU架构的GPU。
类型:Dword
内容:
默认时间片长度取决于每个物理GPU允许的vGPU类型的最大数量。
AA:两个十六进制数字,范围为0x01到0x3C,设置均等共享和固定共享调度器的平均因子,采用严格的轮询调度策略。如果AA为0x01,则在单个时间片中应用已累积的超额时间的补偿。如果AA为0x3C,则已累积的超额时间的补偿分布在60(0x3C)个时间片中。如果AA超出0x01到0x3C的范围,则使用默认值33。
FFF:三个十六进制数字,范围为0x3F到0x3C0,设置均等共享和固定共享调度器的调度频率,采用严格的轮询调度策略。时间片是调度频率的倒数。如果FFF为000或超出0x3F到0x3C0的范围,则将调度频率设置为vGPU类型的默认调度频率。
TT:两个十六进制数字,范围为01到1E,设置均等共享和固定共享调度器的时间片长度(毫秒)。最小长度为1毫秒,最大长度为30毫秒。如果TT为00,则将长度设置为vGPU类型的默认长度。如果TT大于1E,则将长度设置为30毫秒。
示例:
设置vGPU调度器为具有严格轮询调度策略和默认时间片长度、调度频率和平均因子的均等共享调度器:RmPVMRL=0x01
设置vGPU调度器为没有严格轮询调度策略且时间片为3毫秒的均等共享调度器:RmPVMRL=0x00030003
设置vGPU调度器为具有严格轮询调度策略和默认时间片长度、调度频率和平均因子的固定共享调度器:RmPVMRL=0x11
设置vGPU调度器为没有严格轮询调度策略且时间片为24毫秒的固定共享调度器:RmPVMRL=0x00180011
设置vGPU调度器为具有严格轮询调度策略、平均因子为60(0x3C)和调度频率为960(0x3C0)Hz的均等共享调度器:RmPVMRL=0x3c3c0001
设置vGPU调度器为具有严格轮询调度策略、平均因子为60(0x3C)和调度频率为960(0x3C0)Hz的固定共享调度器:RmPVMRL=0x3c3c0011
8.4 获取有关分时vGPU调度行为的信息
nvidia-smi命令提供了获取有关分时vGPU调度行为详细信息的选项。您还可以使用hypervisor的dmesg命令获取所有GPU当前的分时vGPU调度策略。
8.4.1 自15.1版本以来:获取分时vGPU调度器功能
分时vGPU的调度器功能是一组值,定义了如何配置vGPU以为配置了NVIDIA vGPU的每个VM分配工作。这些功能值取决于vGPU引擎类型,对于支持多种调度策略的vGPU,取决于vGPU是否支持和执行严格的轮询调度策略。
- 如果vGPU引擎类型为图形,则vGPU调度器功能值包括支持的调度策略和其他影响为配置了NVIDIA vGPU的每个VM分配工作的值。适用的功能值取决于vGPU是否支持和执行严格的轮询调度策略。
- 如果vGPU支持和执行严格的轮询调度策略,则适用于调度频率和平均因子的值。
- 否则,适用于支持的时间片范围的值。
- 如果vGPU引擎类型为除图形之外的任何类型,则唯一的vGPU调度器功能值指示支持最佳努力调度策略。所有其他功能值均为零。 要获取平台上所有分时vGPU的调度器功能,请使用nvidia-smi vgpu命令并带有--sc或--schedulercaps选项。 要将检索到的信息限制为平台上的一部分GPU,请使用-i或--id选项选择一个或多个GPU。
[root@vgpu ~]# nvidia-smi vgpu -sc
vGPU scheduler capabilities
Supported Policies : Best Effort
Equal Share
Fixed Share
ARR Mode : Supported
Supported Timeslice Range
Maximum Timeslice : 30000000 ns
Minimum Timeslice : 1000000 ns
Supported Scheduling Frequency
Maximum Frequency : 960
Minimum Frequency : 63
8.4.2 自15.1版本以来:获取分时vGPU调度器状态信息
分时vGPU的调度器状态信息包括为vGPU设置的调度策略以及控制为配置了vGPU的VM分配工作的属性值。可用的属性取决于为vGPU设置的调度策略。
可检索的vGPU调度器状态信息取决于配置了vGPU的VM是否正在运行。
[root@vgpu ~]# nvidia-smi vgpu -ss
GPU 00000000:65:00.0
Active vGPUs : 0
Scheduler Policy : Equal Share
ARR Mode : Enabled
Average Factor : Not Available
Time Slice(ns) : Not Available
要获取平台上所有分时vGPU的调度器状态信息,
[root@vgpu ~]# nvidia-smi vgpu -ss
GPU 00000000:65:00.0
Active vGPUs : 1
Scheduler Policy : Equal Share
ARR Mode : Enabled
Average Factor : 33
Time Slice(ns) : 2083333
请使用nvidiasmi vgpu命令并带有--ss或--schedulerstate选项。
要将检索到的信息限制为平台上的一部分GPU,请使用-i或--id选项选择一个或多个GPU。
以下示例显示了为配置了vGPU的VM未运行和正在运行时检索的调度器状态信息。在这些示例中,调度策略为均等共享调度器,采用严格的轮询调度策略以及默认的时间片长度、调度频率和平均因子。
8.4.3 获取分时vGPU调度器工作日志
分时vGPU的调度器工作日志提供有关为配置了vGPU的VM运行时工作分配的信息。
可检索的vGPU调度器工作日志中的信息取决于配置了vGPU的VM是否正在运行。
要获取平台上所有分时vGPU的调度器工作日志,请使用nvidia-smi vgpu命令并带有--sl或--schedulerlogs选项。
要将检索到的信息限制为平台上的一部分GPU,请使用-i或--id选项选择一个或多个GPU。
未运行的VM的vGPU调度器工作日志
[root@vgpu ~]# nvidia-smi vgpu -sl
+---------------------------------------------------------------------------------------------------------
+
Engine Id 1
Scheduler Policy Equal Share
GPU at deviceIndex 0 has no active VM runlist.
+---------------------------------------------------------------------------------------------------------
+
正在运行的VM的vGPU调度器工作日志
[root@vgpu ~]# nvidia-smi vgpu -sl
+---------------------------------------------------------------------------------------------------------
+
GPU Id 0
Engine Id 1
Scheduler Policy Equal Share
ARR Mode Enabled
Avg Factor 33
Time Slice 2083333
+---------------------------------------------------------------------------------------------------------
+
GPU SW Runlist Time Cumulative Prev Timeslice
Target Time Cumulative
Idx Id Stamp Run Time Runtime
Slice Preempt Time
0 0 1673362687729708384 2619237216 2083840
2005425 2493060
0 0 1673362687731793472 2621322304 2085088
2005372 2494762
0 0 1673362687733877664 2623406496 2084192
2005346 2495595
8.4.4 获取所有GPU的当前分时vGPU调度策略
您可以使用hypervisor的dmesg命令获取所有GPU的当前分时vGPU调度策略。在更改一个或多个GPU的调度行为之前获取此信息,以确定是否需要更改它,或在更改后确认更改。
在您的hypervisor命令shell中执行此任务。
1、在您的hypervisor主机机器上打开一个命令shell。
在所有支持的hypervisors上,您可以使用安全外壳(SSH)来实现此目的。各个hypervisors可能提供额外的登录方式。有关详细信息,请参考您的hypervisor文档。
2、使用dmesg命令显示包含字符串NVRM和scheduler的内核消息。
$ dmesg | grep NVRM | grep scheduler
这些消息中通过以下字符串指示调度策略:
- BEST_EFFORT
- EQUAL_SHARE
- FIXED_SHARE
如果调度策略为equal share或fixed share,则还会显示调度器时间片(以毫秒为单位)。
此示例获取了一个系统中GPU的调度策略,其中一个GPU的策略设置为best effort,一个GPU的策略设置为equal share,一个GPU的策略设置为fixed share。
$ dmesg | grep NVRM | grep scheduler
2020-10-05T02:58:08.928Z cpu79:2100753)NVRM: GPU at 0000:3d:00.0 has software
scheduler DISABLED with policy BEST_EFFORT.
2020-10-05T02:58:09.818Z cpu79:2100753)NVRM: GPU at 0000:5e:00.0 has software
scheduler ENABLED with policy EQUAL_SHARE.
NVRM: Software scheduler timeslice set to 1 ms.
2020-10-05T02:58:12.115Z cpu79:2100753)NVRM: GPU at 0000:88:00.0 has software
scheduler ENABLED with policy FIXED_SHARE.
NVRM: Software scheduler timeslice set to 1 ms.
8.5 更改所有GPU的分时vGPU调度行为
注意:您只能在支持多个vGPU调度器的GPU上更改vGPU调度行为,即在Maxwell架构之后基于NVIDIA GPU架构的GPU上。
在您的hypervisor命令shell中执行此任务。
1、在您的hypervisor主机机器上打开一个命令shell。
在所有支持的hypervisors上,您可以使用安全外壳(SSH)来实现此目的。各个hypervisors可能提供额外的登录方式。有关详细信息,请参考您的hypervisor文档。
2、将RmPVMRL注册表键设置为设置GPU调度策略和您想要的时间片长度的值。
在Citrix Hypervisor、Red Hat Enterprise Linux KVM或Red Hat Virtualization(RHV)上,将以下条目添加到/etc/modprobe.d/nvidia.conf文件中。
options nvidia NVreg_RegistryDwords="RmPVMRL=value"
如果/etc/modprobe.d/nvidia.conf文件尚不存在,请创建它。
在VMware vSphere上,使用esxcli set命令。
# esxcli system module parameters set -m nvidia -p
"NVreg_RegistryDwords=RmPVMRL=value"
值
设置GPU调度策略和您想要的时间片长度的值,例如:
0x01
将vGPU调度策略设置为带有默认时间片长度的均等共享调度器。
0x00030001
将GPU调度策略设置为带有3毫秒长时间片的均等共享调度器。
0x11
将vGPU调度策略设置为带有默认时间片长度的固定共享调度器。
0x00180011
将GPU调度策略设置为带有24(0x18)毫秒长时间片的固定共享调度器。
有关所有支持的值,请参阅RmPVMRL注册表键。
3、重新启动您的hypervisor主机机器
确认调度行为已按所需更改,如在获取所有GPU的当前分时vGPU调度策略中所述。
8.6 更改选定GPU的分时vGPU调度行为
注意:您只能在支持多个vGPU调度器的GPU上更改vGPU调度行为,即在Maxwell架构之后基于NVIDIA GPU架构的GPU上。
在您的hypervisor命令shell中执行此任务。
1、在您的hypervisor主机机器上打开一个命令shell。
在所有支持的hypervisors上,您可以使用安全外壳(SSH)来实现此目的。各个hypervisors可能提供额外的登录方式。有关详细信息,请参考您的hypervisor文档。
2、使用lspci命令获取每个要更改调度行为的GPU的PCI域和总线/设备/功能(BDF)。
- 在Citrix Hypervisor、Red Hat Enterprise Linux KVM或Red Hat Virtualization(RHV)上,添加-D选项以显示PCI域,-d 10de:选项以仅显示NVIDIA GPU的信息。
# lspci -D -d 10de:
- 在VMware vSphere上,将lspci的输出导入grep命令以仅显示NVIDIA GPU的信息。
# lspci | grep NVIDIA
此示例中列出的NVIDIA GPU具有PCI域0000和BDF 86:00.0。
0000:86:00.0 3D controller: NVIDIA Corporation GP104GL [Tesla P4] (rev a1)
3、使用模块参数NVreg_RegistryDwordsPerDevice为每个GPU设置pci和RmPVMRL注册表键。
- 在Citrix Hypervisor、Red Hat Enterprise Linux KVM或Red Hat Virtualization(RHV)上,将以下条目添加到/etc/modprobe.d/nvidia.conf文件中。
options nvidia NVreg_RegistryDwordsPerDevice="pci=pci-domain:pcibdf;
RmPVMRL=value
[;pci=pci-domain:pci-bdf;RmPVMRL=value...]"
如果/etc/modprobe.d/nvidia.conf文件尚不存在,请创建它。
在VMware vSphere上,使用esxcli set命令。
# esxcli system module parameters set -m nvidia \
-p "NVreg_RegistryDwordsPerDevice=pci=pci-domain:pci-bdf;RmPVMRL=value\
[;pci=pci-domain:pci-bdf;RmPVMRL=value...]"
对于每个GPU,请提供以下信息:
pci-domain
GPU的PCI域。
pci-bdf
GPU的PCI设备BDF。
value
设置GPU调度策略和您想要的时间片长度的值,例如:
0x01
将GPU调度策略设置为带有默认时间片长度的均等共享调度器。
0x00030001
将GPU调度策略设置为带有3毫秒长时间片的均等共享调度器。
0x11
将GPU调度策略设置为带有默认时间片长度的固定共享调度器。
0x00180011
将GPU调度策略设置为带有24(0x18)毫秒长时间片的固定共享调度器。
有关所有支持的值,请参阅RmPVMRL注册表键。
此示例向/etc/modprobe.d/nvidia.conf文件添加一个条目,以更改单个GPU的调度行为。该条目将PCI域0000和BDF 86:00.0的GPU的GPU调度策略设置为固定共享调度器,具有默认时间片长度。
options nvidia NVreg_RegistryDwordsPerDevice=
"pci=0000:86:00.0;RmPVMRL=0x11"
这个示例向/etc/modprobe.d/nvidia.conf文件添加了一个条目,以更改单个GPU的调度行为。该条目将PCI域为0000且BDF为86:00.0的GPU的调度策略设置为固定共享调度器,时间片长度为24(0x18)毫秒。
options nvidia NVreg_RegistryDwordsPerDevice=
"pci=0000:86:00.0;RmPVMRL=0x00180011"
这个示例更改了在运行VMware vSphere的hypervisor主机上的单个GPU的调度行为。该命令将PCI域为0000且BDF为15:00.0的GPU的调度策略设置为固定共享调度器,具有默认时间片长度。
# esxcli system module parameters set -m nvidia -p \
"NVreg_RegistryDwordsPerDevice=pci=0000:15:00.0;RmPVMRL=0x11[;pci=0000:15:00.0;RmPVMRL=0x11]"
这个示例更改了在运行VMware vSphere的hypervisor主机上的单个GPU的调度行为。该命令将PCI域为0000且BDF为15:00.0的GPU的调度策略设置为固定共享调度器,时间片长度为24(0x18)毫秒。
# esxcli system module parameters set -m nvidia -p \
"NVreg_RegistryDwordsPerDevice=pci=0000:15:00.0;RmPVMRL=0x11[;pci=0000:15:00.0;RmPVMRL=0x00180011]"
4、重新启动您的hypervisor主机机器。
确认调度行为已按所需更改,如在获取所有GPU的当前分时vGPU调度策略中所述。
8.7 恢复默认的分时vGPU调度器设置
在您的hypervisor命令shell中执行此任务。
1、在您的hypervisor主机机器上打开一个命令shell。
在所有支持的hypervisors上,您可以使用安全外壳(SSH)来实现此目的。各个hypervisors可能提供额外的登录方式。有关详细信息,请参考您的hypervisor文档。
2、取消设置RmPVMRL注册表键。
在Citrix Hypervisor、Red Hat Enterprise Linux KVM或Red Hat Virtualization(RHV)上,通过在/etc/modprobe.d/nvidia.conf文件中使用#字符为每个设置RmPVMRL的条目添加注释。
在VMware vSphere上,将模块参数设置为空字符串。
# esxcli system module parameters set -m nvidia -p "module-parameter="
模块参数
要设置的模块参数,取决于是否已更改所有GPU或选定GPU的调度行为:
对于所有GPU,请设置NVreg_RegistryDwords模块参数。
对于选定GPU,请设置NVreg_RegistryDwordsPerDevice模块参数。
例如,要在所有GPU上更改默认vGPU调度器设置后恢复它们,输入以下命令:
# esxcli system module parameters set -m nvidia -p "NVreg_RegistryDwords="
3、重新启动您的hypervisor主机机器。
第九章、 故障排除
本章介绍了在Citrix Hypervisor、Red Hat Enterprise Linux KVM、Red Hat Virtualization(RHV)和VMware vSphere上进行NVIDIA vGPU的基本故障排除步骤,以及在提交错误报告时如何收集调试信息。
已知问题 在进行故障排除或提交错误报告之前,请查阅每个驱动程序发布版本附带的发布说明,了解当前版本的已知问题和潜在解决方法。
9.2 故障排除步骤
如果启用了vGPU的虚拟机无法启动,或者在启动时没有显示任何输出,按照以下步骤缩小可能原因范围。
9.2.1 验证NVIDIA内核驱动程序是否加载
1、使用您的虚拟化程序提供的命令来验证内核驱动程序是否已加载:
‣ 在Citrix Hypervisor、Red Hat Enterprise Linux KVM和RHV上,使用lsmod:
[root@xenserver ~]# lsmod|grep nvidia
nvidia 9604895 84
i2c_core 20294 2 nvidia,i2c_i801
[root@xenserver ~]#
在VMware vSphere上使用vmkload_mod:
[root@esxi:~] vmkload_mod -l | grep nvidia
nvidia 5 8420
2、如果nvidia驱动程序未在输出中列出,请检查dmesg以查看驱动程序报告的任何加载时错误(请参阅检查NVIDIA内核驱动程序输出)。
3、在Citrix Hypervisor、Red Hat Enterprise Linux KVM和RHV上,还可以使用rpm -q命令来验证NVIDIA GPU Manager软件包是否已正确安装。
#rpm -q vgpu-manager-rpm-package-name
vgpu-manager-rpm-package-name
NVIDIA GPU Manager软件包的RPM软件包名称,例如Citrix Hypervisor的NVIDIA GPU Manager软件包的名称为NVIDIAvGPU-NVIDIA-vGPU-CitrixHypervisor-8.2-525.125.03。
此示例验证了Citrix Hypervisor的NVIDIA GPU Manager软件包是否已正确安装。
[root@xenserver ~]# rpm –q NVIDIA-vGPU-NVIDIA-vGPU-CitrixHypervisor-8.2-525.125.03
[root@xenserver ~]#
If an existing NVIDIA GRID package is already installed and you don’t select the
upgrade (-U) option when installing a newer GRID package, the rpm command will
return many conflict errors.
Preparing packages for installation...
file /usr/bin/nvidia-smi from install of NVIDIA-vGPU-NVIDIA-vGPUCitrixHypervisor-
8.2-525.125.03.x86_64 conflicts with file from package NVIDIAvGPU-
xenserver-8.2-525.105.14.x86_64
file /usr/lib/libnvidia-ml.so from install of NVIDIA-vGPU-NVIDIA-vGPUCitrixHypervisor-
8.2-525.125.03.x86_64 conflicts with file from package NVIDIAvGPU-
xenserver-8.2-525.105.14.x86_64
9.2.2 验证nvidia-smi工作正常
如果物理GPU上正确加载了NVIDIA内核驱动程序,请运行nvidia-smi并验证输出中列出了所有当前未用于GPU透传的物理GPU。有关预期输出的详细信息,请参阅NVIDIA系统管理界面nvidia-smi。 如果nvidia-smi未报告预期输出,请检查dmesg以查看NVIDIA内核驱动程序的消息。
9.2.3 检查NVIDIA内核驱动程序输出
NVIDIA内核驱动程序的信息和调试消息记录在内核日志中,并以NVRM或nvidia为前缀。 在Citrix Hypervisor、Red Hat Enterprise Linux KVM、RHV和VMware vSphere上运行dmesg,并检查是否有NVRM和nvidia前缀。
[root@xenserver ~]# dmesg | grep -E "NVRM|nvidia"
[ 22.054928] nvidia: module license 'NVIDIA' taints kernel.
[ 22.390414] NVRM: loading
[ 22.829226] nvidia 0000:04:00.0: enabling device (0000 -> 0003)
[ 22.829236] nvidia 0000:04:00.0: PCI INT A -> GSI 32 (level, low) -> IRQ 32
[ 22.829240] NVRM: This PCI I/O region assigned to your NVIDIA device is invalid:
[ 22.829241] NVRM: BAR0 is 0M @ 0x0 (PCI:0000:00:04.0)
[ 22.829243] NVRM: The system BIOS may have misconfigured your GPU.
9.2.4 检查 NVIDIA 虚拟 GPU 管理器
消息 NVIDIA 虚拟 GPU 管理器的信息和调试消息被记录在虚拟化管理程序的日志文件中,并以 vmiop 为前缀。
9.2.4.1 检查 Citrix Hypervisor vGPU 管理器 消息
对于 Citrix Hypervisor,NVIDIA 虚拟 GPU 管理器的消息被写入到 /var/log/messages 中。
在 /var/log/messages 文件中查找以 vmiop 为前缀的内容。
[root@xenserver ~]# grep vmiop /var/log/messages
Jul 17 10:34:03 localhost vgpu-ll[25698]: notice: vmiop_log: gpu-pci-id :
0000:05:00.0
Jul 17 10:34:03 localhost vgpu-ll[25698]: notice: vmiop_log: vgpu_type : quadro
Jul 17 10:34:03 localhost vgpu-ll[25698]: notice: vmiop_log: Framebuffer: 0x74000000
Jul 17 10:34:03 localhost vgpu-ll[25698]: notice: vmiop_log: Virtual Device Id:
0xl3F2:0xll4E
Jul 17 10:34:03 localhost vgpu-ll[25698]: notice: vmiop_log: ######## vGPU Manager
Information: ########
Jul 17 10:34:03 localhost vgpu-ll[25698]: notice: vmiop_log: Driver
Version: 525.125.03
Jul 17 10:34:03 localhost vgpu-ll[25698]: notice: vmiop_log: Init frame copy engine:
syncing...
Jul 17 10:35:31 localhost vgpu-ll[25698]: notice: vmiop_log: ######## Guest NVIDIA
Driver Information: ########
Jul 17 10:35:31 localhost vgpu-ll[25698]: notice: vmiop_log: Driver Version: 529.11
Jul 17 10:35:36 localhost vgpu-ll[25698]: notice: vmiop_log: Current max guest pfn =
0xllbc84!
Jul 17 10:35:40 localhost vgpu-ll[25698]: notice: vmiop_log: Current max guest pfn =
0xlleff0!
[root@xenserver ~]#
9.2.4.2 检查 Red Hat Enterprise Linux KVM vGPU 管理器 消息
对于 Red Hat Enterprise Linux KVM 和 RHV,NVIDIA 虚拟 GPU 管理器的消息被写入到 /var/log/messages 中。
在这些文件中查找以 vmiop_log: 为前缀的内容:
# grep vmiop_log: /var/log/messages
[2023-07-14 04:46:12] vmiop_log: [2023-07-14 04:46:12] notice: vmiop-env:
guest_max_gpfn:0x11f7ff
[2023-07-14 04:46:12] vmiop_log: [2023-07-14 04:46:12] notice: pluginconfig: /usr/
share/nvidia/vgx/grid_m60-1q.conf,gpu-pci-id=0000:06:00.0
[2023-07-14 04:46:12] vmiop_log: [2023-07-14 04:46:12] notice: Loading Plugin0:
libnvidia-vgpu
[2023-07-14 04:46:12] vmiop_log: [2023-07-14 04:46:12] notice: Successfully update
the env symbols!
[2023-07-14 04:46:12] vmiop_log: [2023-07-14 04:46:12] notice: vmiop_log: gpu-pciid
: 0000:06:00.0
[2023-07-14 04:46:12] vmiop_log: [2023-07-14 04:46:12] notice: vmiop_log:
vgpu_type : quadro
[2023-07-14 04:46:12] vmiop_log: [2023-07-14 04:46:12] notice: vmiop_log:
Framebuffer: 0x38000000
[2023-07-14 04:46:12] vmiop_log: [2023-07-14 04:46:12] notice: vmiop_log: Virtual
Device Id: 0x13F2:0x114D
[2023-07-14 04:46:12] vmiop_log: [2023-07-14 04:46:12] notice: vmiop_log: ########
vGPU Manager Information: ########
[2023-07-14 04:46:12] vmiop_log: [2023-07-14 04:46:12] notice: vmiop_log: Driver
Version: 525.125.03
[2023-07-14 04:46:12] vmiop_log: [2023-07-14 04:46:12] notice: vmiop_log: Init frame
copy engine: syncing...
[2023-07-14 05:09:14] vmiop_log: [2023-07-14 05:09:14] notice: vmiop_log: ########
Guest NVIDIA Driver Information: ########
[2023-07-14 05:09:14] vmiop_log: [2023-07-14 05:09:14] notice: vmiop_log: Driver
Version: 529.11
[2023-07-14 05:09:14] vmiop_log: [2023-07-14 05:09:14] notice: vmiop_log: Current
max guest pfn = 0x11a71f!
[2023-07-14 05:12:09] vmiop_log: [2023-07-14 05:12:09] notice: vmiop_log: vGPU
license state: (0x00000001)
#
9.2.4.3 检查 VMware vSphere vGPU 管理器 消息
对于 VMware vSphere,NVIDIA 虚拟 GPU 管理器的消息被写入到客户虚拟机存储目录中的 vmware.log 文件中。
在 vmware.log 文件中查找以 vmiop 为前缀的内容:
[root@esxi:~] grep vmiop /vmfs/volumes/datastore1/win7-vgpu-test1/vmware.log
2023-07-14T14:02:21.275Z| vmx| I120: DICT pciPassthru0.virtualDev = "vmiop"
2023-07-14T14:02:21.344Z| vmx| I120: GetPluginPath testing /usr/lib64/vmware/plugin/
libvmx-vmiop.so
2023-07-14T14:02:21.344Z| vmx| I120: PluginLdr_LoadShared: Loaded shared plugin
libvmx-vmiop.so from /usr/lib64/vmware/plugin/libvmx-vmiop.so
2023-07-14T14:02:21.344Z| vmx| I120: VMIOP: Loaded plugin libvmxvmiop.
so:VMIOP_InitModule
2023-07-14T14:02:21.359Z| vmx| I120: VMIOP: Initializing plugin vmiop-display
2023-07-14T14:02:21.365Z| vmx| I120: vmiop_log: gpu-pci-id : 0000:04:00.0
2023-07-14T14:02:21.365Z| vmx| I120: vmiop_log: vgpu_type : quadro
2023-07-14T14:02:21.365Z| vmx| I120: vmiop_log: Framebuffer: 0x74000000
2023-07-14T14:02:21.365Z| vmx| I120: vmiop_log: Virtual Device Id: 0x11B0:0x101B
2023-07-14T14:02:21.365Z| vmx| I120: vmiop_log: ######## vGPU Manager Information:
########
2023-07-14T14:02:21.365Z| vmx| I120: vmiop_log: Driver Version: 525.125.03
2023-07-14T14:02:21.365Z| vmx| I120: vmiop_log: VGX Version: 15.3
2023-07-14T14:02:21.445Z| vmx| I120: vmiop_log: Init frame copy engine: syncing...
2023-07-14T14:02:37.031Z| vthread-12| I120: vmiop_log: ######## Guest NVIDIA Driver
Information: ########
2023-07-14T14:02:37.031Z| vthread-12| I120: vmiop_log: Driver Version: 529.11
2023-07-14T14:02:37.031Z| vthread-12| I120: vmiop_log: VGX Version: 15.3
2023-07-14T14:02:37.093Z| vthread-12| I120: vmiop_log: Clearing BAR1 mapping
2023-07-17T23:39:55.726Z| vmx| I120: VMIOP: Shutting down plugin vmiop-display
[root@esxi:~]
9.3 捕获配置数据以便提交错误报告
在向 NVIDIA 提交错误报告时,可以通过以下方式之一从出现错误的平台捕获相关配置数据:
- 在任何支持的虚拟化管理程序上运行 nvidia-bug-report.sh。
- 在 Citrix Hypervisor 上,创建一个 Citrix Hypervisor 服务器状态报告。
9.3.1 通过运行 nvidia-bug-report.sh 捕获配置数据
nvidia-bug-report.sh 脚本将调试信息捕获到服务器上的一个 gzip 压缩的日志文件中。 从 Citrix Hypervisor dom0 shell、Red Hat Enterprise Linux KVM 主机 shell、Red Hat Virtualization (RHV) 主机 shell 或 VMware ESXi 主机 shell 运行 nvidia-bug-report.sh。
本示例在 Citrix Hypervisor 上运行 nvidia-bug-report.sh,但在 Red Hat Enterprise Linux KVM、RHV 或 VMware vSphere ESXi 上的操作步骤相同。
[root@xenserver ~]# nvidia-bug-report.sh
nvidia-bug-report.sh will now collect information about your
system and create the file 'nvidia-bug-report.log.gz' in the current
directory. It may take several seconds to run. In some
cases, it may hang trying to capture data generated dynamically
by the Linux kernel and/or the NVIDIA kernel module. While
the bug report log file will be incomplete if this happens, it
may still contain enough data to diagnose your problem.
For Xen open source/XCP users, if you are reporting a domain issue,
please run: nvidia-bug-report.sh --domain-name <"domain_name">
Please include the 'nvidia-bug-report.log.gz' log file when reporting
your bug via the NVIDIA Linux forum (see devtalk.nvidia.com)
or by sending email to '[email protected]'.
Running nvidia-bug-report.sh...
If the bug report script hangs after this point consider running with
--safe-mode command line argument.
complete
[root@xenserver ~]#
9.3.2 通过创建 Citrix Hypervisor 状态报告捕获配置数据
- 在 XenCenter 中,从“工具”菜单中选择“服务器状态报告”。
- 选择要收集状态报告的 Citrix Hypervisor 实例。
- 选择要包含在报告中的数据。
- 要包含 NVIDIA vGPU 调试信息,请在报告内容项目列表中选择“NVIDIA-logs”。
- 生成报告。
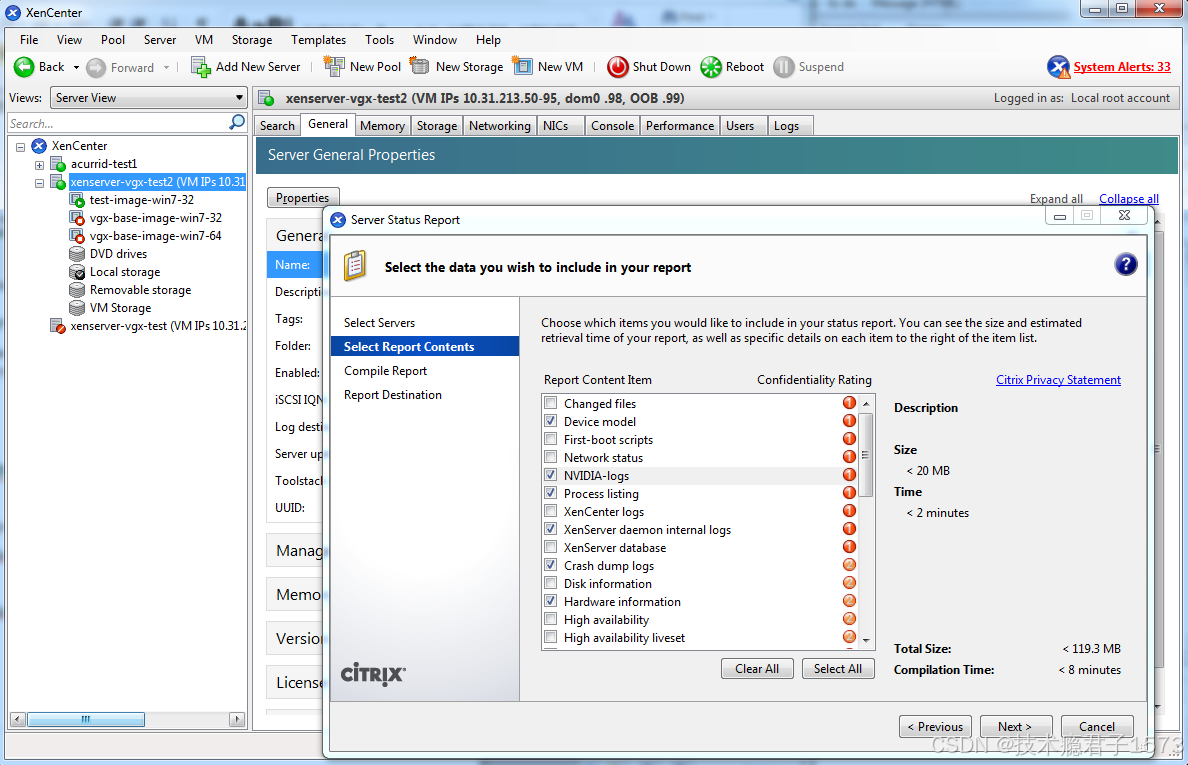
在 Citrix Hypervisor 状态报告中包含 NVIDIA 日志
附录 A. 虚拟 GPU 类型 参考;
A.1 支持的 GPU 的虚拟 GPU 类型
NVIDIA vGPU 是在支持的 NVIDIA GPU 上作为许可产品提供的。要查看推荐的服务器平台和支持的 GPU 列表,请参阅 NVIDIA 虚拟 GPU 软件文档中支持的虚拟化管理程序的发布说明。
A.1.1 NVIDIA A800 PCIe 80GB 和 NVIDIA A800 PCIe 80GB 液冷虚拟 GPU 类型
每个板的物理 GPU 数量:1
此 GPU 支持 MIG 支持的虚拟 GPU 和分时虚拟 GPU。
NVIDIA A800 PCIe 80GB 和 NVIDIA A800 PCIe 80GB 液冷的虚拟 GPU 类型是相同的。
NVIDIA A800 PCIe 80GB 和 NVIDIA A800 PCIe 80GB 液冷的 MIG 支持的 C 系列虚拟 GPU 类型 所需的许可版本:
vCS 或 vWS 有关 GPU 实例配置文件的详细信息,请参阅 NVIDIA 多实例 GPU 用户指南。
虚拟GPU类型预期用途情况下框架
缓冲
(MB)每GPU最大
vGPUs
每个vGPU切片数每个vGPU的计算实例对应的GPU实例配置文件A800D-7-80C
训练
工作负载
81920177MIG 7g.80gbA800D-4-40C
训练
工作负载
40960144MIG 4g.40gbA800D-3-40C
训练
工作负载
40960233MIG 3g.40gbA800D-2-20C
训练
工作负载
20480322MIG 2g.20gbA800D-1-10C
训练
工作负载
10240711MIG 1g.10gbA800D-1-10CME
训练
工作负载
10240111MIG 1g.10gb+me
Time-Sliced (分时切片)C-Series Virtual GPU Types for NVIDIA A800 PCIe 80GB and NVIDIA A800 PCIe 80GB Liquid Cooled 所需许可版本:
vCS或vWS
这些vGPU类型支持单个显示器,具有固定的最大分辨率。
虚拟GPU类型预期用途情况下框架
缓冲
(MB)每GPU最大
vGPUs每块单板最大vgpu数最大显示分辨率每个vGPU的虚拟显示器A800D-80C
训练
工作负载
81920114096×21601A800D-40C
训练
工作负载
40960224096×21601A800D-20C
训练
工作负载
20480444096×21601A800D-16C
训练
工作负载
16384554096×21601A800D-10C
训练
工作负载
10240884096×21601A800D-8C
训练
工作负载
819210104096×21601A800D-4C
训练
工作负载
409620204096×21601
A.1.2 NVIDIA A800 HGX虚拟GPU类型
每个板的物理GPU数量:1
此GPU支持MIG支持的虚拟GPU和分时虚拟GPU。
NVIDIA A800 HGX 80GB的MIG支持的C系列虚拟GPU类型
所需许可版本:vCS或vWS 有关GPU实例配置文件的详细信息,请参阅NVIDIA Multi-Instance GPU用户指南。
虚拟GPU类型预期用途情况下框架
缓冲
(MB)每GPU最大
vGPUs
每个vGPU切片数每个vGPU的计算实例对应的GPU实例配置文件A800DX-7-80C
训练
工作负载
81920177MIG 7g.80gbA800DX-4-40C
训练
工作负载
40960144MIG 4g.40gbA800DX-3-40C
训练
工作负载
40960233MIG 3g.40gbA800DX-2-20C
训练
工作负载
20480322MIG 2g.20gbA800DX-1-10C
训练
工作负载
10240711MIG 1g.10gbA800DX-1-10CME
训练
工作负载
10240111MIG 1g.10gb+me
剩余支持的相关信息请看官方原版英文手册
525.125.03-525.125.06-529.11-grid-vgpu-user-guide.pdf资源-CSDN文库
版权归原作者 技术瘾君子1573 所有, 如有侵权,请联系我们删除。