
文章目录
前言
知识图谱是一个大规模语义网,由实体,概念等节点和属性,关系,类型等边构成。
是许多三元组的集合。每一个三元组是由主语(subject),谓语(predicate),宾语(object)构成。
随着各个领域不断增长的知识图谱,知识图谱存储也吸引着很多人进行研究,本文将从知识图谱的数据模型、存储方式、基于关系/原生的知识图谱存储管理、数据库等几方面进行阐述。
【本文篇幅较长计9662字,阅读完大概需十分钟,若有想直接了解的内容,可直接点击目录】
一、知识图谱
1、数据模型
知识图谱的两种主流数据模型(数据的结构、操作和约束):
RDF 图模型和属性图模型
数据模型特性数据模型特性RDF图模型属性图模型结构标准化程度 数学模型 表达力 边属性表达 概念层本体定义 串行化格式已由W3C制定了标准化的语法和语义 3-均匀有向标签超图 RDF图模型强于属性图模型 通过额外方法, 如“具体化” RDFS、OWL、 XML、JSON、N-Triples、Turtle等尚未形成工业标准 有向标签属性图 属性图模型弱于RDF图模型 内置支持 不支持 CSV操作查询代数SPARQL代数无查询语言SPARQLCypher、Gremlin、PGQL、G-CORE约束约束语言RDF Shapes约束语言(SHACL)无
2、数据库管理系统
知识图谱数据模型的主流数据库管理系统:
RDF三元组库和原生图数据库
3、查询语言
知识图谱查询语言:
SPARQL、Cypher、Gremlin、PGQL 和 G-CORE
语法/语义/特性SPARQLCypherGremlinPGQLG-CORE图模式匹配查询语法CGPCGPCGP(无可选)1CGPCGP语义子图同态、包2无重复边、包2子图同态、包2子图同构3、包2子图同态、包2导航式查询语法RPQ超集(增加反向边和属性集上的否定)RPQ子集(*只能作用在单边)RPQ超集(增加通过表达式比较属性值)RPQ超集(增加比较路径上的顶点和边)RPQ超集(增加复杂路径表达式)语义任意路径、集合4无重复边5、包2任意路径6、包2最短路径7、包8最短路径9、包2分析型查询聚合函数聚合函数聚合函数、PageRank、PeerPressure聚类聚合函数聚合函数查询可组合性否是是否是数据更新语言DMLCRUD10CRUD无无CR数据定义语言DDL无有无无无实现系统Jena、RDF4J、gStore、Virtuoso等Neo4j、AgensGraph等TinkerTop等Oracle PGX无
注:1. Gremlin不显式支持可选(optional)操作, 但可以通过其他语法特性等价模拟.2.可通过DISTINCT关键字支持集合语义.3. PGQL默认的图模式匹配查询语义是子图同构, 可使用ALL关键字改为子图同态.4. SPARQL中只有当使用*运算使得属性路径查询无法等价写为CGP时才使用集合语义.5. Cypher可通过shortestPath函数支持最短路径语义.6. Gremlin中其他语义可以被模拟出来.7. PGQL路径查询可通过用户定义函数实现其他语义.8. PGQL路径查询返回单条最短路径, 集合和包语义相同.9. G-CORE路径查询可通过ALL关键字改为任意路径语义.10. CRUD分别代表CREATE创建、READ读取、UPDATE更新和DELETE删除
4、查询操作
知识图谱上 3 种主要的查询操作类型:
图模式匹配、导航式和分析型查询
- RDF图: 设U、B 和 L 为互不相交的无限集合,分别代表 URI、空顶点(blank node)和字面量(literal). 一个三元组(s,p,o) ∈ \in ∈( U ∪ B U \cup B U∪B) × \times ×U × \times ×( U U U ∪ \cup ∪ B B B ∪ \cup ∪ L L L)称为 RDF 三元组,其中,s 为主语,p 为谓语,o 为宾语.RDF 图 G 是 RDF 三元组的有限集合.
- 属性图:属性图 G 是 5 元组( V V V, E E E, ρ \rho ρ, λ \lambda λ, σ \sigma σ,),其中, (1) V 是顶点的有限集合; (2) E 是边的有限集合且 V ∩ E = ϕ V\cap E=\phi V∩E=ϕ ; (3) 函数 ρ : E → ( V × V ) \rho:E\rightarrow(V\times V) ρ:E→(V×V)将边关联到顶点对,如 ρ ( e ) = ( v 1 , v 2 ) \rho(e)=(v1,v2) ρ(e)=(v1,v2)表示$ e $是从顶点 v 1 v1 v1 到顶点 v 2 v2 v2 的有向边; (4) 设 L a b Lab Lab 是 标签集合,函数 λ : ( V ∪ E ) → L a b \lambda: (V\cup E)\rightarrow Lab λ:(V∪E)→Lab为顶点或边赋予标签,如 v ∈ \in ∈V(或 e ∈ \in ∈E)且 λ ( v ) = l \lambda(v)=l λ(v)=l(或 λ \lambda λ(e)= l l l),则$ l$ 为顶点 v(或边 e)的标 签; (5) 设 P r o p Prop Prop是属性集合, V a l Val Val是值集合,函数 ρ : ( V ∪ E ) × P r o p → V a l \rho:(V\cup E)\times Prop \rightarrow Val ρ:(V∪E)×Prop→Val为顶点或边关联属性,如 v ∈ V ( 或 e ∈ E ) 、 p ∈ P r o p v \in V (或e \in E)、p \in Prop v∈V(或e∈E)、p∈Prop且 σ ( v , p ) = v a l ( \sigma(v,p)=val( σ(v,p)=val(或 σ ( e , p ) = v a l \sigma(e,p)=val σ(e,p)=val,则顶点 v ( 或边 e ) v(或边e) v(或边e)上属性 p 的值为 v a l p的值为val p的值为val
二、知识图谱存储方式
1、关系型存储
存储大规模知识图谱,且便于对知识进行更新,但当知识图谱查询的选择性较大时,查询性能明显下降
2、原生图存储
无邻接索引的特性能够高效处理复杂的知识图谱查询,但有限的存储容量和不灵活的更新机制使得原生图存储不能很好地应用于大规模知识图谱中
三、基于关系的知识图谱存储管理
关系数据库目前仍是使用最多的数据库管理系统。基于关系的知识图谱存储方案,包括:三元组表、水平表、属性表、垂直划分、六重索引和 DB2RDF。
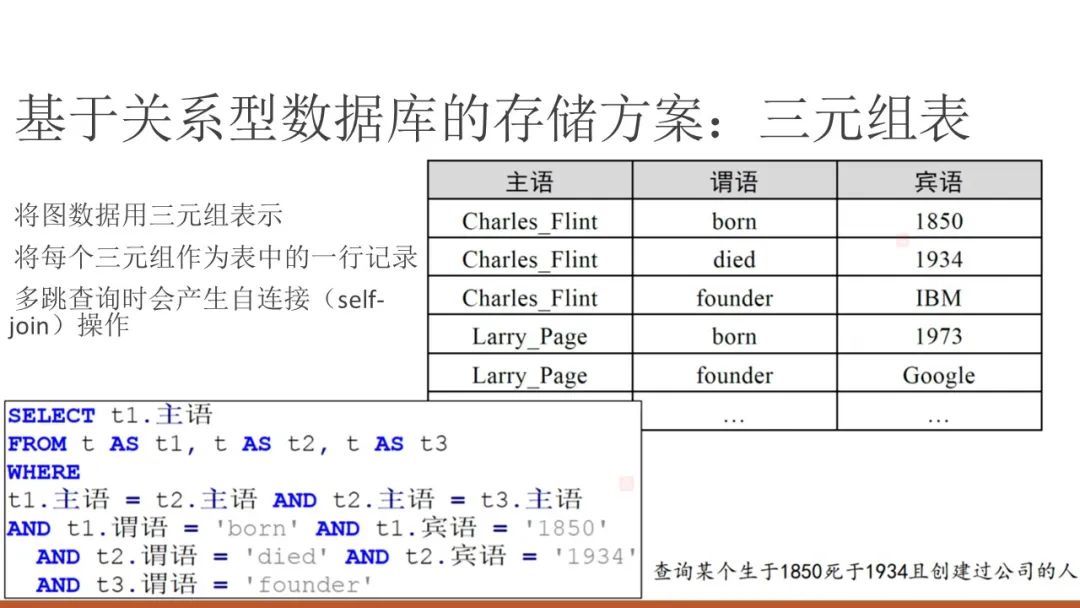
1、三元组表
三元组表(triple table)是将知识图谱存储到关系数据库的最简单、最直接的办法,就是在关系数据库中建立 一张具有 3 列的表,该表的模式为triple_table(subject,predicate,object),subject、predicate 和 object 这 3 列分别表示主语、谓语和宾语。
- 三元组表存储方案虽然简单明了,但三元组表的行数与知识图谱的边数相等,其最大问题在于将知识图谱查询翻译为 SQL 查询后会产生三元组表的大量自连接操作
- RDF 数据库系统 3store
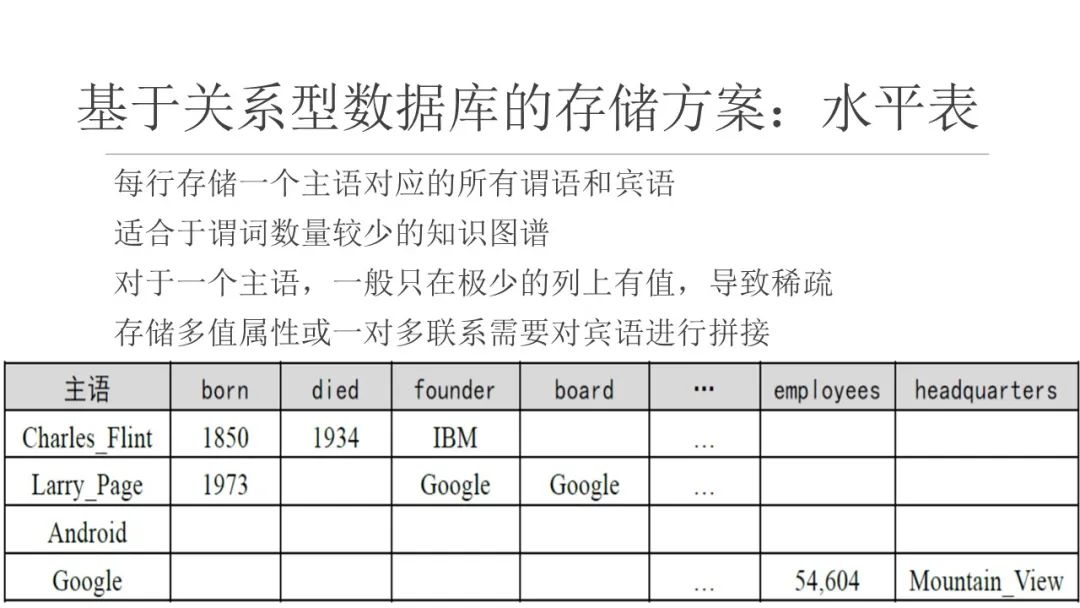
2、水平表
水平表(horizontal table)存储方案同样非常简单。水平表的每行记录存储知识图谱中一个主语的所有谓语 和宾语。实际上,水平表相当于知识图谱的邻接表。水平表的列数是知识图谱中不同谓语的数量,行数是知识图 谱中不同主语的数量。
- RDF 数据库系统 DLDB
- 水平表的缺点在于: - (1) 所需列的数目等于知识图谱中不同谓语数量,在真实知识图谱数据集中,不同 谓语数量可能为几千个到上万个,很可能超出关系数据库所允许的表中列数目上限- (2) 对于一行来说,仅在极 少数列上具有值,表中存在大量空值,空值过多会影响表的存储、索引和查询性能- (3) 在知识图谱中,同一主语 和谓语可能具有多个不同宾语,即一对多联系或多值属性,而水平表的一行一列上只能存储一个值,无法应对这种情况(可以将多个值用分隔符连接存储为一个值,但这违反了关系数据库设计的第一范式);- (4) 知识图谱的更新往往会引起谓语的增加、修改或删除,即水平表中列的增加、修改或删除,这是对于表结构的改变,成本很高。
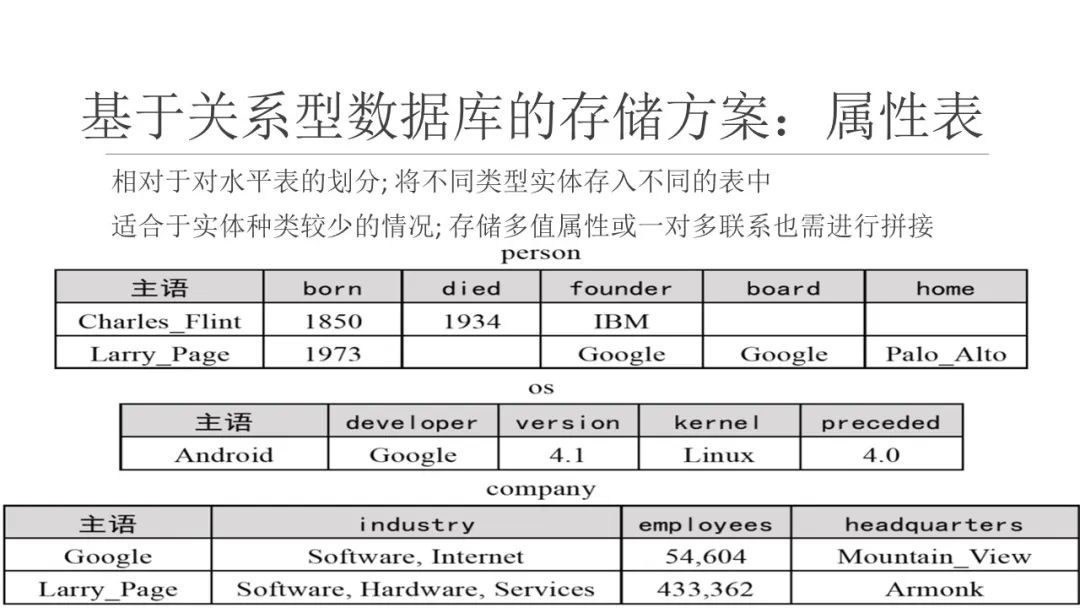
3、属性表
属性表(property table)存储方案是对水平表的细分,将同类主语存到一个表中,解决了表中列数目过多的问题。
- RDF 三元组库 Jena
- 属性表既克服了三元组表的自连接问题,又解决了水平表中列数目过多的问题。实际上,水平表就是属性表的一种极端情况,即水平表是将所有主语划归为一类,因此属性表中的空值问题得到很大的缓解。
- 属性表仍存 在如下一些缺点: - (1) 对于规模稍大的真实知识图谱数据,主语的类别可能有几千到上万个,需要建立几千到上万个表,这往往超过了关系数据库的限制- (2) 即使在同一类型中,不同主语具有的谓语集合也可能差异较大,会造成与水平表中类似的空值问题- (3) 水平表中存在的一对多联系或多值属性存储问题在属性表中仍然存在
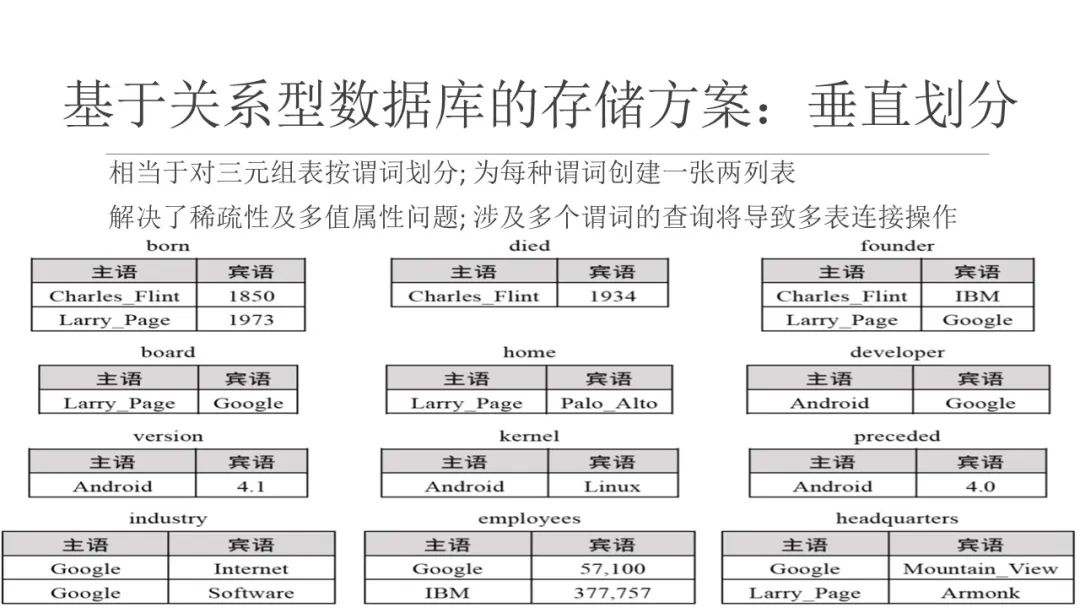
4、垂直划分
垂直划分(vertical partitioning)存储方案,为每种谓语建立一张两列的表(subject,object),表中存放知识图谱中由该谓语连接的主语和宾 语,表的总数量即知识图谱中不同谓语的数量.
- SW-Store
- 优点: - (1) 谓语表仅存储出现在 知识图谱中的三元组,解决了空值问题;- (2) 一个主语的一对多联系或多值属性存储在谓语表的多行中,解决了 多值问题;- (3) 每个谓语表都按主语列的值进行排序,能够使用归并排序连接(merge-sort join)快速执行不同谓 语表的连接查询操作.
- 缺点: - (1) 需要创建的表的数目与知识图谱中不同谓语数目相等,而大规模的真实知识图谱(如DBpedia、YAGO、WikiData 等)中谓语数目可能超过几千个,在关系数据库中维护如此规模的表需要花费很大开销- (2) 越是复杂的知识图谱查询操作,需要执行的表连接操作数量越多,而对于未指定谓语的三元组查询,将发生需要连接全部谓语表进行查询的极端情况- (3) 谓语表的数量越多,数据更新维护代价越大,对于一个主语的更新将涉及多张表,产生很高的更新时 I/O 开销。
5、六重索引
六重索引(sextuple indexing)存储方案是对三元组表的扩展,是一种典型的“空间换时间”策略,其将三元组全部6种排列对应地建立为6张表,即spo(主语,谓语,宾语)、pos(谓语,宾语,主语)、osp(宾语,主语,谓语)、sop(主语,宾语,谓语)、pso(谓语,主语,宾语)和ops(宾语,谓语,主语)。不难看出,其中 spo 表就是原来的三元组表。六重索引通过6张表的连接操作不仅缓解了三元组表的单表自连接问题,而且提高了某些典型知识图谱查询的效率。
- RDF-3X , Hexastore
- 优点: - (1) 知识图谱查询中的每种三元组模式查询都可以直接使用相应的索引进行快速 前缀范围查找;- (2) 可以通过不同索引表之间的连接操作 直接加速知识图谱上的连接查询.
- 缺点: - (1) 虽然部分缓解了三元组表的单表自连接问题,但需要花费 6 倍的存 储空间开销、索引维护代价和数据更新时的一致性维护代价,随着知识图谱规模的增大,该问题会愈加突出;- (2) 当知识图谱查询变得复杂时,会产生大量的连接索引表查询操作,依然不可避免索引表的自连接.
- DB2RDF 是一种面向实体的 RDF 知识图谱存储方案 - IBM DB2
四、原生知识图谱存储管理
原生知识图谱存储是指专门为知识图谱而设计的底层存储管理方案
目前主要的原生图数据库有Neo4j、gStore、JanusGraph、OrientDB和Cayley。
1、Neo4j
Neo4j是目前最流行的属性图数据库,其原生图存储层的最大特点是具有“无索引邻接(index-free adjacency)”特性。所谓“无索引邻接”是指,每个顶点维护着指向其邻接顶点的直接引用,相当于每个顶点都可看作是其邻接顶点的一个“局部索引”,用其查找邻接顶点比使用“全局索引”节省大量时间。这就意味着图导航操作代价与图大小无关,仅与图的遍历范围成正比
2、gStore
gStore 将 RDF 数据图中每个资源的所有属性和属性值映射到一个二进制位串上。具体而言,对于每个属性 或属性值,gStore 都定义一个固定长度的位串并将位串中所有位置为 0。然后利用若干个预先定义的字符串哈希函数将属性或属性值按照标识符映射到若干个小于位串长度的整数值,进而将位串上这些值所对应的位置置为1。
3、分布式图数据库:JanusGraph
JanusGraph是在原有Titan系统基础上继续开发的开源分布式图数据库。JanusGraph的存储后端与查询引擎是分离的, 可使用分布式Bigtable存储库Cassandra或HBase作为存储后端。JanusGraph借助第三方分布式索引库ElasticSearch、Solr和Lucene实现各类型数据的快速检索功能,包括地理信息数据、数值数据和全文搜索。JanusGraph还具备基于MapReduce的图分析引擎,,可将Gremlin导航查询转化为MapReduce任务。
4、OrientDB
OrientDB最初是由OrientDB公司开发的多模型数据库管理系统。OrientDB虽然支持图、文档、键值、对象、关系等多种数据模型, 但其底层实现主要面向图和文档数据存储管理的需求设计。其存储层中数据记录之间的联系并不是像关系数据库那样通过主外键的引用,而是通过记录之前直接的物理指针。OrientDB对于数据模式的支持相对灵活,可以管理无模式数据(schema-less),也可以像关系数据库那样定义完整的模式(schema-full),还可以适应介于两者之间的混合模式(schema-mixed)数据。在查询语言方面,OrientDB支持扩展的SQL和Gremlin用于图上的导航式查询;OrientDB的MATCH语句实现了声明式的模式匹配,这类似于Cypher语言查询模式。
5、Cayley
Cayley是由Google公司工程师开发的一款轻量级开源图数据库。Cayley的开发受到了Freebase知识图谱和Google知识图谱背后的图数据存储的影响。Cayley使用Go语言开发,可以作为Go类库使用;对外提供REST API,具有内置的查询编辑器和可视化界面;支持多种查询语言,包括:基于Gremlin的Gizmo、GraphQL和MQL;支持多种存储后端, 包括:键值数据库Bolt、LevelDB, NoSQL数据库MongoDB、CouchDB、PouchDB、ElasticSearch,关系数据库PostgreSQL、MySQL等。
6、其他原生图数据库
Amazon云平台的Amazon Neptune
多模型图数据库Arango DB
微软的Azure CosmosDB
DataStax的Enterprise Graph
Sparsity的Sparksee
TigerGraph
五、图数据库
1、图数据库排名
图数据库每月排名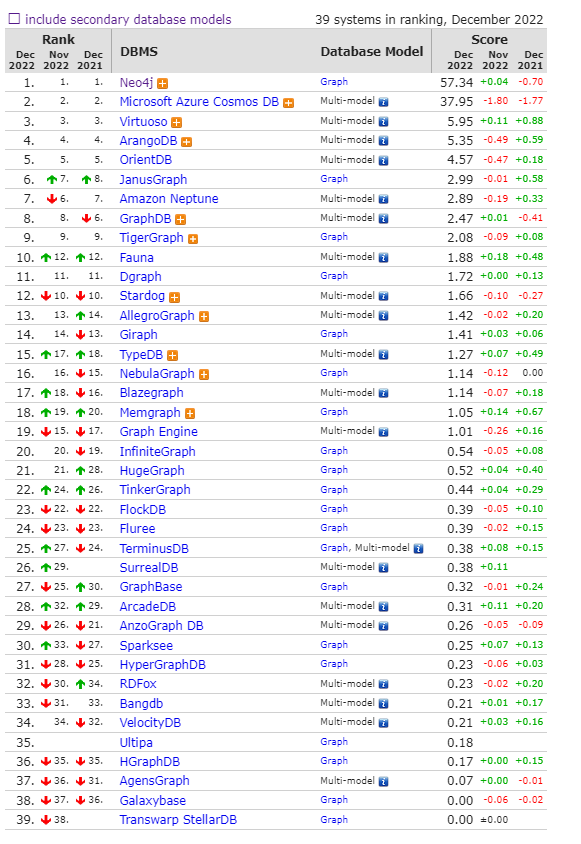
2、图数据库选型
在图数据库的选型上我们主要考虑了以下 5 点:
- (A) 项目开源,暂不考虑需付费的图数据库
- (B) 分布式架构设计,具备良好的可扩展性
- © 毫秒级的多跳查询延迟
- (D) 支持千亿量级点边存储
- (E) 具备批量从数仓导入数据的能力
针对主流图数据库,进行选型分析
DB-Engines Ranking of Graph DBMS 剔除不开源的项目,可分为:
- Neo4j、ArangoDB、Virtuoso、TigerGraph、RedisGraph。 此类图数据库只有单机版本开源可用,性能优秀,但不能应对分布式场景中数据的规模增长,即不满足选型要求(B)、(D)。
- JanusGraph、HugeGraph。 此类图数据库在现有存储系统之上新增了通用的图语义解释层,图语义层提供了图遍历的能力,但是受到存储层或者架构限制,不支持完整的计算下推,多跳遍历的性能较差,很难满足 OLTP(on-line transaction processing)场景下对低延时的要求,即不满足选型要求(C)。
- DGraph、NebulaGraph。 此类图数据库根据图数据的特点对数据存储模型、点边分布、执行引擎进行了全新设计,对图的多跳遍历进行了深度优化,基本满足我们的选型要求。
3、图数据库对比
(1) NebulaGraph vs. Dgraph vs. HugeGraph
NebulaGraph vs. Dgraph vs. HugeGraph的对比分析
部署方案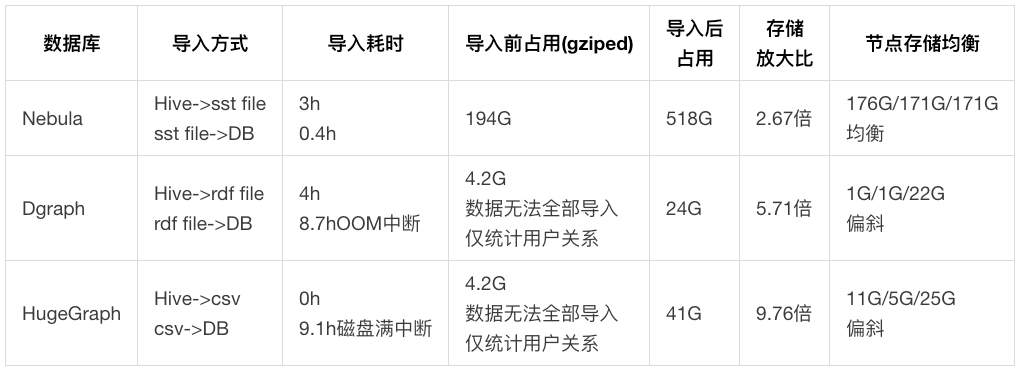
实时数据写入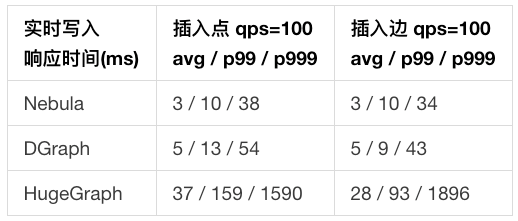
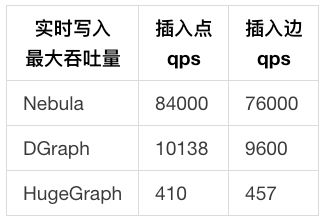
数据查询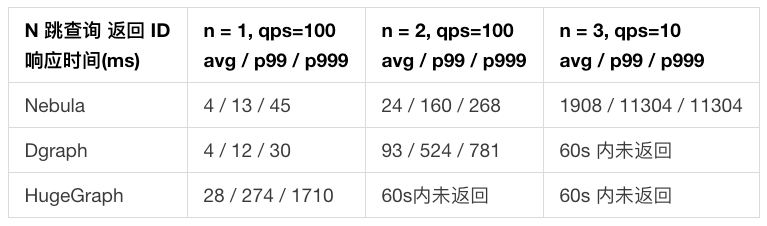
(2) Neo4j vs NebulaGraph vs JanusGraph
Neo4j vs NebulaGraph vs JanusGraph的对比分析
图形数据大小平台数据导入一跳查询两查询共享好友查询1000 万条边Neo4j26秒6.618秒6.644秒6.661秒HugeGraph89秒16毫秒22毫秒72毫秒NebulaGraph32.63秒1.482毫秒3.095毫秒0.994毫秒1 亿条边Neo4j1分21秒42.921秒43.332秒44.072秒HugeGraph10分19毫秒20毫秒5秒NebulaGraph3分52秒1.971毫秒4.34毫秒4.147毫秒10 亿条边Neo4j8分34秒165.397秒176.272秒168.256秒HugeGraph65分19毫秒651毫秒3.8秒NebulaGraph29分35秒2.035秒22.48毫秒1.761毫秒80 亿条边缘Neo4j1小时23分钟314.34秒393.18秒608.27秒HugeGraph16小时68毫秒24秒541毫秒NebulaGraph~30分钟小于 1s小于 5 秒小于 1s
(3) Dgraph vs. HugeGraph vs. JanusGraph vs. NebulaGraph vs. Neo4j
Dgraph vs. HugeGraph vs. JanusGraph vs. NebulaGraph vs. Neo4j的对比分析
(4) 主要知识图谱数据库对比
常见知识图谱数据库管理系统的比较
类型名称许可证数据模型/存储方案查询语言是否活跃基于关系3store开源RDF图/三元组表SPARQL否DLDB研究原型RDF图/水平表SPARQL早期系统, 水平表存储方案的代表性系统Jena开源RDF图/属性表SPARQL主流的语义Web工具库、RDF数据库和OWL推理工具SW-Store研究原型RDF图/垂直划分SPARQL科研原型系统, 垂直划分存储方案的代表性系统IBM DB2商业RDF图/DB2RDFSPARQL/ SQL支持RDF的主流商业数据库Oracle 18c商业RDF图/关系存储SPARQL/ PGQL支持RDF的主流商业数据库RDF三元组库RDF4J开源RDF图/SAIL APISPARQL是RDF-3X开源RDF图/六重索引SPARQL科研原型系统, 六重索引存储方案的代表性系统gStore开源研究原型RDF图/VS*树SPARQL科研原型系统, 原生图存储, 使用了基于位串图存储技术Virtuoso商业/开源RDF图/多模型混合SPARQL/ SQL语义Web项目常用的RDF数据库, 基于成熟的SQL引擎AllegroGraph商业RDF图/三元组索引SPARQL对语义推理功能具有较为完善的支持GraphDB商业RDF图/三元组索引SPARQL支持语义Web标准的主流产品, 支持SAIL层推理功能BlazeGraph商业RDF图/三元组索引SPARQL/ Gremlin基于RDF三元组库的图数据库, 实现了SPARQL和GremlinStarDog商业RDF图/三元组索引SPARQL对OWL2推理机制具有良好的支持原生图数据库Neo4j商业/开源属性图/原生图存储Cypher是JanusGraph开源属性图分布式存储Gremlin分布式图数据库, 存储后端与查询引擎分离, 实现了GremlinOrientDB商业属性图/原生图存储SQL/ Gremlin支持多模型的原生图数据管理系统, 对数据模式的灵活支持Cayley开源RDF图/外部存储Gremlin/ GraphQL轻量级开源图数据库, 易于扩展对新语言和存储后端的支持分布式系统与框架Sempala开源研究原型RDF图/分布式存储SPARQL否TriAD开源研究原型RDF图/分布式存储六重索引SPARQL基于MPI框架的异步通信协议H2RDF+开源研究原型RDF图/分布式存储六重索引SPARQL基于HBase构建六重索引S2RDF开源研究原型RDF图/分布式存储垂直划分SPARQL基于Spark框架建立大量索引Stylus开源研究原型RDF图/分布式存储属性表优化SPARQL基于分布式内存键值库的RDF三元组库Apache Rya开源RDF图/分布式存储三元组索引SPARQL基于列存储Accumulo的RDF三元组库Cypher for Apache Spark开源属性图/分布式存储DataFrameCypher基于Spark框架的Cypher引擎
4、单个性能强图数据库
(1) TuGraph
TuGraph由蚂蚁集团与清华大学联合研发,构建了一套包含图存储、图计算、图学习、图研发平台的完善的图技术体系,拥有业界领先规模的图集群,解决了图数据分析面临的大数据量、高吞吐率和低延迟等重大挑战,是蚂蚁集团金融风控能力的重要基础设施,显著提升了欺诈洗钱等金融风险的实时识别能力和审理分析效率,并面向金融、工业、政务服务等行业客户。
性能较强,大容量,但初步开源,问题较多,功能尚不完善。
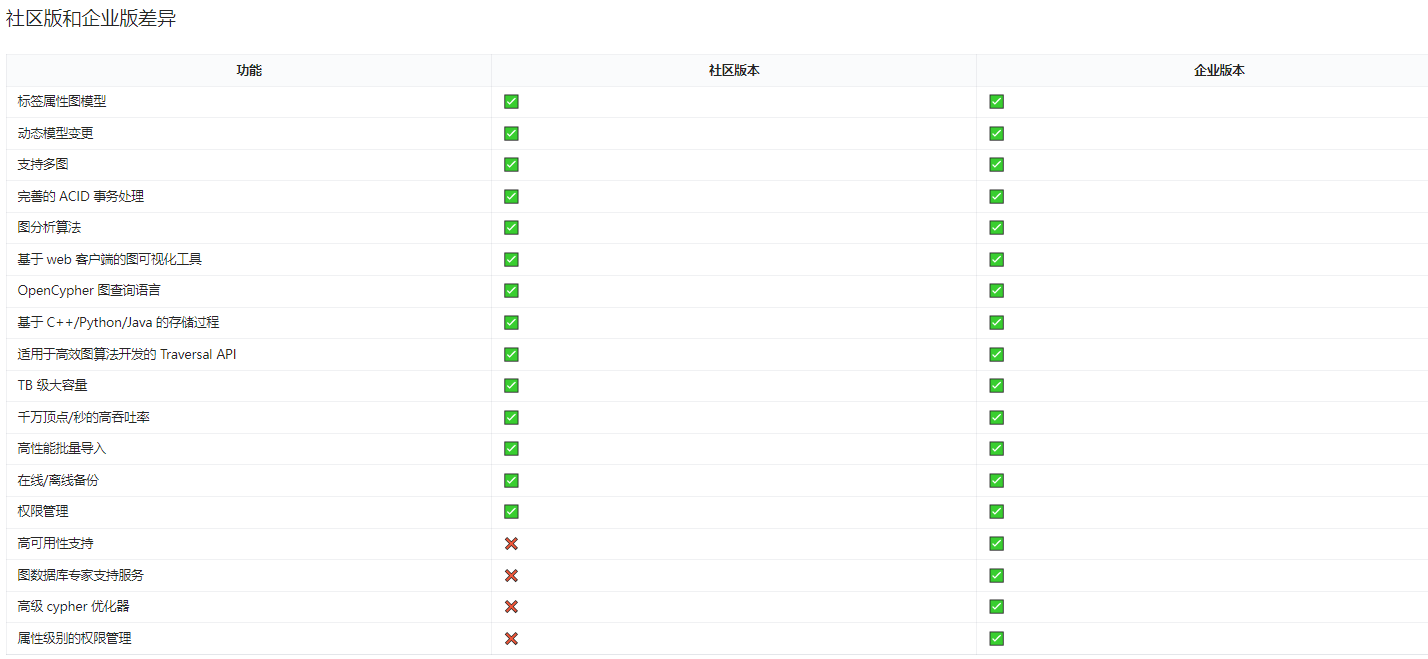
功能特诊性能和可扩展性标签属性图模型TB 级大容量支持多图千万顶点/秒的高吞吐率完善的 ACID 事务处理高可用性支持(企业版)内置 25+ 图分析算法高性能批量导入基于 web 客户端的图可视化工具在线/离线备份支持 RESTful API 和 RPCOpenCypher 图查询语言基于 C++/Python/Java 的存储过程适用于高效图算法开发的 Traversal API
(2) NebulaGraph
NebulaGraph是一个分布式,可扩展且闪电般的图形数据库。它是世界上能够托管具有数百亿个顶点(节点)和数万亿条边(关系)的图形的最佳解决方案,具有毫秒级延迟。
社区版与企业版的差异
整体上来说,社区版比企业版少一些可视化以及图算法
总结
随着知识图谱规模的日益增长,数据管理愈加重要。随着三元组库和图数据库的相互融合发展,知识图谱的存储和数据管理手段将愈加丰富和强大。本文主要讲述的是知识图谱存储技术、数据库的对比,进而能在进行知识存储中进行选择适合自己研发场景的数据库。
以上是我个人在学习过程中的记录所学,希望对正在一起学习的小伙伴有所帮助!!!
如果对你有帮助,希望你能一键三连【关注、点赞、收藏】!!!
参考链接
知识图谱的综述、构建、存储与应用
如何高效存储大规模知识图谱数据?基于机器学习的知识图谱存储结构—论文
知识图谱入门:知识图谱存储、融合、可视化、图表示计算与搜索常用工具总结
美团图数据库平台建设及业务实践 - 美团技术团队 (meituan.com)
(8条消息) Neo4j 和 Nebula Graph 和 HugeGraph对比选型_会发paper的学渣的博客-CSDN博客_nebula neo4j
企业版报价 NebulaGraph Database (nebula-graph.com.cn)
版权归原作者 故事挺秃然 所有, 如有侵权,请联系我们删除。