
01、树形结构数据
前端开发中会经常用到树形结构数据,如多级菜单、商品的多级分类等。数据库的设计和存储都是扁平结构,就会用到各种Tree树结构的转换操作,本文就尝试全面总结一下。
如下示例数据,关键字段
id
为唯一标识,
pid
为
父级id
,用来标识父级节点,实现任意多级树形结构。
"pid": 0
“0”标识为根节点,
orderNum
属性用于控制排序。
const data = [
{ "id": 1, "name": "用户中心", "orderNum": 1, "pid": 0 },
{ "id": 2, "name": "订单中心", "orderNum": 2, "pid": 0 },
{ "id": 3, "name": "系统管理", "orderNum": 3, "pid": 0 },
{ "id": 12, "name": "所有订单", "orderNum": 1, "pid": 2 },
{ "id": 14, "name": "待发货", "orderNum": 1.2, "pid": 2 },
{ "id": 15, "name": "订单导出", "orderNum": 2, "pid": 2 },
{ "id": 18, "name": "菜单设置", "orderNum": 1, "pid": 3 },
{ "id": 19, "name": "权限管理", "orderNum": 2, "pid": 3 },
{ "id": 21, "name": "系统权限", "orderNum": 1, "pid": 19 },
{ "id": 22, "name": "角色设置", "orderNum": 2, "pid": 19 },
];
在前端使用的时候,如树形菜单、树形列表、树形表格、下拉树形选择器等,需要把数据转换为树形结构数据,转换后的数据结效果图:

预期的树形数据结构:多了
children
数组存放子节点数据。
[
{ "id": 1, "name": "用户中心", "pid": 0 },
{
"id": 2, "name": "订单中心", "pid": 0,
"children": [
{ "id": 12, "name": "所有订单", "pid": 2 },
{ "id": 14, "name": "待发货", "pid": 2 },
{ "id": 15, "name": "订单导出","pid": 2 }
]
},
{
"id": 3, "name": "系统管理", "pid": 0,
"children": [
{ "id": 18, "name": "菜单设置", "pid": 3 },
{
"id": 19, "name": "权限管理", "pid": 3,
"children": [
{ "id": 21, "name": "系统权限", "pid": 19 },
{ "id": 22, "name": "角色设置", "pid": 19 }
]
}
]
}
]
02、列表转树-list2Tree
常用的算法有2种:
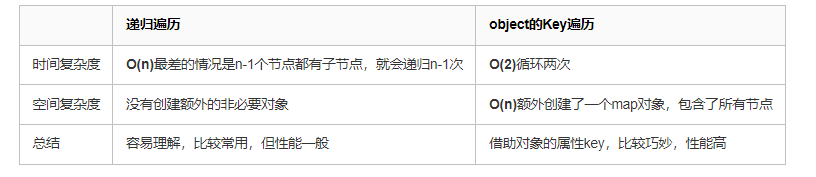
🟢递归遍历子节点:先找出根节点,然后从根节点开始递归遍历寻找下级节点,构造出一颗树,这是比较常用也比较简单的方法,缺点是数据太多递归耗时多,效率不高。还有一个隐患就是如果数据量太,递归嵌套太多会造成JS调用栈溢出,参考《JavaScript函数(2)原理{深入}执行上下文》。
🟢2次循环Object的Key值:利用数据对象的
id作为对象的key创建一个map对象,放置所有数据。通过对象的key快速获取数据,实现快速查找,再来一次循环遍历获取根节点、设置父节点,就搞定了,效率更高。
🟢递归遍历
从根节点递归,查找每个节点的子节点,直到叶子节点(没有子节点)。
//递归函数,pid默认0为根节点
function buildTree(items, pid = 0) {
//查找pid子节点
let pitems = items.filter(s => s.pid === pid)
if (!pitems || pitems.length <= 0)
return null
//递归
pitems.forEach(item => {
const res = buildTree(items, item.id)
if (res && res.length > 0)
item.children = res
})
return pitems
}
🟢object的Key遍历
简单理解就是一次性循环遍历查找所有节点的父节点,两个循环就搞定了。
- 第一次循环,把所有数据放入一个Object对象map中,id作为属性key,这样就可以快速查找指定节点了。
- 第二个循环获取根节点、设置父节点。
分开两个循环的原因是无法完全保障父节点数据一定在前面,若循环先遇到子节点,map中还没有父节点的,否则一个循环也是可以的。
/**
* 集合数据转换为树形结构。option.parent支持函数,示例:(n) => n.meta.parentName
* @param {Array} list 集合数据
* @param {Object} option 对象键配置,默认值{ key: 'id', parent: 'pid', children: 'children' }
* @returns 树形结构数据tree
*/
export function list2Tree(list, option = { key: 'id', parent: 'pid', children: 'children' }) {
let tree = []
// 获取父编码统一为函数
let pvalue = typeof (option.parent) === 'function' ? option.parent : (n) => n[option.parent]
// map存放所有对象
let map = {}
list.forEach(item => {
map[item[option.key]] = item
})
//遍历设置根节点、父级节点
list.forEach(item => {
if (!pvalue(item))
tree.push(item)
else {
map[pvalue(item)][option.children] ??= []
map[pvalue(item)][option.children].push(item)
}
})
return tree
}
- 参数
option为数据结构的配置,就可以兼容各种命名的数据结构了。 option中的parent支持函数,兼容一些复杂的数据结构,如parent: (n) => n.meta.parentName,父节点属性存在一个复合对象内部。
测试一下:
data.sort((a, b) => a.orderNum - b.orderNum)
const sdata = list2Tree(data)
console.log(sdata)
对比一下
延伸一下:Map和Object哪个更快?
在上面的方案2(object的Key遍历)中使用的是Object,其实也是可以用ES6新增的Map对象。Object、Map都可用作键值查找,速度都还是比较快的,他们内部使用了哈希表(hash table)、红黑树等算法,不过不同引擎可能实现不同。
let obj = {};
obj['key1'] = 'objk1'
console.log(obj.key1)
let map = new Map()
map.set('key1','map1')
console.log(map.get('key1'))
大多数情况下Map的键值操作是要比Object更高效的,比如频繁的插入、删除操作,大量的数据集。相对而言,数据量不多,插入、删除比较少的场景也是可以用Object的。
03、树转列表-tree2List
树形数据结构转列表,这就简单了,广度优先,先横向再纵向,从上而下依次遍历,把所有节点都放入一个数组中即可。
/**
* 树形转平铺list(广度优先,先横向再纵向)
* @param {*} tree 一颗大树
* @param {*} option 对象键配置,默认值{ children: 'children' }
* @returns 平铺的列表
*/
export function tree2List(tree, option = { children: 'children' }) {
const list = []
const queue = [...tree]
while (queue.length) {
const item = queue.shift()
if (item[option.children]?.length > 0)
queue.push(...item[option.children])
list.push(item)
}
return list
}
04、设置节点不可用-setTreeDisable
递归设置树形结构中数据的
disabled
属性值为不可用。使用场景:在修改节点所属父级时,不可选择自己及后代。
基本思路:
- 先重置
disabled属性,递归树所有节点,这一步可根据实际情况优化下。 - 设置目标节点及其子节点的
disabled属性。
/**
* 递归设置树形结构中数据的 disabled 属性值为不可用。使用场景:在修改父级时,不可选择自己及后代
* @param {*} tree 一颗大树
* @param {*} disabledNode 需要禁用的节点,就是当前节点
* @param {*} option 对象键配置,默认值{ children: 'children', disabled: 'disabled' }
* @returns void
*/
export function setTreeDisable(tree, disabledNode, option = { children: 'children', disabled: 'disabled' }) {
if (!tree || tree.length <= 0)
return tree
// 递归更新disabled值
const update = function(tree, value) {
if (!tree || tree.length <= 0)
return
tree.forEach(item => {
item[option.disabled] = value
update(item[option.children], value)
})
}
// 开始干活,先重置
update(tree, false)
if (!disabledNode) return tree
// 设置所有子节点disable = true
disabledNode[option.disabled] = true
update(disabledNode[option.children], true)
return tree
}
05、搜索过滤树-filterTree
搜索树中符合条件的节点,但要包含其所有上级节点(父节点可能并没有命中),便于友好展示。当树形结构的数据量大、结构深时,搜索功能就很有必要了。
基本思路:
- 为避免污染原有Tree数据,这里的对象都使用了简单的浅拷贝
const newNode = { ...node }。 - 递归为主的思路,子节点有命中,则会包含父节点,当然父节点的
children会被重置。
/**
* 递归搜索树,返回新的树形结构数据,只要子节点命中保留其所有上级节点
* @param {Array|Tree} tree 一颗大树
* @param {Function} func 过滤函数,参数为节点对象
* @param {Object} option 对象键配置,默认值{ children: 'children' }
* @returns 过滤后的新 newTree
*/
export function filterTree(tree, func, option = { children: 'children' }) {
let resTree = []
if (!tree || tree?.length <= 0) return null
tree.forEach(node => {
if (func(node)) {
// 当前节点命中
const newNode = { ...node }
if (node[option.children])
newNode[option.children] = null //清空子节点,后面递归查询赋值
const cnodes = filterTree(node[option.children], func, option)
if (cnodes && cnodes.length > 0)
newNode[option.children] = cnodes
resTree.push(newNode)
}
else {
// 如果子节点有命中,则包含当前节点
const fnode = filterTree(node[option.children], func, option)
if (fnode && fnode.length > 0) {
const newNode = { ...node, [option.children]: null }
newNode[option.children] = fnode
resTree.push(newNode)
}
}
})
return resTree
}
文章转载自:安木夕
原文链接:https://www.cnblogs.com/anding/p/17625911.html
体验地址:引迈 - JNPF快速开发平台_低代码开发平台_零代码开发平台_流程设计器_表单引擎_工作流引擎_软件架构
版权归原作者 快乐非自愿 所有, 如有侵权,请联系我们删除。