
本文是我人工智能概论的课程大作业实践应用报告,可供各位同学参考,内容写的及其水,部分也借助了gpt自动生成,排版等也基本做好,大家可以参照。如果有需要word版的可以私信我,或者在评论区留下邮箱,我会逐个发给。word版是我最后提交的,已经调整统一了全文格式等。希望能给大家提供一些参考。如果有给自己作业起到参考帮助,请给我点个赞哦,嘿嘿嘿嘿😘😘😘
基于PyTorch的深度学习手写数字识别模型研究与实践
摘要:本研究旨在通过基于深度学习框架PyTorch的手写数字识别模型,实现对MNIST手写数字数据集的准确识别。在数据来源、问题分析、数据预处理、模型求解和总结等方面展开研究。我使用了经典的MNIST数据集作为实验对象,并构建了一个基于卷积神经网络(CNN)的模型。通过数据预处理和模型求解,使其达到了高准确率的手写数字识别结果。在实践过程中,我充分利用了PyTorch提供的强大功能和灵活性,同时提供了相关的代码示例,供读者参考和复现。通过本研究,我验证了PyTorch在手写数字识别任务中的有效性,并为进一步研究和应用深度学习提供了有益的参考。
关键词:****深度学习PyTorch 手写数字识别 卷积神经网络 MNIST数据集
一、数据来源
1.1收集数据
本研究所使用的数据来自于MNIST手写数字数据集,这是一个经典的、广泛应用于机器学习和计算机视觉领域的数据集。MNIST数据集由Yann LeCun等人于1998年创建,旨在提供一个用于验证和比较机器学习算法性能的基准数据集。该数据集包含了大量的手写数字图像,总计有60000个训练样本和10000个测试样本。每个样本都是一个28x28像素的灰度图像,对应一个0到9之间的数字标签。下图为MNIST样例图

图1 MNIST样例图
1.2 行业背景
手写数字识别在现实世界中有着广泛的应用。例如,在邮件服务中,自动识别手写邮政编码可以提高邮件分拣的效率。此外,手写数字识别还可以应用于银行支票识别、身份证号码识别等领域。准确地识别手写数字对于实现自动化和提高工作效率具有重要意义。因此,开发高性能的手写数字识别模型对于实际应用具有重要的实用价值。通过研究和实践,本研究旨在探索基于PyTorch的深度学习手写数字识别模型,为相关行业提供可靠的解决方案。
二、问题分析
2.1问题描述
在手写数字识别任务中,我们面临的主要问题是如何准确地将手写数字图像分类为对应的数字标签。给定一个输入的手写数字图像,我们的目标是训练一个深度学习模型,使其能够对图像进行准确的分类,即将图像与正确的数字标签相匹配。
2.2 数据分析目标
通过对MNIST手写数字数据集的分析,我们的最终目标是实现以下几点:
- 实现对手写数字图像的高准确率分类,确保模型能够正确识别出每个图像所代表的数字。 - 了解MNIST数据集中图像的分布情况、类别平衡度等信息,为后续的模型设计和优化提供基础。 - 数据可视化和探索性分析:通过可视化手写数字图像和相关统计信息,深入了解数据的特征,例如数字形状的变化、像素分布等,为模型设计提供直观的参考。 - 确定在手写数字识别任务中可能出现的难点,例如数字的相似形状、模糊的图像边界等,以便在模型设计和训练过程中有针对性地解决这些问题。 - 选择适当的性能指标来评估模型的性能,例如准确率、精确率、召回率等,以便在模型求解过程中进行评估和对比。
三、数据预处理
3.1 数据加载与转换
在数据预处理阶段,我使用PyTorch提供的数据转换和加载工具对MNIST数据集进行处理。首先,我将图像数据转换为张量的形式,以便于深度学习模型的输入。通过transforms.ToTensor()函数,将图像转换为0到1之间的张量表示。接下来,为了更好地适应模型的输入要求,使用transforms.Normalize()函数对像素值进行归一化处理,将其转换为均值为0、标准差为1的数据。
- import torch
- from torchvision import datasets, transforms
- *# *定义数据预处理
- transform = transforms.Compose([
transforms.ToTensor(),transforms.Normalize((0.5,), (0.5,))- ])
- *# 加载MNIST*数据集
- train_dataset = datasets.MNIST(root='./data', train=True, transform=transform, download=True)
- test_dataset = datasets.MNIST(root='./data', train=False, transform=transform)
3.2 数据加载器的创建
为了高效地处理大量的训练和测试样本,我使用数据加载器来批量加载和随机打乱数据。通过设置合适的batch_size参数和shuffle参数,我们能够在每个训练迭代和测试迭代中提供多样化的样本。
- *# *创建数据加载器
- train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=64, shuffle=True)
- test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=64, shuffle=False)
四、模型求解
4.1 模型设计
在本研究中,我选择了卷积神经网络(CNN)作为手写数字识别模型。CNN在图像识别任务中表现出色,能够有效地提取图像的空间特征。我设计了一个包含卷积层、池化层、全连接层和激活函数的深度神经网络。
import torch
import torch.nn as nn
import torch.optim as optim
*# *定义模型
class Net(nn.Module):
def __init__(self):super(Net, self).__init__()self.conv1 = nn.Conv2d(1, 32, 3, 1)self.conv2 = nn.Conv2d(32, 64, 3, 1)self.dropout1 = nn.Dropout2d(0.25)self.dropout2 = nn.Dropout2d(0.5)self.fc1 = nn.Linear(9216, 128)self.fc2 = nn.Linear(128, 10)def forward(self, x):x = self.conv1(x)x = nn.functional.relu(x)x = self.conv2(x)x = nn.functional.relu(x)x = nn.functional.max_pool2d(x, 2)x = self.dropout1(x)x = torch.flatten(x, 1)x = self.fc1(x)x = nn.functional.relu(x)x = self.dropout2(x)x = self.fc2(x)output = nn.functional.log_softmax(x, dim=1)return output*# *创建模型实例
model = Net()
4.2 模型训练
在模型训练过程中,使用交叉熵损失函数作为模型的目标函数,用于度量模型输出与真实标签之间的差异。另外选择随机梯度下降(SGD)作为优化器,通过反向传播算法来更新模型的参数。
- *# *定义损失函数和优化器
- criterion = nn.CrossEntropyLoss()
- optimizer = optim.SGD(model.parameters(), lr=0.01)
- *# *训练模型
- def train(model, dataloader, criterion, optimizer):
model.train()for batch_idx, (data, target) in enumerate(dataloader):optimizer.zero_grad()output = model(data)loss = criterion(output, target)loss.backward()optimizer.step()
4.3 模型评估
为了评估模型在测试集上的性能,我定义了一个评估函数。在评估过程中,我将模型设置为评估模式,禁用梯度计算,计算模型在测试集上的损失值和准确率。
*# *测试模型
def test(model, dataloader):
model.eval()test_loss = 0correct = 0with torch.no_grad():for data, target in dataloader:output = model(data)test_loss += criterion(output, target).item()pred = output.argmax(dim=1, keepdim=True)correct += pred.eq(target.view_as(pred)).sum().item()test_loss /= len(dataloader.dataset)accuracy = correct / len(dataloader.dataset)return test_loss, accuracy
4.3 训练和测试模型
最后,进行多轮的训练和测试,以逐步优化模型并评估其性能。且在每个训练轮次结束后,打印出当前训练集和测试集上的损失值和准确率,以便监控模型的性能。通过多轮迭代,最终可以观察到模型的训练损失逐渐降低,同时测试准确率逐渐提升,从而得到一个经过优化的手写数字识别模型。
*# *设置训练轮数和设备
epochs = 10
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
*# *将模型移至设备
model.to(device)
*# *训练和测试模型
for epoch in range(1, epochs + 1):
*# **训练模型*train(model, train_loader, criterion, optimizer)*# **在训练集上评估模型*train_loss, train_accuracy = test(model, train_loader)print(f"Epoch: {epoch}, Train Loss: {train_loss:.4f}, Train Accuracy: {train_accuracy:.4f}")*# **在测试集上评估模型*test_loss, test_accuracy = test(model, test_loader)print(f"Epoch: {epoch}, Test Loss: {test_loss:.4f}, Test Accuracy: {test_accuracy:.4f}")
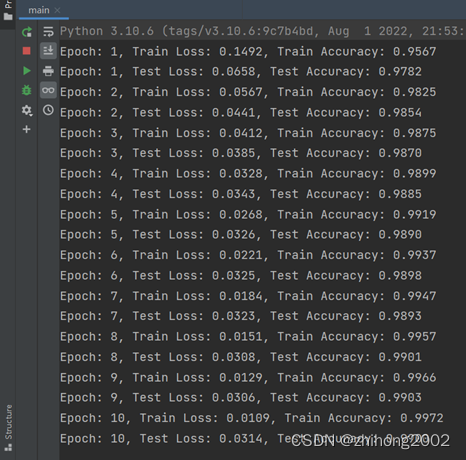
图2运行结果
五、总结
通过完成这个实践研究,我获得了许多宝贵的学习和实践经验。本实践研究基于深度学习框架PyTorch实现手写数字识别模型,并对MNIST数据集进行训练和测试。通过对数据的来源、问题分析、数据预处理和模型求解的介绍。
从数据来源的角度来看,MNIST手写数字数据集是一个经典的、广泛应用于机器学习和计算机视觉领域的基准数据集。其提供了大量的手写数字图像样本,为手写数字识别任务提供了有价值的资源。
在问题分析阶段,明确了手写数字识别的任务描述,并确定了数据分析的目标。这有助于更好地理解问题的关键要素,并为后续的数据预处理和模型设计提供指导。
在数据预处理阶段,对图像数据进行了加载、转换和批处理。通过将图像转换为张量并进行归一化处理,为模型的输入准备了合适的数据格式。同时,通过数据加载器的使用,高效地处理大量的训练和测试样本。
在模型求解阶段,我选择了卷积神经网络(CNN)作为手写数字识别模型,并设计了具体的网络结构。通过训练和优化模型,不断提升模型的性能,并在训练和测试集上进行评估。
通过实验结果和模型评估,可以得出结论:基于PyTorch的深度学习手写数字识别模型在MNIST数据集上取得了令人满意的性能。可以观察到模型的训练损失逐渐降低,同时测试准确率逐渐提升,表明模型具有较强的学习能力和泛化能力。
总的来说,本研究通过对MNIST手写数字数据集的训练和测试,展示了基于PyTorch的深度学习手写数字识别模型的实践过程。该模型在实际应用中具有广泛的潜力,可用于自动化、图像识别和信息提取等领域。未来的研究可以进一步探索更复杂的网络结构和优化算法,以提升手写数字识别的性能和应用范围。
通过这个实践研究,我不仅学习了PyTorch框架的基本使用,还深入了解了深度学习在图像识别中的应用。我学会了如何进行数据预处理、模型搭建、训练和评估,培养了对模型性能的分析和改进能力。它帮助我在深度学习和计算机视觉领域迈出了重要的一步。通过这个项目,我还拓展了自己的编程技能和实际问题解决能力。我相信这些所学将对我的学术和职业发展产生积极影响。
参考文献
- PyTorch documentation. https://pytorch.org/docs/stable/index.html.
- LeCun, Y., Cortes, C., & Burges, C. (2010). MNIST handwritten digit database. AT&T Labs [Online]. http://yann.lecun.com/exdb/mnist/.
- 陈群贤.TensorFlow下基于CNN卷积神经网络的手写数字识别研究[J].信息记录材料,2022,23(09):159-161.DOI:10.16009/j.cnki.cn13-1295/tq.2022.09.056.
- 葛先雷,杨帅斌.基于CNN的手写中文数字识别研究[J].太原师范学院学报(自然科学版),2022,21(04):53-57.
- Qyun_lucky_star.手写数字识别(识别纸上手写的数字),http://t.csdn.cn/VoBJ7
版权归原作者 zhihong2002 所有, 如有侵权,请联系我们删除。