
一、StableDiffusion是什么
Stable Diffusion是一种基于潜在空间扩散(latent diffusion)的模型。它并非直接在高维图像空间中操作,而是首先将图像压缩到潜空间(latent space)中,然后在潜空间中应用扩散过程来生成新的图像。
Stable Diffusion能够从文本描述中生成详细的图像,并可用于图像修复、图像绘制、文本到图像和图像到图像等多种任务。简而言之,只需提供所需的图片的文字描述,Stable Diffusion就能生成符合要求的逼真图像。
Stable Diffusion将“图像生成”过程转换为逐渐去除噪声的“扩散”过程。整个过程从随机高斯噪声开始,经过训练逐步去除噪声,直到不再有噪声,最终输出更贴近文本描述的图像。
二、准备StableDiffusion
要想使用该软件,那肯定安装要准备GPU相关了。
(1)自己电脑安装软件:如果你硬件条件充裕,可以直接搜索其他页面怎么安装StableDiffusion即可,这里不过多描述。(其实本人也不太会装)
(2)租赁GPU算力:如果你硬件条件不充裕,可以考虑GPU算力租赁,也不贵。本博主就是太穷买不起高端显卡,自己电脑自带显卡太拉跨,就考虑GPU算力租赁。本人一开始是在腾X云租GPU服务器,要6块钱一个小时,还要自己经历复杂的安装及配置,后面生图速度也不尽人意,于是就放弃。后面找到一个比较划算的,2块一小时,有兴趣的话看后续第五章内容。
三、StableDiffusion页面功能介绍
下面以文生图页面来介绍
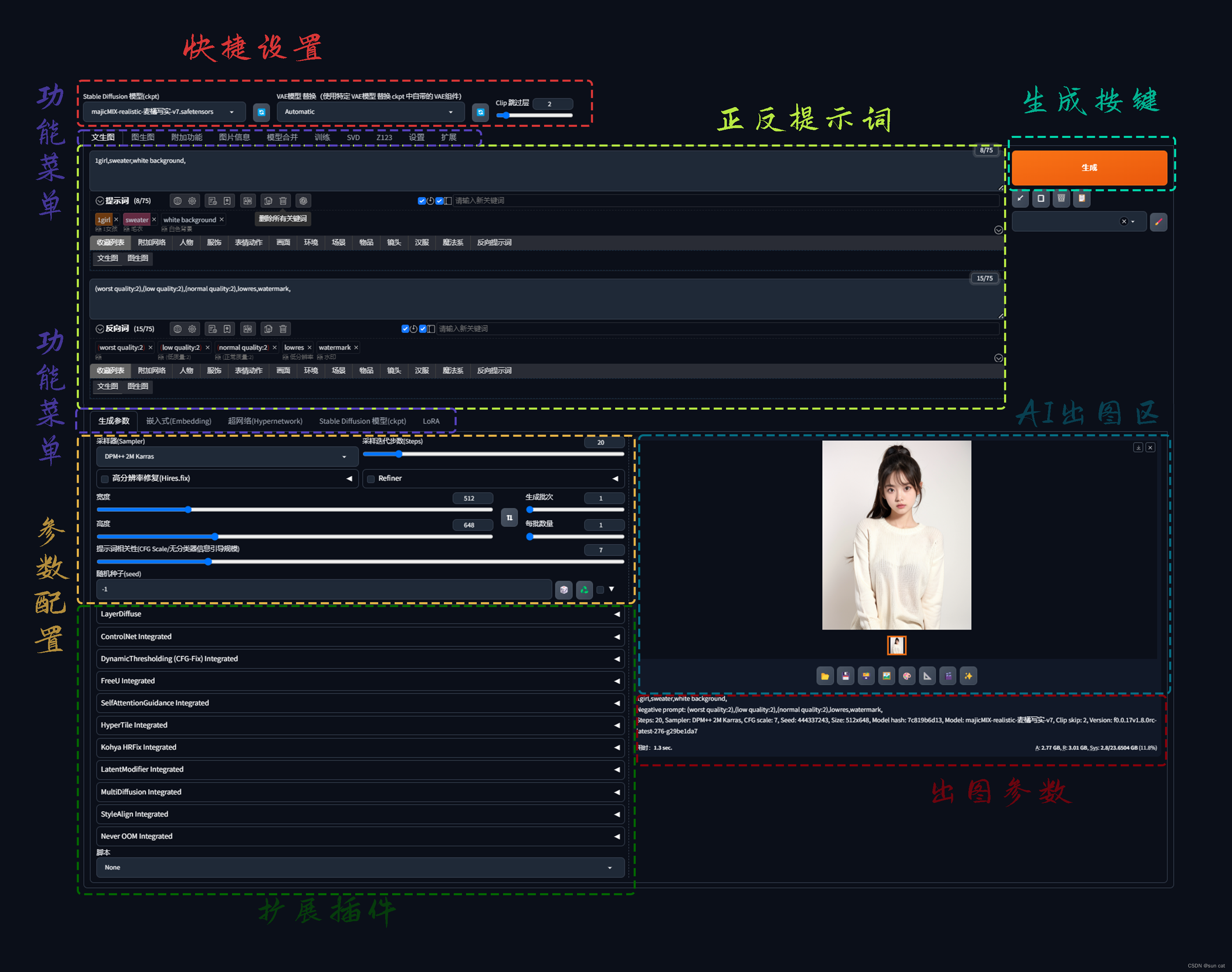
1、快捷设置
(1)StableDiffusion模型(ckpt):
大模型,经过训练学习后得到的程序文件。
模型常见下载地址:
1)civitai.com
2)liblib.art
3)huggingface.co
(2)VAE模型:
VAE(变分自编码器,Variational Autoencoder)是一种基于深度学习的生成模型,它起到增强图像质量和细节的关键作用,主要作用于滤镜和微调。
(3)Clip跳过层:
是通过一个神经网络系统,将提示词从文字转化成简单的数字。将这些数字放入到神经网络的第一层进行计算,把得到的运算结果再放到第二层进行计算,然后再放到第三层进行计算……层层处理,层层递进,一直到最后一层。
默认值为2,即在通过神经网络的运算层的时候跳过两层运算,提前结束运算。
数值越低,越能理解提示词,越接近你的描述。数值越高,越容易忽略提示词,AI会更多自主创新
2、功能菜单
(1)文生图:顾名思义就是通过一些文字描述生成一些AI图片
(2)图生图:顾名思义就是你提供图片,再进行一些修改/转绘
(3)Lora模型:固定目标的特征形象的一个模型
(4)设置:设置一些配置的地方
(5)扩展:扩展StableDiffusion插件的地方,在这里可以找到你需要的插件并进行安装使用。如本人常用的人脸修复插件
3、正反提示词
(1)正向提示词(Prompts):主要描述你想要什么样的内容,比如 a girl 。建议使用英文
(2)反向提示词(Negative Prompts):描述你不想要什么,比如low quality。也同样建议使用英文
4、参数配置:
(1)采样迭代步数(Steps):图像扩散的步数,也可以理解为AI绘画的笔数。
(2)采样器(Smapler):提供不同的算法来去大模型中采取数据样本。不同算法采样的结果会有所不同。
(3)宽度:单位是像素,AI出图时的宽度。
(4)高度:单位是像素,AI出图时的高度。
(5)生成批次:AI要跑几批图片
(6)每批数量:每批要出几张图(建议不动,吃显卡)
(7)提示词相关新(CFG):影响输入提示词的权重
(8)随机种子:图片生成的种子数据。默认值是-1,即随机抽取种子数据生成图片。种子对于图像生成至关重要,简而言之如果遇上了“对眼”的图片请立刻锁定种子,通过增加步数、调整关键词等深化图像。同时也可以去图片信息中调用你之前生成的图片种子。
(9)高分辨率修复:
针对你的生成的图片的图片进行修复,扩大像素及抗锯齿性等。
可能有人问,为什么不直接调整AI出图宽度和高度?这样不是更快吗?不同的,调整AI出图的宽度和高度,会让AI有不同的空间绘画出不同的内容。就比如你之前是600*800,像素点有限,AI绘画出来的结果就可能只是一个女孩,这正好符合你的要求。但假如你调整为1200*1600,像素变大了,AI绘画出来的空间更大,可能就不止一个女孩子了,这时可能就不太符合你的要求了。
5、生成按键:
配置好相应的内容后点击"生成"按键,会绘画出对应的AI图
6、扩展插件:
安装插件后,大部分插件功能都会扩展在此处操作
7、AI出图区:
StableDiffusion生成图片的区域,此区域也可以点击下载
8、出图参数:
AI绘完图后,点击对应的图,会出现改图所有的参数,比如种子数据等
四、简单样例--生成清纯AI美女图
1、下载对应模型
这里我们通过liblib.art网站中找到麦橘写实模型

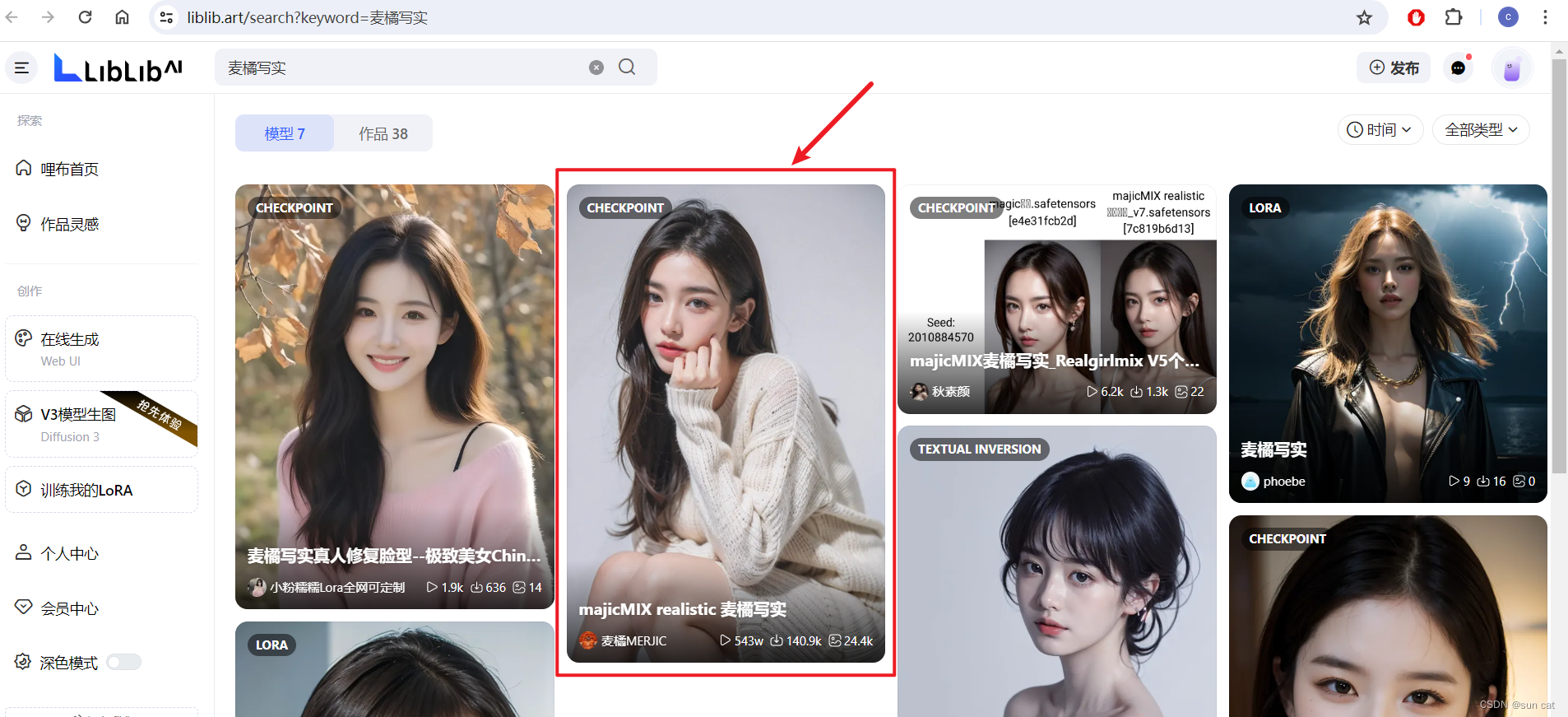

下载对应模型,并将其放置在该文件夹下
StableDiffusion安装目录/models/Stable-diffusion/
2、刷新并选择模型


3、输入正反向提示词
正向提示词:比如我想要一个女孩、白色背景、穿着毛衣
1girl,sweater,white background,
反向提示词:
比如我不想要低质量、水印这些,可以输入
(worst quality:2),(low quality:2),(normal quality:2),lowres,watermark,

4、配置参数
根据需要配置宽高或者迭代步数之类的
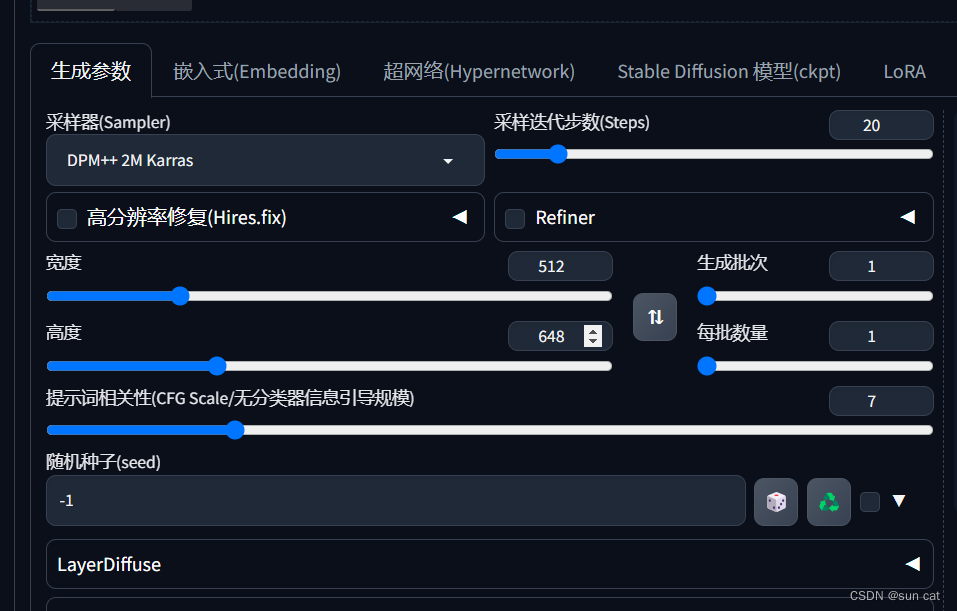
5、生成图片


五、额外--GPU算力租赁
为了避嫌对应图片我会打码(我没收它们广告费,也不想过多曝光它们。只是我自己觉得好用,推荐给一些读者能更快上手)
1、打开仙X云网址,注册用户
2、创建StableDiffusion容器软件.


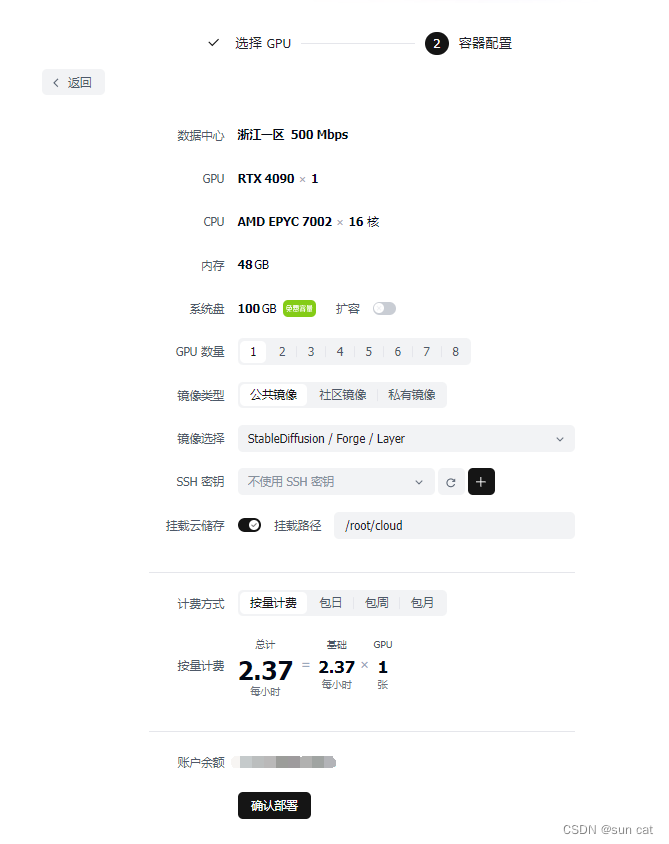
3、打开WebUI页面使用

版权归原作者 sun cat 所有, 如有侵权,请联系我们删除。