
阅读原文
NL2SQL在大型语言模型(LLM)的支持下得到了广泛应用,为了对基于LLM的NL2SQL解决方案进行系统化研究,我们需要全面理解和实践,包括Prompt工程、指令微调(SFT)、Agent、RAG等技术方案。为深入研究NL2SQL提供一些参考和指导。
1. 什么是NL2SQL
简言之,Natural Language to SQL (NL2SQL) 是指将用户的自然语句转为可以执行的 SQL 语句。
2. 基于LLM的NL2SQL现状
Spider和BIRD是比较受欢迎的两个NL2SQL的benchmark。Spider包含了1万多个自然语言的问题和相关的SQL语句,以及用来运行这些SQL的200多个数据库,横跨了100多个应用领域;BIRD相对于Spider更专注于学术研究,BIRD则更加考虑了真实应用中的数据库中信息的复杂性,且考虑了模型生成的SQL运行效率。BIRD也包含了约12000多个自然语言与SQL,涵盖了约37个专业领域的90多个数据库。
可以看到在Spider和BIRD上,GPT是远比开源模型效果要好的;在Spider榜单上,开源模型没有超过80分的,且在BIRD榜单上GPT也都没有超过60分。因此实现一个NL2SQL的模型简单,但是在实际应用时它的表现却没有想象的那样好,当前AI模型输出SQL的准确性还远无法达到人类工程师的输出精度。

3. 难点简析
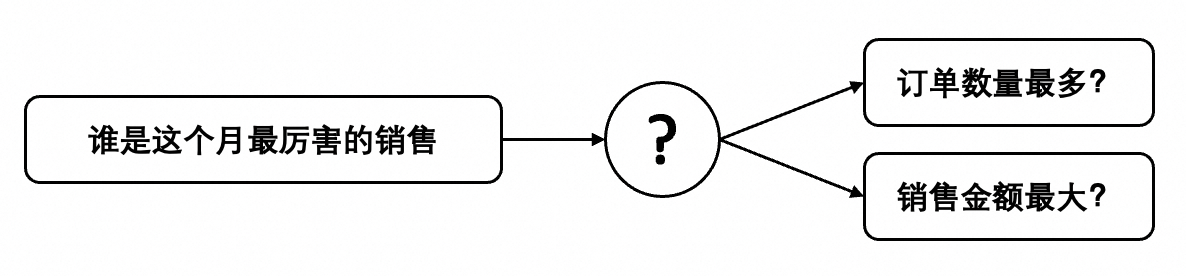
应用难:真实企业应用数据库的结构更复杂、分析逻辑更复杂、准确性和相应性能要求高。深度学习的AI模型预测本身就有置信度的问题,无法确保绝对可靠性,这一点在大语言模型依然存在,尤其是在NL2SQL任务上,自然语言表达本身具有歧义性,而SQL是一种精确编程语言。因此在实际应用中,可能会出现无法理解,或者错误理解的情况。比如,“谁是这个月最厉害的销售”,那么AI是理解成订单数量最多,还是订单金额最大呢?输出的不确定性也是目前限制大模型在关键企业系统应用最大的障碍。
测评难:评估NL2SQL模型输出正确性很困难,既不能用SQL的执行结果来判断,也不能直接用SQL语句进行对比来判断。
- 用SQL执行结果来判断:在database 1上,Predicted1的结果和正确SQL的结果一模一样,但实际上Predicted1的SQL是错误的。
- 如果直接对比SQL语句:由于Predicted2和正确的SQL不完全一致,但其实Predicted2的SQL和正确的SQL是等价的。

那么大语言模型在应对这些问题时是否有很好的解决方案呢?遗憾的是,从当前的一些模型测试结果看,让大语言模型能够在这些场景下完全胜任,达到人类工程师的精度是不现实的。但是我们可以在几个方面考虑其优化,以实现在部分场景下的优先可用:
- 提示词工程优化
- 大模型指令微调
- Agent/RAG增强
4. NL2SQL通用优化方案
4.1 提示词工程优化
随着LLM的发展,使用LLM进行NL2SQL已成为一种新的范式。在这一过程中,如何利用提示工程来发掘LLM的NL2SQL能力显得尤为重要。
在利用LLM完成NL2SQL这一任务时,提示工程的关键在于将自然语言问题与必要的数据库信息转化为适用于LLM的自然语言序列输入,即问题表示。同时,当允许输入一些样例以利用LLM的in-context learning能力时,还需要考虑如何选择样例以及如何将这些样例有机地组织到输入序列中。
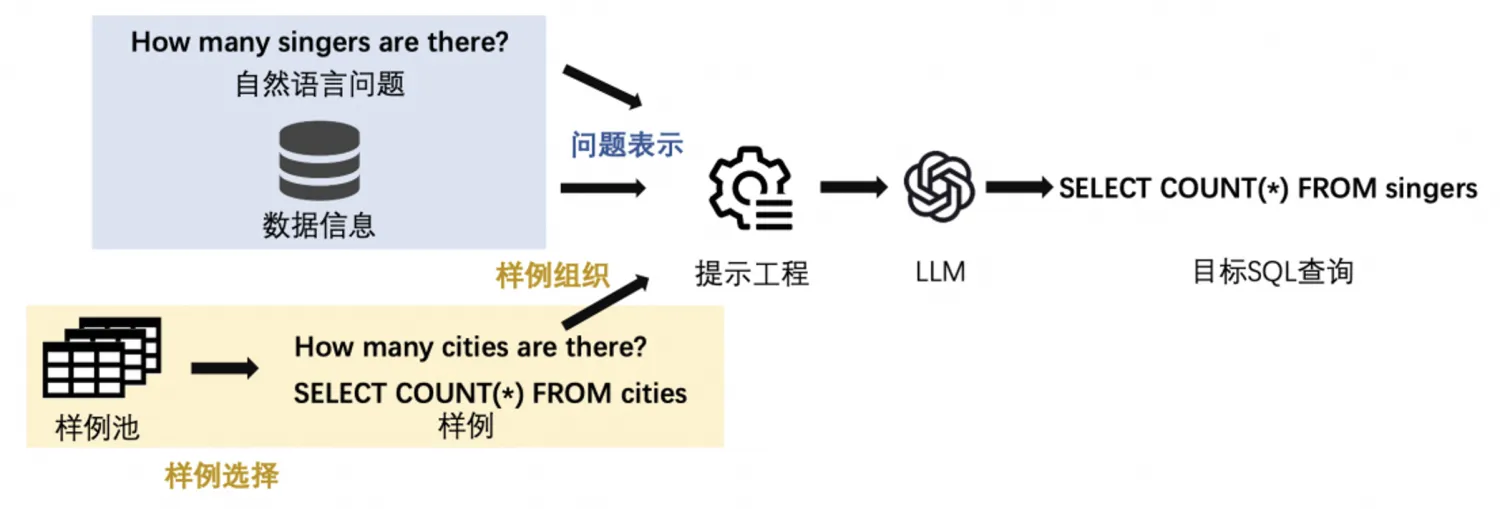
在zero-shot场景中有五花八门的Prompt模版,这里展示现有文献中四个最具代表性的。此外,再展示一个在 Alpaca中使用的Prompt模板,因为它在监督式微调中非常受欢迎。下表总结了这五种方法:
问题表示INSRIFKLLMsEM
B
S
P
BS_P
BSPxx---
T
R
P
TR_P
TRP✓xxCode-Davinci-00269.0
O
D
P
OD_P
ODP✓✓xGPT-3.5-Turbo, GPT-470.1
C
R
P
CR_P
CRP✓x✓Code-Davinci-002, GPT-3.5-Turbo75.6
A
S
P
AS_P
ASP✓xx--
EX:SQL执行准确率、INS:指令(任务描述)、RI:规则信息(指导性语句,比如“仅输出SQL语句,无需解释”)、FK:外键(数据库的外键信息)
基本提示
基本提示(Basic Prompt)是一种简单的Prompt模板,它由表模式、以 Q: 为前缀的自然语言问题、以及提示LLM生成SQL的响应前缀 A:SELECT 组成。之所以命名为基本提示,是因为它并未包含任何指令内容。

Table table_name1, columns = [column1, column2, ...]
...
Table table_name2, columns = [column1, column2, ...]
Q: The question
A: SELECT...(目标SQL)
文本表示提示
文本表示法提示(Text Representation Prompt)相比于基本提示,它在提示的开头添加了指导LLM的指令。在零样本场景中,它能在 Spider-dev 上实现了69.0%的执行准确率。

The Instruction(e.g. Given the following database schema: )
Table table_name1, columns = [column1, column2, ...]
...
Table table_name2, columns = [column1, column2, ...]
Answer the following: The question...
SELECT...(目标SQL)
OpenAI范式提示
OpenAI示范提示(OpenAI Demostration Prompt)首次在OpenAI的官方NL2SQL演示中使用,它由指令、表模式和问题组成,其中所有信息都用“#”进行注释。与文本表示提示相比,OpenAI示范提示中的指令更具体,而且还有一条规则约束,“仅完成sqlite SQL查询,无需解释”。

### The Instruction
# SQLite SQL tables, with their properties:
#
# table_name1(column1, column2, ...)
# ...
# table_name2(column1, column2, ...)
#
### The question...
SELECT...(目标SQL)
代码表示提示
代码表示提示(Code Representation Prompt)是一种基于SQL语法实现NL2SQL任务的方式。具体来说,它直接将表创建语句“CREATE TABLE …”放到Prompt中。相较于其他的问题表示方法,代码表示提示的独特之处在于,它能够提供创建数据库所需的全面信息,例如列名、列类型、主键/外键等。在这样的表示方式下, Code-Davinci-002能够正确预测约75.6%的SQL。

/* Given the following database schema: */
CREATE TABLE table_name1(
column1 type primary key,
column2 type,
foreign key(column3) references table_name2(xxx)
);
CREATE TABLE table_name2(
column1 thpe primary key,
column2 type,
foreign key(column3) references table_name1(xxx)
);
/* Answer the following: The question...
SELECT...(目标SQL)
Alpace指令微调提示
Alpace指令微调提示(Alpaca SFT Prompt)是一种用于监督微调的提示方式,它指导LLM按照指示并根据Markdown格式上下文来完成任务。

The description of the NL2SQL Task
### Instruction:
Write a sql to answer the question "The question"
### Input:
table_name1(column1, column2, ...)
...
table_name2(column1, column2, ...)
### Response:
SELECT...(目标SQL)
以上问题表示方法使大型语言模型(LLM)能够通过zero-shot学习直接输出所需的SQL。然而,在NL2SQL任务中,LLM通过上下文学习可以表现更出色,而这只需要在问题表示中提供了少量示例即可。
In-Context 学习
在In-Context 学习中,NL2SQL 涉及两个子任务:选择最有帮助的示例、将这些选定的示例组织到问题表示里面去,分别称作“示例选择(Example Selection)”和“示例组织(Example Organization)”。
示例选择
示例选择(Example Selection)在先前的研究中主要有以下几种策略:
- 随机选择(Random):此策略随机采样 k k k个可用候选的示例 Q Q Q,现有的工作已经将其作为示例选择的基准方案。
- 问题相似性选择(Question Similarity Selection):此方案选择与目标问题 q q q最相似的 k k k个示例。具体来说,使用预训练的语言模型(比如BERT等)将示例问题 Q Q Q和目标问题 q q q嵌入到同一个向量空间。然后,计算每个<示例问题, 目标问题>对应用预定义的距离度量,如欧氏距离或负余弦相似度。最后,利用 k k k近邻(KNN)算法从 Q Q Q中选择 k k k个与目标问题 q q q相近的示例。
- 遮蔽问题相似性选择(Masked Question Similarity Selection):对于跨领域NL2SQL,遮蔽问题相似性选择通过使用掩码标记(MASK)替换所有问题中的表名、列名和值,从而消除领域的特定信息,然后使用最近邻算法计算其嵌入向量的相似性。
- 查询相似性选择(Query Similarity Selection):此方案不是计算文本问题之间相似度,而是选择与目标SQL查询最相似的𝑘个示例。具体来说,首先初步使用模型将目标问题 q q q转换成SQL语句,然后选择与此SQL最相似的 k k k个示例。
上述策略重点是仅使用目标问题或目标SQL来选择示例。然而,In-Context 文学习本质上是通过类比进行学习。在NL2SQL的情况下,目标是生成与给定问题匹配的查询,因此大型语言模型应该学习从问题到SQL查询的映射,所以在示例选择过程中,同时考虑目标问题和目标SQL可能更有助NL2SQL任务。
示例组织
示例组织(Example Organization)在决定上述选定的示例有哪些信息将被组织到问题表示中发挥了关键作用。目前已有的研究中示例组织策略可以总结为两个类别,即完整信息组织和仅SQL组织。在下面的例子中,DATABASE_SCHEMA表示数据库模式,TARGET_QUESTION表示目标问题表示。
- 完整信息组织(Full-Information Organization):此策略将示例组织成与目标问题相同的表示形式。如下图示,给出了两个示例问题及其SQL语句,示例的结构与目标问题表示完全相同,唯一的区别是,给定的示例在“SELECT”后有完整的SQL查询,而目标问题在最后只有“SELECT”标记。

- 仅SQL组织(SQL-Only Organization):在提示中仅包括选定示例的SQL语句,并在前缀中附加指示信息。这种组织方式旨在最大程度地利用有限的Token长度来包括示例数量。然而,它去除了问题和SQL语句之间的映射信息,而这些信息可能很有用,后面的实验也可以证明。

总之, 完整信息组织包含了示例的全部信息,以确保质量;而仅SQL组织仅保留 SQL 查询以便选择更多示例,侧重于数量。那么是否在示例组织中存在一种更好的质量与数量的权衡呢,这可以进一步优化NL2SQL任务。
DAIL-SQL
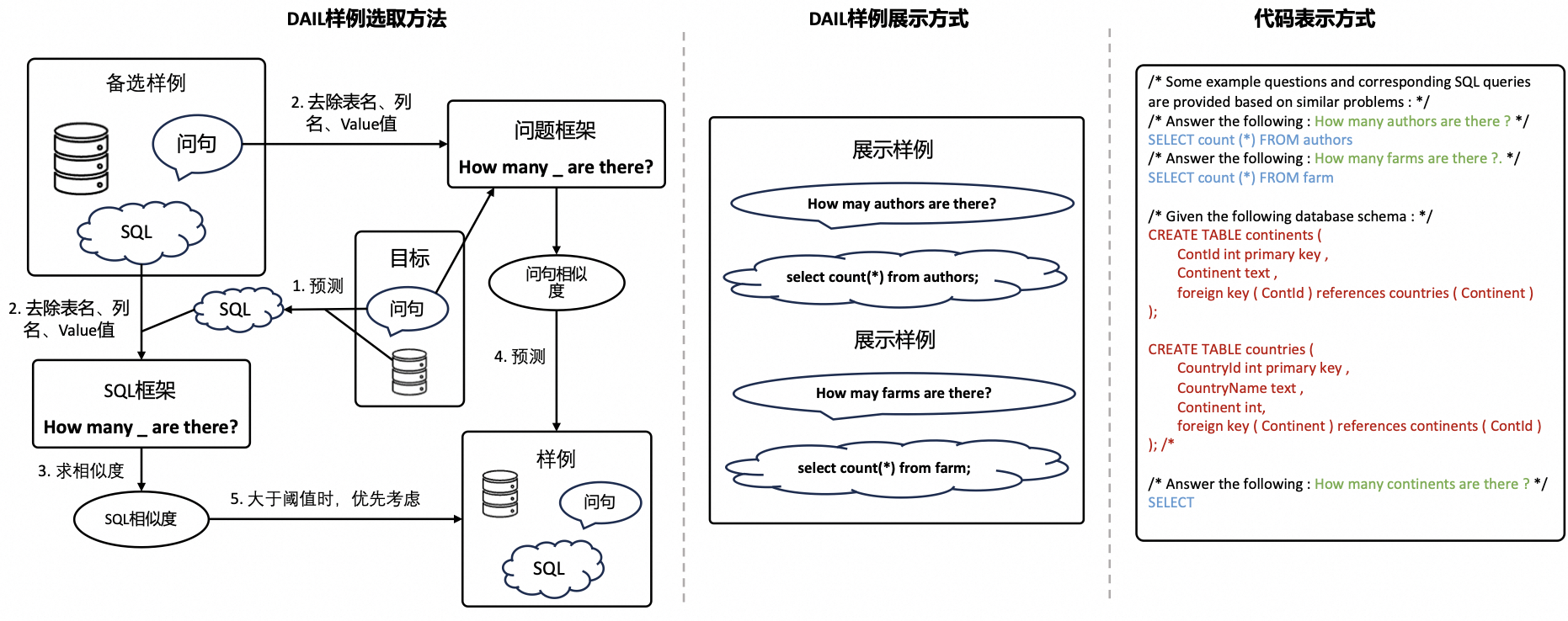
为了解决上述的问题:仅使用目标问题或目标SQL的相似度来选择示例,一个新的NL2SQL方案DAIL-SQL被提出。对于示例选择,受到遮蔽问题相似性选择和查询相似性选择的启发,DAIL同时考虑了问题和查询来选择候选示例。具体来说,DAIL选择首先屏蔽了问题的领域特定词。然后,它根据问题之间的欧几里得距离对候选示例进行排名。同时,它计算了预目标SQL与候选示例SQL之间的相似度,并要求相似度大于预定的阈值。通过这种方式,选择的
k
k
k个示例在问题和SQL上都具有很好的相似性。
除此之外,为了保留问题和SQL语句之间的映射信息并且提高Token效率,DAIL提出了一种新的示例组织策略:DAIL组织(DAIL Organization),以在质量和数量方面进行权衡。具体来说,如上图所示,DAIL组织包含了示例的问题和相应的SQL语句 ,作为完整信息组织和仅SQL组织之间的折中,DAIL组织保留了question-SQL映射,并通过去除数据库模式信息来减少示例的token长度。
C3-SQL
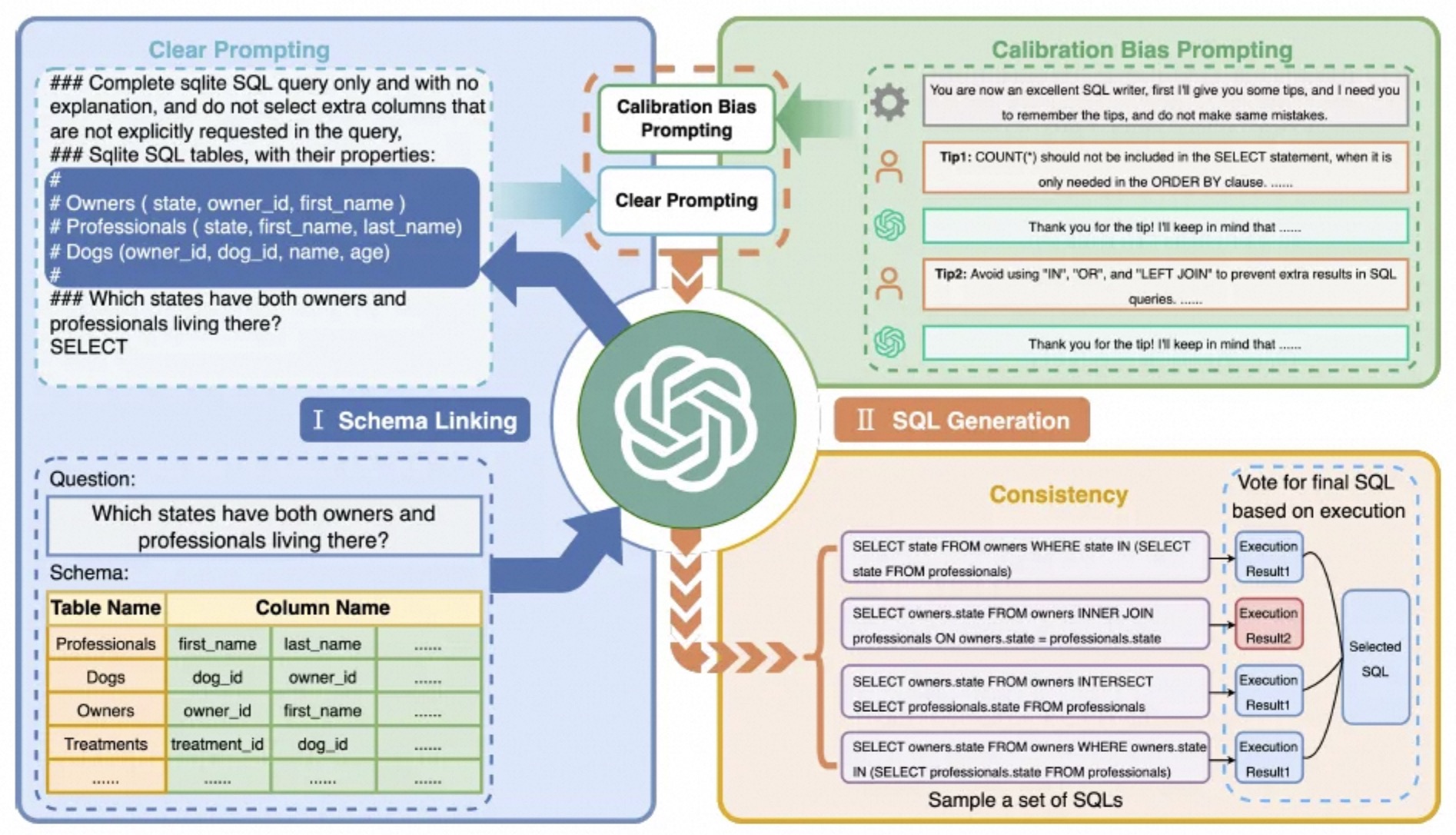
C3使用chatgpt作为基座模型,探索了zero-shot的方案,这样可以进一步降低推理成本。
浙江大学推出一种针对text2SQL场景的提示工程优化方法,与DAIL-SQL不同的是,这是一种zero-shot的提示方法(零样例),不在prompt增加样例,而是通过三个方面的提示或优化来提升输出的质量:
- Clear Prompting:通过对Prompt提供更清晰的层次,并只嵌入必要的数据结构信息,来优化提示。一个重要的思想是,在构建Prompt之前,先通过大语言模型来分析本次输入最可能相关的数据实体(table)及其列(column)信息,即仅召回本次最可能用到的table和column,然后组装到Prompt,而不是把整个数据库的结构全部组装进入。
- Claibration Bias Prompting:通过在上下文信息中嵌入一些偏差提示,可以简单的理解为指示大模型在一些场景下需要遵循的一些规则或者“注意点”。
- Consistent Output: 这是一种输出处理方式,也是解决大模型输出不确定性的一种方案。可以解释为:让大模型输出多次SQL,然后根据输出的SQL执行结果进行“投票”。比如让LLM输出四次SQL,其中三个的执行结果都是一致的,另一个结果不一致,那么就认为这三次的输出是正确的。
Chain-of-thought(CoT)
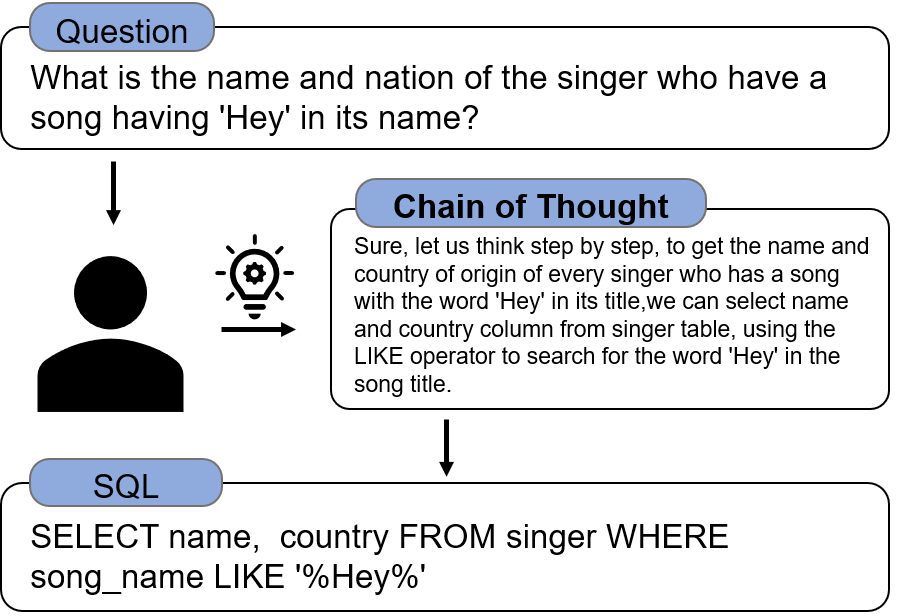
思维链(CoT)提示与大型语言模型(LLM)相结合,在复杂的推理任务上取得了不错的结果。 NL2SQL是一项典型的语义解析任务,它将自然语言转换为SQL语句,涉及复杂的推理过程。CoT首先将任务划分为子任务,然后处理每个子任务。这里列举三种常见的CoT方案:
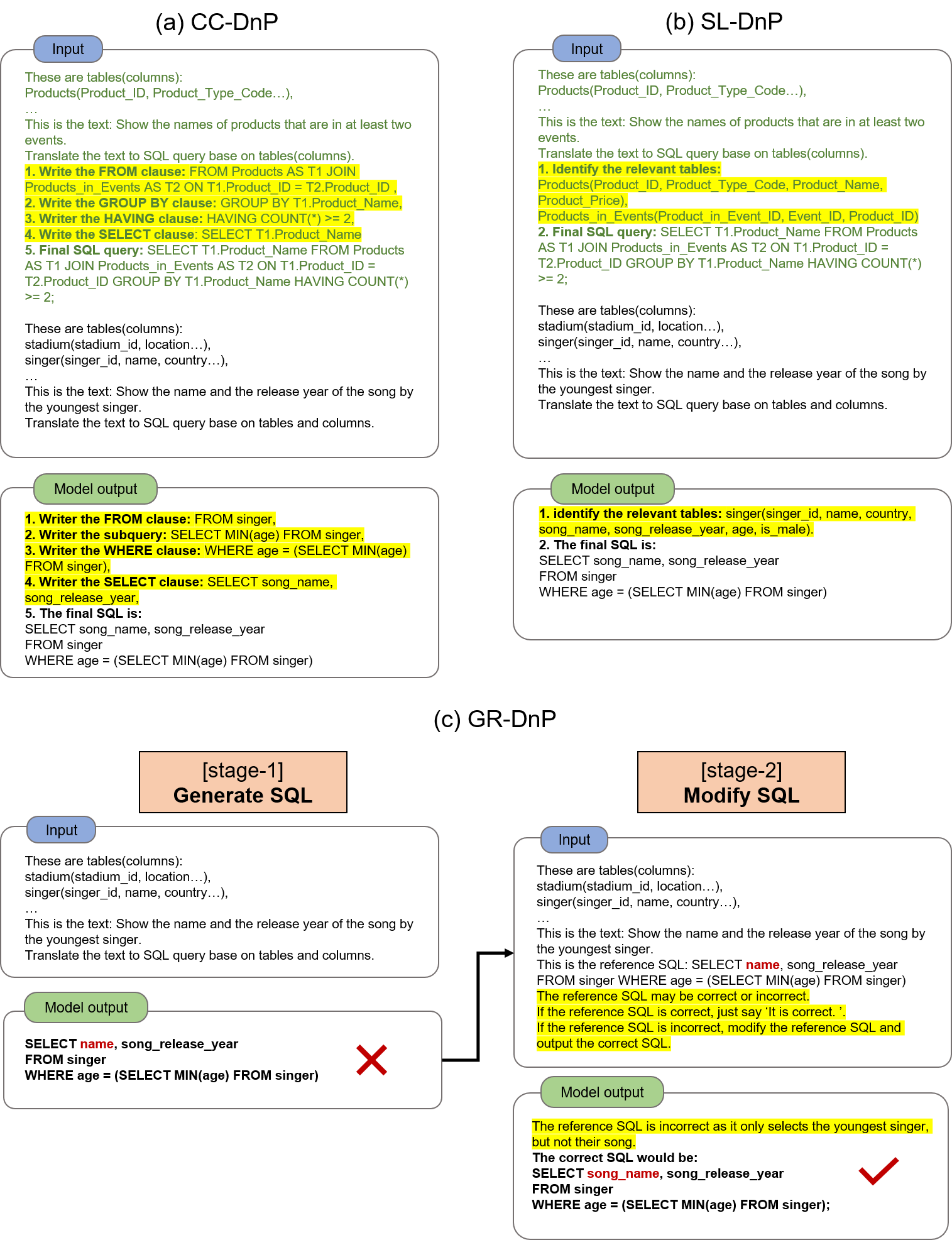
- **Clause by Clause DnP (CC-DnP)**。 在这种方法中,模型被诱导逐块生成SQL查询,例如 首先生成 SELECT 子句,然后生成 FROM 子句 ⋯ 如图所示。
- **Schema Linking DnP (SL-DnP)**。 已经证实识别相关模式元素(表、列等),对于模型正确生成SQL很有价值。 模型首先学习识别与问题相关的相关模式元素,然后生成 SQL。 更重要的是,我们发现不同的模式链接方式会对性能产生影响。
- **Generate and Refine DnP(GR-DnP)**。此方法使用 LLM 修改可能有一些错误的原始输出。该方法分两个阶段生成 SQL 查询。 第一阶段,模型生成初始SQL; 在第二阶段,模型根据需要检查并细化 SQL。 如图显示了一个示例。
通用方案总结
综合考虑上述Prompt策略,以及经过大量的实践,我们可以总结一套比较通用的NL2SQL的Prompt方案。在NL2SQL的Prompt中包含指令(Instruction)、数据结构(Table Schema)、参考样例(Sample)、其它提示(Tips)/约束条件(Constraint)、领域知识(Knowledge)、用户问题(Question)这六个要素有较好效果:
- 指令(Instruction):比如,“你是一个SQL生成专家。请参考如下的表格结构,直接输出SQL语句,不要多余的解释。”
- 数据结构(Table Schema):类似于语言翻译中的“词汇表”。即需要使用的数据库表结构,由于大模型无法直接访问数据库,你需要把数据的结构组装进入Prompt,这通常包括表名、列名、列的类型、列的含义、主外键信息。
- 参考样例(Sample):这是一个可选项,当然也是提示工程的常见技巧。即指导大模型生成本次SQL的参考样例。
- 其他提示(Tips)/约束条件(Constraint):其他你认为有必要的指示。比如要求生成的SQL中不允许出现的表达式,或者要求列名必须用“table.column"的形式等。
- 领域知识:这个也是一个可选项,在一些特定的问题中,比如“谁是这个月最厉害的销售”,需要告知模型,“最厉害”是指“销售单量最多”还是“销售金额最多”。
- 用户问题(Questions):自然语言表达的问题,比如,“统计上个月的平均订单额”。
融合上述的这些元素,我们可以得到下面的NL2SQL通用Prompt模板抽象框架,明确给出了Prompt包含哪些部分以及其可选或必选的要求。
/* 这里是描述NL2SQL任务的instructioin */[必选]
${INSTRUCTION}
/* 这里是数据库表的结构信息:*/[必选]
${DATABASE_SCHEMA}
/* 这里是一些相似的用户问题和对应的SQL语句: */[可选]
${EXAMPLE}
/* 这里与用户问题相关的领域知识: */[可选]
${KNOWLEDGE}
/* 这里是一些你需要严格遵守的约束条件:*/[可选]
${TIPS/CONSTRAINT}
/* 这里是需要生成SQL的目标用户问题 */
${TARGERT_QUESTION}[必选]
于上述NL2SQL通用Prompt模板抽象框架,可以实例出一个具体的通用Prompt模板,只需要Format ${…}即可。可以根据不同场景的需求,修改下面的内容得到特定的Prompt模板,只要按照NL2SQL通用Prompt模板抽象框架来设计即可。
你是擅长使用SQL帮助用户进行数据分析的智能助手,尽你所能的根据下面的用户问题生成准确的SQL语句。
这里是数据库表的结构信息:
${DATABASE_SCHEMA}
这里是一些相似的用户问题和对应的SQL语句:
${EXAMPLE}
这里与用户问题相关的领域知识:
${KNOWLEDGE}
请使用下面的格式:
用户问题:用户输入的问题,你需要将其转换成SQL语句
SQL: 你在这里将用户问题转成SQL语句
开始!
用户问题:${TARGERT_QUESTION}
其中
D
A
T
A
B
A
S
E
S
C
H
E
M
A
、
{DATABASE_SCHEMA}、
DATABASESCHEMA、{EXAMPLE}、${KNOWLEDGE}所填入的内容格式无特殊要求,可直接参考下面的具体Prompt样例。以一个实际场景为例,Format之后的完整Prompt如下:
你是擅长使用SQL帮助用户进行数据分析的智能助手,尽你所能的根据下面的用户问题生成准确的SQL语句。
这里是数据库表的结构信息:
CREATE TABLE IF NOT EXISTS public.dwd_en_pub_customs_trade_hscode_df
(
year INT COMMENT '年份',
month INT COMMENT '月份',
direction STRING COMMENT '贸易类型:Import/Export',
hscode_type STRING COMMENT '海关商品编码类型:hs2/hs4/hs6/commodity(当前只有hs6)',
hscode STRING COMMENT '海关商品编码',
reporter_country_en_name STRING COMMENT '报告国家英文名(IHS提供的)',
reporter_country_id INT COMMENT '报告国家ID',
reporter_country_iso STRING COMMENT '报告国家国际标准ISO(IHS提供的)',
partner_country_en_name STRING COMMENT '贸易伙伴国家英文名(IHS提供的)',
partner_country_id INT COMMENT '贸易伙伴国家ID',
partner_country_iso STRING COMMENT '贸易伙伴国家国际标准ISO(ISH提供的)',
currency STRING COMMENT '币种,当前只有USD',
trade_amt DOUBLE COMMENT '贸易金额',
ds STRING COMMENT '日期分区字段,格式为:yyyymmdd'
)
COMMENT '40个核心国家的进出口贸易数据表。这是一张全量表,最新的ds分区内包含所有历史数据'
LIFECYCLE 3; -- 表分区生命周期,单位为天,默认为3天。
这里是一些相似的用户问题和对应的SQL语句:
/* 在2023年7月,中国对哪些国家商品编码为340600的出口额排名在前五位? */
SELECT partner_country_en_name, SUM(trade_amt) AS total_trade_amt FROM nicbucdm.dwd_en_pub_customs_trade_hscode_df WHERE year = '2023' AND month = '07' AND direction = 'Export' AND reporter_country_en_name = 'China' AND hscode = '340600' GROUP BY partner_country_en_name ORDER BY SUM(trade_amt) DESC LIMIT 5;
/* 在2023年,中国对哪些月份的无机化学品的出口额最多?(hscode主要包括281410、320611、281990、282090、282410) */
SELECT year, month, SUM(trade_amt) AS total_trade_amt FROM nicbucdm.dwd_en_pub_customs_trade_hscode_df WHERE reporter_country_en_name = 'China' AND hscode IN ('281410', '320611', '281990', '282090', '282410') AND direction = 'Export' AND ds = '20231202' AND year = '2023' GROUP BY year, month ORDER BY SUM(trade_amt) DESC LIMIT 3;
/* 2023年上半年,中国进口340600和234596金额最高的月份是哪些? */
SELECT year, month, SUM(trade_amt) AS total_trade_amt FROM nicbucdm.dwd_en_pub_customs_trade_hscode_df WHERE reporter_country_en_name = 'China' AND hscode IN ('340600', '234596') AND direction = 'Import' AND ds = '20230102' AND year = TO_CHAR(TO_DATE(ds, 'yyyymmdd'), 'yyyy') AND month >= '01' AND month < '07' GROUP BY year, month ORDER BY SUM(trade_amt) DESC LIMIT 3;
这里与用户问题相关的领域知识:
1. 增长最快是指当前周期内的总金额SUM(trade_amt)环比上一个周期内总金额的增长比例最高
2. 趋势是指每个月的金额情况,需要年(year)、month(月)、sum(trade_amt)(总金额)字段,需要按照时间远到近排序,比如ORDER BY year, month ASC
3. 增幅是指当前周期内的总金额SUM(trade_amt)环比上一个周期内总金额的增长比例
4. 旺季月份是指销售总金额SUM(trade_amt)最多的月份
5. 在WHERE条件里面,Import表示进口,Export表示出口,direction IN ('Import', 'Export')表示进出口。
6. 请勿在SQL中使用hscode_type字段。
请使用下面的格式:
用户问题:用户输入的问题,你需要将其转换成SQL语句
SQL: 你在这里将用户问题转成SQL语句
开始!
用户问题:2023年皮鞋行业中国进口趋势(hscode主要包括640351、640359、640399、640420、640510)
以上就是一个完整的NL2SQL通用Prompt样例。Prompt模板中的6要素按什么顺序排列、每个要素的格式、以及每个要素的内容如何组织和获取都是影响Prompt效果的因素,像DAIL-SQL、C3-SQL等就提供了一些不错思路,后续会把这些方案和思路做成通用能力。除此之外,CoT也是一种比较有效的提升NL2SQL效果的Prompt方案,后续再在此基础上升级优化。
4.2. 大模型指令微调
为了在zero-shot场景中提高 LLM 的性能,现有的NL2SQL方法普遍采用的策略是上下文学习。作为一种替代且富有潜力方案:监督微调,至今还鲜有探讨。与各种语言任务的监督微调类似,我们也可以将其应用于NL2SQL领域,以提高LLM在这个下游任务上的性能。测试结果表明,如果直接使用当前开源的各类大语言模型,在text2SQL的任务上表现并不佳,所以SFT(高效微调)就成为常见的手段。开源的微调框架有很多,这里列举几个常用的:

4.3. Agent在NL2SQL中的应用
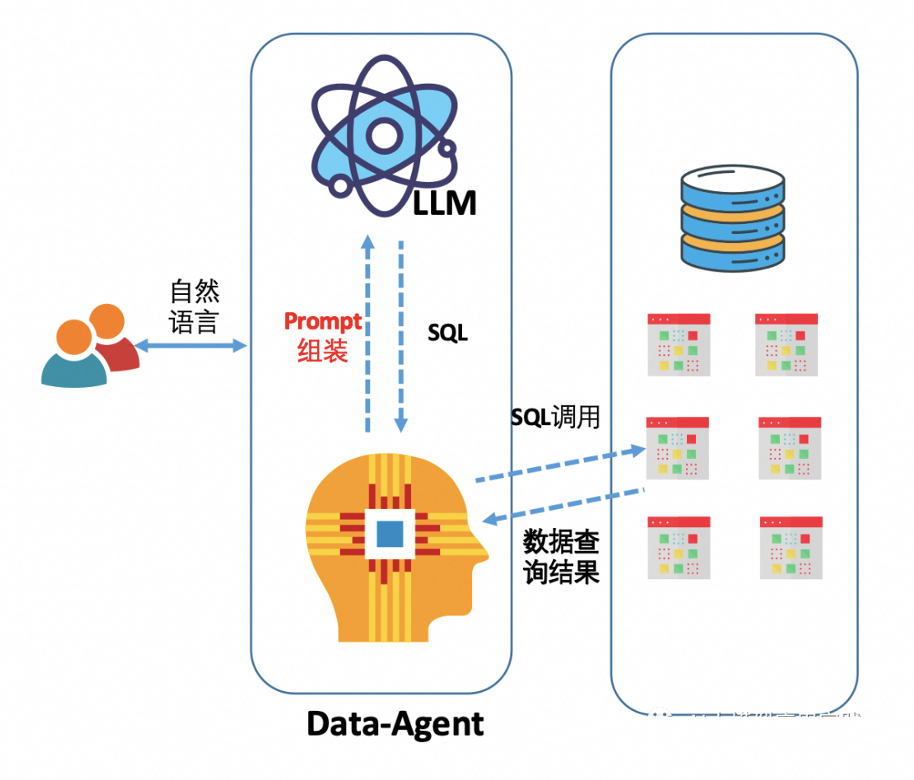
在大语言模型LLM领域中,Agent是一个人工智能系统的设计理念,它旨在模拟人类或其他智能体的行为和决策过程。Agent被设计为能够在特定环境中运作,能够感知环境状态,处理信息,制定策略,执行行动,并根据反馈调整其行为。Agent 的本质是教大模型一些思考方法论,就好像人们已经有了知识,但可能缺乏思考的方法。因此,Agent通过一个框架传授方法论,这个框架具有一些具体模块,支持整个结构的运行。一个复杂的任务通常涉及多个步骤,Agent需要知道这些步骤并提前计划,类型包括:
- 子目标和任务分解:Agent将大型任务分解为更小、更易管理的子目标,使得能够有效地处理复杂任务。其技术研究包括: - 思维链(CoT;Wei等人,2022年)已成为增强模型在复杂任务上性能的标准提示技术。模型被指示“一步一步思考”,利用更多测试时间计算将困难任务分解为更小、更简单的步骤。CoT将大任务转化为多个可管理的任务,并揭示了模型思考过程的解释。- 思维树(ToT;Yao等人,2023年)通过在每一步探索多种推理可能性扩展了CoT。它首先将问题分解为多个思维步骤,并在每一步生成多个思想,创建一个树状结构。搜索过程可以是广度优先搜索(BFS)或深度优先搜索(DFS),每个状态由分类器(通过Prompt)或多数投票评估。
任务分解可以通过以下方式进行:
- LLM使用简单的提示,如“Steps for X.Y.Z.”,“What are the subgoals for achieving XYZ?”
- 使用任务特定的指令,例如用于写作“Write a story outline.”
- 用户输入
- 反思与改进:Agent可以对过去的行为进行自我校准和自我反思,从错误中学习并改进未来步骤,从而提高最终结果的质量。其技术研究包括: - ReAct通过将“Acting行为”和“Reasoning推理”组合,在LLM中集成推理和行动。前者使LLM能够与外部环境交互(例如Wikipedia搜索API),而后者提示LLM生成自然语言中的推理轨迹。
Answer the following questions as best you can. You have access to the following tools:
{tool_desc}
Use the following format:
Question: the input question you must answer
Thought: you should always think about what to do
Action: the action to take, should be one of [quark_search,image_gen]
Action Input: the input to the action
Observation: the result of the action
... (this Thought/Action/Action Input/Observation can be repeated zero or more times)
Thought: I now know the final answer
Final Answer: the final answer to the original input question
Begin!
Question: 。
阅读原文
5. Reference
版权归原作者 _冷眸_ 所有, 如有侵权,请联系我们删除。