
损失函数
一、感知损失(Perceptual Loss)
1.相关介绍
《Perceptual Losses for Real-Time Style Transfer and Super-Resolution》提出感知损失的概念,用于实时超分辨任务和风格迁移任务,后来也被应用于更多的领域,在图像去雾方向也有不少工作使用到了感知损失,所以这里就细看一下感知损失具体是什么,该如何构造(说个题外话:我之前做实验,用VGG提取特征构造感知损失狂爆内存,然后直接放弃了,都怪设备太垃圾啊!!!)。
1)Perceptual Loss是什么?
对于图像数据来说,网络在提取特征的过程中,较浅层通常提取边缘、颜色、亮度等低频信息,而网络较深层则提取一些细节纹理等高频信息,再深一点的网络层则提取一些具有辨别性的关键特征,也就是说,网络层越深提取的特征越抽象越高级。
感知损失就是通过一个固定的网络(通常使用预训练的VGG16或者VGG19),分别以真实图像(Ground Truth)、网络生成结果(Prediciton)作为其输入,得到对应的输出特征:feature_gt、feature_pre,然后使用feature_gt与feature_pre构造损失(通常为L2损失),逼近真实图像与网络生成结果之间的深层信息,也就是感知信息,相比普通的L2损失而言,可以增强输出特征的细节信息。
可以这么理解:此处的固定网络视为一个函数f,feature_gt=f(Ground Truth),feature_pre=f(Prediciton) ,我们的目的是最小化feature_gt与feature_pre之间的差异,即最小化feature_gt、feature_pre构成的感知损失。
2)Perceptual Loss如何构造?
- 设置固定网络(如ImageNet上预训练好的VGG16),该网络参数固定,不进行更新;
- 以真实图像(Ground Truth)、网络生成结果(Prediciton)作为其输入,得到对应的输出特征:feature_gt、feature_pre;
- 使用feature_gt与feature_pre构造损失;

此处有两个需要注意的地方:
(1)通常生成网络的目标函数不只有一个感知损失,而是由多部份损失组合得到最终的损失函数,比如:
其中α、β作为权衡系数调整不同损失对总损失函数的重要性。
(2)通常不只使用固定网络(如VGG16)的单一层提取特征,而是使用其网络结构中的浅层、较深层、更深层中的某几层组合提取特征,构造损失。对于真实图像y和生成图像y’,定义如下,N表示一个批次中样本数,Φ表示固定网络的特征提取层,j表示指定的第j个网络层,Φj表示该层的输出特征: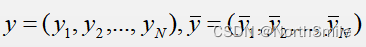
单一层提取特征:
此时,特征提取使用固定网络中的多个指定网络层的输出特征进行组合构造损失,比如VGG16 的特征提取模块的第3、5、7个卷积层的输出特征进行累加。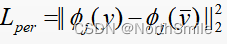
多个层组合:
此时,特征提取使用固定网络中的指定网络层的输出特征构造损失,比如VGG16 的特征提取模块的第3个卷积层的输出。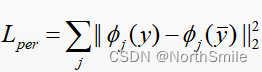
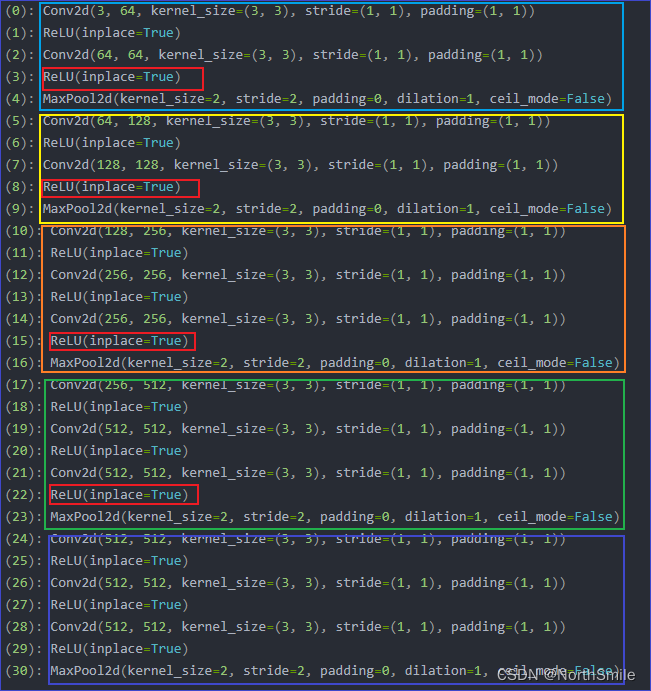
VGG16特征提取模块结构如下:
原文中使用红框所示的四个激活层的输出构造感知损失,对应我在结构图中用红色框住的部分: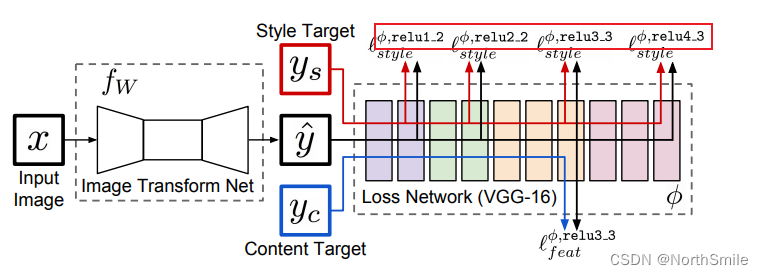
3)代码实现
import torch
import torch.nn as nn
from torch.autograd import Variable
from torchvision.models import vgg16
import warnings
warnings.filterwarnings('ignore')# 计算特征提取模块的感知损失defvgg16_loss(feature_module,loss_func,y,y_):
out=feature_module(y)
out_=feature_module(y_)
loss=loss_func(out,out_)return loss
# 获取指定的特征提取模块defget_feature_module(layer_index,device=None):
vgg = vgg16(pretrained=True, progress=True).features
vgg.eval()# 冻结参数for parm in vgg.parameters():
parm.requires_grad =False
feature_module = vgg[0:layer_index +1]
feature_module.to(device)return feature_module
# 计算指定的组合模块的感知损失classPerceptualLoss(nn.Module):def__init__(self,loss_func,layer_indexs=None,device=None):super(PerceptualLoss, self).__init__()
self.creation=loss_func
self.layer_indexs=layer_indexs
self.device=device
defforward(self,y,y_):
loss=0for index in self.layer_indexs:
feature_module=get_feature_module(index,self.device)
loss+=vgg16_loss(feature_module,self.creation,y,y_)return loss
在使用上面代码构造感知损失时需要注意:
- loss_func为基础损失函数:确定使用那种方式构成感知损失,比如MSE、MAE,在声明PerceptualLoss对象时需要提前使用loss_func.to(device)确定损失函数执行运算的设备;
- layer_indexs必须为列表或元祖,指定使用VGG16的哪几个网络层的输出构成感知损失,比如3则表示使用vgg16特征提取模块中的0-3层构成的第一个模块的输出;
2.代码示例
# -*- coding: utf-8 -*-# create time:2022/9/28# author:Pengze Liimport torch
import torch.nn as nn
from torch.autograd import Variable
from torchvision.models import vgg16
import warnings
warnings.filterwarnings('ignore')# 计算特征提取模块的感知损失defvgg16_loss(feature_module,loss_func,y,y_):
out=feature_module(y)
out_=feature_module(y_)
loss=loss_func(out,out_)return loss
# 获取指定的特征提取模块defget_feature_module(layer_index,device=None):
vgg = vgg16(pretrained=True, progress=True).features
vgg.eval()# 冻结参数for parm in vgg.parameters():
parm.requires_grad =False
feature_module = vgg[0:layer_index +1]
feature_module.to(device)return feature_module
# 计算指定的组合模块的感知损失classPerceptualLoss(nn.Module):def__init__(self,loss_func,layer_indexs=None,device=None):super(PerceptualLoss, self).__init__()
self.creation=loss_func
self.layer_indexs=layer_indexs
self.device=device
defforward(self,y,y_):
loss=0for index in self.layer_indexs:
feature_module=get_feature_module(index,self.device)
loss+=vgg16_loss(feature_module,self.creation,y,y_)return loss
if __name__ =="__main__":
device = torch.device("cuda"if torch.cuda.is_available()else"cpu")
x = torch.ones((1,3,256,256))
y = torch.zeros((1,3,256,256))
x,y=x.to(device),y.to(device)
layer_indexs =[3,8,15,22]# 基础损失函数:确定使用那种方式构成感知损失,比如MSE、MAE
loss_func = nn.MSELoss().to(device)# 感知损失
creation = PerceptualLoss(loss_func, layer_indexs, device)
perceptual_loss=creation(x,y)print(perceptual_loss)
tensor(0.1451, device='cuda:0')
二、总变分损失(TV Loss)
1.相关介绍
1)TV Loss全称Total Variation Loss,计算输入图像的总变分。TV Loss常用作正则项出现在总体函数中去约束网络学习,可以有效促进网络输出结果的空间平滑性。在数字图像处理中,其定义通常如下:
上述公式只针对单幅图像,xi,j表示输入图像中的一个像素点,公式的含义是:分别计算每个像素点xi,j与水平方向(图像的宽W)、垂直方向(图像的高H)的下一个紧邻像素xi,j-1、xi+1,j之间的差的平方,然后开方,针对所有像素求和即可。
2)代码实现
def_tensor_size(t):return t.size()[1]* t.size()[2]* t.size()[3]deftv_loss(x):
h_x = x.size()[2]
w_x = x.size()[3]
count_h = _tensor_size(x[:,:,1:,:])
count_w = _tensor_size(x[:,:,:,1:])
h_tv = torch.pow((x[:,:,1:,:]- x[:,:,:h_x -1,:]),2).sum()
w_tv = torch.pow((x[:,:,:,1:]- x[:,:,:,:w_x -1]),2).sum()return2*(h_tv/count_h+w_tv/count_w)classTV_Loss(nn.Module):def__init__(self,TVLoss_weight=1):super(TV_Loss, self).__init__()
self.TVLoss_weight = TVLoss_weight
defforward(self,x):
batch_size=x.shape[0]return self.TVLoss_weight*tv_loss(x)/batch_size
2.代码示例
import torch
import torch.nn as nn
from torchvision import transforms
import numpy as np
import os
import time
import pathlib
from matplotlib import pyplot as plt
import warnings
np.set_printoptions(threshold=np.inf)
warnings.filterwarnings(action='ignore')def_tensor_size(t):return t.size()[1]* t.size()[2]* t.size()[3]deftv_loss(x):
h_x = x.size()[2]
w_x = x.size()[3]
count_h = _tensor_size(x[:,:,1:,:])
count_w = _tensor_size(x[:,:,:,1:])
h_tv = torch.pow((x[:,:,1:,:]- x[:,:,:h_x -1,:]),2).sum()
w_tv = torch.pow((x[:,:,:,1:]- x[:,:,:,:w_x -1]),2).sum()return2*(h_tv/count_h+w_tv/count_w)classTV_Loss(nn.Module):def__init__(self,TVLoss_weight=1):super(TV_Loss, self).__init__()
self.TVLoss_weight = TVLoss_weight
defforward(self,x):
batch_size=x.shape[0]return self.TVLoss_weight*tv_loss(x)/batch_size
device=torch.device("cuda"if torch.cuda.is_available()else"cpu")
x=torch.randint(10,size=(1,1,3,3))
x=x.to(device)print(x)
creation=TV_Loss().to(device)
loss=creation(x)print(loss)
tensor(156.3333, device='cuda:0')
参考:
1)https://blog.csdn.net/u013289254/article/details/102880140
2)https://blog.csdn.net/yexiaogu1104/article/details/88395475
声明:上述内容若有错误,欢迎大家一起探讨!
版权归原作者 NorthSmile 所有, 如有侵权,请联系我们删除。