
一、深度学习里面的element-wise特征相乘和相加到底有什么区别?
很多深度学习模型在设计时,中间特征在分支处理后,然后可能会采用element-wise相乘或相加,不知道这个乘和加的细微区别?
答:相加的两个tensor通常都是具有特征意义的tensor,相乘的话,一般来说,其中一个tensor是有类似权重的含义,而不是特征意义。
二、concatenation operation
向量之间的拼接
代码例子如下:
import numpy as np
a = np.array([[1, 2], [3, 4]])
print(a.shape)
b = np.array([[5, 6]])
print(b.shape)
np.concatenate((a, b))
c= np.concatenate((a, b))
print(c)
print(c.shape)
Out[1]: (2, 2)
Out[2]: (1, 2)
Out[3]:
array([[1, 2],
[3, 4],
[5, 6]])
Out[4]: (3, 2)
三、Dot Product
向量点积

import numpy as np
np1 = np.array([4, 6])
np2 = np.array([[-3], [7]])
print(np.dot(np1, np2)
## [30]
# 4*-3 + 6*7 = 42*12 = 30
四、element-wise product
element-wise product实际上是两个同样维度的向量/矩阵每一个元素分别相乘
这个可以参见:我的另一篇文章
import numpy as np
np1 = np.array([4, 6])
np2 = np.array([-3, 7])
print(np2 * np1)
# [-12 42]
import numpy as np
np1 = np.array([4, 6])
print(np1 * 3)
# [12 18]
五、DL中,何时用concatenate/elementwise乘法/elementwise加法呢?
深度学习中,信息相互融合的时候,什么时候用concatenate,什么时候用elementwise乘法呢,什么时候又用elementwise加法呢?
答:
点乘其实是gate的形式 可能会损失性能。concatenate则是简单拼接,要网络自己学习变换。
实际过程中可能只能试。
六、feature map的几种连接形式
(1)concatenate:通道合并,每个通道对应着对应的卷积
(2)element-wise addition(计算量比(1)小):将对应的特征图相加,然后卷积。对应通道的特征图语义类似,对应的特征图共享一个卷积核。
对比:
add方式:add的特征结合方式使得描述图像的特征下的信息量增多了,但是描述图像的维度本身并没有增加,只是每一维下的信息量在增加,这显然是对最终的图像的分类是有益的。
concatenate方式:该方式是通道数的合并,也就是说描述图像本身的特征数(通道数)增加了,而每一特征下的信息是没有增加的。
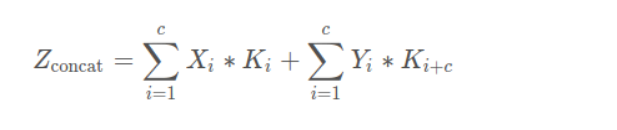
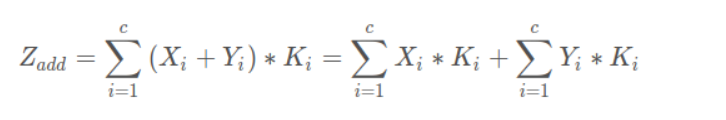
显然,concatenate的计算量 > add的计算量
另:还有element-wise max和element-wise average方式
实验结果:max>avg>concate
七、总结
通过add操作会得到新的特征,这个新的特征可以反映原始特征的一些特性,但是原始特征的一些信息也会由于add方式造成损失,但是concatenate就是将原始特征直接拼接,让网络去学习应该如何融合特征,这个过程中信息不会损失。
concat带来的计算量较大,在明确原始特征的关系可以使用add操作融合的话,使用add操作可以节省计算代价!
参考:
深度学习中---merger层、concatenate层、add层的区别_夜幕下的光123的博客-CSDN博客_concatenate层
Pytorch教程(十五):element-wise、Broadcasting_vincent_duan的博客-CSDN博客_element-wise
版权归原作者 曙光_deeplove 所有, 如有侵权,请联系我们删除。