
摘要:
AI中英文场景OCR(Optical Character Recognition,光学字符识别)技术是一种利用人工智能技术识别和提取图像或视频中的文字信息的技术。它可以自动检测图像中的文字,并将其转换为可编辑的文本格式,从而实现对图像中文字的理解和处理。在英文场景中,AI中英文场景OCR技术能够识别和提取英文文本,包括印刷体和手写体文字。通过使用深度学习和计算机视觉技术,OCR系统能够实现高准确度的文字识别,即使在复杂的背景或低光照条件下,也能够有效地提取文字信息。
目前有许多项目和平台支持OCR识别技术。以下是一些主要的OCR识别项目和平台:
Tesseract OCR: Tesseract是一个开源的OCR引擎,由Google开发。它支持多种操作系统,并提供了许多语言的文本识别能力。
Microsoft Azure Computer Vision API: 微软Azure平台提供了强大的计算机视觉API,其中包括OCR功能,能够识别图像中的文本,并提供文本检测和提取服务。
Google Cloud Vision API: 谷歌云平台的计算机视觉API也提供了OCR功能,能够识别图像中的文字,并支持多种语言的文本识别。
ABBYY FineReader: ABBYY FineReader是一款商业化的OCR软件,具有强大的文字识别和文档处理能力,支持多种文件格式的识别。
Baidu OCR: 百度提供了OCR文字识别的云服务,能够识别图像中的文字,并支持中英文等多种语言的识别。
Amazon Textract: 亚马逊的Textract是一项全面的文档识别服务,能够自动检测和提取图像中的文本、表格和键值对等信息。
大家可以从下面两个项目中了解OCR的强大:
项目1:https://github.com/baudm/parseq
项目2:https://github.com/clovaai/donut
实战:
现在我使用两种方法实现简单的OCR功能:分别是使用easyocr库和Tesseract OCR引擎。
一、easyocr库
EasyOCR操作简单,是一个基于PyTorch的开源OCR库,可以用于进行文本检测和识别。EasyOCR库的设计目标是简化OCR技术的应用,使用户能够快速地实现文字识别功能,同时具有较高的识别准确度。重点是它支持中文(简体和繁体)、英文、 法语等70种语言,非常强大。
当你第一次使用时,选择一种语言,程序会自动下载该语言模型。
代码:
import cv2
import easyocr
import matplotlib.pyplot as plt
preprocess = 'blur'
image = cv2.imread('test2.jpg')
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
if preprocess == 'blur':
gray = cv2.medianBlur(gray, 3)
plt.imshow(cv2.cvtColor(gray, cv2.COLOR_BGR2RGB))
plt.axis('off') # 关闭坐标轴
plt.show()
# 使用 EasyOCR 进行文本识别
reader = easyocr.Reader(['en']) #选择对应语言
result = reader.readtext(image)
# 在图像上打印识别结果
for detection in result:
top_left = tuple(detection[0][0])
bottom_right = tuple(detection[0][2])
text = detection[1]
cv2.rectangle(image, top_left, bottom_right, (0, 255, 0), 2)
cv2.putText(image, text, (top_left[0], top_left[1] - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.8, (0, 255, 0), 2)
print(detection[1])
# 保存带有识别结果的图像
output_image_file = "result_with_text1.jpg"
cv2.imwrite(output_image_file, image)
print(f"带有识别结果的图像已保存到 {output_image_file}")
这里我选择一张英文广告牌:

将识别结果输出打印在图像上:

发现没什么问题!
再试试中文,由于中文在opencv上是打印不出来的,所以我使用以下代码,这个字体文件在C:/windows/Fonts:
import cv2
import easyocr
import matplotlib.pyplot as plt
from PIL import ImageFont, Image, ImageDraw
import numpy as np
preprocess = 'blur'
image = cv2.imread('test.png')
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
if preprocess == 'blur':
gray = cv2.medianBlur(gray, 3)
plt.imshow(cv2.cvtColor(gray, cv2.COLOR_BGR2RGB))
plt.axis('off') # 关闭坐标轴
plt.show()
# 使用 EasyOCR 进行文本识别
reader = easyocr.Reader(['ch_tra']) # 选择对应语言
result = reader.readtext(image)
font_path = 'msyh.ttc' #windows自带字体
font = ImageFont.truetype(font_path, 32)
# 在图像上打印识别结果
image_pil = Image.fromarray(image)
draw = ImageDraw.Draw(image_pil)
for detection in result:
top_left = detection[0][0]
bottom_right = detection[0][2]
text = detection[1]
cv2.rectangle(image, top_left, bottom_right, (0, 255, 0), 2)
draw.text((top_left[0], top_left[1] - 10), text, fill=(0, 255, 0), font=font)
# 将带有识别结果的图像转换为 OpenCV 格式并保存
image_with_text_np = np.array(image_pil)
output_image_file = "result_with_text.png"
cv2.imwrite(output_image_file, image_with_text_np)
print(f"带有识别结果的图像已保存到 {output_image_file}")

输出打印结果:

也都识别出来了。
二、Tesseract OCR引擎
Tesseract是一个开源的OCR引擎,由Google开发。它支持多种操作系统,并提供了许多语言的文本识别能力。
使用Tesseract需要下载对应的.exe程序,在这个网址里:https://digi.bib.uni-mannheim.de/tesseract/
安装好程序后记得把你的安装路径添加进环境变量里,这样可以在任何位置使用它,进入cmd,输入tesseract -v测试是否安装成功,如果成功会输出相关信息:
然后,我们还要找到python的安装路径,找到Libs/site-packages/pytesseract/pytesseract.py
找到:tesseract_cmd = 改成自己Tesseract程序的安装路径/tesseract.exe'
然后我们使用以下代码可以使用:
from PIL import Image
import pytesseract
import cv2
import os
preprocess = 'blur' #thresh
image = cv2.imread('scan.jpg')
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
if preprocess == "thresh":
gray = cv2.threshold(gray, 0, 255,cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1]
if preprocess == "blur":
gray = cv2.medianBlur(gray, 3)
filename = "{}.png".format(os.getpid())
cv2.imwrite(filename, gray)
text = pytesseract.image_to_string(Image.open(filename))
print(text)
os.remove(filename)
cv2.imshow("Image", image)
cv2.imshow("Output", gray)
cv2.waitKey(0)
输入:
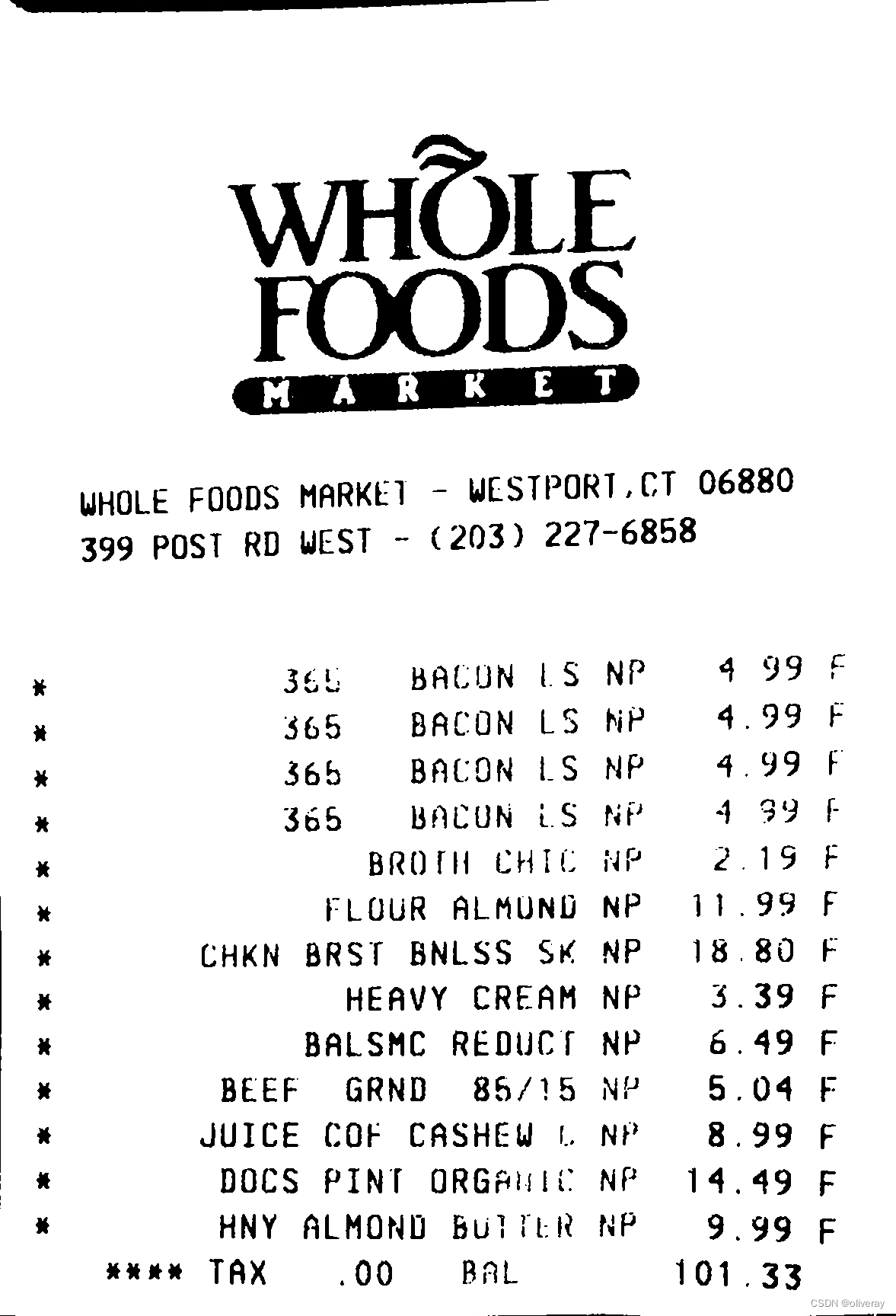
输出: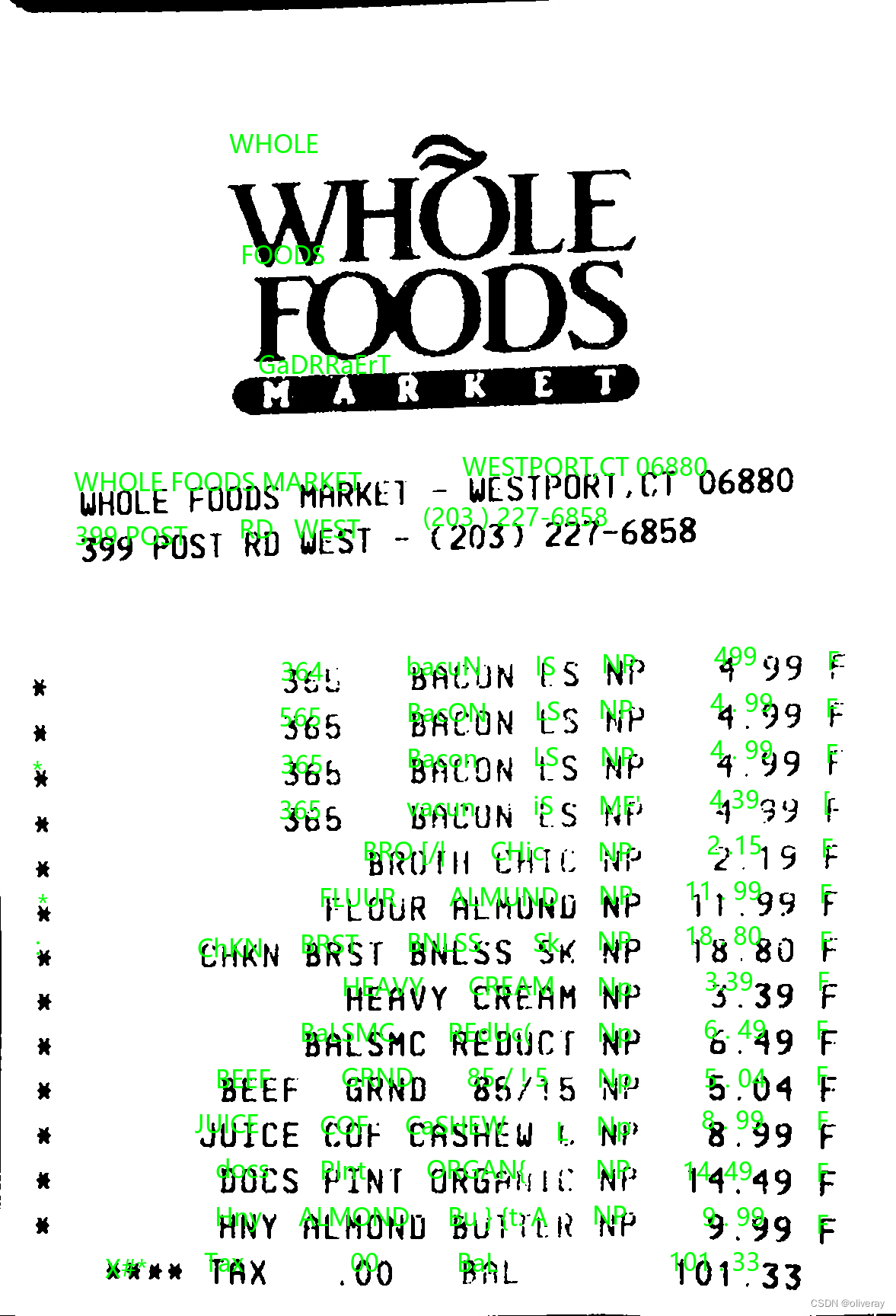
OCR用于实现图像中英文本的快速识别的项目还有很多,感兴趣的小伙伴可以自己了解。
以上为全部内容!
版权归原作者 oliveray 所有, 如有侵权,请联系我们删除。