
一、YOLOV5S网络结构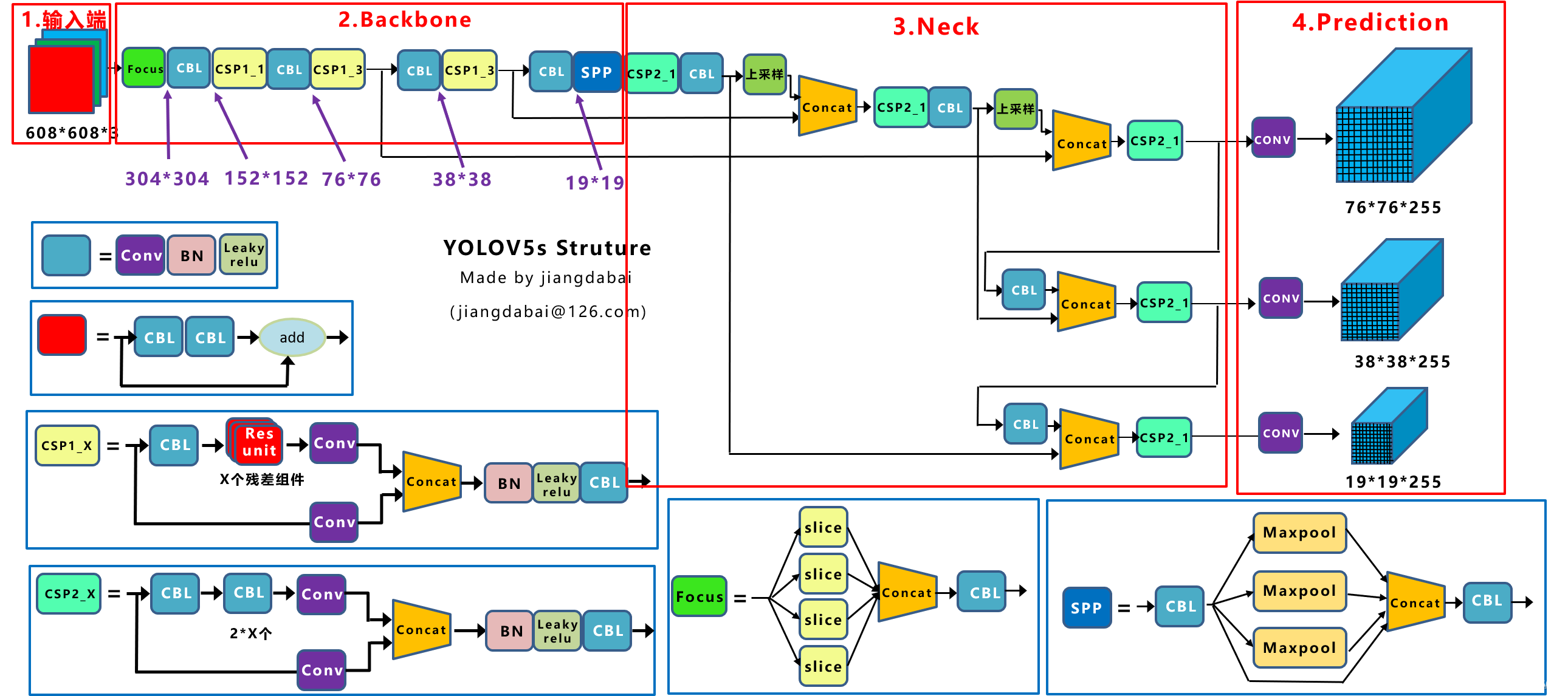 ](https://img-blog.csdnimg.cn/10a2b7587dd44dbebd23129cf8f71643.png)
](https://img-blog.csdnimg.cn/10a2b7587dd44dbebd23129cf8f71643.png)
(参考:https://blog.csdn.net/nan355655600/article/details/107852353)
(1)输入端处理
①Mosaic数据增强
Yolov5和Yolov4一样,对于输入图片采用了Mosaic数据增强,也就是对图片进行处理后,再多张拼贴起来。起到了数据增强的作用。
②自定义锚框
在Yolov3和Yolov4中,我们都需要提前设定Anchor的大小,以便于去适应不同大小的真实框。
在Yolov3、Yolov4中,训练不同的数据集时,计算初始锚框的值是通过单独的程序运行的。
但Yolov5中将此功能嵌入到代码中,每次训练时,自适应的计算不同训练集中的最佳锚框值。
③自适应图片放缩
输入图片和网络需要的输入大小的图片往往是不相同,我们要对输入图片进行处理,一般是通过先压缩再加灰边等方式。
在Yolov5中也是通过这样的方式 ,当时Yolov5采用了一个更好的方式,可以使得加灰边的大小尽可能的小,可以增加运行的速度。
(2)Backbone
①Focus结构
Backbone中的第一个模块是Focus模块。这是以前没有用过的结构。Focus模块的核心是切片slice。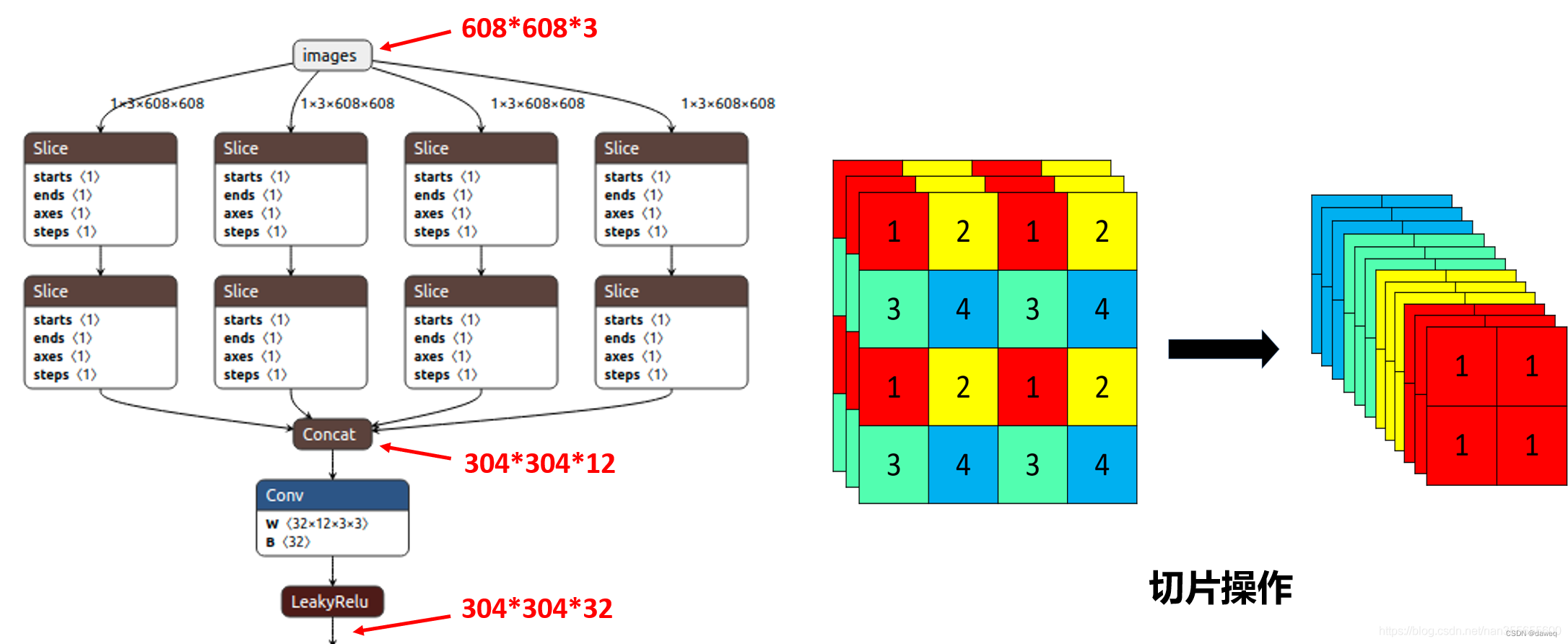
其实实际上就是对数据进行了下采样。输入608x608x3大小的图片,经过Concat模块后,会变成304x304x12的大小。再经过一次32个卷积核的卷积操作,最终变成304×304×32的特征图。
②CSP结构
在Yolov5中采用了两种CSP结构,分别在Back中,这里先介绍第一种。CSP1,其中分为CSP1_1和CSP1_3。具体的网络结构可以看图。本质上是一种多次充分利用残差的网络结构。
(3)Neck
Yolov5中的Neck采用FPN+PAN的结构,和Yolov4中最大的不同就是使用了CSPNET网络。采用上,下采样灵活的构造特征金字塔。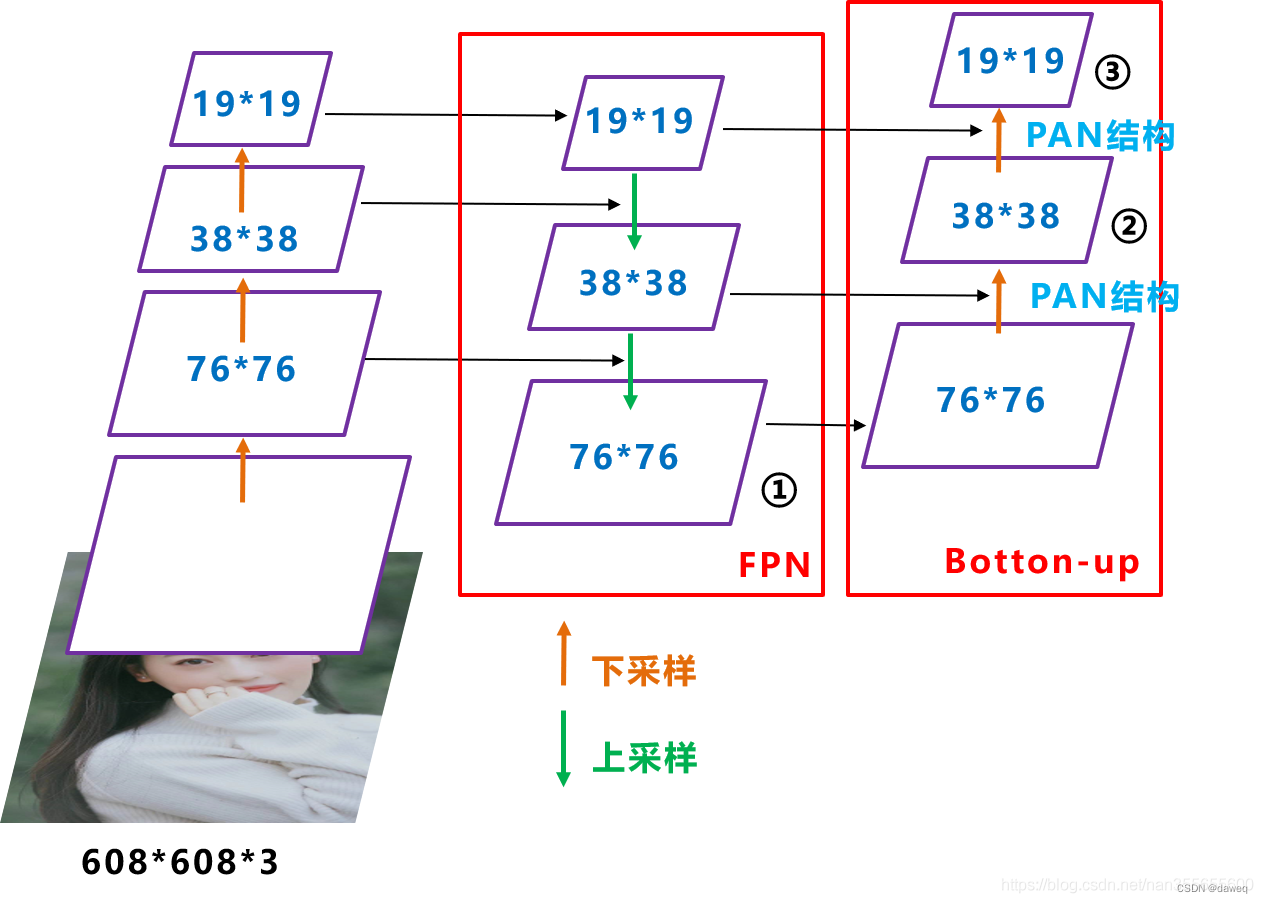
(4)输出端
输出端的处理,其实和Yolov4基本上差别不大。
Yolov5中采用其中的CIOU_Loss做Bounding box的损失函数。
Yolov4在DIOU_Loss的基础上采用DIOU_nms的方式,而Yolov5中仍然采用加权nms的方式。
二、四种Yolov5结构的差别和控制。
四种Yolov5的结构分别为Yolov5s,Yolov5m,Yolov5l,Yolov5x。
这四种结构其实本质上没有区别,它们的主要差别是在于,用两个不同的参数,控制了网络的深度和宽度。
depth_multiple控制网络的深度,width_multiple控制网络的宽度。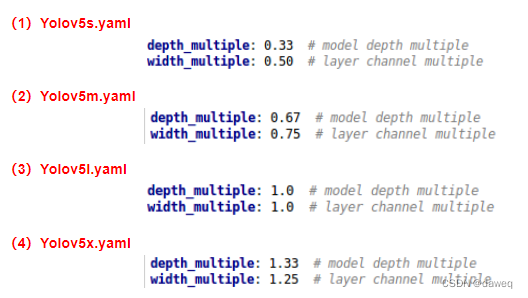
(1)depth_multiple深度
我们以Backbone中的CSP结构为例,下图是4种不同结构的CSP结构中的残差次数。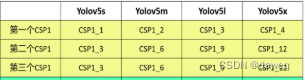
总的来说在基本网络结构中,会对CSP网络的参数进行确定,而我们将用公式吧参数和给出的深度,宽度参数进行计算,从而算出残差次数的使用次数,也就控制了深度。
(2)width_multiple宽度
其实计算方法是类似的,这里控制的是每一次卷积的卷积核的大小。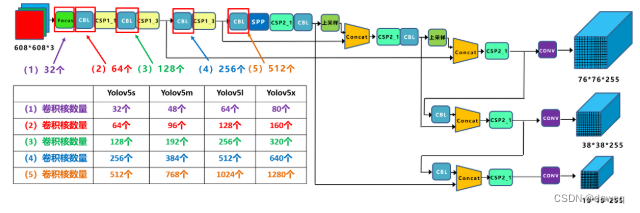
版权归原作者 daweq 所有, 如有侵权,请联系我们删除。