
Reducing Label Effort: Self-Supervised meets Active Learning这篇论文将主动学习和自监督训练结合,减少了标签的依赖并取得了很好的效果。
自监督学习 (SimSiam) + 主动学习 (AL)
通过自监督的预训练强化主动学习框架图
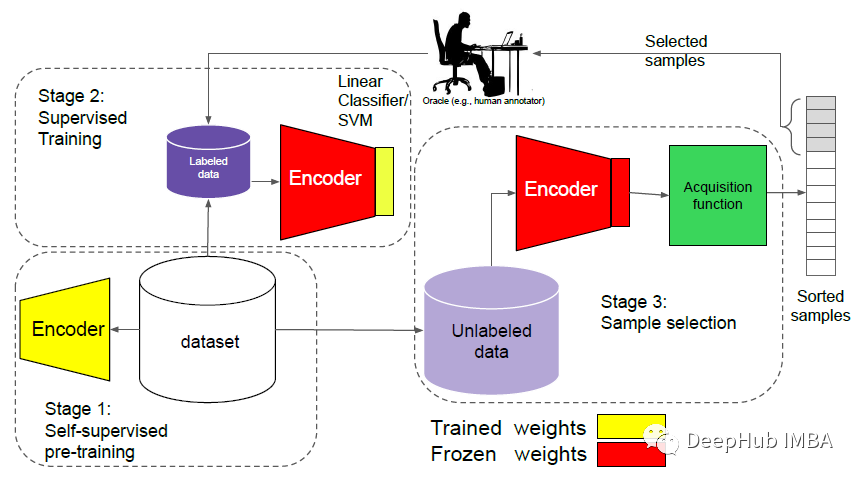
该框架包括3个阶段:
- 在整个数据集上训练自监督训练。
- 冻结主干网络的权重并给定少量标记数据,使用线性分类器或支持向量机以监督的方式进行微调。
- 运行该模型对未标记的数据进行推理,然后通过采集函数对样本进行从信息量最小到最高的排序。最后将顶级样本通过人工的专家进行标注,并添加到标注集。
上述阶段重复,直到全部标签都进行了训练和标注。
在主动学习方面,考虑了几种获不同的方法,包括Informativeness[10]和Representativeness[42,40]的方法。论文中并没有提及抽样方法的问题,因为作者发现最好的方法是随机抽样。
使用SimSiam进行自监督学习
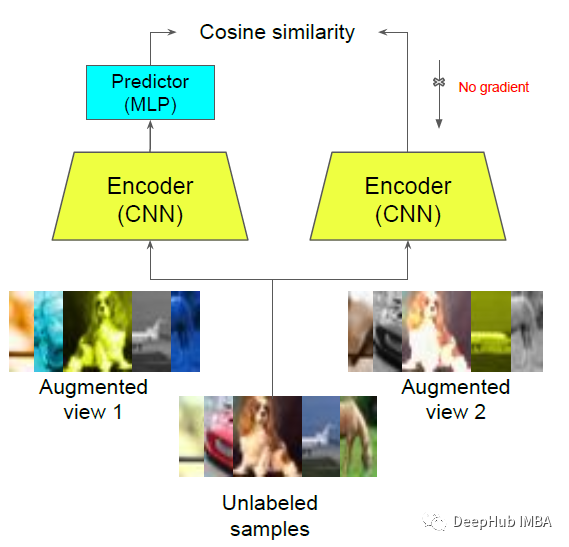
这里可以使用任何自监督学习框架。作者选用的是SimSiam
实验结果
均匀地从所有类中随机选择整个数据集的1%,2%和10%。对于其中一个数据集,论文还评估了0.1%和0.2%的选取规模。
在每个循环中,训练要么完全重新开始,要么首先使用自监督训练预训练主干网络。该模型在c个循环中进行训练,直到完成所有的选取规模。
CIFAR-10 & CIFAR-100
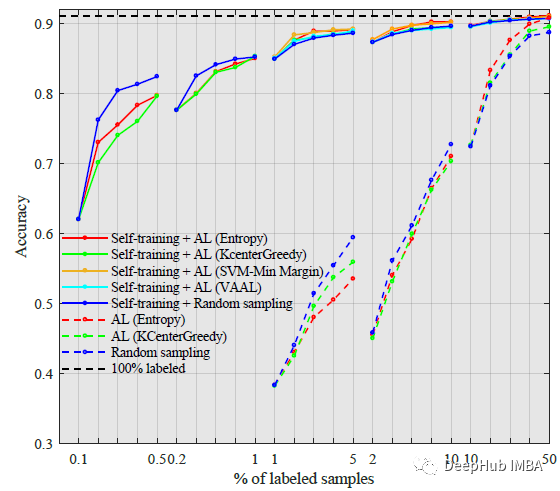
实验表明特别是在低预算(训练标注少)的情况下,自监督大大减少了所需的标签。
这两种方法(使用和不使用自监督预训练)在标记了50%的数据后几乎达到了完整的性能,缩小了自监督方法和监督方法之间的差距。从主动学习的角度来看,当标注数据小于1%时,随机抽样优于AL。
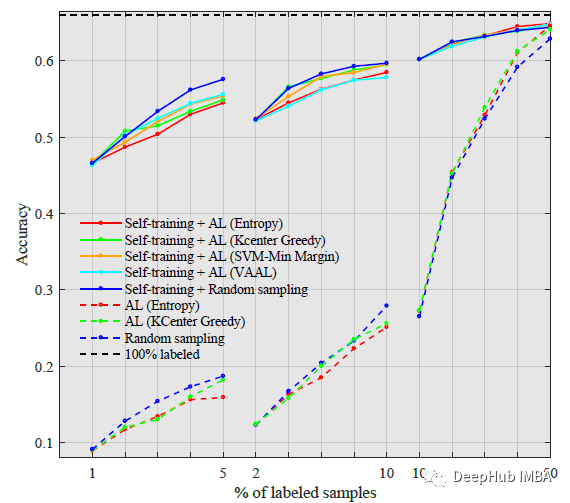
上图为CIFAR-100在低预算的情况下,自监督的预训练大大减少了所需的标签数量。
当接近有包含50%标记数据时,无自监督训练的AL与自监督训练的同类方法的性能相当,这意味着当预算增加时,自监督训练的影响会减少。但是无论是否使用自监督的预训练,随机抽样都优于低预算的主动学习方法。
这些趋势与CIFAR-10的趋势相似。
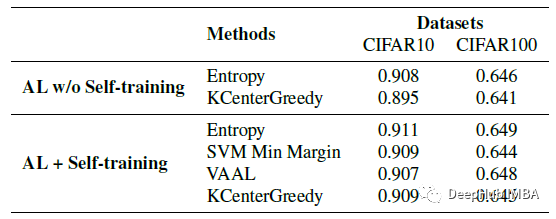
当标注数据越来越多,AL和AL+ Self-training之间的性能差距减小了。
Tiny ImageNet
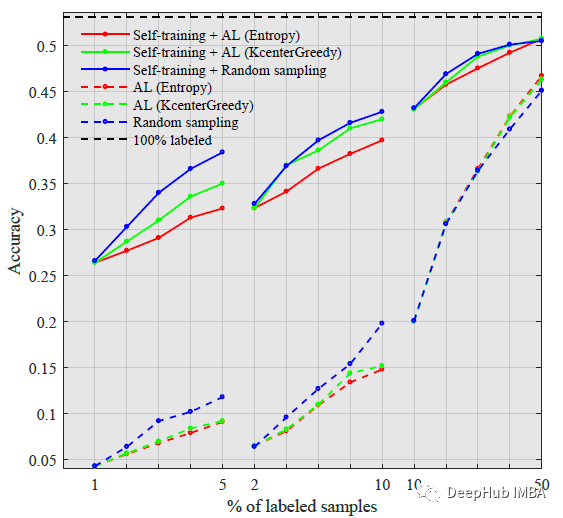
自监督的预训练在低预算方案中大大减少了所需的标记。
与CIFAR数据集不同的是,AL需要超过50%的标记来缩小它们与自监督训练的性能差距。在采用自监督训练的方法中,随机抽样的效果较好。但是与上面一样增加标记数据可以缩小与AL方法的性能差距。
两个实验结果都表明:在主动学习框架中,低预算的情况下SimSiam帮助很大。在高预算下,从头训练和SimSiam之间的性能差距缩小了。
最后是论文和引用
Reference
[2021 ICCVW] [SimSiam+AL]Reducing Label Effort: Self-Supervised Meets Active Learning arxiv :2108.11458
作者:Sik-Ho Tsang