
🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
在本章中,我们将研究词嵌入以及它们如何帮助我们计算文本片段之间的相似性。词嵌入是自然语言处理中用于将词表示为n维空间中的向量的强大技术。这个空间的有趣之处在于,具有相似含义的单词会彼此靠近。
我们将在这里使用的主要模型是 Google 的 Word2vec 的一个版本。这不是一个深度神经模型。事实上,它只不过是一个从词到向量的大查找表,因此根本就不是一个模型。Word2vec 嵌入是作为训练网络从上下文中预测来自谷歌新闻的句子的单词的副作用而产生的。此外,它可能是最著名的嵌入示例,而嵌入是深度学习中的一个重要概念。
一旦你开始寻找它们,具有语义属性的高维空间就会开始在深度学习中无处不在。我们可以通过将电影投影到高维空间(第 4 章)或仅使用二维(第 13章)创建手写数字映射来构建电影推荐器。图像识别网络将图像投影到一个空间中,使相似的图像彼此靠近(第 10 章)。
在当前章节中,我们将只关注词嵌入。我们将从使用预训练的词嵌入模型来计算词相似度开始,然后展示一些有趣的 Word2vec 数学。然后我们将探索如何可视化这些高维空间。
接下来,我们将看看如何利用 Word2vec 等词嵌入的语义属性进行特定领域的排名。我们将单词及其嵌入视为它们所代表的实体,并产生一些有趣的结果。我们将从在 Word2vec 嵌入中查找实体类开始——在本例中为国家。然后,我们将展示如何针对这些国家/地区对术语进行排名,以及如何在地图上可视化这些结果。
词嵌入是一种将词映射到向量的强大方法,并且有很多用途。它们通常用作文本的预处理步骤。
本章有两个 Python 笔记本:
03.1 使用预训练的词嵌入
03.2 使用 word2vec 余弦距离的特定领域排名
3.1 使用预训练的词嵌入来查找词相似度
问题
您需要确定两个单词是否相似但不相等,例如,当您验证用户输入并且您不希望要求用户准确输入预期单词时。
解决方案
您可以使用预训练的词嵌入模型。我们将
gensim
在此示例中使用一个有用的库,通常用于 Python 中的主题建模。
第一步是获取预训练模型。互联网上有许多预训练模型可供下载,但我们将使用 Google News 之一。它嵌入了 300 万个单词,并接受了从谷歌新闻档案中提取的大约 1000 亿个单词的训练。下载它需要一段时间,所以我们将文件缓存到本地:
MODEL = 'GoogleNews-vectors-negative300.bin'
path = get_file(MODEL + '.gz',
'https://s3.amazonaws.com/dl4j-distribution/%s.gz' % MODEL)
unzipped = os.path.join('generated', MODEL)
if not os.path.isfile(unzipped):
with open(unzipped, 'wb') as fout:
zcat = subprocess.Popen(['zcat'],
stdin=open(path),
stdout=fout
)
zcat.wait()
从 GoogleNews-vectors-negative300.bin.gz 下载数据 1647050752/1647046227 [==============================] - 71s 0us/步
现在我们已经下载了模型,我们可以将它加载到内存中。该模型非常大,这将需要大约 5 GB 的 RAM:
model = gensim.models.KeyedVectors.load_word2vec_format(MODEL, binary=True)
模型加载完成后,我们可以使用它来查找相似词:
model.most_similar(positive=['espresso'])
[(u'cappuccino', 0.6888186931610107),
(u'mocha', 0.6686209440231323),
(u'coffee', 0.6616827249526978),
(u'latte', 0.6536752581596375),
(u'caramel_macchiato', 0.6491267681121826),
(u'ristretto', 0.6485546827316284),
(u'espressos', 0.6438628435134888),
(u'macchiato', 0.6428250074386597),
(u'chai_latte', 0.6308028697967529),
(u'espresso_cappuccino', 0.6280542612075806)]
讨论
词嵌入将一个n维向量与词汇表中的每个词相关联,使得相似词彼此靠近。寻找相似词只是一种最近邻搜索,即使在高维空间中也有有效的算法。
稍微简化一下,Word2vec 嵌入是通过训练神经网络从上下文中预测单词而获得的。因此,我们要求网络预测它应该在一系列片段中为 X 选择哪个词;例如,“咖啡厅提供的 X 真的把我吵醒了。”
这样,可以插入相似模式的单词将获得彼此接近的向量。我们不关心实际任务,只关心分配的权重,这是我们训练这个网络的副作用。
在本书的后面,我们将看到如何使用词嵌入将词输入神经网络。将 300 维的嵌入向量输入网络比单热编码的 300 万维嵌入向量更可行。此外,使用预训练词嵌入的网络不必学习词之间的关系,而是可以立即从手头的实际任务开始。
3.2 Word2vec 数学
问题
如何自动回答“A 之于 B,C 之于什么”形式的问题?
解决方案
使用 Word2vec 模型的语义属性。该
gensim
库使这变得相当简单:
def A_is_to_B_as_C_is_to(a, b, c, topn=1):
a, b, c = map(lambda x:x if type(x) == list else [x], (a, b, c))
res = model.most_similar(positive=b + c, negative=a, topn=topn)
if len(res):
if topn == 1:
return res[0][0]
return [x[0] for x in res]
return None
我们现在可以将其应用于任意词——例如,找出与“国王”相关的内容,就像“儿子”与“女儿”相关的方式一样:
A_is_to_B_as_C_is_to('man','woman','king')
u'queen'
我们还可以使用这种方法来查找选定国家的首都:
for country in 'Italy', 'France', 'India', 'China':
print('%s is the capital of %s' %
(A_is_to_B_as_C_is_to('Germany', 'Berlin', country), country))
Rome is the capital of Italy
Paris is the capital of France
Delhi is the capital of India
Beijing is the capital of China
或查找公司的主要产品(注意这些嵌入中使用的任何数字的 # 占位符):
for company in 'Google', 'IBM', 'Boeing', 'Microsoft', 'Samsung':
products = A_is_to_B_as_C_is_to(
['Starbucks', 'Apple'], ['Starbucks_coffee', 'iPhone'], company, topn=3)
print('%s -> %s' %
(company, ', '.join(products)))
Google -> personalized_homepage, app, Gmail
IBM -> DB2, WebSphere_Portal, Tamino_XML_Server
Boeing -> Dreamliner, airframe, aircraft
Microsoft -> Windows_Mobile, SyncMate, Windows
Samsung -> MM_A###, handset, Samsung_SCH_B###
讨论
正如我们在上一步中看到的,与单词相关联的向量对单词的含义进行编码——彼此相似的单词具有彼此接近的向量。事实证明,词向量之间的差异也编码了词之间的差异,所以如果我们将“儿子”这个词的向量减去“女儿”这个词的向量,我们最终会得到一个差异,可以解释为“从男变女。” 如果我们将此差异添加到单词“king”的向量中,我们最终会接近单词“queen”的向量:
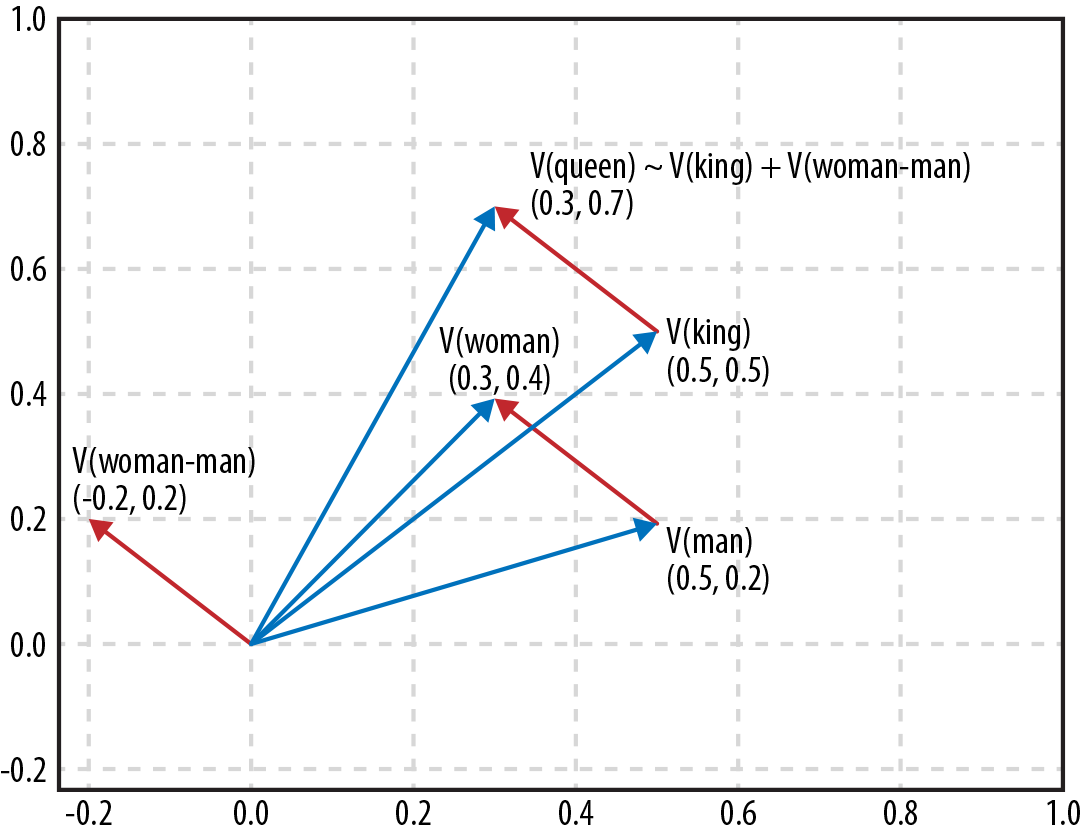
该
most_similar
方法采用一个或多个肯定词和一个或多个否定词。它查找相应的向量,然后从正数中减去负数,并返回具有最接近结果向量的向量的单词。
因此,为了回答“A 之于 B 就像 C 之于?”这个问题。我们想从 B 中减去 A,然后添加 C,或者
most_similar
用
positive = [B, C]
and调用
negative = [A]
。该示例
A_is_to_B_as_C_is_to
为此行为添加了两个小功能。如果我们只请求一个示例,它将返回一个项目,而不是一个包含一个项目的列表。同样,我们可以返回 A、B 和 C 的列表或单个项目。
能够提供列表在产品示例中被证明是有用的。我们要求每家公司提供三种产品,这使得获得完全正确的向量比我们只要求一种更重要。通过提供“Starbucks”和“Apple”,我们得到了“is a product of”概念的更准确向量。
3.3 可视化词嵌入
问题
您想深入了解词嵌入如何划分一组对象。
解决方案
300 维空间很难浏览,但幸运的是,我们可以使用一种称为t 分布随机邻域嵌入(t-SNE) 的算法将更高维空间折叠成更易于理解的空间,例如二维空间。
假设我们想看看三组术语是如何划分的。我们将选择国家、运动和饮料:
beverages = ['espresso', 'beer', 'vodka', 'wine', 'cola', 'tea']
countries = ['Italy', 'Germany', 'Russia', 'France', 'USA', 'India']
sports = ['soccer', 'handball', 'hockey', 'cycling', 'basketball', 'cricket']
items = beverages + countries + sports
现在让我们查找它们的向量:
item_vectors = [(item, model[item])
for item in items
if item in model]
我们现在可以使用 t-SNE 在 300 维空间中找到簇:
vectors = np.asarray([x[1] for x in item_vectors])
lengths = np.linalg.norm(vectors, axis=1)
norm_vectors = (vectors.T / lengths).T
tsne = TSNE(n_components=2, perplexity=10,
verbose=2).fit_transform(norm_vectors)
让我们使用 matplotlib 在一个漂亮的散点图中显示结果:
x=tsne[:,0]
y=tsne[:,1]
fig, ax = plt.subplots()
ax.scatter(x, y)
for item, x1, y1 in zip(item_vectors, x, y):
ax.annotate(item[0], (x1, y1))
plt.show()
结果是:

讨论
t-SNE 是一个聪明的算法;你给它一组高维空间中的点,它会迭代地尝试找到在低维空间(通常是平面)上的最佳投影,以尽可能地保持点之间的距离。因此,它非常适合可视化更高维度,如(词)嵌入。
对于更复杂的情况,可以使用
perplexity
参数。这个变量松散地决定了局部精度和整体精度之间的平衡。将其设置为较低的值会创建局部准确的小集群;将其设置得更高会导致更多的局部扭曲,但整体集群会更好。
3.4 在嵌入中查找实体类
问题
在高维空间中,通常存在仅包含一类实体的子空间。你如何找到这些空间?
解决方案
在一组示例和反例上应用支持向量机 (SVM)。例如,让我们在 Word2vec 空间中查找国家/地区。我们将首先再次加载模型并探索类似于国家德国的事物:
model = gensim.models.KeyedVectors.load_word2vec_format(MODEL, binary=True)
model.most_similar(positive=['Germany'])
[(u'Austria', 0.7461062073707581),
(u'German', 0.7178748846054077),
(u'Germans', 0.6628648042678833),
(u'Switzerland', 0.6506867408752441),
(u'Hungary', 0.6504981517791748),
(u'Germnay', 0.649348258972168),
(u'Netherlands', 0.6437495946884155),
(u'Cologne', 0.6430779099464417)]
如您所见,附近有许多国家,但“德国”之类的词和德国城市的名称也出现在列表中。我们可以尝试通过将许多国家的向量相加而不是仅仅使用德国来构建一个最能代表“国家”概念的向量,但仅此而已。嵌入空间中的国家概念不是一个点,而是一个形状。我们需要的是一个真正的分类器。
支持向量机已被证明对此类分类任务有效。Scikit-learn 有一个易于部署的解决方案。第一步是建立一个训练集。对于这个食谱来说,获得正面的例子并不难,因为只有这么多的国家:
positive = ['Chile', 'Mauritius', 'Barbados', 'Ukraine', 'Israel',
'Rwanda', 'Venezuela', 'Lithuania', 'Costa_Rica', 'Romania',
'Senegal', 'Canada', 'Malaysia', 'South_Korea', 'Australia',
'Tunisia', 'Armenia', 'China', 'Czech_Republic', 'Guinea',
'Gambia', 'Gabon', 'Italy', 'Montenegro', 'Guyana', 'Nicaragua',
'French_Guiana', 'Serbia', 'Uruguay', 'Ethiopia', 'Samoa',
'Antarctica', 'Suriname', 'Finland', 'Bermuda', 'Cuba', 'Oman',
'Azerbaijan', 'Papua', 'France', 'Tanzania', 'Germany' … ]
有更多的正面例子当然更好,但是对于这个例子来说,使用 40-50 会让我们很好地了解解决方案是如何工作的。
我们还需要一些反面例子。我们直接从 Word2vec 模型的通用词汇表中抽取这些样本。我们可以不走运,画一个国家,把它放在反例中,但是考虑到我们模型中有 300 万个单词,而世界上只有不到 200 个国家,我们确实必须非常不走运:
negative = random.sample(model.vocab.keys(), 5000)
negative[:4]
[u'Denys_Arcand_Les_Invasions',
u'2B_refill',
u'strained_vocal_chords',
u'Manifa']
现在我们将根据正例和负例创建一个带标签的训练集。我们将使用
1
作为一个国家的标签,而
0
不是一个国家。我们将遵循将训练数据存储在变量中
X
并将标签存储在变量中的约定
y
:
labelled = [(p, 1) for p in positive] + [(n, 0) for n in negative]
random.shuffle(labelled)
X = np.asarray([model[w] for w, l in labelled])
y = np.asarray([l for w, l in labelled])
让我们训练模型。我们将留出一小部分数据来评估我们的表现:
TRAINING_FRACTION = 0.7
cut_off = int(TRAINING_FRACTION * len(labelled))
clf = svm.SVC(kernel='linear')
clf.fit(X[:cut_off], y[:cut_off])
由于我们的数据集相对较小,即使在功能不是很强大的计算机上,训练也应该几乎立即发生。我们可以通过查看模型对 eval 集的位进行正确预测的次数来了解我们的工作情况:
res = clf.predict(X[cut_off:])
missed = [country for (pred, truth, country) in
zip(res, y[cut_off:], labelled[cut_off:]) if pred != truth]
100 - 100 * float(len(missed)) / len(res), missed
您获得的结果将在一定程度上取决于所选的正面国家以及您碰巧抽取了哪些负面样本。我通常会得到一个它错过的国家的列表——通常是因为国家名称也意味着其他东西,比如约旦,但那里也有一些真正的遗漏。精度达到99.9%左右。
我们现在可以对所有单词运行分类器以提取国家:
res = []
for word, pred in zip(model.index2word, all_predictions):
if pred:
res.append(word)
if len(res) == 150:
break
random.sample(res, 10)
[u'Myanmar',
u'countries',
u'Sri_Lanka',
u'Israelis',
u'Australia',
u'Pyongyang',
u'New_Hampshire',
u'Italy',
u'China',
u'Philippine']
结果相当不错,虽然并不完美。例如,“国家”一词本身就被归类为国家,大陆或美国各州等实体也是如此。
讨论
支持向量机是在词嵌入等高维空间中查找类的有效工具。他们通过尝试找到将正例与负例分开的超平面来工作。
Word2vec 中的国家/地区都有些接近,因为它们共享语义方面。支持向量机帮助我们找到国家的云并提出边界。下图在两个维度上对此进行了可视化:
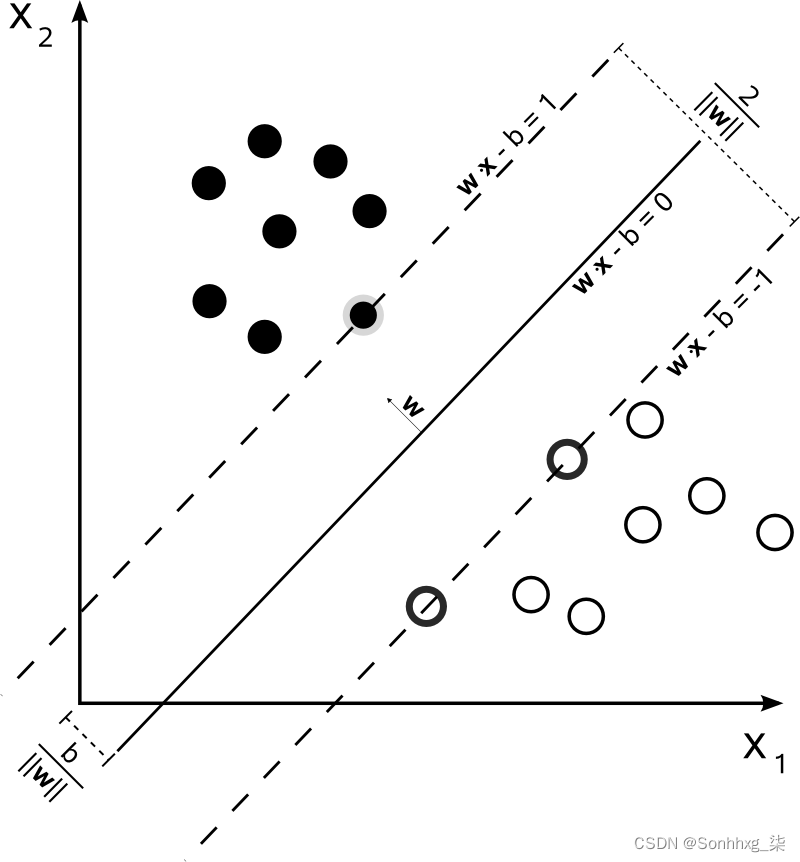
支持向量机可用于机器学习中的各种自组织分类器,因为即使维度数大于样本数,它们也是有效的,就像在这种情况下一样。300 个维度可以让模型过拟合数据,但是由于 SVM 试图找到一个简单的模型来拟合数据,我们仍然可以从小到几十个示例的数据集中进行泛化。
取得的结果相当不错,但值得注意的是,在我们有 300 万个负例的情况下,99.7% 的精度仍然会给我们 9000 个误报,淹没实际国家。
3.5 计算类内的语义距离
问题
对于给定的标准,你如何从一个类中找到最相关的项目?
解决方案
给定一个类,例如国家,我们可以通过查看相对距离,根据标准对该类的成员进行排名:
country_to_idx = {country['name']: idx for idx, country in enumerate(countries)}
country_vecs = np.asarray([model[c['name']] for c in countries])
country_vecs.shape
(184, 300)
我们现在可以像以前一样将国家的向量提取到与国家一致的
numpy
数组中:
countries = list(country_to_cc.keys())
country_vecs = np.asarray([model[c] for c in countries])
快速检查一下哪些国家最像加拿大:
dists = np.dot(country_vecs, country_vecs[country_to_idx['Canada']])
for idx in reversed(np.argsort(dists)[-8:]):
print(countries[idx], dists[idx])
Canada 7.5440245
New_Zealand 3.9619699
Finland 3.9392405
Puerto_Rico 3.838145
Jamaica 3.8102934
Sweden 3.8042784
Slovakia 3.7038736
Australia 3.6711009
加勒比国家有些出人意料,考虑到斯洛伐克和芬兰出现在名单上,很多关于加拿大的新闻肯定与曲棍球有关,但除此之外看起来也不无道理。
让我们换个角度,对一组国家的任意术语进行一些排名。对于每个国家,我们将计算国家名称与我们想要排名的术语之间的距离。与该术语“更接近”的国家/地区与该术语更相关:
def rank_countries(term, topn=10, field='name'):
if not term in model:
return []
vec = model[term]
dists = np.dot(country_vecs, vec)
return [(countries[idx][field], float(dists[idx]))
for idx in reversed(np.argsort(dists)[-topn:])]
例如:
rank_countries('cricket')
[('Sri_Lanka', 5.92276668548584),
('Zimbabwe', 5.336524486541748),
('Bangladesh', 5.192488670349121),
('Pakistan', 4.948408126831055),
('Guyana', 3.9162840843200684),
('Barbados', 3.757995128631592),
('India', 3.7504401206970215),
('South_Africa', 3.6561498641967773),
('New_Zealand', 3.642028331756592),
('Fiji', 3.608567714691162)]
由于我们使用的 Word2vec 模型是在 Google 新闻上训练的,因此排名器将返回最近新闻中以给定术语最为人所知的国家。印度可能更常被提到板球,但只要它也被其他东西覆盖,斯里兰卡仍然可以获胜。
讨论
在我们将不同类别的成员投影到相同维度的空间中,我们可以使用跨类别距离作为亲和度的度量。Word2vec 并不能完全代表一个概念空间(“约旦”这个词可以指河流、国家或人),但它足以很好地根据各种概念的相关性对国家进行排名。
在构建推荐系统时经常采用类似的方法。例如,对于 Netflix 挑战赛,一种流行的策略是使用用户对电影的评分作为将用户和电影投射到共享空间中的一种方式。然后期望与用户接近的电影被该用户高度评价。
在我们有两个不相同的空间的情况下,如果我们可以计算投影矩阵从一个空间到另一个空间,我们仍然可以使用这个技巧。如果我们有足够多的候选人,他们在这两个空间中的位置我们都知道,这是可能的。
3.6 在地图上可视化国家数据
问题
您如何通过地图上的实验将国家/地区排名形象化?
解决方案
GeoPandas 是在地图上可视化数字数据的完美工具。
这个漂亮的库结合了 Pandas 的强大功能和地理原语,并预装了一些地图。让我们加载世界:
world = gpd.read_file(gpd.datasets.get_path('naturalearth_lowres'))
world.head()
这向我们展示了一组国家的一些基本信息。
world
我们可以根据我们的
rank_countries
函数向对象添加一列:
def map_term(term):
d = {k.upper(): v for k, v in rank_countries(term,
topn=0,
field='cc3')}
world[term] = world['iso_a3'].map(d)
world[term] /= world[term].max()
world.dropna().plot(term, cmap='OrRd')
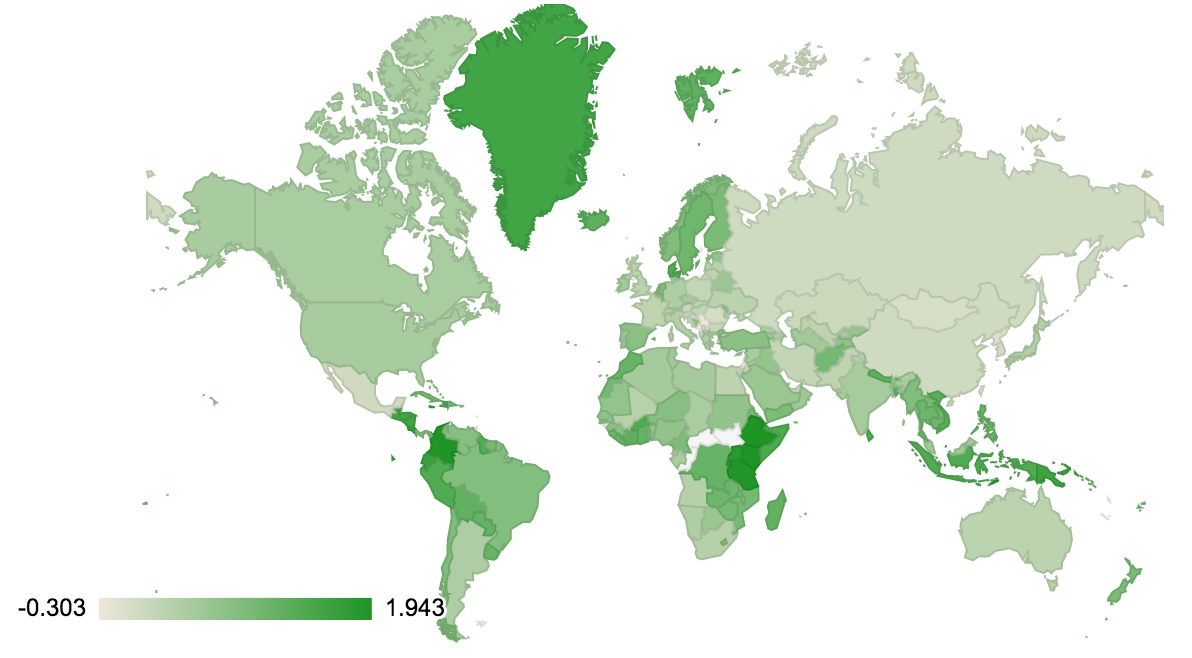
map_term('coffee')
例如,这很好地绘制了咖啡地图,突出了咖啡消费国和咖啡生产国。
讨论
数据可视化是机器学习的一项重要技术。能够查看数据,无论是输入还是某些算法的结果,都可以让我们快速发现异常。格陵兰岛的人真的喝那么多咖啡吗?或者我们是否因为“格陵兰咖啡”(爱尔兰咖啡的变体)而看到了人工制品?而非洲中部的那些国家——他们真的不喝也不生产咖啡吗?还是我们没有关于它们的数据,因为它们没有出现在我们的嵌入中?
GeoPandas 是分析地理编码信息的完美工具,它建立在 Pandas 的一般数据能力之上,我们将在第 6 章中看到更多内容。
版权归原作者 Sonhhxg_柒 所有, 如有侵权,请联系我们删除。