
使用机器学习预测2022世界杯
文章目录
项目说明
- 本项目是基于Kaggle开源的Baseline进行调整及优化,并对baseline进行逐行讲解。
- 本项目所使用的数据集为国际足联世界排名1992-2022以及1872年至2022年国际足球成绩。
- 在本项目中,我们将问题变为分类问题,即我们最后模型的目标是预测主队的胜率和客场的平局/胜率。
- 为了去除客场球队的优势,在项目中预测了客场和主场球队的变化结果(因为世界杯没有主场优势),并使用两个预测的平均值作为概率。
- 有需要的同学请点击超链接进行下载。
数据集说明
1872年至2022年国际足球成绩
- 该数据集包括从 1872 年的第一场正式比赛到 2022 年的44,152场国际足球比赛结果。
- 比赛范围从FIFA世界杯到FIFI野生杯到常规友谊赛。
- 这些比赛严格来说是男子的正式国际比赛,数据不包括奥运会或至少有一支球队是国家B队,U-23或联赛选择球队的比赛。
results.csv包括以下列:
- date- 比赛日期
- home_team- 主队名称
- away_team- 客队名称
- home_score- 全职主队得分,包括加时赛,不包括点球大战
- away_score- 全场客队得分,包括加时赛,不包括点球大战
- tournament- 比赛名称
- city- 比赛所在的城市/城镇/行政单位的名称
- country- 比赛所在国的名称
- neutral- TRUE/FALSE 列,指示比赛是否在中立场地进行
shootouts.csv包括以下列:
- date- 比赛日期
- home_team- 主队名称
- away_team- 客队名称
- winner- 点球大战获胜者
国际足联世界排名1992-2022
- country_full— 国家全名
- country_abrv— 国家缩写
- rank — 当前国家/地区排名
- total_points— 当前总分
- previous_points— 上次评分的总分
- rank_change — 排名变化
- confederation— 国际足联联合会
- rank_date— 评级计算日期
数据分析及预处理
数据准备
#解压数据集
!unzip -d datasets/international-football-results-from-1872-to-20171872年至2022年国际足球成绩.zip
!unzip -d datasets/fifaworldranking 国际足联世界排名1992-2022.zip
对1872年至2022年国际足球成绩进行分析和预处理
导入1872年至2022年国际足球成绩中的result.csv
import pandas as pd
import numpy as np
import re
df = pd.read_csv("datasets/international-football-results-from-1872-to-2017/results.csv")
df.head()
我们先大概预览一下数据,知道其大概结构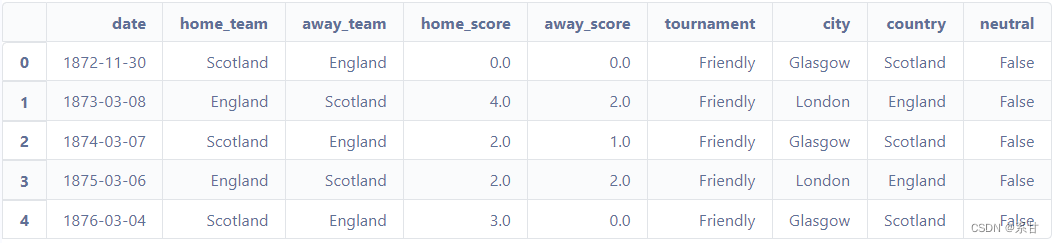
查看下数据的基本信息
df.info()

- 可以发现data是表示日期的,但它并不是日期的格式,因此我们预处理的时候需将它修改为日期的格式
- 这个表格中只有两列是连续型特征,其余的特征都是离散型的
查看下缺失值
#缺失值查看、
df.isna().sum()
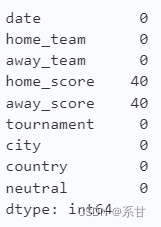
- 可以发现有两列特征是同时含有40个缺失值的。
- 而这两列特征代表的恰好是我们最重要的分数特征。
- 没有分数特征,我们对其就不能进行接下来的建模,因此我们要剔除含有分数缺失的样本。
剔除含有分数缺失的样本及修改date格式
#删除缺失值所在的行
df.dropna(inplace=True)#将日期列的格式转换为日期格式
df["date"]= pd.to_datetime(df["date"])
但是这样直接运行会报错,因为运行之后我们发现,在date这一列中含有’2022-19-22’这个字符串(并不符合正常日期逻辑),因此我们要先将含有该字符串的行剔除再对数据进行处理。
df = df.drop(df[df['date']=='2022-19-22'].index,axis=0)
我们使用的数据集将是2018年国际足联奥运会,从2018年世界杯后到2022年世界杯前的最后一场比赛。这个想法是为了分析世界杯准备和分类阶段的比赛情况。
因此,我们要对数据集进行筛选
- 我们先查看一下2022年最后几场的情况吧
df.sort_values("date").tail()
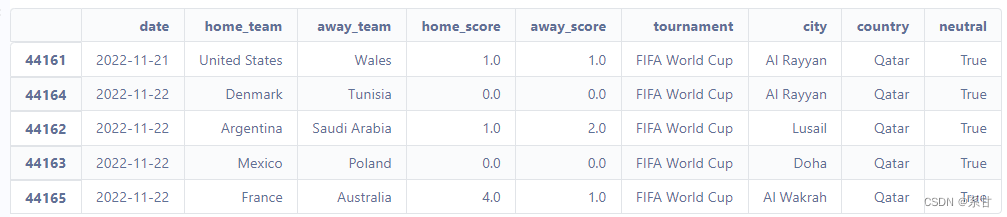
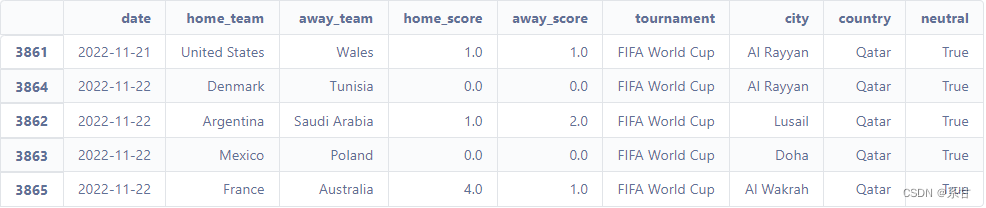
- 筛选出2018年8月1日以后的比赛,并重置索引
df = df[(df["date"]>="2018-8-1")].reset_index(drop=True)
df.sort_values('data').tail()
对国际足联世界排名1992-2022的数据集进行分析和预处理
和刚刚一样,我们需要先转换日期格式并抽出2018年8月1日后的数据
rank = pd.read_csv("datasets/fifaworldranking/fifa_ranking-2022-10-06.csv")
rank["rank_date"]= pd.to_datetime(rank["rank_date"])#转换日期格式
rank = rank[(rank["rank_date"]>="2018-8-1")].reset_index(drop=True)#筛选数据集
世界杯上的一些球队在排名数据集中有不同的名字。所以,它需要调整。
rank["country_full"]= rank["country_full"].str.replace("IR Iran","Iran").str.replace("Korea Republic","South Korea").str.replace("USA","United States")
对两表进行merge
接下来,我们要对数据集进行merge,merge是为了得到一个世界杯的数据集及其排名。
- 将日期设置为我们的索引,然后根据国家进行分组,再重新采样每一天的第一条数据作为我们的数据,最后重置索引
- 若是空值的话,我们使用了前向填充的方法。
rank = rank.set_index(['rank_date']).groupby(['country_full'], group_keys=False).resample('D').first().fillna(method='ffill').reset_index()
- 我们选择rank表中的"country_full", “total_points”, “previous_points”, “rank”, “rank_change”, "rank_date"这些特征和df表进行merge
- 并根据左表的date、home_team以及右表的rank_date、country_full进行左右对齐
- 由于左右表有重复的特征列,因此我们只需取其中一个即可,因此我们这里选择将rank_date和country_full进行删除
df_wc_ranked = df.merge(rank[["country_full","total_points","previous_points","rank","rank_change","rank_date"]],
left_on=["date","home_team"], right_on=["rank_date","country_full"]).drop(["rank_date","country_full"], axis=1)
- 我们知道在result.csv中除了有home_team(主队名称)还有away_team(客队名称)
- 上方的merge只是将主队的数据merge到一起,而客队的还没merge,因此我们还需要重新merge一次
- 在这里我们取rank的特征列与上方一致,只是左对齐中的home_team变成了我们的away_team
- 由于刚刚已经合并过一次了,因此再合并的话,会出现很多重复的列名。也为了区分主客队的特征,我们将主队的rank特征列的后缀改为_home,将客队的rank特征列的后缀改为_away
- 最后也是和刚刚一样,剩下的重复特征(例如时间与国家名),我们取其中一个即可
df_wc_ranked = df_wc_ranked.merge(rank[["country_full","total_points","previous_points","rank","rank_change","rank_date"]],
left_on=["date","away_team"], right_on=["rank_date","country_full"],
suffixes=("_home","_away")).drop(["rank_date","country_full"], axis=1)
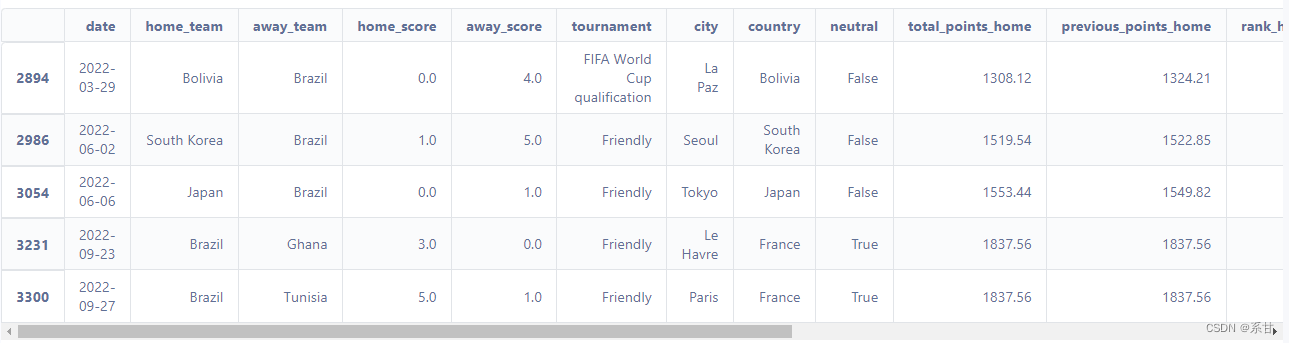
合并完我们抽主客队都为Brazil的部分数据出来看一下
df_wc_ranked[(df_wc_ranked.home_team =="Brazil")|(df_wc_ranked.away_team =="Brazil")].tail()
现在,我们已经准备好了数据,可以根据数据集进行特征工程了
特征工程
- 这是的想法是创造更多对足球比赛胜负有影响的特征
- 我们认为影响的特征可能是以下几个: 1.球队的历史得分 2.球队历史的进球与失球 3.球队的排名 4.球队排名的上升情况 5.排名所面临的进球和损失 6.比赛的重要性(是否友好)
- 因此我们要创建一个功能:判断哪支队赢了,以及他们在比赛中获得了多少分
封装一个判断输赢的函数
df = df_wc_ranked
defresult_finder(home, away):if home > away:return pd.Series([0,3,0])if home < away:return pd.Series([1,0,3])else:return pd.Series([2,1,1])
results = df.apply(lambda x: result_finder(x["home_score"], x["away_score"]), axis=1)
df[["result","home_team_points","away_team_points"]]= results
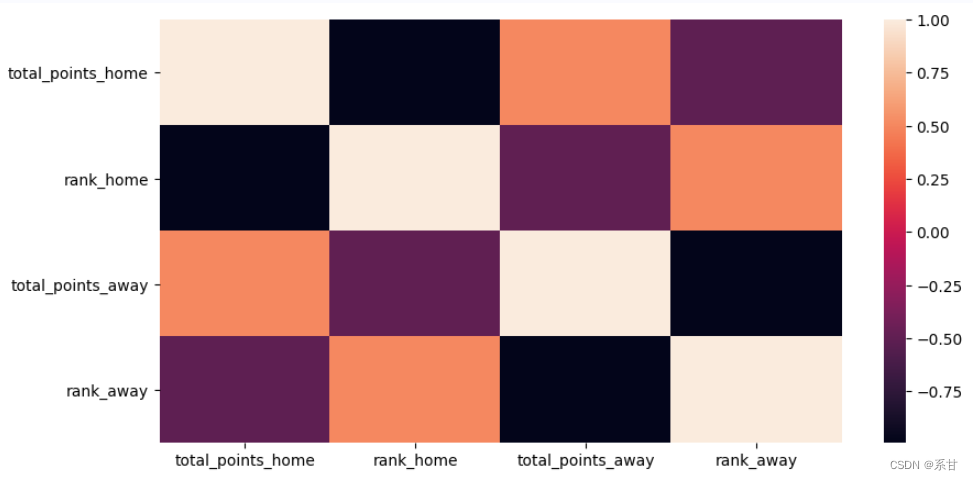
假设的检验
- 比赛积分是赢3分,平1分,输0分,与数据库中已有的排名积分不同。
- 另外,我们认为数据集中的排名积分和同一球队的排名是负相关的,我们应该只使用其中的一个来创建新的特征。
- 以下是对这一假设的检验。
import seaborn as sns
import matplotlib.pyplot as plt
plt.figure(figsize=(15,10))
sns.heatmap(df[["total_points_home","rank_home","total_points_away","rank_away"]].corr())
plt.show()
特征衍生
- 现在,我们需要创建对建模有利的特征
- 例如: 1.排名差异 2.在比赛中赢得的分数与面对的球队排名 3.比赛中的进球差异。所有不属于差异的特征都应该为两支球队(客场和主场)创建。
df["rank_dif"]= df["rank_home"]- df["rank_away"]#排名差异
df["sg"]= df["home_score"]- df["away_score"]#分数差异
df["points_home_by_rank"]= df["home_team_points"]/df["rank_away"]#主场队伍进球与排名的关系
df["points_away_by_rank"]= df["away_team_points"]/df["rank_home"]#客场队伍进球与排名的关系
为了更好的特征衍生,我们将数据集分为主队和客队的数据集,然后合并一起计算它们过去比赛的各种特征。
之后再将它们分离并合并,构造出一个原始的数据集。
这个过程优化了特征衍生
- 先将数据集分成主场与客场的数据集
home_team = df[["date","home_team","home_score","away_score","rank_home","rank_away","rank_change_home","total_points_home","result","rank_dif","points_home_by_rank","home_team_points"]]
away_team = df[["date","away_team","away_score","home_score","rank_away","rank_home","rank_change_away","total_points_away","result","rank_dif","points_away_by_rank","away_team_points"]]
- 由于刚刚merge数据集的时候,对特征列的名字是做了修改的,现在我们要将特征列的名字修改成初始的名字,以便后续的处理
home_team.columns =[h.replace("home_","").replace("_home","").replace("away_","suf_").replace("_away","_suf")for h in home_team.columns]
away_team.columns =[a.replace("away_","").replace("_away","").replace("home_","suf_").replace("_home","_suf")for a in away_team.columns]
- 将它们append到一起进行特征计算
team_stats = home_team.append(away_team)
- 这些列将被用来特征计算
team_stats_raw = team_stats.copy()
现在,我们得到了一个数据集,准备进行进一步的特征衍生。将要衍生的列是:
- Mean goals of the team in World Cup Cycle. --世界杯球队的平均进球数
- Mean goals of the team in last 5 games. --球队最近5场比赛的平均进球数
- Mean goals suffered of the team in World Cup Cycle. --世界杯球队的平均犯规数
- Mean goals suffered of the team in last 5 games. --球队最近5场比赛的平均犯规数
- Mean FIFA Rank that team faced in World Cup Cycle. --球队在世界杯中FIFA平均排名
- Mean FIFA Rank that team faced in last 5 games. --球队在最近5场比赛中FIFA平均排名
- FIFA Points won at the cycle. --FIFA积分
- FIFA Points won in last 5 games. --最近5场FIFA积分
- Mean game points at the Cycle. --比赛得分
- Mean game points at last 5 games. --最近5场比赛积分
- Mean game points by rank faced at the Cycle.
- Mean game points by rank faced at last 5 games.
stats_val =[]for index, row in team_stats.iterrows():
team = row["team"]
date = row["date"]
past_games = team_stats.loc[(team_stats["team"]== team)&(team_stats["date"]< date)].sort_values(by=['date'], ascending=False)
last5 = past_games.head(5)#取出过去五场比赛
goals = past_games["score"].mean()
goals_l5 = last5["score"].mean()
goals_suf = past_games["suf_score"].mean()
goals_suf_l5 = last5["suf_score"].mean()
rank = past_games["rank_suf"].mean()
rank_l5 = last5["rank_suf"].mean()iflen(last5)>0:
points = past_games["total_points"].values[0]- past_games["total_points"].values[-1]#qtd de pontos ganhos
points_l5 = last5["total_points"].values[0]- last5["total_points"].values[-1]else:
points =0
points_l5 =0
gp = past_games["team_points"].mean()
gp_l5 = last5["team_points"].mean()
gp_rank = past_games["points_by_rank"].mean()
gp_rank_l5 = last5["points_by_rank"].mean()
stats_val.append([goals, goals_l5, goals_suf, goals_suf_l5, rank, rank_l5, points, points_l5, gp, gp_l5, gp_rank, gp_rank_l5])
- 将刚刚衍生出来的特征与原表格合并到一起
- 并且重新用full_df去接收
stats_cols =["goals_mean","goals_mean_l5","goals_suf_mean","goals_suf_mean_l5","rank_mean","rank_mean_l5","points_mean","points_mean_l5","game_points_mean","game_points_mean_l5","game_points_rank_mean","game_points_rank_mean_l5"]
stats_df = pd.DataFrame(stats_val, columns=stats_cols)
full_df = pd.concat([team_stats.reset_index(drop=True), stats_df], axis=1, ignore_index=False)
- 再次将合并好的数据集分成主场与客场
home_team_stats = full_df.iloc[:int(full_df.shape[0]/2),:]
away_team_stats = full_df.iloc[int(full_df.shape[0]/2):,:]
- 取出刚刚特征衍生出来的列
home_team_stats = home_team_stats[home_team_stats.columns[-12:]]
away_team_stats = away_team_stats[away_team_stats.columns[-12:]]
- 对其进行重命名(home_代表主场)(away_代表客场)为了统一数据集,需要为每一列添加主场和客场的后缀,之后,数据就可以合并使用了
home_team_stats.columns =['home_'+str(col)for col in home_team_stats.columns]
away_team_stats.columns =['away_'+str(col)for col in away_team_stats.columns]
- 数据合并
match_stats = pd.concat([home_team_stats, away_team_stats.reset_index(drop=True)], axis=1, ignore_index=False)
full_df = pd.concat([df, match_stats.reset_index(drop=True)], axis=1, ignore_index=False)
full_df.columns
看一下现有的特征列
- 为了确定该场比赛是否友好,我们封装一个函数去判断它
deffind_friendly(x):if x =="Friendly":return1else:return0
full_df["is_friendly"]= full_df["tournament"].apply(lambda x: find_friendly(x))
- 并对其进行One-hot编码
full_df = pd.get_dummies(full_df, columns=["is_friendly"])
对特征工程后的数据集进行数据分析
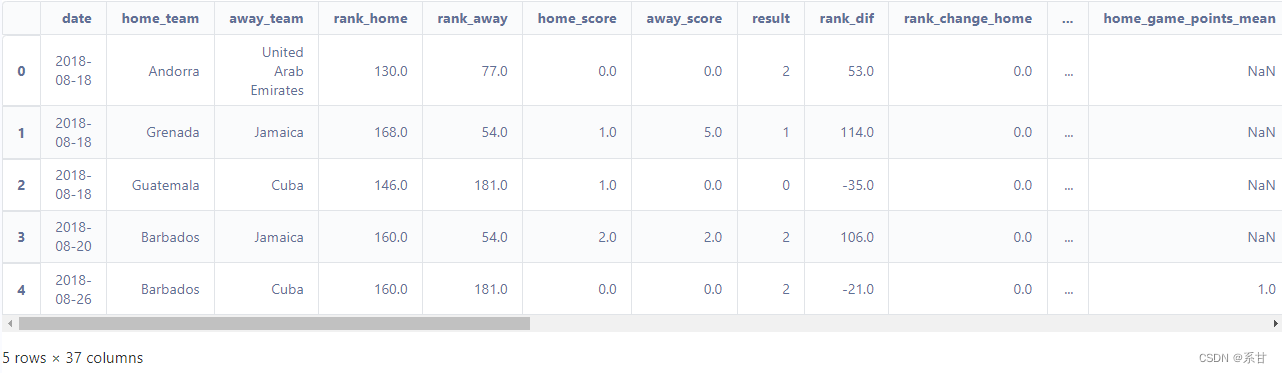
- 在这里,我们只选择有助于我们特征分析的列进行分析
base_df = full_df[["date","home_team","away_team","rank_home","rank_away","home_score","away_score","result","rank_dif","rank_change_home","rank_change_away",'home_goals_mean','home_goals_mean_l5','home_goals_suf_mean','home_goals_suf_mean_l5','home_rank_mean','home_rank_mean_l5','home_points_mean','home_points_mean_l5','away_goals_mean','away_goals_mean_l5','away_goals_suf_mean','away_goals_suf_mean_l5','away_rank_mean','away_rank_mean_l5','away_points_mean','away_points_mean_l5','home_game_points_mean','home_game_points_mean_l5','home_game_points_rank_mean','home_game_points_rank_mean_l5','away_game_points_mean','away_game_points_mean_l5','away_game_points_rank_mean','away_game_points_rank_mean_l5','is_friendly_0','is_friendly_1']]
base_df.head()
- 查询一下缺失值
base_df.isna().sum()
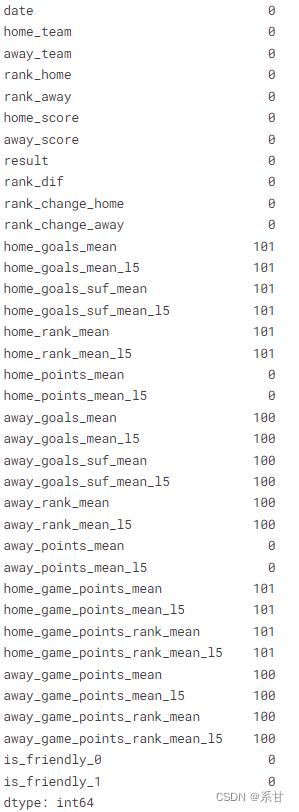
- 我们知道,带有空值的行,是无法计算其平均值的,所以我们需要将有空值的样本剔除
base_df_no_fg = base_df.dropna()
现在,我们需要分析所有创建的特征,检查它们是否具有预测能力。另外,如果它们没有,我们需要创建一些有预测力的特征,比如主客队的差异。为了分析预测能力,我将指定平局作为主队的输球,并将二分类问题。
df = base_df_no_fg
defno_draw(x):if x ==2:return1else:return x
df["target"]= df["result"].apply(lambda x: no_draw(x))
利用小提琴图和箱线图筛选特征
- 接下来我们利用小提琴图以及箱线图来分析特征是否根据目标有不同的分布
- 用散点图来分析相关关系
- 为了图像更直观,我们将抽取一部分特征画在同一个画布,另一部分特征画在下一个画布
data1 = df[list(df.columns[8:20].values)+["target"]]
data2 = df[df.columns[20:]]
- 对特征进行标准化处理
scaled =(data1[:-1]- data1[:-1].mean())/ data1[:-1].std()
scaled["target"]= data1["target"]
violin1 = pd.melt(scaled,id_vars="target", var_name="features", value_name="value")
scaled =(data2[:-1]- data2[:-1].mean())/ data2[:-1].std()
scaled["target"]= data2["target"]
violin2 = pd.melt(scaled,id_vars="target", var_name="features", value_name="value")
- 画data1中的特征小提琴图
plt.figure(figsize=(15,10))
sns.violinplot(x="features", y="value", hue="target", data=violin1,split=True, inner="quart")
plt.xticks(rotation=90)
plt.show()
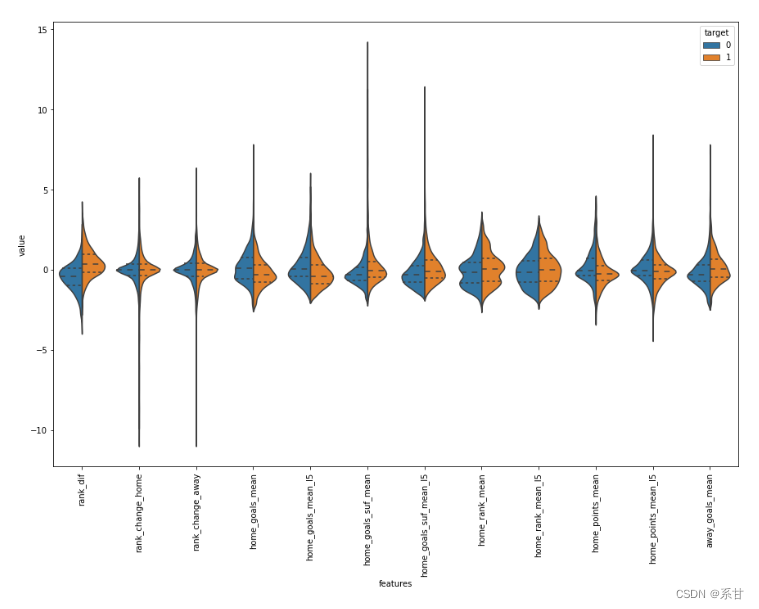
- 画data2的特征小提琴图
plt.figure(figsize=(15,10))
sns.violinplot(x="features", y="value", hue="target", data=violin2,split=True, inner="quart")
plt.xticks(rotation=90)
plt.show()
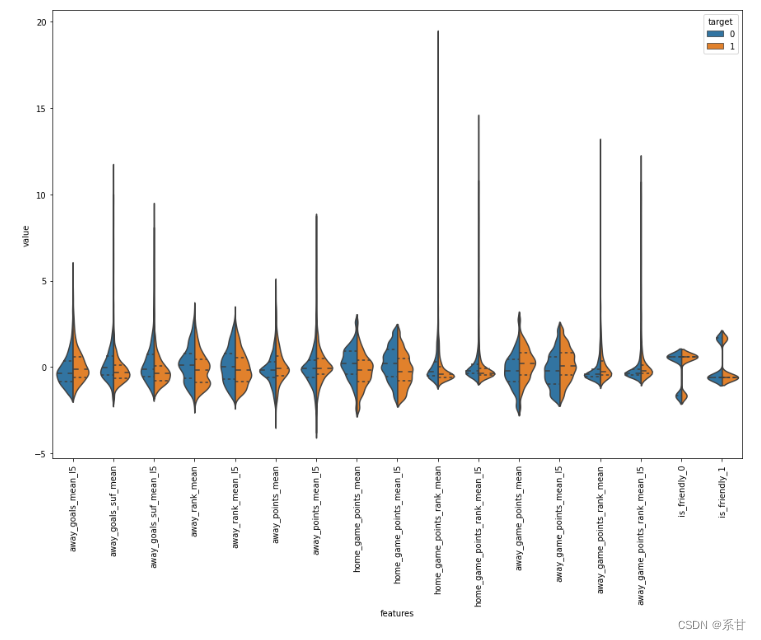
通过这些图,我们发现等级差异是数据唯一好的分离器。但是,我们可以创建一些特征来获得主队和客队之间的差异,并分析它们是否能很好地分离数据。
- 为了更好的探究主客场的差异,我们求出各主客场的特征均值之差,并将其标准化,随后画出它们的小提琴图
dif = df.copy()
dif.loc[:,"goals_dif"]= dif["home_goals_mean"]- dif["away_goals_mean"]
dif.loc[:,"goals_dif_l5"]= dif["home_goals_mean_l5"]- dif["away_goals_mean_l5"]
dif.loc[:,"goals_suf_dif"]= dif["home_goals_suf_mean"]- dif["away_goals_suf_mean"]
dif.loc[:,"goals_suf_dif_l5"]= dif["home_goals_suf_mean_l5"]- dif["away_goals_suf_mean_l5"]
dif.loc[:,"goals_made_suf_dif"]= dif["home_goals_mean"]- dif["away_goals_suf_mean"]
dif.loc[:,"goals_made_suf_dif_l5"]= dif["home_goals_mean_l5"]- dif["away_goals_suf_mean_l5"]
dif.loc[:,"goals_suf_made_dif"]= dif["home_goals_suf_mean"]- dif["away_goals_mean"]
dif.loc[:,"goals_suf_made_dif_l5"]= dif["home_goals_suf_mean_l5"]- dif["away_goals_mean_l5"]
data_difs = dif.iloc[:,-8:]
scaled =(data_difs - data_difs.mean())/ data_difs.std()
scaled["target"]= data2["target"]
violin = pd.melt(scaled,id_vars="target", var_name="features", value_name="value")
plt.figure(figsize=(10,10))
sns.violinplot(x="features", y="value", hue="target", data=violin,split=True, inner="quart")
plt.xticks(rotation=90)
plt.show()
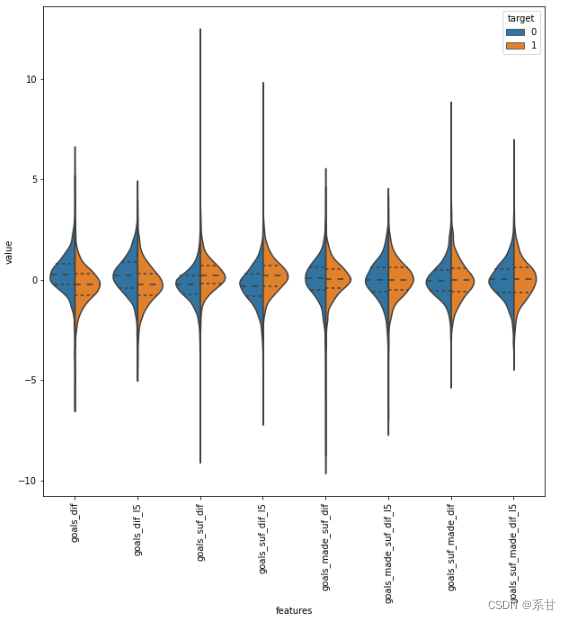
通过该图可以看出,进球数的差异是很好的分离器,犯规数也是。但各队的进球数和失球数之间的差异并不是很好的区分标准
- 那我们现在就筛选出以下5个特征 1. ran_dif2. goals_dif3. goals_dif_l54. goals_suf_dif5. goals_suf_dif_l5
- 接下来,我们还可以创造其它特征,例如:所获分数的差异,排名的差异
dif.loc[:,"dif_points"]= dif["home_game_points_mean"]- dif["away_game_points_mean"]
dif.loc[:,"dif_points_l5"]= dif["home_game_points_mean_l5"]- dif["away_game_points_mean_l5"]
dif.loc[:,"dif_points_rank"]= dif["home_game_points_rank_mean"]- dif["away_game_points_rank_mean"]
dif.loc[:,"dif_points_rank_l5"]= dif["home_game_points_rank_mean_l5"]- dif["away_game_points_rank_mean_l5"]
dif.loc[:,"dif_rank_agst"]= dif["home_rank_mean"]- dif["away_rank_mean"]
dif.loc[:,"dif_rank_agst_l5"]= dif["home_rank_mean_l5"]- dif["away_rank_mean_l5"]
- 此外,我们还可以按等级计算出所进的球和犯规的影响,并检查这种差异
dif.loc[:,"goals_per_ranking_dif"]=(dif["home_goals_mean"]/ dif["home_rank_mean"])-(dif["away_goals_mean"]/ dif["away_rank_mean"])
dif.loc[:,"goals_per_ranking_suf_dif"]=(dif["home_goals_suf_mean"]/ dif["home_rank_mean"])-(dif["away_goals_suf_mean"]/ dif["away_rank_mean"])
dif.loc[:,"goals_per_ranking_dif_l5"]=(dif["home_goals_mean_l5"]/ dif["home_rank_mean"])-(dif["away_goals_mean_l5"]/ dif["away_rank_mean"])
dif.loc[:,"goals_per_ranking_suf_dif_l5"]=(dif["home_goals_suf_mean_l5"]/ dif["home_rank_mean"])-(dif["away_goals_suf_mean_l5"]/ dif["away_rank_mean"])
- 老样子,对新构建的特征进行标准化,然后用小提琴图可视化
data_difs = dif.iloc[:,-10:]
scaled =(data_difs - data_difs.mean())/ data_difs.std()
scaled["target"]= data2["target"]
violin = pd.melt(scaled,id_vars="target", var_name="features", value_name="value")
plt.figure(figsize=(15,10))
sns.violinplot(x="features", y="value", hue="target", data=violin,split=True, inner="quart")
plt.xticks(rotation=90)
plt.show()
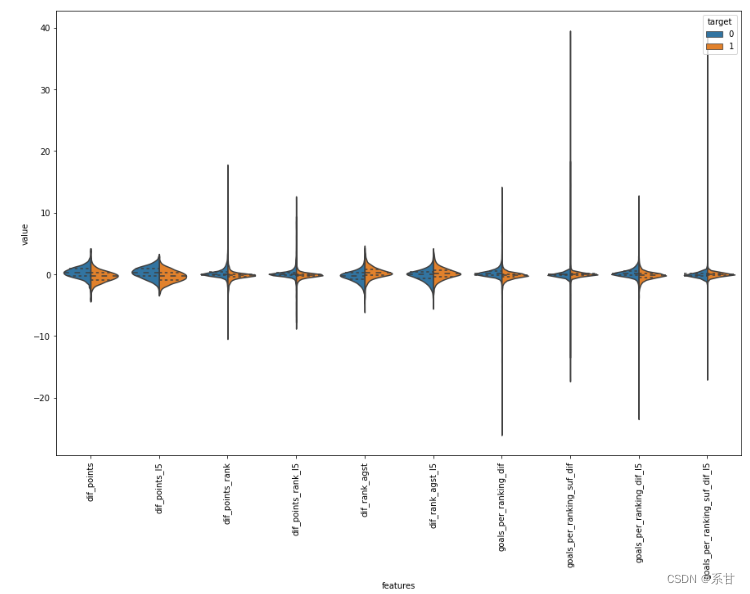
由于数值较低,小提琴图并不能很好的给我们反馈,因此对于这些特征,我们将使用箱线图
plt.figure(figsize=(15,10))
sns.boxplot(x="features", y="value", hue="target", data=violin)
plt.xticks(rotation=90)
plt.show()

- 从中可以看出,Difference of points (所有比赛和最近5场比赛), difference of points by ranking faced (所有比赛和最近5场比赛) 和 difference of rank faced (所有比赛和最近5场比赛)是很好的特征。
- 另外,一些衍生出来的特征具有非常相似的分布,对于这些特征,我们将使用散点图进行分析。
sns.jointplot(data = data_difs, x ='goals_per_ranking_dif', y ='goals_per_ranking_dif_l5', kind="reg")
plt.show()
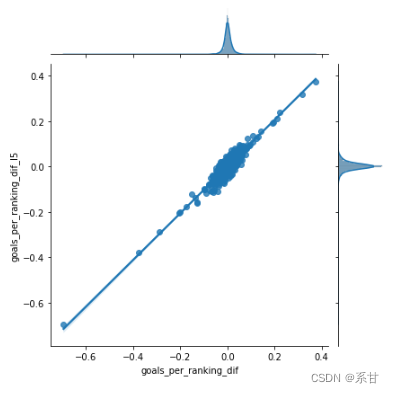
- 由于dif_rank_agst和dif_rank_agst_l5的特征分布非常相似,因此,我们就只使用它的完整版本进行绘图(dif_rank_agst)
sns.jointplot(data = data_difs, x ='dif_rank_agst', y ='dif_rank_agst_l5', kind="reg")
plt.show()
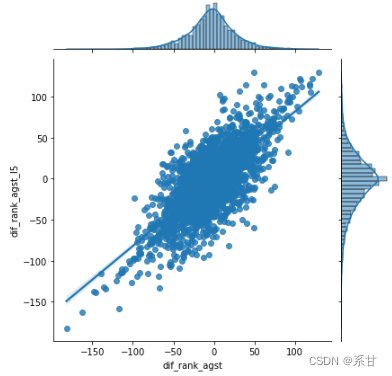
- 针对分数特征
sns.jointplot(data = data_difs, x ='dif_points', y ='dif_points_l5', kind="reg")
plt.show()
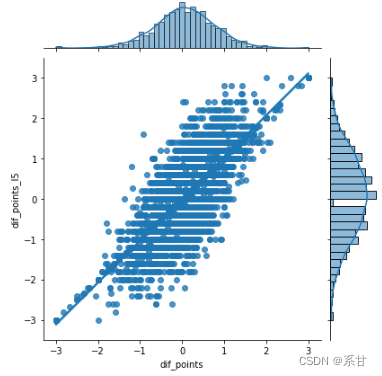
- 针对分数排名特征
sns.jointplot(data = data_difs, x ='dif_points_rank', y ='dif_points_rank_l5', kind="reg")
plt.show()
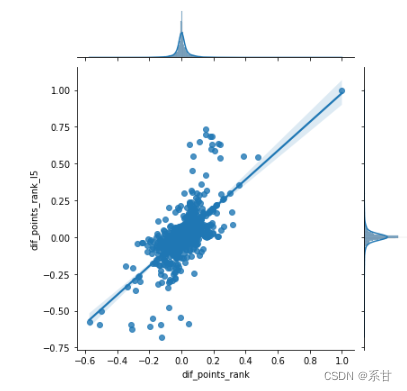
因为排名差异,积分差异,排名平均积分差异这两个版本(所有数据、最近5场比赛)并不那么相似,因此我们决定两个版本都使用。因此,我们特征筛选最后的结果是:
- rank_dif
- goals_dif
- goals_dif_l5
- goals_suf_dif
- goals_suf_dif_l5
- dif_rank_agst
- dif_rank_agst_l5
- goals_per_ranking_dif
- dif_points_rank
- dif_points_rank_l5
- is_friendly
defcreate_db(df):
columns =["home_team","away_team","target","rank_dif","home_goals_mean","home_rank_mean","away_goals_mean","away_rank_mean","home_rank_mean_l5","away_rank_mean_l5","home_goals_suf_mean","away_goals_suf_mean","home_goals_mean_l5","away_goals_mean_l5","home_goals_suf_mean_l5","away_goals_suf_mean_l5","home_game_points_rank_mean","home_game_points_rank_mean_l5","away_game_points_rank_mean","away_game_points_rank_mean_l5","is_friendly_0","is_friendly_1"]
base = df.loc[:, columns]
base.loc[:,"goals_dif"]= base["home_goals_mean"]- base["away_goals_mean"]
base.loc[:,"goals_dif_l5"]= base["home_goals_mean_l5"]- base["away_goals_mean_l5"]
base.loc[:,"goals_suf_dif"]= base["home_goals_suf_mean"]- base["away_goals_suf_mean"]
base.loc[:,"goals_suf_dif_l5"]= base["home_goals_suf_mean_l5"]- base["away_goals_suf_mean_l5"]
base.loc[:,"goals_per_ranking_dif"]=(base["home_goals_mean"]/ base["home_rank_mean"])-(base["away_goals_mean"]/ base["away_rank_mean"])
base.loc[:,"dif_rank_agst"]= base["home_rank_mean"]- base["away_rank_mean"]
base.loc[:,"dif_rank_agst_l5"]= base["home_rank_mean_l5"]- base["away_rank_mean_l5"]
base.loc[:,"dif_points_rank"]= base["home_game_points_rank_mean"]- base["away_game_points_rank_mean"]
base.loc[:,"dif_points_rank_l5"]= base["home_game_points_rank_mean_l5"]- base["away_game_points_rank_mean_l5"]
model_df = base[["home_team","away_team","target","rank_dif","goals_dif","goals_dif_l5","goals_suf_dif","goals_suf_dif_l5","goals_per_ranking_dif","dif_rank_agst","dif_rank_agst_l5","dif_points_rank","dif_points_rank_l5","is_friendly_0","is_friendly_1"]]return model_df
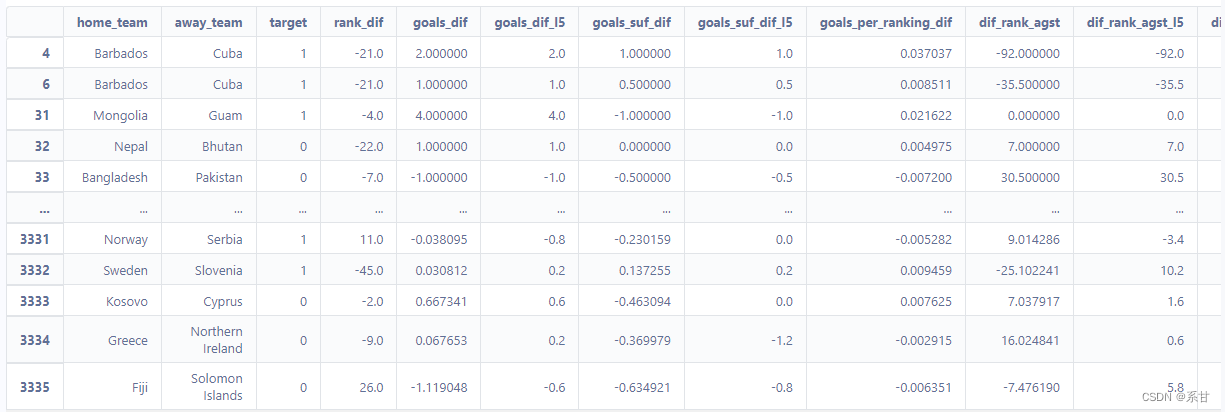
model_db = create_db(df)
model_db
建立预测模型
- 通过上面步骤,我们已经得到了一个具有预测能力的数据集,我们可以开始我们的建模了
- 在本次任务中,我们将建立两个模型(RFC、GBDT)。最终选择召回率最佳的模型作为我们的预测模型。
- 首先我们筛选出我们的特征列和标签列
X = model_db.iloc[:,3:]
y = model_db[["target"]]
- 导入sklearn中集成学习里面的RFC和GBDT
- 导入sklearn中切分数据集以及网格搜索的包
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier
from sklearn.model_selection import train_test_split, GridSearchCV
- 在这里我们选择8:2的比例切分数据集,并设置随机种子数为1
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1)
建立GBDT模型
- 首先建立GBDT模型,并用网格搜索对模型调优
gb = GradientBoostingClassifier(random_state=5)
params ={"learning_rate":[0.01,0.1,0.5],"min_samples_split":[5,10],"min_samples_leaf":[3,5],"max_depth":[3,5,10],"max_features":["sqrt"],"n_estimators":[100,200]}
gb_cv = GridSearchCV(gb, params, cv =3, n_jobs =-1, verbose =False)
gb_cv.fit(X_train.values, np.ravel(y_train))

- 查看一下GBDT的参数配置
gb = gb_cv.best_estimator_
gb

建立RFC模型
- 接下来建立RFC模型并用网格搜索对模型进行调优
params_rf ={"max_depth":[20],"min_samples_split":[10],"max_leaf_nodes":[175],"min_samples_leaf":[5],"n_estimators":[250],"max_features":["sqrt"],}
rf = RandomForestClassifier(random_state=1)
rf_cv = GridSearchCV(rf, params_rf, cv =3, n_jobs =-1, verbose =False)
rf_cv.fit(X_train.values, np.ravel(y_train))

rf = rf_cv.best_estimator_
模型对比
在这里,我们使用混淆矩阵以及ROC曲线进行模型对比
defanalyze(model):
fpr, tpr, _ = roc_curve(y_test, model.predict_proba(X_test.values)[:,1])#test AUC
plt.figure(figsize=(15,10))
plt.plot([0,1],[0,1],'k--')
plt.plot(fpr, tpr, label="test")
fpr_train, tpr_train, _ = roc_curve(y_train, model.predict_proba(X_train.values)[:,1])#train AUC
plt.plot(fpr_train, tpr_train, label="train")
auc_test = roc_auc_score(y_test, model.predict_proba(X_test.values)[:,1])
auc_train = roc_auc_score(y_train, model.predict_proba(X_train.values)[:,1])
plt.legend()
plt.title('AUC score is %.2f on test and %.2f on training'%(auc_test, auc_train))
plt.show()
plt.figure(figsize=(15,10))
cm = confusion_matrix(y_test, model.predict(X_test.values))
sns.heatmap(cm, annot=True, fmt="d")
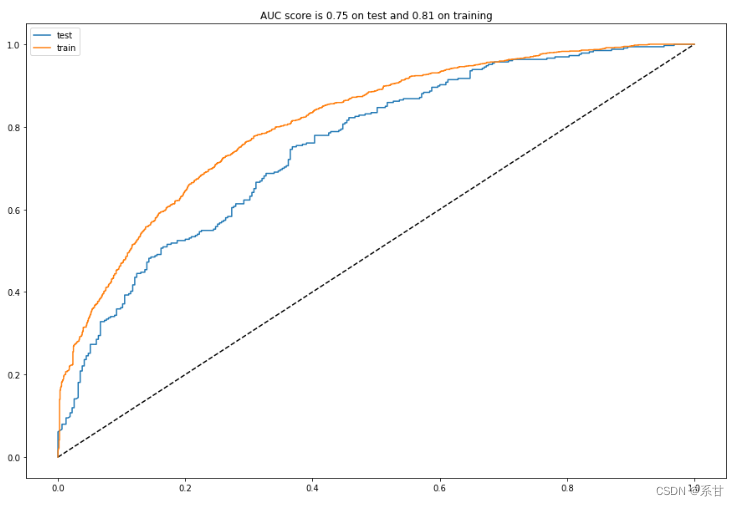
- GBDT
analyze(gb)

analyze(rf)
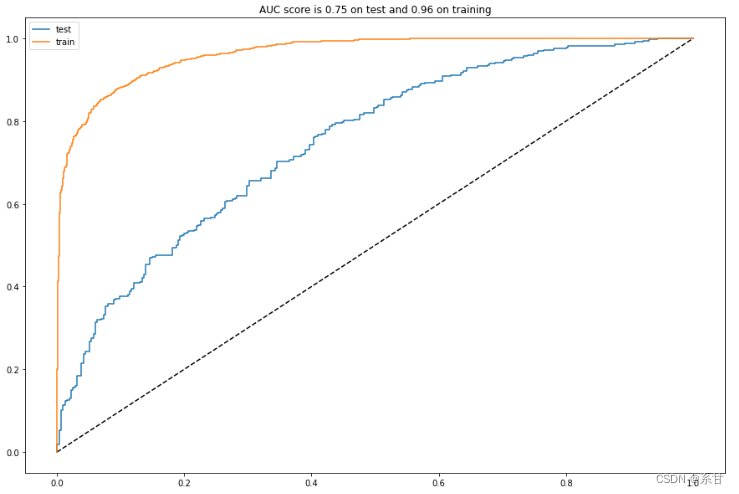
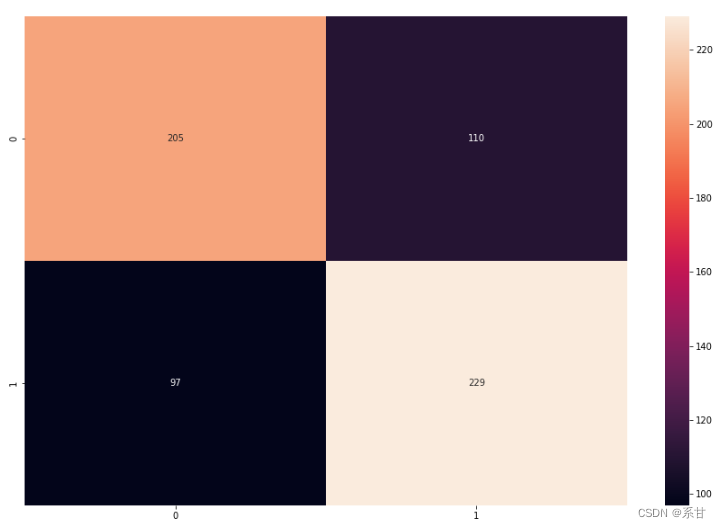
通过分析发现,随机森林模型或许稍微好一点,但似乎泛化能力不行。因此我们将使用GBDT模型
世界杯模拟
数据准备及预处理
- 第一件事是创建FIFA世界杯游戏
- 要做到这一点,我们得先在维基百科中获得球队和小组赛阶段的比赛
- 先使用pd.read_html快速爬取数据
from operator import itemgetter
dfs = pd.read_html(r"https://en.wikipedia.org/wiki/2022_FIFA_World_Cup#Teams")
- 对爬取下来的表格进行预处理
from collections.abc import Iterable
for i inrange(len(dfs)):
df = dfs[i]
cols =list(df.columns.values)ifisinstance(cols[0], Iterable):ifany("Tie-breaking criteria"in c for c in cols):
start_pos = i+1ifany("Match 46"in c for c in cols):
end_pos = i+1
matches =[]
groups =["A","B","C","D","E","F","G","H"]
group_count =0
table ={}
table[groups[group_count]]=[[a.split(" ")[0],0,[]]for a inlist(dfs[start_pos].iloc[:,1].values)]for i inrange(start_pos+1, end_pos,1):iflen(dfs[i].columns)==3:
team_1 = dfs[i].columns.values[0]
team_2 = dfs[i].columns.values[-1]
matches.append((groups[group_count], team_1, team_2))else:
group_count+=1
table[groups[group_count]]=[[a,0,[]]for a inlist(dfs[i].iloc[:,1].values)]
table
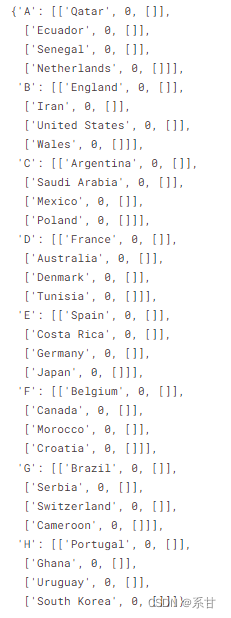
以上,我们存储了各球队在小组赛中的积分以及它在每一场比赛中获胜的概率。特别地,当两支球队的积分相同时,球队获胜概率的均值将被用作平局。
接下来,我们将使用上一场比赛的数据作为每支队伍参赛队伍的数据。如,巴西对塞尔维亚,巴西的数据就是他们在上一场比赛中的数据,塞尔维亚的数据也是如此。
deffind_stats(team_1):#team_1 = "Qatar"
past_games = team_stats_raw[(team_stats_raw["team"]== team_1)].sort_values("date")
last5 = team_stats_raw[(team_stats_raw["team"]== team_1)].sort_values("date").tail(5)
team_1_rank = past_games["rank"].values[-1]
team_1_goals = past_games.score.mean()
team_1_goals_l5 = last5.score.mean()
team_1_goals_suf = past_games.suf_score.mean()
team_1_goals_suf_l5 = last5.suf_score.mean()
team_1_rank_suf = past_games.rank_suf.mean()
team_1_rank_suf_l5 = last5.rank_suf.mean()
team_1_gp_rank = past_games.points_by_rank.mean()
team_1_gp_rank_l5 = last5.points_by_rank.mean()return[team_1_rank, team_1_goals, team_1_goals_l5, team_1_goals_suf, team_1_goals_suf_l5, team_1_rank_suf, team_1_rank_suf_l5, team_1_gp_rank, team_1_gp_rank_l5]deffind_features(team_1, team_2):
rank_dif = team_1[0]- team_2[0]
goals_dif = team_1[1]- team_2[1]
goals_dif_l5 = team_1[2]- team_2[2]
goals_suf_dif = team_1[3]- team_2[3]
goals_suf_dif_l5 = team_1[4]- team_2[4]
goals_per_ranking_dif =(team_1[1]/team_1[5])-(team_2[1]/team_2[5])
dif_rank_agst = team_1[5]- team_2[5]
dif_rank_agst_l5 = team_1[6]- team_2[6]
dif_gp_rank = team_1[7]- team_2[7]
dif_gp_rank_l5 = team_1[8]- team_2[8]return[rank_dif, goals_dif, goals_dif_l5, goals_suf_dif, goals_suf_dif_l5, goals_per_ranking_dif, dif_rank_agst, dif_rank_agst_l5, dif_gp_rank, dif_gp_rank_l5,1,0]
正式开始模拟
现在我们可以开始模拟世界杯了。
由于该模型是二分类模型,只会预测球队1是否会赢。因此,我们需要定义一些标准来判断平均。此外,由于世界杯没有主场优势,所以我们的想法是预测两次比赛,改变球队1和球队2,具有最高概率平均值的球队将为赢家。**在小组赛阶段,如果主队作为1队获胜而作为2队输掉比赛,或者如果主队作为2队获胜而作为1队输掉比赛,该场比赛将被定为平局。
advanced_group =[]
last_group =""for k in table.keys():for t in table[k]:
t[1]=0
t[2]=[]for teams in matches:
draw =False
team_1 = find_stats(teams[1])
team_2 = find_stats(teams[2])
features_g1 = find_features(team_1, team_2)
features_g2 = find_features(team_2, team_1)
probs_g1 = gb.predict_proba([features_g1])
probs_g2 = gb.predict_proba([features_g2])
team_1_prob_g1 = probs_g1[0][0]
team_1_prob_g2 = probs_g2[0][1]
team_2_prob_g1 = probs_g1[0][1]
team_2_prob_g2 = probs_g2[0][0]
team_1_prob =(probs_g1[0][0]+ probs_g2[0][1])/2
team_2_prob =(probs_g2[0][0]+ probs_g1[0][1])/2if((team_1_prob_g1 > team_2_prob_g1)&(team_2_prob_g2 > team_1_prob_g2))|((team_1_prob_g1 < team_2_prob_g1)&(team_2_prob_g2 < team_1_prob_g2)):
draw=Truefor i in table[teams[0]]:if i[0]== teams[1]or i[0]== teams[2]:
i[1]+=1elif team_1_prob > team_2_prob:
winner = teams[1]
winner_proba = team_1_prob
for i in table[teams[0]]:if i[0]== teams[1]:
i[1]+=3elif team_2_prob > team_1_prob:
winner = teams[2]
winner_proba = team_2_prob
for i in table[teams[0]]:if i[0]== teams[2]:
i[1]+=3for i in table[teams[0]]:#adding criterio de desempate (probs por jogo)if i[0]== teams[1]:
i[2].append(team_1_prob)if i[0]== teams[2]:
i[2].append(team_2_prob)if last_group != teams[0]:if last_group !="":print("\n")print("%s组 : "%(last_group))for i in table[last_group]:#adding crieterio de desempate
i[2]= np.mean(i[2])
final_points = table[last_group]
final_table =sorted(final_points, key=itemgetter(1,2), reverse =True)
advanced_group.append([final_table[0][0], final_table[1][0]])for i in final_table:print("%s -------- %d"%(i[0], i[1]))print("\n")print("-"*10+" %s组开始分析 "%(teams[0])+"-"*10)if draw ==False:print(" %s组 - %s VS. %s: %s获胜 概率为 %.2f"%(teams[0], teams[1], teams[2], winner, winner_proba))else:print(" %s组 - %s vs. %s: 平局"%(teams[0], teams[1], teams[2]))
last_group = teams[0]print("\n")print(" %s组 : "%(last_group))for i in table[last_group]:#adding crieterio de desempate
i[2]= np.mean(i[2])
final_points = table[last_group]
final_table =sorted(final_points, key=itemgetter(1,2), reverse =True)
advanced_group.append([final_table[0][0], final_table[1][0]])for i in final_table:print("%s -------- %d"%(i[0], i[1]))
小组赛预测结果
---------- a组开始分析----------
A组-卡塔尔vs厄瓜多尔:厄瓜多尔获胜概率为0.60
A组-塞内加尔vs荷兰:荷兰获胜概率为0.59
A组-卡塔尔vs塞内加尔:塞内加尔获胜概率为0.58
A组-荷兰vs厄瓜多尔:荷兰获胜概率为0.66
A组-厄瓜多尔vs塞内加尔:厄瓜多尔获胜概率为0.53
A组-荷兰vs卡塔尔:荷兰获胜概率为0.69
A组:
荷兰-------- 9
厄瓜多尔-------- 6
塞内加尔-------- 3
卡塔尔-------- 0
---------- b组开始分析----------
B组英格兰vs伊朗:英格兰获胜概率为0.60
B组-美国对威尔士:平局
B组-威尔士vs伊朗:威尔士获胜概率为0.54
B组-英格兰对美国:英格兰获胜概率为0.58
B组-威尔士vs英格兰:英格兰获胜概率为0.60
B组-伊朗对美国:美国获胜概率为0.57
B组:
英格兰-------- 9
美国-------- 4
威尔士-------- 4
伊朗-------- 0
---------- c组开始分析----------
C组-阿根廷vs沙特:阿根廷获胜概率为0.70
C组-墨西哥对波兰:平局
C组-波兰vs沙特:波兰获胜概率为0.64
C组-阿根廷vs墨西哥:阿根廷获胜概率为0.62
C组-波兰vs阿根廷:阿根廷获胜概率为0.64
C组-沙特VS.墨西哥:墨西哥获胜概率为0.64
C组:
阿根廷-------- 9
波兰-------- 4
墨西哥-------- 4
沙特阿拉伯-------- 0
---------- d组开始分析----------
D组-丹麦vs突尼斯:丹麦获胜概率为0.63
D组-法国对澳大利亚:法国获胜概率为0.65
D组-突尼斯对澳大利亚:平局
D组-法国对丹麦:平局
D组-澳大利亚vs丹麦:丹麦获胜概率为0.65
D组-突尼斯vs法国:法国获胜概率为0.63
D组:
法国-------- 7
丹麦-------- 7
突尼斯-------- 1
澳大利亚-------- 1
---------- e组开始分析----------
E组-德国对日本:德国获胜概率为0.59
E组-西班牙vs哥斯达黎加:西班牙获胜概率为0.68
E组-日本vs哥斯达黎加:平局
E组-西班牙对德国:平局
E组-日本vs西班牙:西班牙获胜概率为0.62
E组-哥斯达黎加VS.德国:德国获胜概率为0.60
E组:
西班牙-------- 7
德国-------- 7
日本-------- 1
哥斯达黎加-------- 1
---------- f组开始分析----------
F组-摩洛哥vs克罗地亚:克罗地亚获胜概率为0.58
F组-比利时vs加拿大:比利时获胜概率为0.67
F组-比利时vs摩洛哥:比利时获胜概率为0.63
F组-克罗地亚vs加拿大:克罗地亚获胜概率为0.62
F组-克罗地亚vs比利时:比利时获胜概率为0.60
F组-加拿大对摩洛哥:平局
F组:
比利时-------- 9
克罗地亚-------- 6
摩洛哥-------- 1
加拿大-------- 1
---------- g组开始分析----------
G组-瑞士vs喀麦隆:瑞士获胜概率为0.62
G组-巴西vs塞尔维亚:巴西获胜概率为0.63
G组-喀麦隆vs塞尔维亚:塞尔维亚获胜概率为0.61
G组-巴西vs瑞士:平局
G组-塞尔维亚vs瑞士:瑞士获胜概率为0.56
G组-喀麦隆vs巴西:巴西获胜概率为0.71
G组:
巴西-------- 7
瑞士-------- 7
塞尔维亚-------- 3
喀麦隆-------- 0
---------- h组开始分析----------
H组-乌拉圭vs韩国:乌拉圭获胜概率为0.60
H组-葡萄牙vs加纳:葡萄牙获胜概率为0.71
H组-韩国vs加纳:韩国获胜概率为0.69
H组-葡萄牙对乌拉圭:平局
H组-加纳vs乌拉圭:乌拉圭获胜概率为0.69
H组-韩国vs葡萄牙:葡萄牙获胜概率为0.63
H组:
葡萄牙-------- 7
乌拉圭-------- 7
韩国-------- 3
加纳-------- 0
季后赛预测
小组赛的预测应该没有什么意外,特许是巴西和瑞士或法国和丹麦之间的抽签。对于季后赛阶段,我们将以树形图的方式展示
advanced = advanced_group
playoffs ={"第十六场比赛":[],"四分之一决赛":[],"半决赛":[],"决赛":[]}for p in playoffs.keys():
playoffs[p]=[]
actual_round =""
next_rounds =[]for p in playoffs.keys():if p =="第十六场比赛":
control =[]for a inrange(0,len(advanced*2),1):if a <len(advanced):if a %2==0:
control.append((advanced*2)[a][0])else:
control.append((advanced*2)[a][1])else:if a %2==0:
control.append((advanced*2)[a][1])else:
control.append((advanced*2)[a][0])
playoffs[p]=[[control[c], control[c+1]]for c inrange(0,len(control)-1,1)if c%2==0]for i inrange(0,len(playoffs[p]),1):
game = playoffs[p][i]
home = game[0]
away = game[1]
team_1 = find_stats(home)
team_2 = find_stats(away)
features_g1 = find_features(team_1, team_2)
features_g2 = find_features(team_2, team_1)
probs_g1 = gb.predict_proba([features_g1])
probs_g2 = gb.predict_proba([features_g2])
team_1_prob =(probs_g1[0][0]+ probs_g2[0][1])/2
team_2_prob =(probs_g2[0][0]+ probs_g1[0][1])/2if actual_round != p:print("-"*10)print("开始模拟 %s"%(p))print("-"*10)print("\n")if team_1_prob < team_2_prob:print("%s VS. %s: %s 晋级 概率为 %.2f"%(home, away, away, team_2_prob))
next_rounds.append(away)else:print("%s VS. %s: %s 晋级 概率为 %.2f"%(home, away, home, team_1_prob))
next_rounds.append(home)
game.append([team_1_prob, team_2_prob])
playoffs[p][i]= game
actual_round = p
else:
playoffs[p]=[[next_rounds[c], next_rounds[c+1]]for c inrange(0,len(next_rounds)-1,1)if c%2==0]
next_rounds =[]for i inrange(0,len(playoffs[p])):
game = playoffs[p][i]
home = game[0]
away = game[1]
team_1 = find_stats(home)
team_2 = find_stats(away)
features_g1 = find_features(team_1, team_2)
features_g2 = find_features(team_2, team_1)
probs_g1 = gb.predict_proba([features_g1])
probs_g2 = gb.predict_proba([features_g2])
team_1_prob =(probs_g1[0][0]+ probs_g2[0][1])/2
team_2_prob =(probs_g2[0][0]+ probs_g1[0][1])/2if actual_round != p:print("-"*10)print("开始模拟 %s"%(p))print("-"*10)print("\n")if team_1_prob < team_2_prob:print("%s VS. %s: %s 晋级 概率为 %.2f"%(home, away, away, team_2_prob))
next_rounds.append(away)else:print("%s VS. %s: %s 晋级 概率为 %.2f"%(home, away, home, team_1_prob))
next_rounds.append(home)
game.append([team_1_prob, team_2_prob])
playoffs[p][i]= game
actual_round = p
开始模拟 第十六场比赛---------
荷兰vs美国:荷兰晋级概率为0.55
阿根廷vs丹麦:阿根廷晋级概率为0.59
西班牙vs克罗地亚:西班牙晋级概率为0.57
巴西vs乌拉圭:巴西晋级概率为0.60
厄瓜多尔vs英格兰:英格兰晋级概率为0.65
波兰vs法国:法国晋级概率为0.60
德国vs比利时:比利时晋级概率为0.50
瑞士vs葡萄牙:葡萄牙晋级概率为0.52
开始模拟 四分之一决赛---------
荷兰vs阿根廷:荷兰晋级概率为0.52
西班牙vs巴西:巴西晋级概率为0.51
英格兰vs法国:法国晋级概率为0.51
比利时vs葡萄牙:葡萄牙晋级概率为0.52
开始模拟 半决赛---------
荷兰vs巴西:巴西晋级概率为0.52
法国vs葡萄牙:葡萄牙晋级概率为0.52
开始模拟 决赛---------
巴西vs葡萄牙:巴西晋级概率为0.52
- 画出其树图
!pip install pydot pydot-ng graphviz
import networkx as nx
from networkx.drawing.nx_pydot import graphviz_layout
plt.figure(figsize=(15,10))
G = nx.balanced_tree(2,3)
labels =[]for p in playoffs.keys():for game in playoffs[p]:
label =f"{game[0]}({round(game[2][0],2)}) \n {game[1]}({round(game[2][1],2)})"
labels.append(label)
labels_dict ={}
labels_rev =list(reversed(labels))for l inrange(len(list(G.nodes))):
labels_dict[l]= labels_rev[l]
pos = graphviz_layout(G, prog='twopi')
labels_pos ={n:(k[0], k[1]-0.08*k[1])for n,k in pos.items()}
center = pd.DataFrame(pos).mean(axis=1).mean()
nx.draw(G, pos = pos, with_labels=False, node_color=range(15), edge_color="#bbf5bb", width=10, font_weight='bold',cmap=plt.cm.Greens, node_size=5000)
nx.draw_networkx_labels(G, pos = labels_pos, bbox=dict(boxstyle="round,pad=0.3", fc="white", ec="black", lw=.5, alpha=1),
labels=labels_dict)
texts =["Round \nof 16","Quarter \n Final","Semi \n Final","Final\n"]
pos_y = pos[0][1]+55for text inreversed(texts):
pos_x = center
pos_y -=75
plt.text(pos_y, pos_x, text, fontsize =18)
plt.axis('equal')
plt.show()
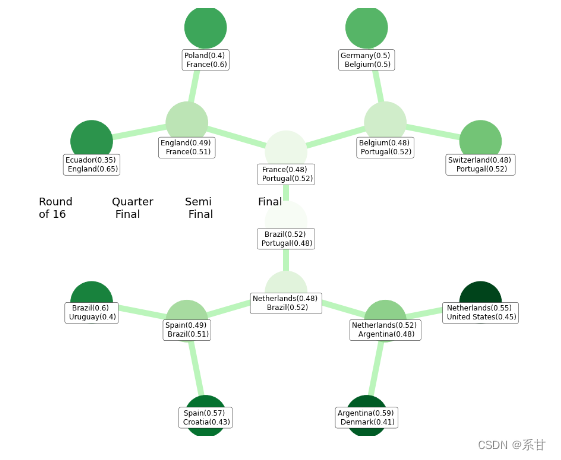
总结
- 预测结果随时都会发生改变,因为我们的数据库随着比赛的进行也会发生改变。若想知道最新结果,将最新数据放进去即可。
- 预测结果不一定准确,只是图一乐,主要用途是学习,在本项目中可以很好的学到数据预处理及特征工程的技术
- 在本项目中的建模较为粗糙,只有一个经过了网格搜索交叉验证的梯度提升树,因此结果并不准确,当然我也希望最后巴西能够获胜
- 截止2022.11.25中午,共进行了16场世界杯比赛,其中有11场比赛预测正确。阿根廷和日本的爆冷是没有预测正确的,以及乌拉圭与韩国、摩洛哥与克罗地亚、丹麦与突尼斯的平局是没有预测正确的。
- 请不要用该预测结果参与各种投注,仅供学习参考
优化方向
- 尝试添加更多对预测有利的特征,例如新冠疫情、选手近些天的状态等
- 在特征工程上可以在花多点功夫
- 最后就是在模型上,本文的模型比较草率,可以尝试使用更有优势的机器学习模型
代码下载
Baseline:
https://www.kaggle.com/code/sslp23/predicting-fifa-2022-world-cup-with-ml/notebook
随时都会优化并更新的版本:
https://aistudio.baidu.com/aistudio/projectdetail/5116425?contributionType=1&sUid=2553954&shared=1&ts=1669358827040
版权归原作者 Code_cab 所有, 如有侵权,请联系我们删除。