
꒰˃͈꒵˂͈꒱ write in front ꒰˃͈꒵˂͈꒱
ʕ̯•͡˔•̯᷅ʔ大家好,我是xiaoxie.希望你看完之后,有不足之处请多多谅解,让我们一起共同进步૮₍❀ᴗ͈ . ᴗ͈ აxiaoxieʕ̯•͡˔•̯᷅ʔ—CSDN博客
本文由xiaoxieʕ̯•͡˔•̯᷅ʔ 原创 CSDN 如需转载还请通知˶⍤⃝˶
个人主页:xiaoxieʕ̯•͡˔•̯᷅ʔ—CSDN博客
系列专栏:xiaoxie的JAVA系列专栏——CSDN博客●'ᴗ'σσணღ*
**我的目标:"团团等我💪( ◡̀_◡́ ҂)" **( ⸝⸝⸝›ᴥ‹⸝⸝⸝ )欢迎各位→点赞👍 + 收藏⭐️ + 留言📝+关注(互三必回)!
 一.顺序表
一.顺序表
1.底层实现
首先我们要清楚,数据结构是一门逻辑十分清晰的学科,所以我们需要清楚的认识到每个结构的底层是什么,这样才能更好的掌握这个结构。
顺序表是用一段物理地址连续的存储单元依次存储数据元素的线性结构,一般情况下采用数组存储。在数组上完成 数据的增删查改。
2.构造方法
在集合框架中,ArrayList是一个普通的类,实现了List接口,并且ArrayList是一个泛型类
而ArrayList的构造方法如下所示
public class Text {
public static void main(String[] args) {
//无参
List<Integer> list = new ArrayList<>();
//指定顺序表初始容量
List<Integer> list1 = new ArrayList<>(20);
list1.add(1);
list1.add(11);
//ArrayList(Collection<? extends E> c) 利用其他 Collection 构建 ArrayList
List<Integer> list2 = new ArrayList<>(list1);
}
}
3.常用方法
ArrayList是一个普通的类,实现了List接口,所以它实现了许多接口内的方法,博主现在为大家列举出一些常用的方法
List<Integer> list = new ArrayList<>();
//尾插入元素
list.add(1);
list.add(12);
list.add(11);
//指定位置插入参数为 位置 和 元素
list.add(2,3);
//顺序表长度
list.size();
//删除指定位置元素
list.remove(2);
//是否包含某个元素
list.contains(4);
//截取部分 list
list.subList(0,1);
//获取下标 index 位置元素
list.get(2);
//将下标 index 位置元素设置为 element
list.set(3,9);
//返回第一个 o 所在下标
list.indexOf(8);
//返回最后一个 o 的下标
list.lastIndexOf(8);
4.Arrays的遍历方法
1.直接输出
List<Integer> list = new ArrayList<>();
//尾插入元素
list.add(1);
list.add(12);
list.add(11);
System.out.println(list);

2.for循环和for-each
List<Integer> list = new ArrayList<>();
//尾插入元素
list.add(1);
list.add(12);
list.add(11);
System.out.println("for循环遍历");
for (int i = 0; i < list.size(); i++) {
System.out.print(list.get(i)+" ");
}
System.out.println();
System.out.println("for-each循环遍历");
for (Integer x:list) {
System.out.print(x+" ");
}

3.使用迭代器
List<Integer> list = new ArrayList<>();
//尾插入元素
list.add(1);
list.add(12);
list.add(11);
System.out.println("迭代器正序输出");
Iterator<Integer>it = list.iterator();
while (it.hasNext()) {
System.out.print(it.next()+" ");
}
System.out.println();
System.out.println("迭代器逆序输出");
ListIterator <Integer> it1 = list.listIterator(list.size());
while (it1.hasPrevious()) {
System.out.print(it1.previous()+" ");
}
}
 5.实战演示
5.实战演示
杨辉三角 力扣的118题,难度不大,感兴趣的朋友可以去尝试一下
解答代码如下
/*
1
1 1
1 2 1
1 3 3 1
1 4 6 4 1
由图可知每一行的第一个为1,最后一个也为一中间部分等于上一行的前一个加上上一行同一列的
一个,并且最后一个也为一。
*/
class Solution {
public List<List<Integer>> generate(int numRows) {
List<Integer> list = new ArrayList<>();
List<List<Integer>> ans = new ArrayList<>();
list.add(1);//第一行
ans.add(list);
for(int i = 1;i < numRows;i++) {
List<Integer> temp = new ArrayList<>();
temp.add(1);//每一行的第一个都为一
List<Integer> row =ans.get(i-1);//上一行
for(int j = 1; j <i;j++) {
int x = row.get(j)+row.get(j-1);//中间部分为上一行的前一个加上上一行同一列的一个
temp.add(x);
}
temp.add(1);//一行的最后一个元素也为1
ans.add(temp);
}
return ans;
}
}
以上是博主解答这题的思路和代码,时间复杂度为O(n^2)如果你有更好的方法或者是不懂的地方都可以私聊博主,大家一起交流进步
二.链表
1.底层实现
链表是一种物理存储结构上非连续存储结构,数据元素的逻辑顺序是通过链表中的引用链接次序实现的,它的结构如下
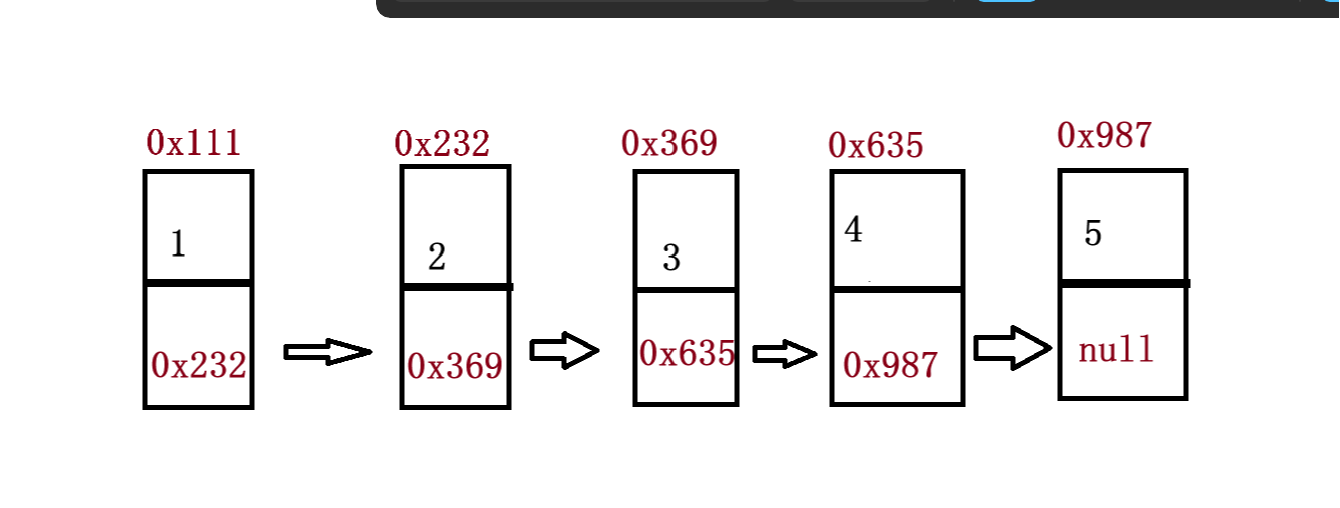
当然链表的结构不仅仅是这一种其他还有1. **单向或者双向 **2. **带头或者不带头 **3. **循环或者非循环 **
虽然有这么多的链表的结构,但是我们重点掌握两种:
无头单向非循环链表:结构简单,一般不会单独用来存数据。实际中更多是作为其他数据结构的子结构,如
哈希桶、图的邻接表等等。另外这种结构在笔试面试中出现很多。
无头双向链表:在Java的集合框架库中LinkedList底层实现就是无头双向循环链表。
2.无头单向非循环链表
无头单向非循环链表是一种数据结构,其特点是没有头节点、只有一个指向第一个节点的指针,而且最后一个节点的指针为空(NULL),形成一个单向链表的尾部。这意味着如果需要查找第一个节点,必须从指向第一个节点的指针开始遍历链表。此外,非循环链表是一个单向链表,从第一个节点开始一直到最后一个节点,而最后一个节点指向空(NULL),这样就可以避免链表中的死循环问题。
3.无头双向非循环链表
无头双向非循环链表是一种数据结构,它由多个节点组成,每个节点有两个指针,一个指向前一个节点,一个指向后一个节点。和单向链表不同的是,双向链表可以向前和向后遍历,而且插入和删除节点的操作比较方便。
无头表示链表没有头节点,也就是第一个节点就是链表的起始节点。非循环表示链表没有环,也就是最后一个节点的指针指向 NULL。
在无头双向非循环链表中,我们可以从任意一个节点开始遍历,也可以逆序遍历整个链表。双向链表比单向链表多了一个指针,所以它在一些场景下比单向链表更加方便,比如需要频繁地插入和删除节点时。但是,它也需要更多的内存空间来存储指针。
4.顺序表和链表之间的区别
顺序表和链表是两种数据结构,它们的主要区别在于存储方式和操作效率不同:
- 存储方式不同:顺序表使用一组连续的存储单元存储数据,而链表则使用指针将一组零散的存储单元串联起来。
- 随机访问效率不同:顺序表通过下标可以直接访问任意位置的元素,时间复杂度为O(1),但插入和删除操作需要移动数据,时间复杂度为O(n)。而链表不能通过下标直接访问元素,插入和删除操作只需要修改指针,时间复杂度为O(1),但是随机访问需要遍历整个链表,时间复杂度为O(n)。
- 空间利用率不同:顺序表预先分配存储空间大小固定,当存储空间不够时需要重新分配内存,可能浪费内存。而链表通过动态分配内存,只在需要时才分配所需的存储空间,空间利用率较高。
总之,应根据实际需求选择合适的数据结构,如果需要频繁随机访问,可以选择顺序表;如果需要频繁插入和删除,可以选择链表。
5.链表面试题
1.给定一个链表,返回链表开始入环的第一个节点。 如果链表无环,则返回 NULL 链接
public class Solution {
// 定义一个方法detectCycle,输入参数为链表头节点head,返回值类型为ListNode(链表节点)
public ListNode detectCycle(ListNode head) {
// 如果链表为空或只有一个元素,则没有环,直接返回null
if(head == null || head.next == null) {
return null;
}
// 初始化两个指针fast和slow,都指向链表头节点
ListNode fast = head;
ListNode slow = head;
// 使用快慢指针进行遍历
while(fast != null && fast.next != null) {
// 慢指针每次前进一步
slow = slow.next;
// 快指针每次前进两步
fast = fast.next.next;
// 如果快慢指针相遇,则说明存在环
if(slow == fast) {
break;
}
}
// 如果快指针遍历到链表末尾,说明不存在环,返回null
if(fast == null || fast.next == null) {
return null;
}
// 重新设置快指针fast到链表头节点,慢指针slow保持在相遇点
fast = head;
// 当快慢指针再次相遇时,相遇点即为环的起点
while(slow != fast) {
slow = slow.next;
fast = fast.next;
}
// 返回环的起点
return fast;
}
}
2.链表的回文结构链接
public class PalindromeList {
// 定义一个方法chkPalindrome,输入参数为链表头节点head,返回值类型为布尔值(true表示是回文链表,false表示不是)
public boolean chkPalindrome(ListNode head) {
// 如果链表为空,则直接返回true(空链表是回文链表)
if(head == null ) {
return true;
}
// 使用快慢指针找到链表的中间结点
ListNode fast = head;
ListNode slow = head;
while(fast != null && fast.next != null) {
fast = fast.next.next; // 快指针每次前进一步
slow = slow.next; // 慢指针每次前进一步
}
// 翻转链表后半部分
ListNode cur = slow.next;
while(cur != null) {
ListNode curnext = cur.next;
cur.next = slow;
slow = cur;
cur = curnext;
}
// 判断翻转后的链表与原链表前半部分是否相等
while(head != slow) {
if(head.val != slow.val) { // 如果两个节点的值不相等,则说明不是回文链表
return false;
}if(head.next != slow) { // 奇数情况下,已经比较完所有节点,可以提前结束循环
return true;
}
head = head.next; // 头节点向后移动一位
slow = slow.next; // 反转后的尾节点向前移动一位
}
// 遍历结束后没有发现不相等的节点,说明是回文链表
return true;
}
}
3.将两个有序链表合并为一个新的有序链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。链接
public class Partition {
// 定义一个方法partition,输入参数为链表头节点head和整数x,返回值类型为ListNode(链表节点)
public ListNode partition(ListNode head, int x) {
// 如果链表为空,则直接返回null
if(head == null) {
return null;
}
// 初始化两个指针de和dx,用于记录小于x的元素链表的尾节点和当前节点
ListNode de = null;
ListNode dx = null;
// 初始化两个指针pe和px,用于记录大于等于x的元素链表的尾节点和当前节点
ListNode pe = null;
ListNode px = null;
// 初始化一个指针cur,指向链表的头节点
ListNode cur = head;
// 遍历链表中的每个节点
while(cur != null) {
// 如果当前节点的值小于x
if(cur.val < x) {
// 如果小于x的元素链表尚未创建,则将当前节点设置为头节点和尾节点
if(de == null) {
de = cur;
dx = cur;
}else { // 否则将当前节点添加到小于x的元素链表的末尾
dx.next = cur;
dx = dx.next;
}
}else { // 如果当前节点的值大于等于x
// 如果大于等于x的元素链表尚未创建,则将当前节点设置为头节点和尾节点
if(pe == null) {
pe = cur;
px = cur;
}else { // 否则将当前节点添加到大于等于x的元素链表的末尾
px.next = cur;
px = px.next;
}
}
// 指针cur向后移动一位
cur = cur.next;
}
// 如果不存在小于x的元素,则直接返回大于等于x的元素链表
if(dx == null) {
return pe;
}
// 将大于等于x的元素链表接到小于x的元素链表的末尾
dx.next = pe;
// 如果存在大于等于x的元素,则将其尾节点的next指针置为null
if(pe != null) {
px.next = null;
}
// 返回小于x的元素链表的头节点
return de;
}
}
三.结语
数据结构一门逻辑十分严谨的一门学科,而顺序表和链表都是十分基础的结构,也是后续学习的基础,所以应该要多花时间去搞清楚它的底层,好了本文到这里就结束了,感谢您的阅读,祝您一天愉快
版权归原作者 小谢在努力 所有, 如有侵权,请联系我们删除。