
非参重建(3D Clothed Human Reconstruction)
Title: AvatarCap: Animatable Avatar Conditioned Monocular Human Volumetric Capture
Author: Tsinghua University
Abstract: 本文提出了AvatarCap,通过少量(约20次)的扫描来进行单目人体体积捕捉,实现高保真重建,而不考虑能见度。
Paper
Code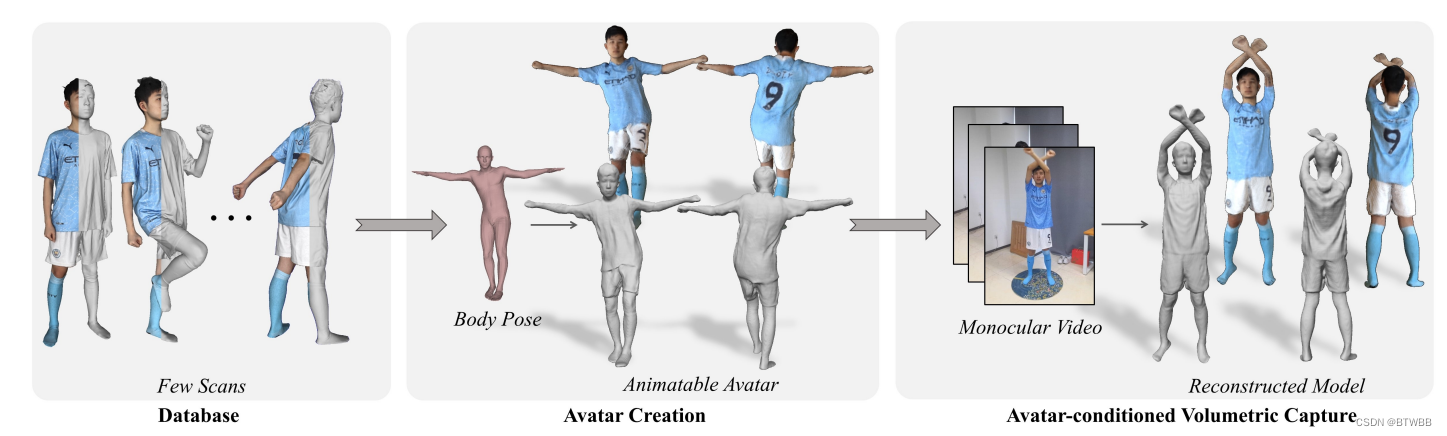
Title: DiffuStereo: High Quality Human Reconstruction via Diffusion-based Stereo Using Sparse Cameras
Author: Tsinghua University
Abstract: 本文的系统由三个关键步骤组成,从稀疏视图输入重建高质量的人体模型:i)初始人体网格由DoubleField预测,并呈现为粗视差流;ii)在基于扩散的立体视觉中对粗视差图进行细化,获得高质量的深度图;iii)将初始的人体网格和高质量的深度图融合为最终的高质量人体网格。
Paper
Code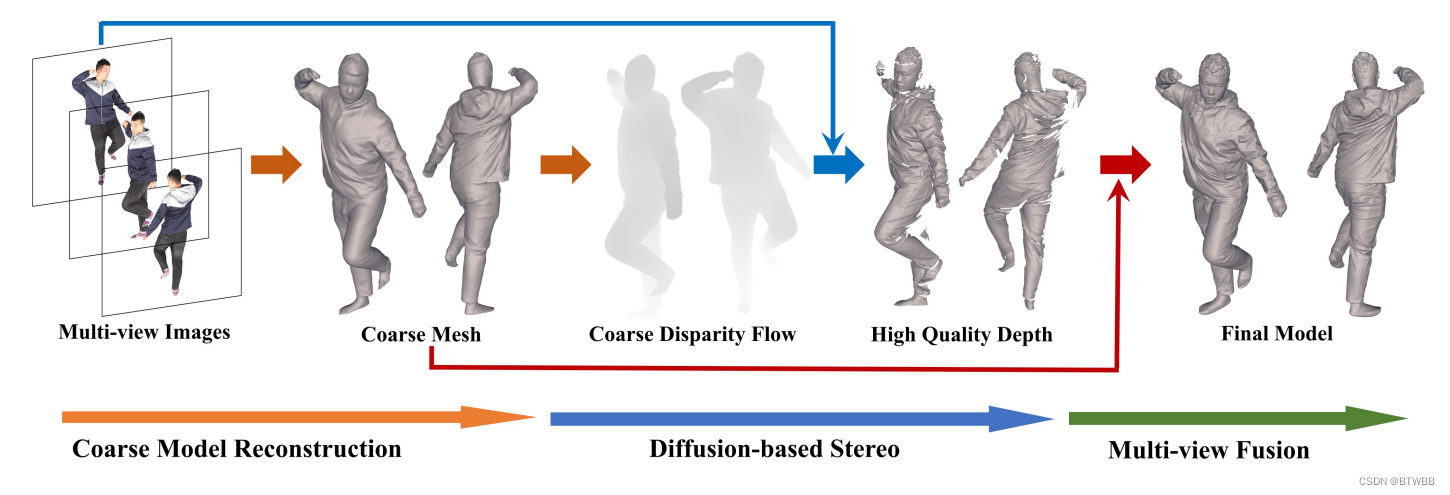
Title: Learning Implicit Templates for Point-Based Clothed Human Modeling
Author: Tsinghua University
Abstract: 本文提出了一种先隐后显的服装建模框架FITE。本文的框架首先学习表示粗糙服装拓扑的隐式表面模板,然后使用模板来指导点集的生成,进一步捕获姿态相关的服装变形,如褶皱。
Paper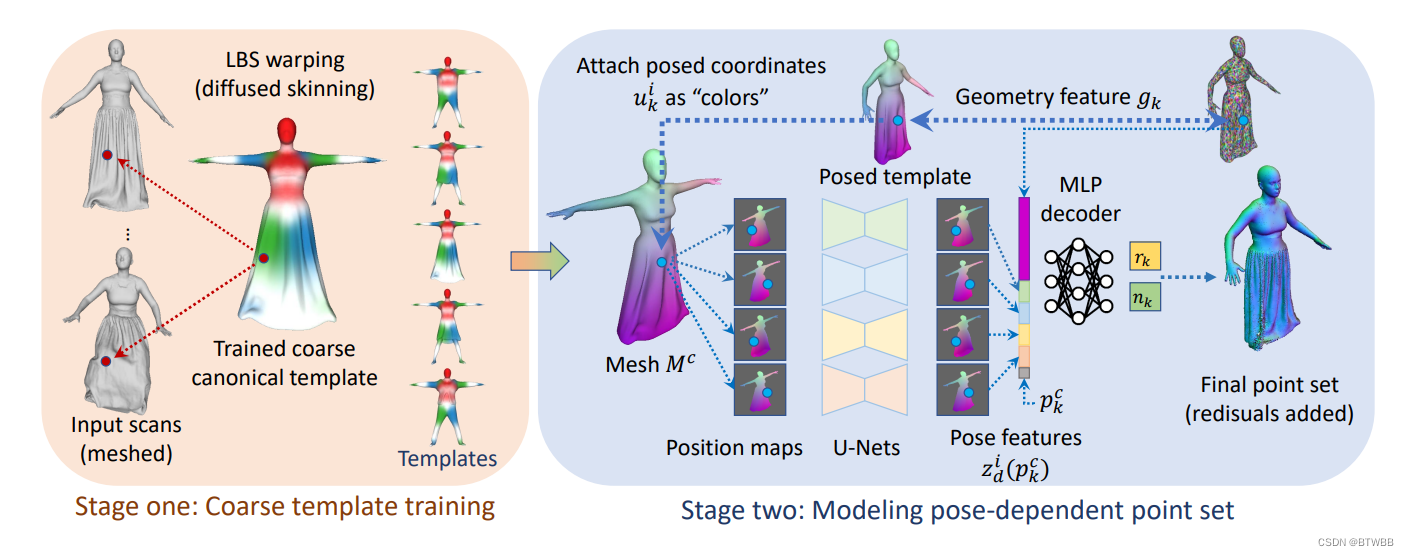
Title: LoRD: Local 4D Implicit Representation for High-Fidelity Dynamic Human Modeling
Author: 1Fudan University 2Google
Abstract: LoRD用一组重叠的局部部分来代表动态的人。利用估计的SMPL网格对每个部分进行时间跟踪,并包含低维的运动、规范形状和纹理潜在代码(可选),解码后可通过一种方法恢复局部表面块的详细时间变化4d隐式网络。
Paper
Code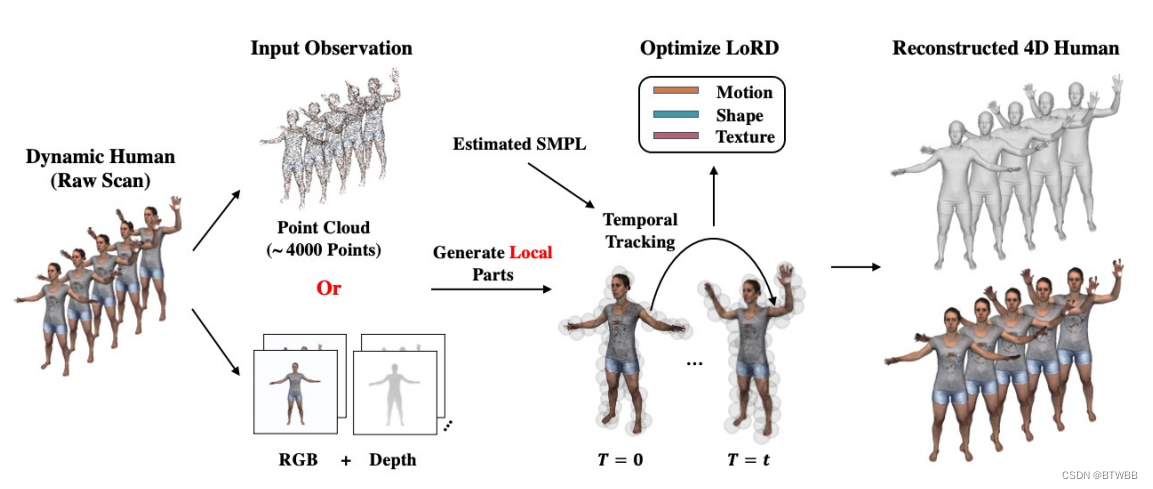
Title: 3D Clothed Human Reconstruction in the Wild
Author: Meta Reality Labs Research(part)
Abstract: ClothNet预测布料生成模型SMPLicit的布料潜在代码,并通过将代码传递给SMPLicit来生成一个无符号的距离字段。BodyNet预测SMPL姿势和形状参数。
Paper
Code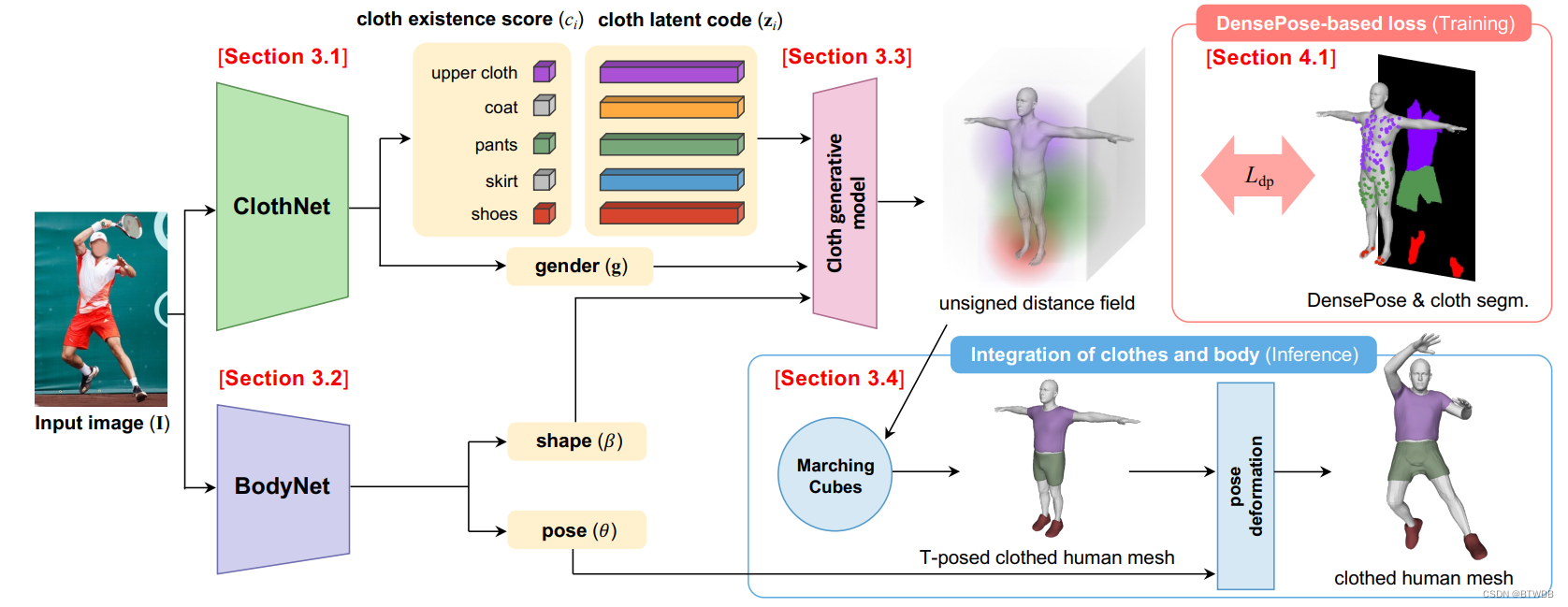
Title: UNIF: United Neural Implicit Functions for Clothed Human Reconstruction and Animation
Author: 1 ZMO AI Inc. 2 ShanghaiTech University
Abstract: 本文提出了一个统一隐式函数(united implicit functions, UNIF),一种基于部分的方法,以原始扫描和骨架为输入,实现穿戴人体的重建和动画。
Paper
Code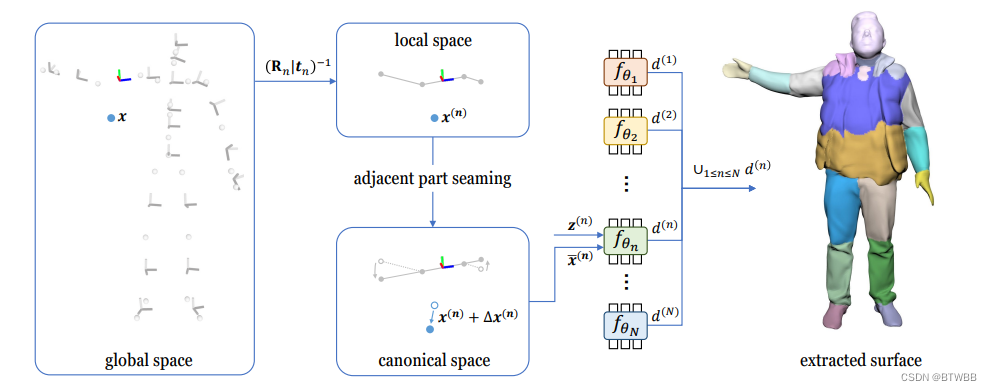
参数重建(Human shape and pose estimation)
Title: CLIFF: Carrying Location Information in Full Frames into Human Pose and Shape Estimation
Author: Huawei Noah’s Ark Lab
Abstract: 本文提出了CLIFF:携带位置信息通过对之前的自顶向下方法进行两大修改,将完整的帧转换为3D人体姿态和形状估计。
Paper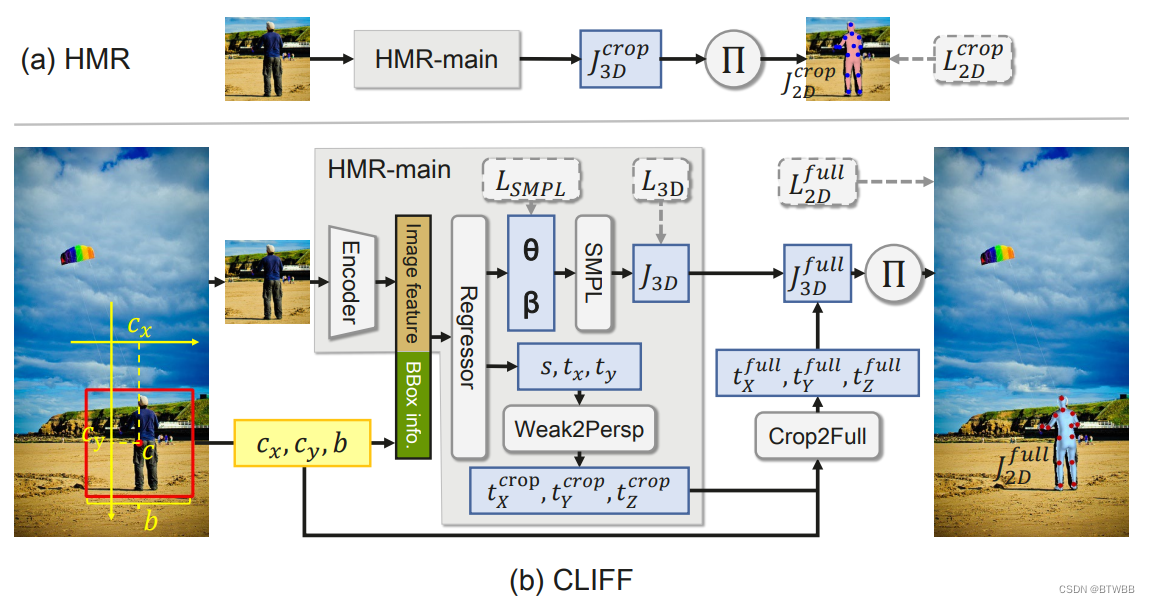
Title: Cross-Attention of Disentangled Modalities for 3D Human Mesh Recovery with Transformers
Author: 1Department of CSE 2Department of EE 3Graduate School of AI
Abstract: 本文提出了一种新颖的transformer编码器-解码器架构,用于从单一图像重建人体三维网格,称为FastMETRO。
Paper
Code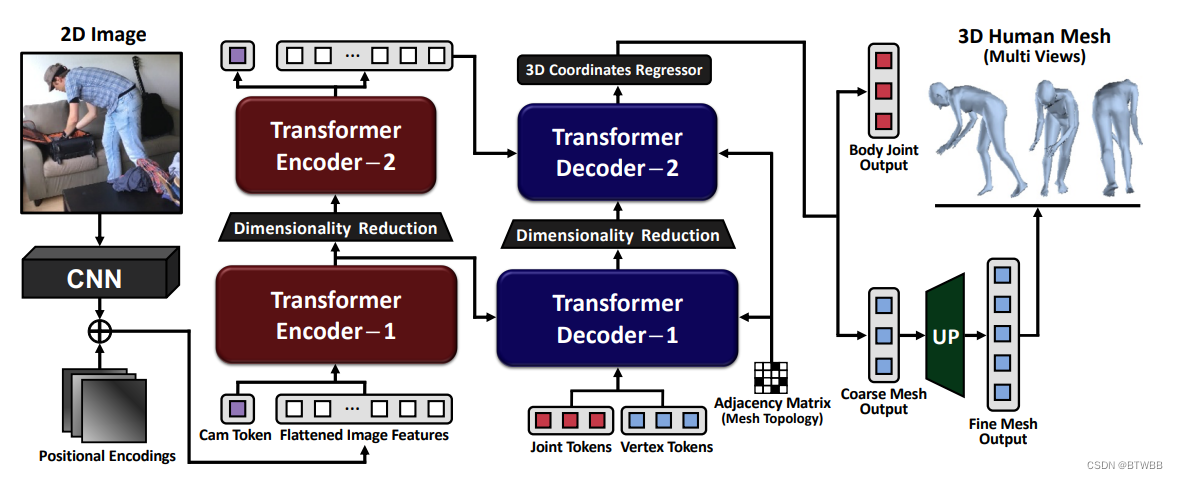
Title: Learned Vertex Descent: A New Direction for 3D Human Model Fitting
Author: University of T¨ubingen, Germany(part)
Abstract: 本文提出了一种新的基于优化的范式的三维人体模型拟合图像和扫描。与直接从输入图像回归低维统计体模型(如SMPL)参数的现有方法相比,本文训练每个顶点神经场网络的集合。
Paper
Code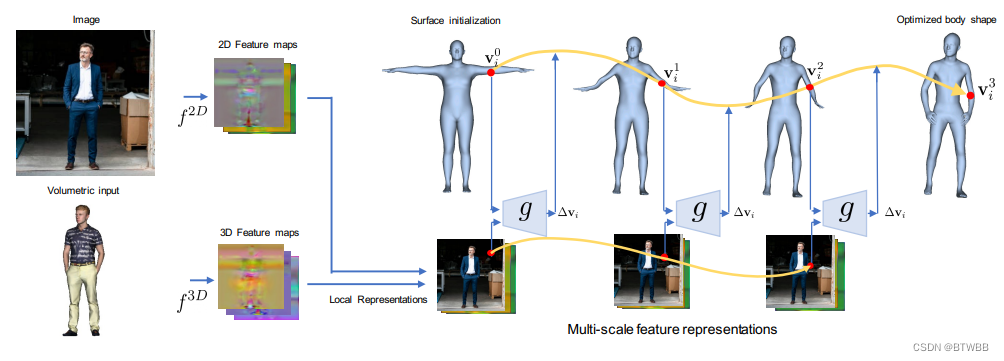
Title: CHORE: Contact, Human and Object REconstruction from a single RGB image
Author: University of T¨ubingen, Germany(part)
Abstract: 本文引入了一种新的方法——CHORE,该方法学习从单一RGB图像对物体和人之间进行联合重构。CHORE的灵感来自隐式表面学习和经典模型拟合的最新进展。
Paper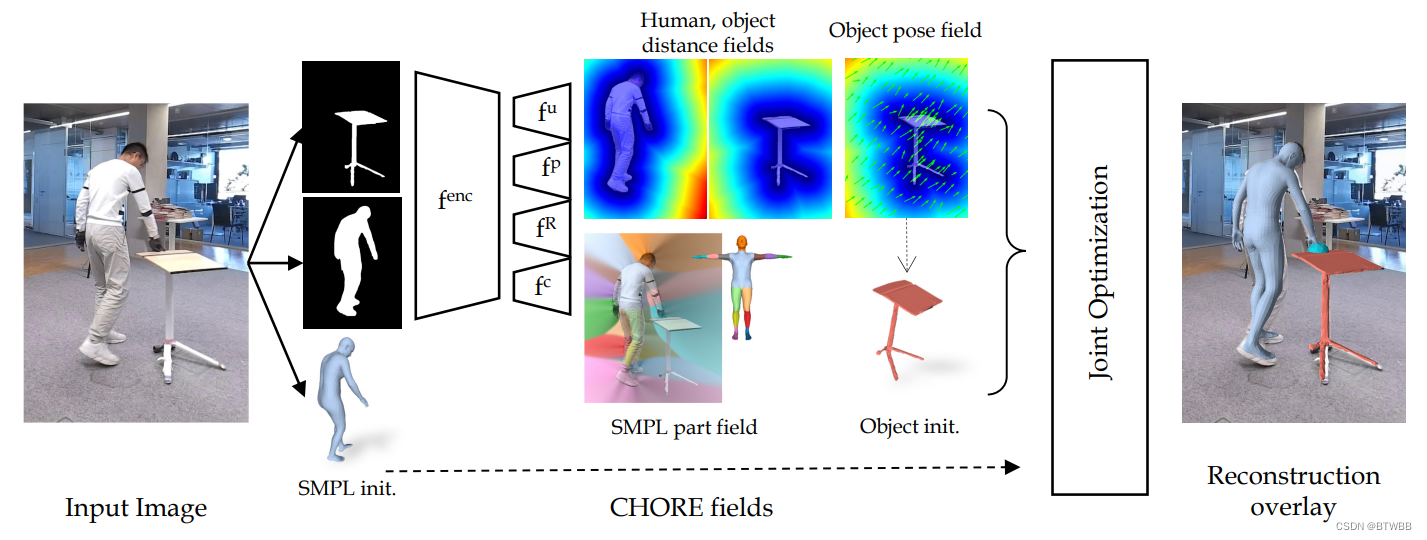
Title: Learning to Fit Morphable Models
Author: 1Max Planck Institute for Intelligent Systems, T¨ubingen, Germany, 2Microsoft
Abstract: 本文建立在学习优化的最新进展,并提出了一个更新规则的灵感来自经典的Levenberg-Marquardt算法。本文展示了所提出的神经优化器在三个问题上的有效性,从一个头戴设备的三维身体估计,从稀疏的2D关键点的三维身体估计和从密集的2D landmarks的人脸表面估计。
Paper
Title: The One Where They Reconstructed 3D Humans and Environments in TV Shows
Author: University of California, Berkeley
Abstract: 在本文中认为电视节目中存在着一定的持续性。例如,环境和人物的重复,这使得该内容的三维重建成为可能。基于这一见解,其提出了一种自动方法,它可以运行在一整季的电视节目中,并在3D中聚合信息;建立三维环境模型,计算相机信息、静态三维场景结构和人体尺度信息。
Paper
Title: TAVA: Template-free Animatable Volumetric Actors
Author: 1. UC Berkeley 2. University of Bonn 3. Meta Reality Labs Research
Abstract: 本文提出了一种基于神经表示的创建无模板可动画角色的方法。本文仅依靠多视图数据和跟踪骨架来创建演员的体积模型,该模型可以在给定的新姿势的测试时间进行动画化。由于TAVA不需要身体模板,它不仅适用于人类,也适用于其他生物,如动物。
Paper
Code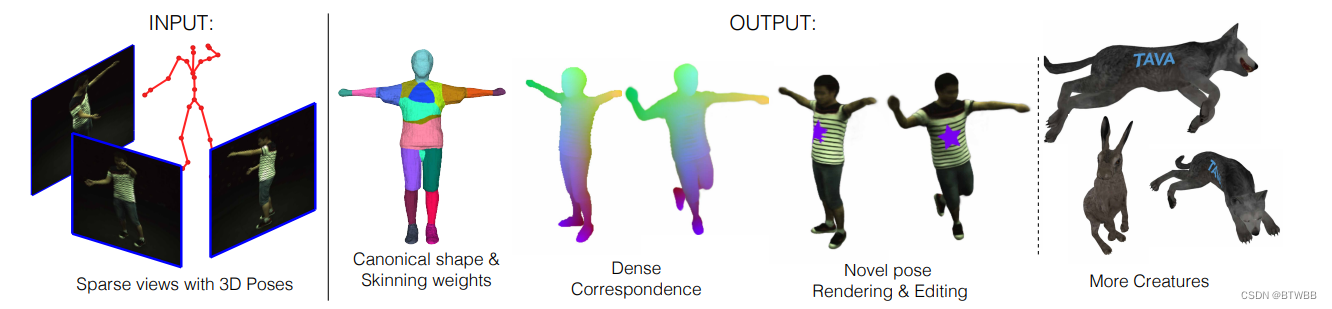
Title: EgoBody: Human Body Shape and Motion of Interacting People from Head-Mounted Devices
Author: 1ETH Z¨urich 2Microsoft
Abstract: 本文提出一个全新的大规模数据集,用于在复杂3D场景交互过程中从自我中心视角进行人体姿态、形状和运动估计。
Paper
Title: Learning Visibility for Robust Dense Human Body Estimation
Author: 1UC Merced 2Adobe 3Google 4Yonsei University
Abstract: 本文主要针对身体的部分被遮挡或在帧外的问题,提出了密集人体估计,分别显式地在x、y和z轴上建模人体关节和顶点的可见性。x轴和y轴的可见性有助于区分框外情况,深度轴的可见性对应于遮挡(自遮挡或被其他物体遮挡)。
Paper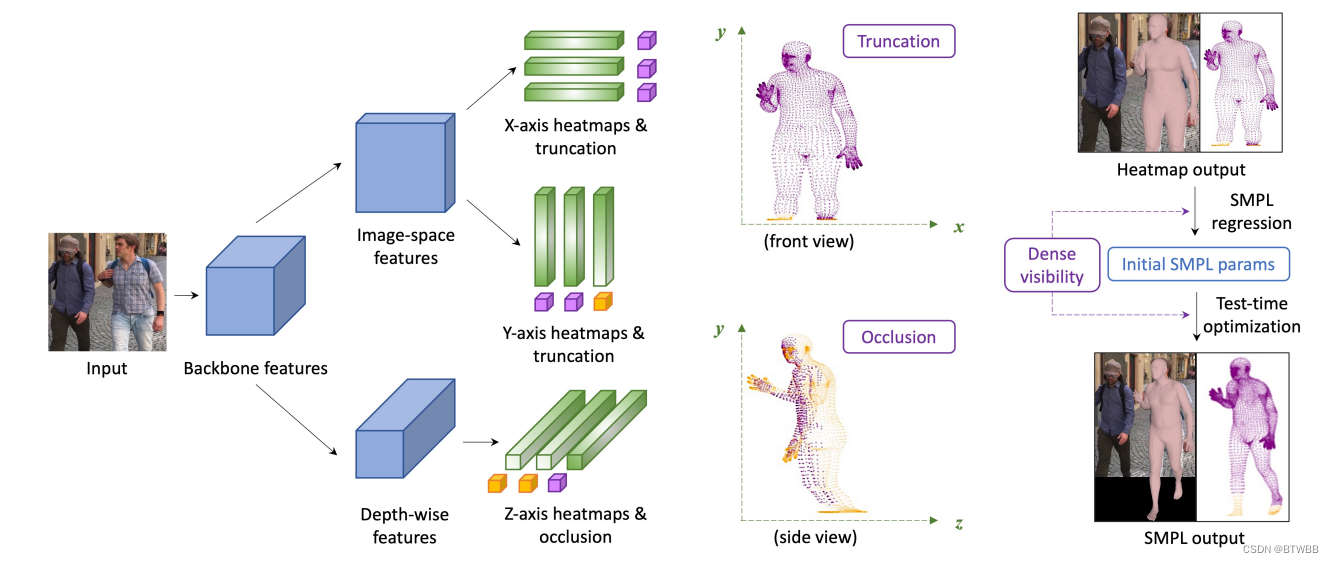
Title: ARAH: Animatable Volume Rendering of Articulated Human SDFs
Author: 1 ETH Z¨urich 2 Max Planck Institute for Intelligent Systems, T¨ubingen 3 University of T¨ubingen
Abstract: 本文针对神经辐射场(NeRF)由于缺少几何约束,推导出的几何结构缺乏细节的问题,提出了一个模型,以创建具有详细几何形状的可动画穿戴的人类化身,并很好地概括了非分布姿势。为了实现详细的几何图形,本文将铰接隐式曲面表示与体绘制相结合。
Paper
Code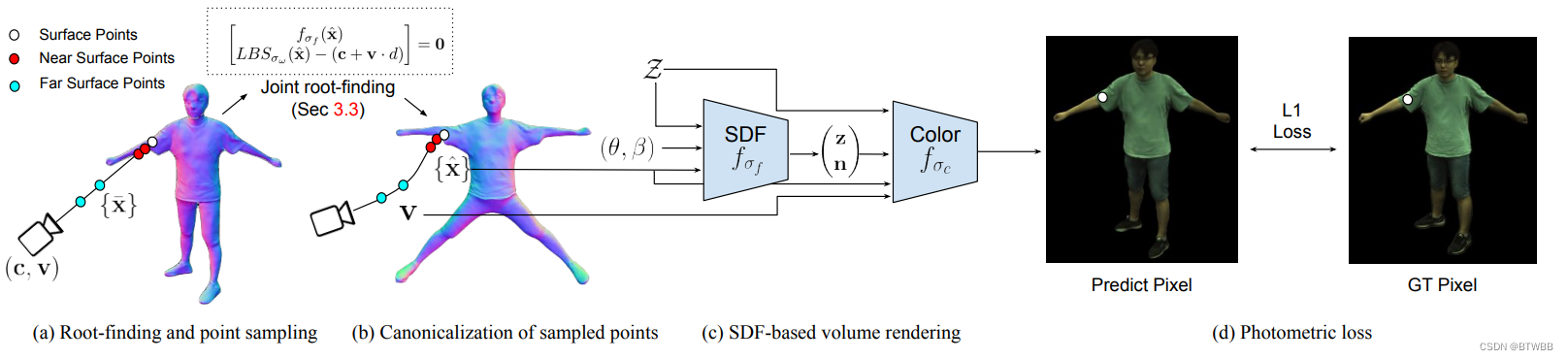
Title: Super-resolution 3D Human Shape from a Single Low-Resolution Image
Author: Centre for Vision, Speech and Signal Processing (CVSSP), University of Surrey
Abstract: 本文提出了一个新的框架,以重建超分辨率人体形状从单一低分辨率输入图像。该方法克服了现有从单幅图像重建三维人体形状的方法的局限性,需要高分辨率的图像加上表面法线或参数化模型等辅助数据来重建高细节的人体形状。
Paper
Code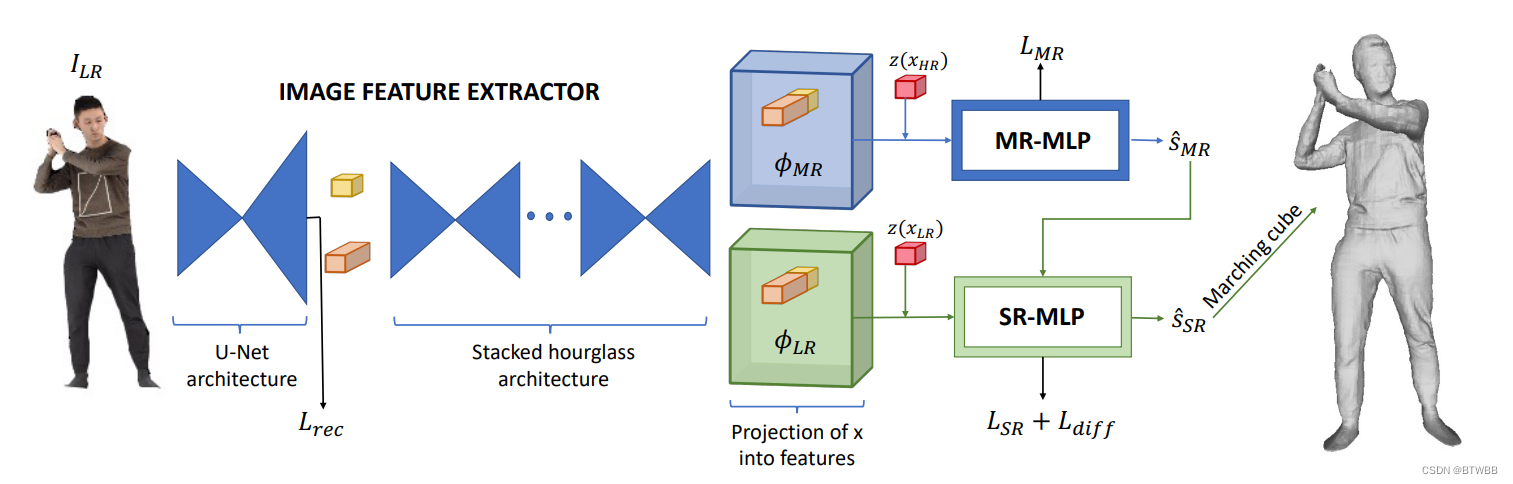
Title: SUPR: A Sparse Unified Part-Based Human Representation
Author: 1 Max Planck Institute for Intelligent Systems, T¨ubingen, Germany 2 University of Amsterdam
Abstract: 本文提出了一种新的学习方案,使用全身和身体部分扫描的联邦数据集联合训练全身模型和特定部位模型。具体地说,本文训练了一个称为SUPR(稀疏统一基于部分的表示)的表达人体模型,其中每个关节都严格影响模型顶点的稀疏集。分解的表示法使SUPR可以分离为一整套身体部位模型:一个有表现力的头(SUPR- head),一个铰接的手(SUPR- hand)和一个新颖的脚(SUPR- foot)。
Paper
Title: Self-supervised Human Mesh Recovery with Cross-Representation Alignment
Author: 1 University at Buffalo, Buffalo NY, USA 2 United Imaging Intelligence, Cambridge MA, USA
Abstract: 本文提出利用来自鲁棒稀疏表示(2D关键点)的互补信息进行交叉表示对齐。具体而言,将初始网格估计与两种二维表示之间的对齐误差转发到回归量中,并在接下来的网格回归中进行动态校正。这种自适应的交叉表示对齐明确地从偏差中学习并捕获互补信息:从稀疏表示中获得鲁棒性,从密集表示中获得丰富性。
Paper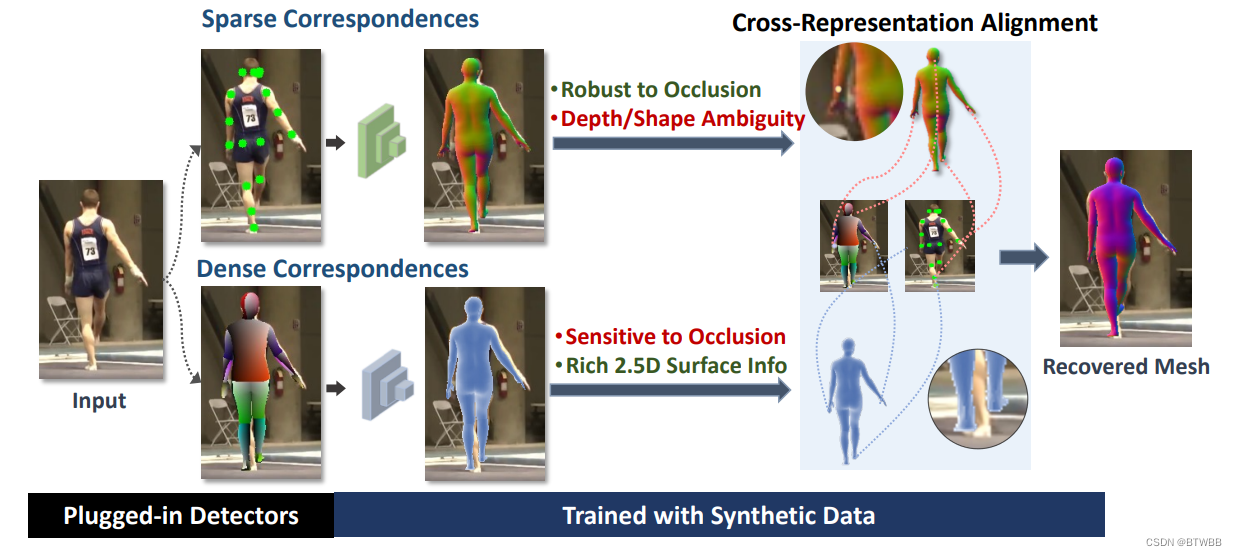
Title: HuMMan: Multi-Modal 4D Human Dataset for Versatile Sensing and Modeling
Author: 1Shanghai AI Laboratory, 2S-Lab, Nanyang Technological University, 3SenseTime Research, 4The Chinese University of Hong Kong, 5Tsinghua University
Abstract: 本文贡献了一个大规模的多模态4D人类数据集human man,包含1000个人类受试者,400k序列和60M帧。HuMMan有几个吸引人的特性:1)多模态数据和注释,包括彩色图像、点云、关键点、SMPL参数和纹理网格;2)传感器套件中包含流行的移动设备;3)一套500个动作,旨在涵盖基本动作;4)支持和评估动作识别、姿态估计、参数人体恢复和纹理网格重建等多个任务。
Paper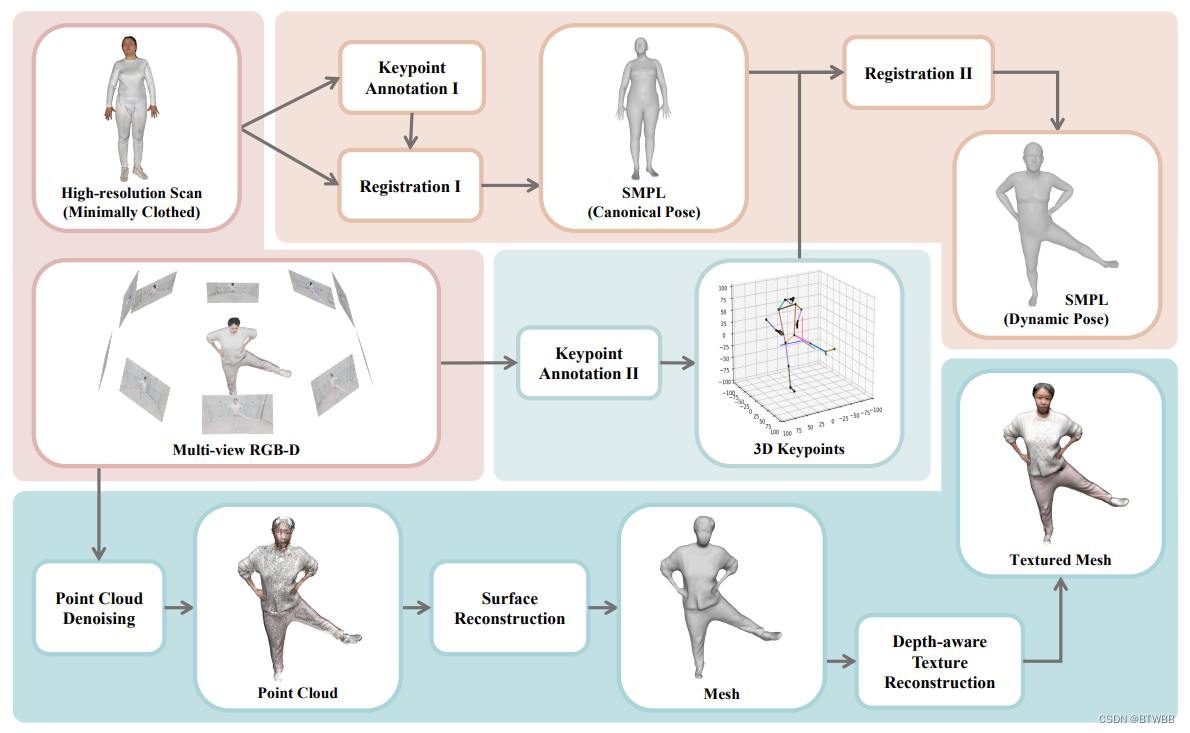
Title: IntegratedPIFu: Integrated Pixel Aligned Implicit Function for Single-view Human Reconstruction
Author: 1 S-Lab, Nanyang Technological University 2 SenseTime Research 3 Nanyang Technological University
Abstract: 本文提出了一种新的像素对齐隐式模 IntegratedPIFu,它建立在PIFuHD所建立的基础上。IntegratedPIFu展示了深度和人工解析信息如何在像素对齐隐式模型中进行预测和利用。此外,IntegratedPIFu引入了面向深度的采样,这是一种新的训练方案,可以提高任何像素对齐的隐式模型重建重要人体特征的能力,而不受噪声人工干扰。
Paper
Code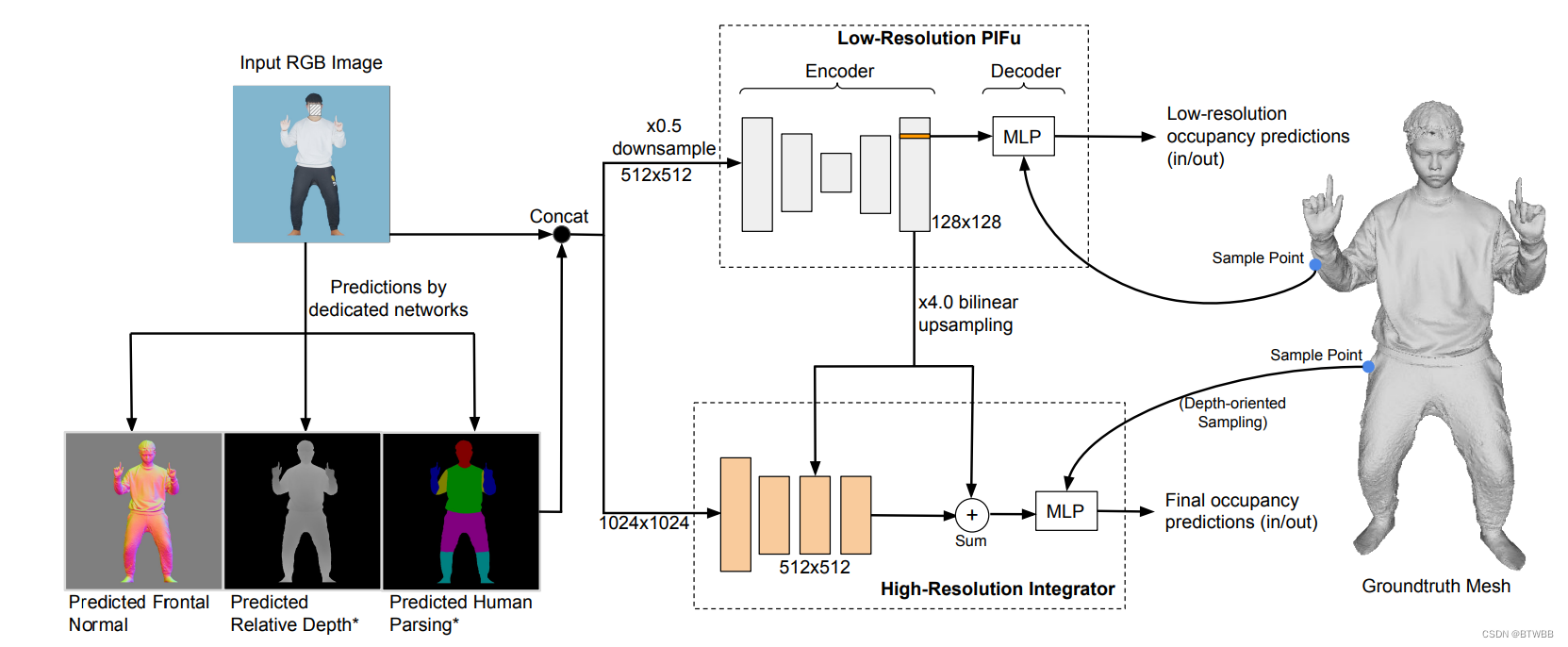
版权归原作者 BTWBB 所有, 如有侵权,请联系我们删除。