
highway-env自定义高速路环境
问题描述
highway-env自车(ego vehicle)初始状态(位置,速度)可以根据给出的API进行设置,但周围车辆(other vehicles)初始状态为随机生成,不可设置(环境开发作者说的,见下图)。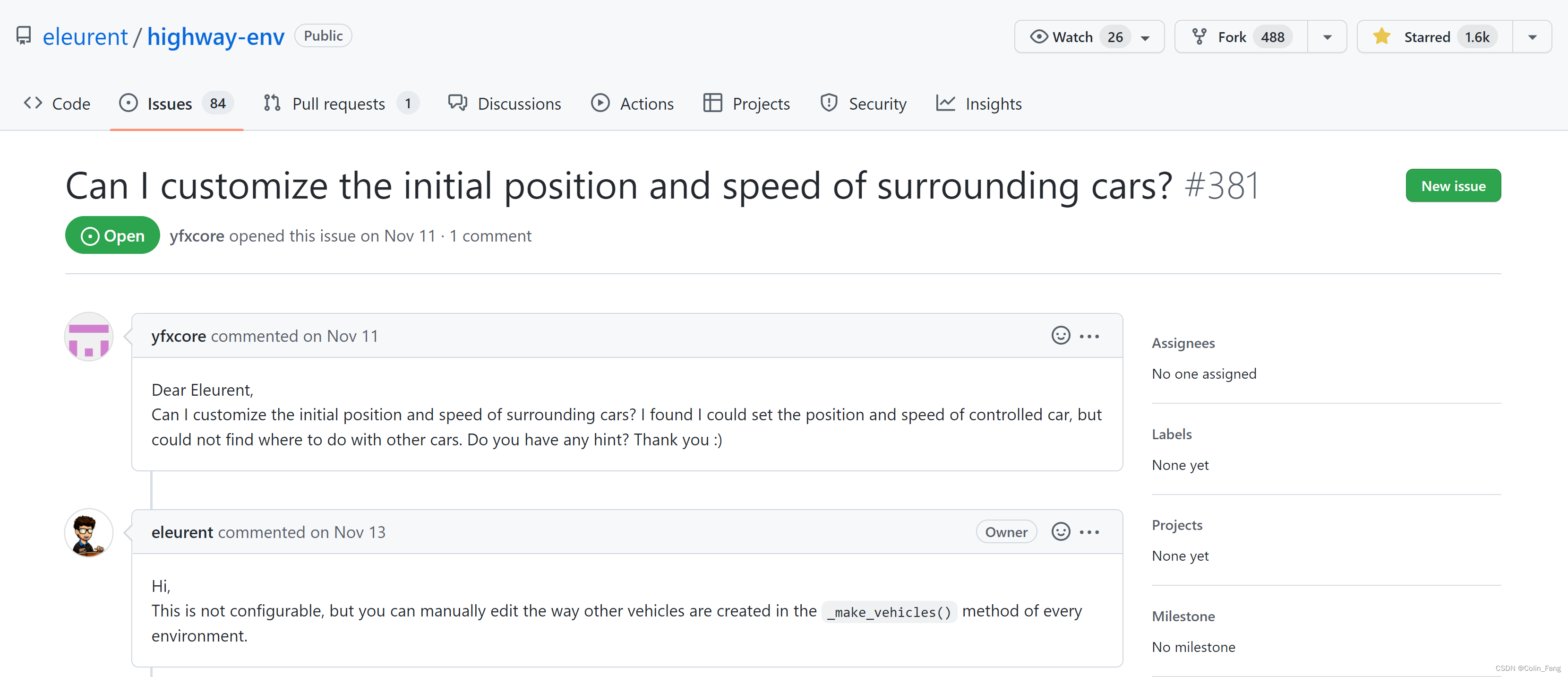
问题测试
import gym
import highway_env
# Create environment
env = gym.make("highway-v0")
env.configure({'observation':{'type':'Kinematics',"absolute":False,"normalize":False},'action':{'type':'DiscreteMetaAction'},'simulation_frequency':15,'policy_frequency':10,'other_vehicles_type':'highway_env.vehicle.behavior.IDMVehicle','screen_width':600,'screen_height':150,'centering_position':[0.3,0.5],'scaling':5.5,'show_trajectories':False,'render_agent':True,'offscreen_rendering':False,'manual_control':False,'real_time_rendering':False,'lanes_count':2,# 车道数'vehicles_count':1,# 周围车辆数'controlled_vehicles':1,'initial_lane_id':None,'duration':100,'ego_spacing':2,'vehicles_density':1,'collision_reward':-1,'right_lane_reward':0.1,'high_speed_reward':0.4,'lane_change_reward':0,'reward_speed_range':[20,30],'offroad_terminal':False,'lane_from':1})
eposides =10
rewards =0for eq inrange(eposides):
obs = env.reset()
env.render()
done =Falsewhilenot done:
action = env.action_space.sample()
obs, reward, done, info = env.step(action)
env.render()
rewards += reward
print(rewards)
测试视频如下:highway_setting。上述代码中,定义了两辆车:一辆为自车,一辆为周围车辆,想要实现的场景为,两辆车初始在同一条车道,前车速度慢,后车根据驾驶场景,采用强化学习来实现超车然后换回本车道。然后视频可看出,自车初始化在id为1的车道,周围车辆初始化随机出现在两车道中。
依赖包版本
gym == 0.21.0
highway-env == 1.5
单车控制环境
根据上述无法自定义设置周围车辆,解决方案为:按照自车定义方式,然后加入到道路中,但不加入到控制车辆内,这里重写了奖励函数,代码如下:
import highway_env
from highway_env.envs.common.abstract import AbstractEnv
from highway_env.road.road import Road, RoadNetwork
from highway_env.envs.common.action import Action
from highway_env.vehicle.controller import ControlledVehicle
from highway_env.vehicle.kinematics import Vehicle
LANES =2
ANGLE =0
START =0
LENGHT =200
SPEED_LIMIT =30
SPEED_REWARD_RANGE =[10,30]
COL_REWARD =-1
HIGH_SPEED_REWARD =0
RIGHT_LANE_REWARD =0
DURATION =100.0classmyEnv(AbstractEnv):@classmethoddefdefault_config(cls)->dict:
config =super().default_config()
config.update({'observation':{'type':'Kinematics',"absolute":False,"normalize":False},'action':{'type':'DiscreteMetaAction'},"reward_speed_range": SPEED_REWARD_RANGE,"simulation_frequency":20,"policy_frequency":20,"centering_position":[0.3,0.5],})return config
def_reset(self)->None:
self._create_road()
self._create_vehicles()def_create_road(self)->None:
self.road = Road(
network=RoadNetwork.straight_road_network(LANES, speed_limit=SPEED_LIMIT),
np_random=self.np_random,
record_history=False,)# 创建车辆def_create_vehicles(self)->None:
vehicle = Vehicle.create_random(self.road, speed=23, lane_id=1, spacing=0.3)
vehicle = self.action_type.vehicle_class(
self.road,
vehicle.position,
vehicle.heading,
vehicle.speed,)
self.vehicle = vehicle
self.road.vehicles.append(vehicle)
vehicle = Vehicle.create_random(self.road, speed=30, lane_id=1, spacing=0.35)
vehicle = self.action_type.vehicle_class(
self.road,
vehicle.position,
vehicle.heading,
vehicle.speed,)
self.road.vehicles.append(vehicle)# 重写的奖励函数,仅考虑车辆碰撞影响def_reward(self, action: Action)->float:
reward =0
lane =(
self.vehicle.target_lane_index[2]ifisinstance(self.vehicle, ControlledVehicle)else self.vehicle.lane_index[2])if self.vehicle.crashed:
reward =-1elif lane ==0:
reward +=1
reward =0ifnot self.vehicle.on_road else reward
return reward
def_is_terminal(self)->bool:return(
self.vehicle.crashed
or self.time >= DURATION
or(Falseandnot self.vehicle.on_road))if __name__ =='__main__':
env = myEnv()
obs = env.reset()
eposides =10
rewards =0for eq inrange(eposides):
obs = env.reset()
env.render()
done =Falsewhilenot done:
action = env.action_space.sample()
obs, reward, done, info = env.step(action)
env.render()
rewards += reward
print(rewards)
测试视频如下:highway_env_single,从视频可看出,两辆车均初始化在同一个车道。但存在颜色没法区分问题,有知道的小伙伴可以留言讨论一下哦。
多车控制环境
import random
import highway_env
from highway_env.envs.common.abstract import AbstractEnv
from highway_env.road.road import Road, RoadNetwork
from highway_env.envs.common.action import Action
from highway_env.vehicle.controller import ControlledVehicle
from highway_env.vehicle.kinematics import Vehicle
LANES =2
ANGLE =0
START =0
LENGHT =200
SPEED_LIMIT =30
SPEED_REWARD_RANGE =[10,30]
COL_REWARD =-1
HIGH_SPEED_REWARD =0
RIGHT_LANE_REWARD =0
DURATION =100.0classmyEnv(AbstractEnv):@classmethoddefdefault_config(cls)->dict:
config =super().default_config()
config.update({"observation":{"type":"MultiAgentObservation","observation_config":{"type":"Kinematics","vehicles_count":2,"features":["x","y","vx","vy"],"absolute":True,},},"action":{"type":"MultiAgentAction","action_config":{"type":"DiscreteMetaAction",},},"reward_speed_range": SPEED_REWARD_RANGE,"simulation_frequency":20,"policy_frequency":20,"centering_position":[0.3,0.5],})return config
def_reset(self)->None:
self._create_road()
self._create_vehicles()def_create_road(self)->None:
self.road = Road(
network=RoadNetwork.straight_road_network(LANES, speed_limit=SPEED_LIMIT),
np_random=self.np_random,
record_history=False,)def_create_vehicles(self)->None:
self.controlled_vehicles =[]
vehicle = Vehicle.create_random(self.road, speed=23, lane_id=1, spacing=0.3)
vehicle = self.action_type.vehicle_class(
self.road,
vehicle.position,
vehicle.heading,
vehicle.speed,)
self.controlled_vehicles.append(vehicle)
self.road.vehicles.append(vehicle)
vehicle = Vehicle.create_random(self.road, speed=30, lane_id=1, spacing=0.35)
vehicle = self.action_type.vehicle_class(
self.road,
vehicle.position,
vehicle.heading,
vehicle.speed,)
self.controlled_vehicles.append(vehicle)
self.road.vehicles.append(vehicle)def_reward(self, action: Action)->float:
reward =0
lane =(
self.vehicle.target_lane_index[2]ifisinstance(self.vehicle, ControlledVehicle)else self.vehicle.lane_index[2])if self.vehicle.crashed:
reward =-1elif lane ==0:
reward +=1
reward =0ifnot self.vehicle.on_road else reward
return reward
def_is_terminal(self)->bool:return(
self.vehicle.crashed
or self.time >= DURATION
or(Falseandnot self.vehicle.on_road))if __name__ =='__main__':
env = myEnv()
obs = env.reset()
eposides =10
rewards =0for eq inrange(eposides):
obs = env.reset()
env.render()
done =Falsewhilenot done:# action = env.action_space.sample()
action1 = random.sample([0,1,2,3,4],1)[0]
action2 =1
action =(action1,action2)
obs, reward, done, info = env.step(action)
env.render()
rewards += reward
print(rewards)
测试视频如下:highway_env_muti
后记
highway-env: 手册
本文转载自: https://blog.csdn.net/ColinFhz/article/details/128348828
版权归原作者 Colin_Fang 所有, 如有侵权,请联系我们删除。
版权归原作者 Colin_Fang 所有, 如有侵权,请联系我们删除。