
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀**对毕设有任何疑问都可以问学长哦!**
选题指导:
最新最全计算机专业毕设选题精选推荐汇总
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯基于深度学习的交通车速车流量检测系统
设计思路
一、课题背景与意义
随着城市交通的不断发展和增长,车速和车流量的检测对于交通管理和规划变得越来越重要。传统的交通检测方法通常基于传感器设备,但其成本高昂且覆盖范围有限。随着深度学习和计算机视觉技术的迅速发展,基于图像和视频的交通车速车流量检测系统成为一种具有广阔应用前景的新兴解决方案。该系统可以通过分析交通场景中的图像和视频数据,实时准确地检测和估计车辆的速度和流量信息,从而为交通管理和智能交通系统提供重要的数据支持。
二、算法理论原理
2.1 注意力机制
注意力机制是为了嵌入机器学习算法模型中,让模型能够自主学习并计算输入对输出的贡献,从而生成新的权重校准特征映射。在计算机视觉领域,注意力机制通过学习一组权重系数,对不同的输入进行概率动态加权,强调感兴趣的区域并抑制不相关的背景区域,以更好地识别与任务相关的特征。通道域注意力和空间域注意力是注意力机制的两种类型,其中通道域注意力在深度学习算法中具有重要作用。高效通道注意力机制(ECA)是对经典通道注意力机制的创新,通过规避维度缩减和减少参数量的方式改善了通道间的信息交换方式。ECA注意力机制可以方便地嵌入网络中,对输入特征图进行通道特征增强,并输出经过ECA模块处理后的特征图,而不改变其大小。
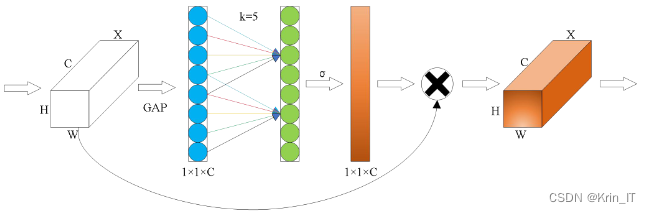
ECA注意力模块的前向传播过程如下:首先,通过全局平均池化操作(GAP)将输入特征图降维为一个大小为1x1xC的向量,其中C表示通道数。然后,通过一维卷积操作计算自适应的卷积核,该卷积核的大小为k。一维卷积操作会计算每个通道的权重大小,并且以组的形式存在,因此卷积核的大小决定了权重的数量。ECA注意力模块通过权重共享机制,使每个组具有相同的权重大小,从而减少了网络的参数量。权重的数量从k*C缩减到k。然而,对于不同大小的通道数C,k的大小也会不同,ECA提出了一种自适应的方法来确定k的大小。
标准卷积是常用的卷积操作,它使用一个卷积核同时处理输入特征图的所有通道。标准卷积在计算中需要较多的参数和计算量,适用于通道数较少的情况。
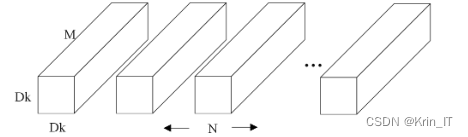
深度可分离卷积是一种卷积操作,它分为深度卷积和逐点卷积两个步骤。深度卷积首先对输入特征图的每个通道进行独立的卷积操作,生成与通道数相同的中间特征图。然后,逐点卷积将中间特征图与1x1的卷积核进行卷积操作,生成最终的特征图。深度可分离卷积可以显著减少参数量和计算量,适用于通道数较多的情况,同时保持相对较好的性能。

2.2 跟踪算法
DeepSORT是一种基于深度学习的多目标跟踪算法,它结合了目标检测和目标跟踪的技术,能够在复杂场景下准确地跟踪多个目标。DeepSORT通过深度学习模型提取目标的特征表示,辅以目标关联和运动预测的技术,能够准确地跟踪目标物体并在目标重叠或遮挡的情况下进行正确的关联。深度学习模型能够学习到更具有判别性的特征表示,从而提高目标的识别和跟踪准确性。DeepSORT在目标关联阶段使用贪婪的最近邻匹配算法,能够根据目标之间的相似性进行可靠的关联。此外,DeepSORT还引入了外观相似度等匹配规则,能够在目标外貌变化较大或相似目标存在的情况下有效地区分和跟踪不同的目标,提高了算法的鲁棒性。
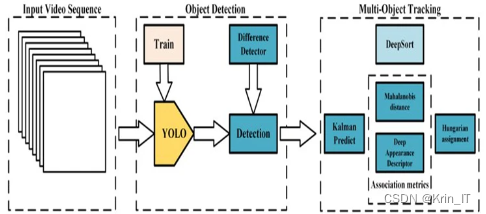
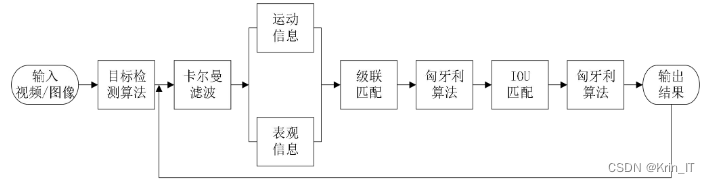
DeepSORT算法在原始SORT算法的基础上引入了级联匹配、物体的表观信息以及对新轨迹的确认等步骤。具体步骤如下:
- 对于第一帧检测到的目标,创建对应的轨迹,并进行卡尔曼滤波预测得到运动轨迹。此时轨迹处于不确定状态。
- 进入下一帧,采用IOU匹配方式,将当前帧的目标检测框与上一帧通过卡尔曼滤波预测得到的轨迹框进行逐一匹配,计算代价矩阵。
- 使用匈牙利算法将代价矩阵作为输入,得到线性的匹配结果。匹配结果可能有三种情况:轨迹失配、检测失配和成功匹配。 - 轨迹失配:将失配的轨迹删除。- 检测失配:将失配的检测框初始化为新的轨迹。- 成功匹配:对匹配成功的检测框使用卡尔曼滤波进行更新,并更新对应的轨迹变量。
- 循环执行步骤2和步骤3,直到出现确认态的轨迹或视频结束。
- 经过卡尔曼滤波预测后,得到不确定态轨迹对应的预测框和确认态目标轨迹。使用级联匹配将确认态的检测框和轨迹进行匹配,并利用检测框和目标的表观信息和运动信息,提升跟踪性能。
- 级联匹配后可能有两种结果: - 轨迹匹配:通过卡尔曼滤波更新匹配成功的轨迹变量。- 检测框和轨迹失配:将之前的不确定态轨迹和失配的轨迹分别与检测失配的框进行IOU匹配,通过IOU匹配结果计算代价矩阵。
- 将所有代价矩阵作为匈牙利算法的输入,进行匹配,同步骤3。
- 循环执行步骤5到步骤7,直到视频结束。
三、检测的实现
3.1 数据集
由于网络上没有现有的合适的数据集,我决定自己去采集数据。我选择了多个交通场景并使用摄像设备进行拍摄,包括道路、高速公路、城市街道等。通过这些现场拍摄,我能够捕捉到真实的交通场景和多样的车辆行驶情况,这将为我的研究提供更准确、可靠的数据。我还使用了计算机视觉技术和图像处理算法对采集到的图像进行预处理和标注,以便进行车速和车流量的检测和估计。通过自制的数据集,我相信能为交通车速车流量检测系统的研究提供有力的支持,并为该领域的发展做出积极贡献。

为了增加数据集的多样性和数量,我使用了数据增强技术对采集到的图像进行扩充。这包括图像翻转、旋转、缩放、平移等操作,以生成更多样的图像样本。通过数据扩充,我能够增加数据集的丰富性,提高模型的泛化能力,并改善交通车速车流量检测系统的性能。数据扩充是一个有效的方法,可以通过模拟真实场景中的各种变化和变形,提高模型在不同条件下的鲁棒性和准确性。通过数据扩充,我能够更好地应对各种复杂的交通场景和变化,为交通管理和规划提供更准确可靠的数据支持。
def random_scale(image, scale_range=(0.8, 1.2)):
scale_factor = np.random.uniform(scale_range[0], scale_range[1])
height, width = image.shape[:2]
new_height, new_width = int(height * scale_factor), int(width * scale_factor)
image = cv2.resize(image, (new_width, new_height))
return image
def random_translate(image, translate_range=(-20, 20)):
translate_x = np.random.randint(translate_range[0], translate_range[1])
translate_y = np.random.randint(translate_range[0], translate_range[1])
M = np.float32([[1, 0, translate_x], [0, 1, translate_y]])
height, width = image.shape[:2]
image = cv2.warpAffine(image, M, (width, height))
return image
def random_rotate(image, angle_range=(-10, 10)):
angle = np.random.uniform(angle_range[0], angle_range[1])
height, width = image.shape[:2]
center = (width / 2, height / 2)
M = cv2.getRotationMatrix2D(center, angle, 1.0)
image = cv2.warpAffine(image, M, (width, height))
return image
def random_flip(image, flip_prob=0.5):
if np.random.uniform() < flip_prob:
image = cv2.flip(image, 1)
return image
3.2 实验环境搭建

3.3 实验及结果分析
目标检测算法的评价指标包括准确率、召回率、平均精度和速度(FPS)。准确率衡量了算法在预测为正类的样本中的准确性,召回率衡量了算法正确检测出真实正类样本的能力。平均精度是在不同召回率下准确率的平均值,用于评估算法在不同阈值下的性能。速度(FPS)表示算法处理每秒帧数的效率。除了这些常用指标,还可使用F1分数、IoU等指标来综合评估算法的性能。综合考虑这些指标能够全面评估目标检测算法的准确性、召回率、整体性能和处理速度。

注意力模块能够通过自适应地调整特征图的权重分配,强化对重要特征的关注,抑制对不重要特征的干扰。这种机制可以提高模型对车辆目标的检测能力,尤其对于小目标和被遮挡目标的检测更加有效。通过将注意力模块嵌入主干网络,网络可以更加有针对性地关注重要的车辆特征,提高检测的准确性和召回率。
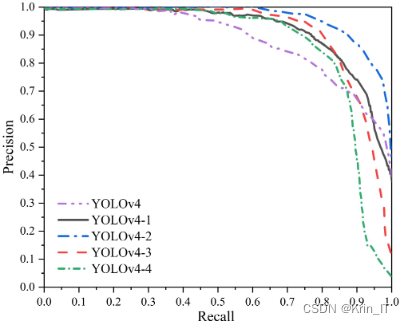
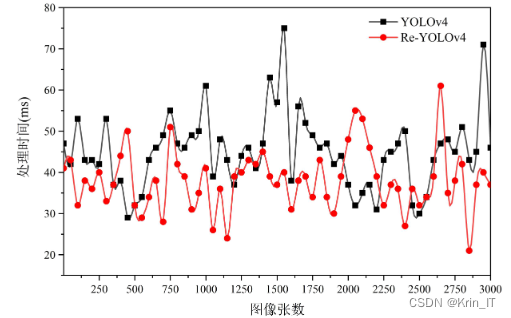
通过对比实验的结果,可以评估轻量化后网络模型在性能和速度方面的权衡。如果轻量化后的网络模型在保持较高性能的同时能够显著提高检测速度,那么该轻量化处理可以被认为是有效的,并且能够增强检测算法的实时性和应用范围。
相关代码示例:
class_ids = []
confidences = []
boxes = []
for out in outs:
for detection in out:
scores = detection[5:]
class_id = np.argmax(scores)
confidence = scores[class_id]
if confidence > 0.5 and class_id in [0, 1, 2, 3]:
# 检测到车辆
center_x = int(detection[0] * width)
center_y = int(detection[1] * height)
w = int(detection[2] * width)
h = int(detection[3] * height)
# 计算车辆边界框的坐标
x = int(center_x - w / 2)
y = int(center_y - h / 2)
# 保存车辆信息
class_ids.append(class_id)
confidences.append(float(confidence))
boxes.append([x, y, w, h])
# 绘制车辆边界框和类别标签
cv2.rectangle(frame, (x, y), (x + w, y + h), (0, 255, 0), 2)
cv2.putText(frame, classes[class_id], (x, y - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2)
# 车流量统计
vehicle_count += len(boxes)
# 在图像上显示车流量
cv2.putText(frame, "Vehicle Count: " + str(vehicle_count), (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 0.8, (0, 0, 255), 2)
# 显示检测结果
cv2.imshow("Traffic Detection", frame)
创作不易,欢迎点赞、关注、收藏。
毕设帮助,疑难解答,欢迎打扰!
最后
本文转载自: https://blog.csdn.net/2301_79555157/article/details/136009771
版权归原作者 Krin_IT 所有, 如有侵权,请联系我们删除。
版权归原作者 Krin_IT 所有, 如有侵权,请联系我们删除。