
前言:
在工作或学习中我们需要进行部署,下面这篇文章是我亲自部署jetson nano之后做出的总结,包括自己遇到一些报错和踩坑,希望对你们有所帮助**: )**
一、准备工具
- 读卡器
- SD卡
- 小螺丝刀
- 网线(更改语言需要网络)
二、烧录
烧录镜像就是要把SD卡里的东西给完全清除,好比我们电脑重装系统一样,把SD卡格式化。
插上读卡器后会自动识别U盘,我的电脑会识别很多,弹出很多个U盘选项,这个是正常现象,只格式化一个就可以了。

1. 在本地的电脑上下载烧录的镜像,可以去官网自行下载,下载的时候需要看好版本,不然会出问题,我下载的版本是4.4.1,下载的网址如下:
JetPack SDK 4.4.1 archive | NVIDIA Developer

**2. **下载好之后进行解压:

**3. **然后我们需要下载烧录SD卡的工具,网址如下:
Get Started With Jetson Nano Developer Kit | NVIDIA Developer
下载完之后是一个.exe可执行文件,运行安装就可以了。

4. 开始烧录镜像
运行上面下载好的Etcher之后是这样的,选择完镜像之后会自动识别SD卡,让后点击flash
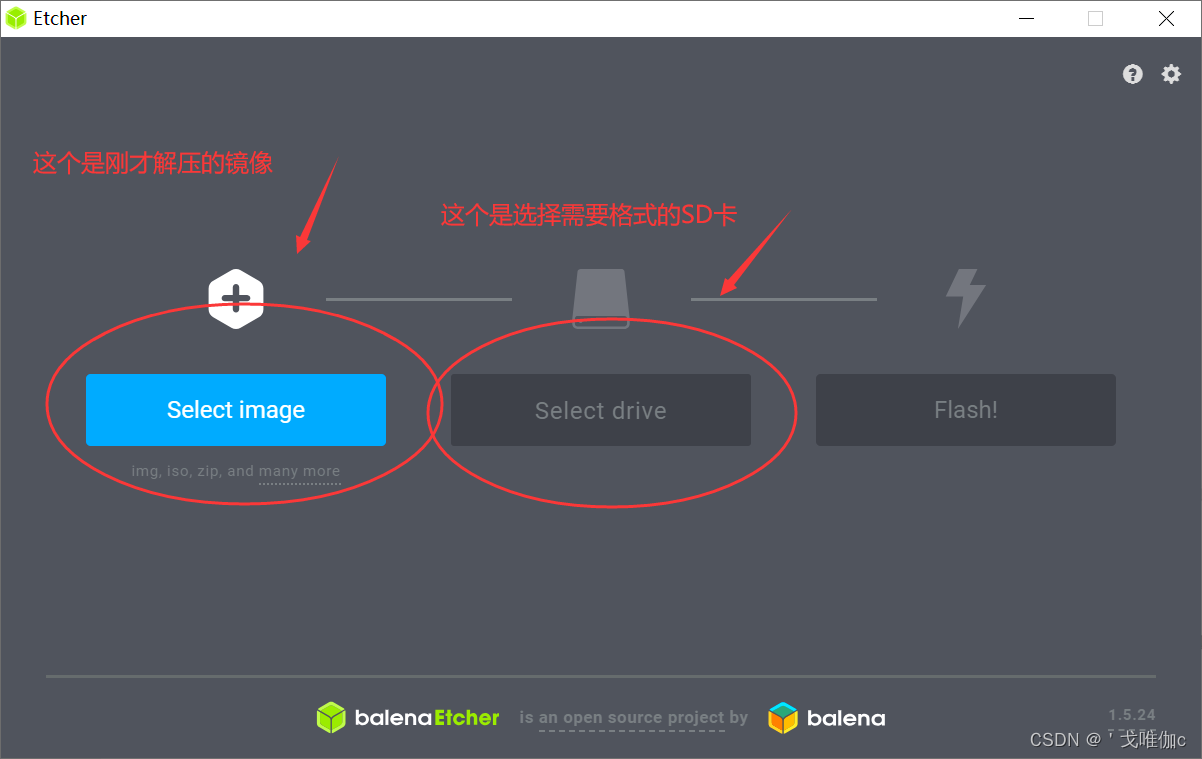
这个是正在烧录的界面,会自动烧录2遍(大约20分钟左右)

**5.**烧录完成,弹出读卡器,插卡开机。

**6.**开机之后,简单设置一下(密码、地区、时间),然后会就是和我们本地电脑Ubuntu界面差不多。
三、搭配环境
**1. **配置CUDA
首先打开终端(ctrl+alt+t),输入以下命令:
sudo gedit ~/.bashrc
输入密码后进入文档:
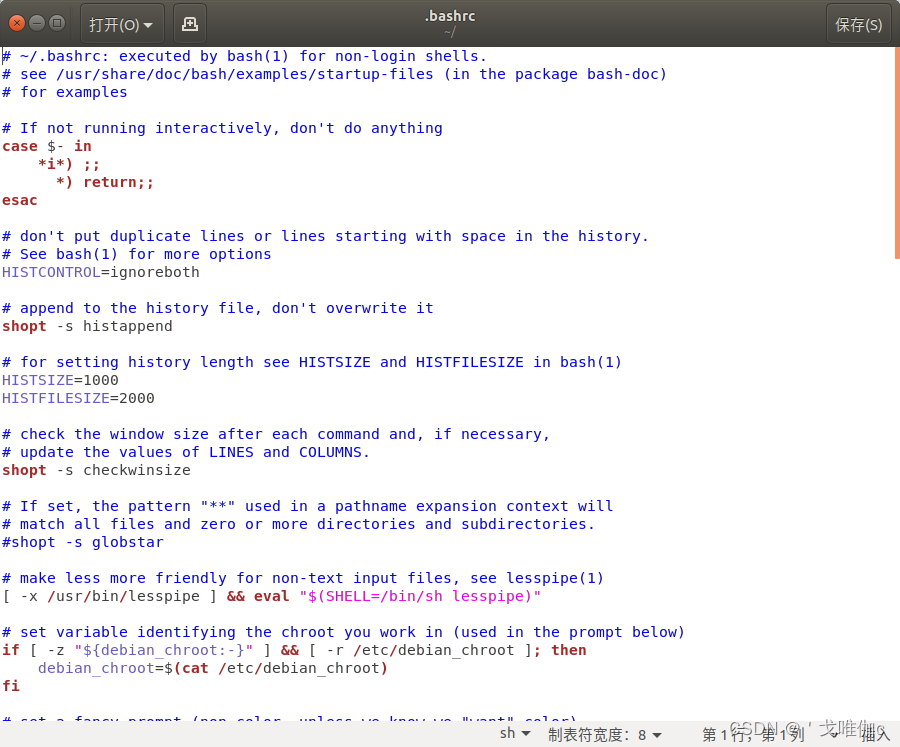
鼠标滚轮滚到文档最下面,输入下面命令,然后按ctrl+s保存:
export CUDA_HOME=/usr/local/cuda-10.2
export LD_LIBRARY_PATH=/usr/local/cuda-10.2/lib64:$LD_LIBRARY_PATH
export PATH=/usr/local/cuda-10.2/bin:$PATH
验证CUDA是否安装配置成功 :
nvcc -V
出现这个就证明配置成功了。

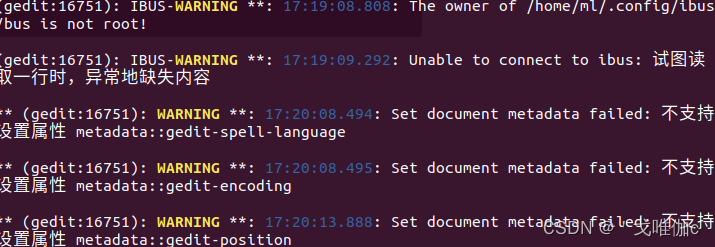
报错
我输出之后会出现读取异常,或者不允许保存的提示,然后运行nvcc -V的时候显示命令不可执行,这个多输入几次或者关闭终端再输入几次命令
2. 配置conda
jetson nanoB01的架构是aarch64,与windows和liunx不同不同,所以不能安装Anaconda,可以安装一个替代它的archiconda。
在终端输入以下下载命令:
wget https://github.com/Archiconda/build-tools/releases/download/0.2.3/Archiconda3-0.2.3-Linux-aarch64.sh
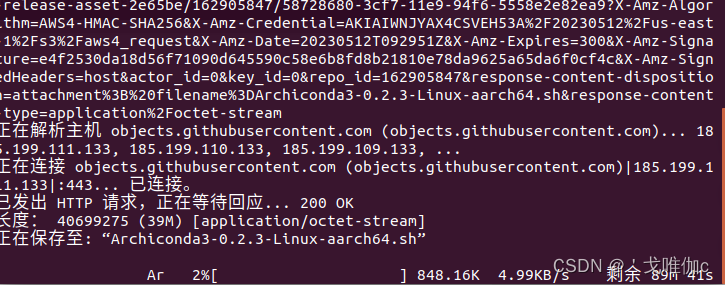
下载成功。 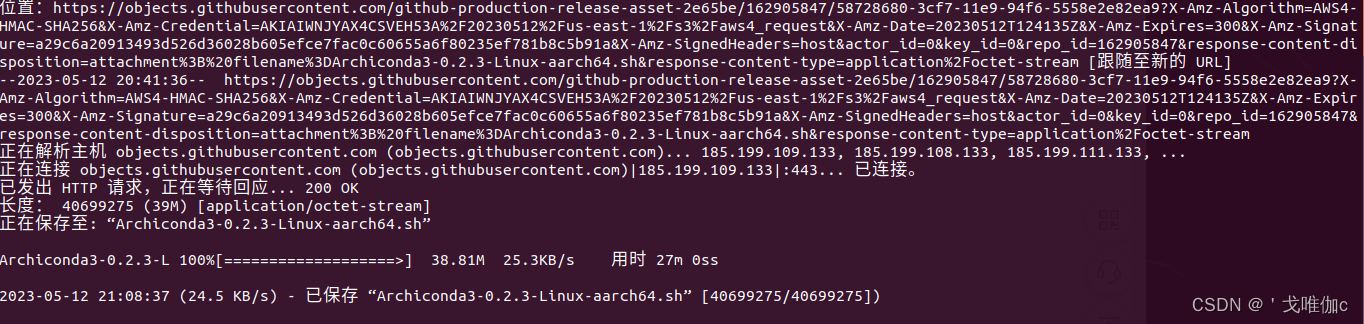
*** 报错***
遇到下载一半或者下载到99%之后报错的问题。
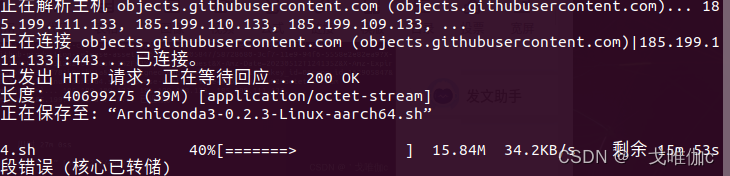
这个问题是因为堆栈小的原因,改一下堆栈大小就可以了。
先查一以下自己的系统堆栈大小,用这个命令:
ulimit -a
stack size是堆栈的大小,我原来是8192,需要改成102400

直接用代码 ulimit -s 102400 修改,改完之后:

下载好之后运行这个命令:
bash Archiconda3-0.2.3-Linux-aarch64.sh
接下来就是傻瓜式的安装:
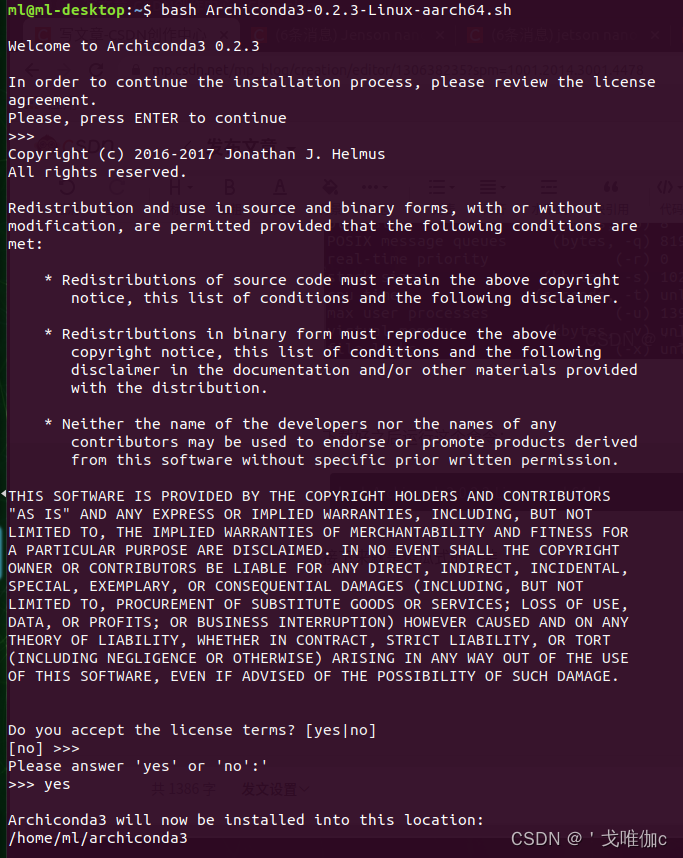
安装完之后配置环境变量:
sudo gedit ~/.bashrc

在最初打开的文档里的最后一行加上这个命令:
export PATH=~/archiconda3/bin:$PATH
查看conda的版本号:
conda -V
3. 创建你自己的虚拟环境:
conda create -n xxx(虚拟环境名) python=3.6 #创建一个python3.6的虚拟环境
conda activate xxx #进入虚拟环境
conda deactivate #(退出虚拟环境)
4. 换源
首先需要备份一下sources.list文件,执行后终端没有响应
sudo cp /etc/apt/sources.list /etc/apt/sources.list.bak
进入sources.list内部
sudo gedit /etc/apt/sources.list
进入之后,ctrl+a删除所有内容,之后将以下内容复制进去保存退出。
deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ bionic main multiverse restricted universe
deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ bionic-security main multiverse restricted universe
deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ bionic-updates main multiverse restricted universe
deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ bionic-backports main multiverse restricted universe
deb-src http://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ bionic main multiverse restricted universe
deb-src http://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ bionic-security main multiverse restricted universe
deb-src http://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ bionic-updates main multiverse restricted universe
deb-src http://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ bionic-backports main multiverse restricted universe

然后更新软件列表,保存到本地:
sudo apt-get update

更新软件:
sudo apt-get upgrade
升级所有的安装包,并解决依赖关系
sudo apt-get dist-upgrade
**5. **安装pip
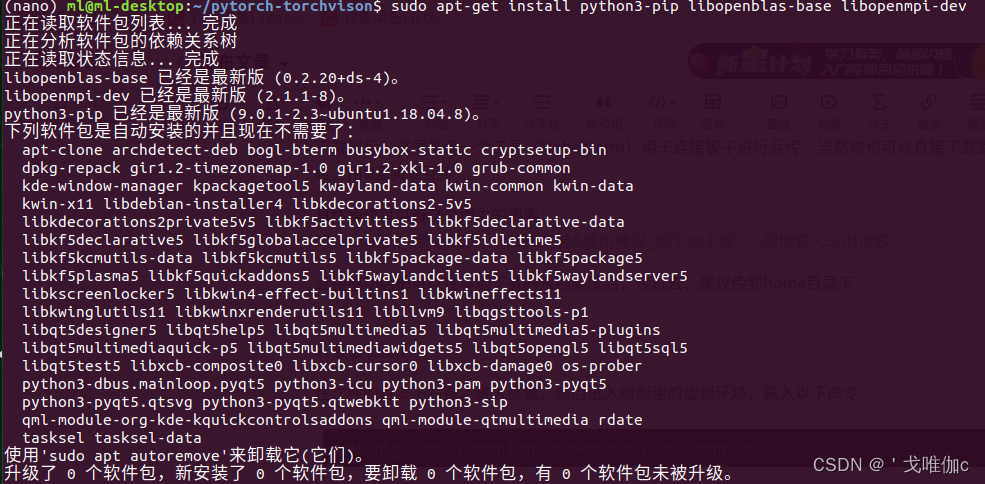
sudo apt-get install python3-pip libopenblas-base libopenmpi-dev
更新pip到最新版本
pip3 install --upgrade pip #如果pip已是最新,可不执行
** 6. **下载torch和torchvision
nano上安装需要去英伟达官网下载所需版本,我这里是1.8.0,网址如下:
PyTorch for Jetson - version 1.10 now available - Jetson Nano - NVIDIA Developer Forums

下载好后,这里推荐一个工具(MobaXterm)用于连接板子进行互传,当然你也可以直接下载到U盘,用U盘实现互传。
具体操作可以看这个博主的博客:MobaXterm(终端工具)下载&安装&使用教程_蜗牛也不慢......的博客-CSDN博客
连接成功后把可以在本地下载的东西解压后,传过去,建议传到home目录下。
**7. **安装torch
在torchvision文件夹的目录下右键,进入终端,然后进入你创建的虚拟环境,输入以下命令:
sudo apt-get install python3-pip libopenblas-base libopenmpi-dev
pip install torch-1.8.0-cp36-cp36m-linux_aarch64.whl
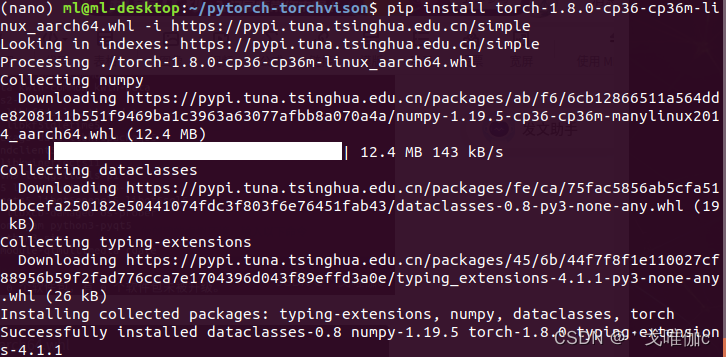
如果遇到网络问题下载不了,就在第二个命令下载后面加上清华下载镜像:
-i https://pypi.tuna.tsinghua.edu.cn/simple
安装torch时,一定要安装numpy,不然的话显示你安装torch成功,但是你conda list是找不到的。
sudo apt install python3-numpy

测试torch是否安装成功:
import torch
print(torch.__version__)
报错
在测试torch是否安装成功时报错:非法指令(核心已转储)。
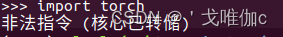
export OPENBLAS_CORETYPE=ARMV8
8. 安装torchvision,逐个执行以下命令(如果执行第三个命令报错,继续执行第四第五行命令,如果不报错就直接cd ..)
cd torchvision
export BUILD_VERSION=0.9.0
sudo python setup.py install
python setup.py build
python setup.py install
cd .. #(中间有个空格)
报错
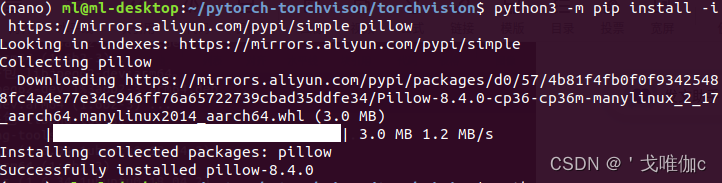
在测试时如果报错PIL,就安装pillow,命令如下(在第二步如果报权限错误,就在开头加sudo,或在结尾加--user)

sudo apt-get install libjpeg8 libjpeg62-dev libfreetype6 libfreetype6-dev
python3 -m pip install -i https://mirrors.aliyun.com/pypi/simple pillow

到这里为止环境就全部搭建完毕了,下面开始部署Yolo5。
** **四、试跑Yolov5
**1. **去官网上下载需要的版本,我这里下载的是5.0版本,下载的时候要把对应的权重也要下载。网址如下:
ultralytics/yolov5 at v5.0 (github.com)
在这里选择版本:

权重网址如下:
Releases · ultralytics/yolov5 (github.com)

**2. **下载完或者使用工具将yolo5和权重文件拖到主目录之后,使用cd进入yolo5文件目录下,在终端下载依赖项:
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
** 报错**
遇到下面的问题是因为numpy版本过高导致的,降低以下版本就可以了。

把版本降低到1.19.4:
pip install numpy==1.19.4 -i https://pypi.tuna.tsinghua.edu.cn/simple

解决完报错之后,在运行上面的命令,会自动下载需要的安装包,其他的都是很快的,但是到opencv的时候需要花费很长很长很长很长的时间......,当安装opencv时会出现Building wheel for opencv-python (pyroject.toml)... 这种情况正常现象,是opencv在编译,继续等就可以了,我编译了2个多小时...
3. 经过N长时间的等待,安装好所有依赖包后,将权重文件拖到yolov5文件夹根目录下,在yolov5的根目录下打开终端,执行以下命令:
python3 detect.py --weights yolov5s.pt

测试一下是没问题的,接下来我们开始部署yolov5。
五、tensorRT部署yolov5
**1. **tensorRT官网下载yolov5,网址如下,确定下载是v5.0版本:
mirrors / wang-xinyu / tensorrtx · GitCode
mirrors / wang-xinyu / tensorrtx · GitCodeImplementation of popular deep learning networks with TensorRT network definition API 🚀 Github 镜像仓库 🚀 源项目地址https://gitcode.net/mirrors/wang-xinyu/tensorrtx?utm_source=csdn_github_accelerator
**2. **下载完毕之后在文件夹里找到gen_wts.py,然后复制到yolov5文件夹下,右键打开终端,执行命令后生成yolov5.wts文件:
python3 gen_wts.py --w yolov5s.pt
注:每个人的文件路径不同,这个根据自己的途权重路径而改变,一般路径都在tensorrtx-yolov5-v5.0 -> yolov5 -> gen_wts.pt。

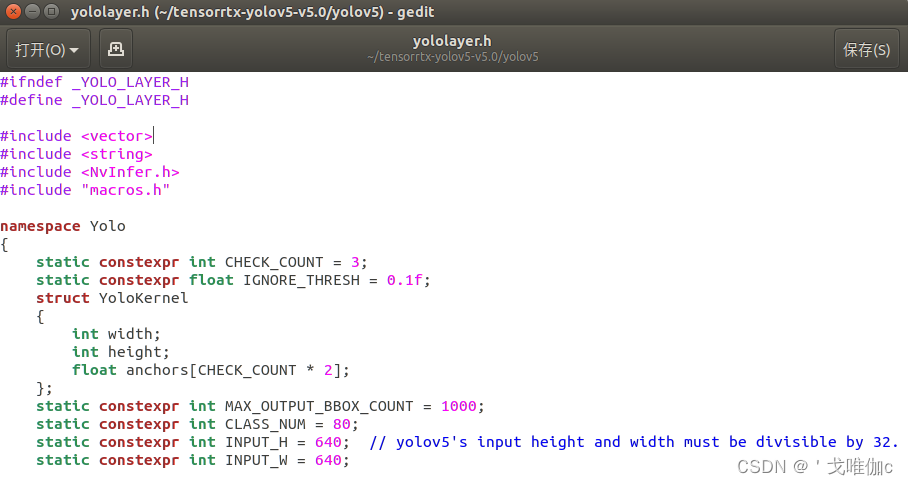
** 3. **找到yololayer.h文件,打开修改类别数量(根据自己的情况而定),和输入图片大小(修改是尽量是32的倍数)
**4. **在当前目录下创建文件build,命令如下:
maker build #创建build文件夹
cd build #进入build
cmake .. #构建项目
#将我们上面生成的.wts文件复制到build文件夹中
make
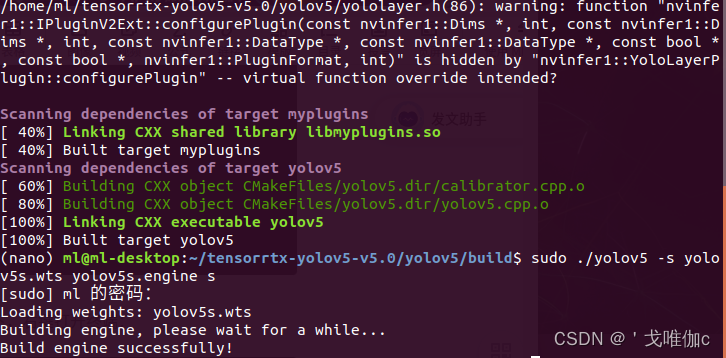
**5. **将上面生成的yolov5.wts文件拖到tensortx/yolov5下,右键打开终端:
sudo ./yolov5 -s yolov5s.wts yolov5s.engine s
**6. **在tensorrtx-yolov5-v5.0\yolov5下新建sample文件夹,在里面放一张需要测试的图片(尽量放人的图片)进行测试,命令如下 :
sudo ./yolov5 -d yolov5s.engine ../sample
注:运行之后 ,在build文件夹下会生成一张检测过的图片,但是效果不是很好,这个是正常现象。
**7. **测试图片看不出效果,并且真正部署到生产环境,交付给用户使用.是通过调用摄像头.所以要改一下tensorrtx-yolov5-v5.0 -> yolov5.cpp,可以参考网上大神的教程:
#include <iostream>
#include <chrono>
#include "cuda_utils.h"
#include "logging.h"
#include "common.hpp"
#include "utils.h"
#include "calibrator.h"
#define USE_FP16 // set USE_INT8 or USE_FP16 or USE_FP32
#define DEVICE 0 // GPU id
#define NMS_THRESH 0.4
#define CONF_THRESH 0.5
#define BATCH_SIZE 1
// stuff we know about the network and the input/output blobs
static const int INPUT_H = Yolo::INPUT_H;
static const int INPUT_W = Yolo::INPUT_W;
static const int CLASS_NUM = Yolo::CLASS_NUM;
static const int OUTPUT_SIZE = Yolo::MAX_OUTPUT_BBOX_COUNT * sizeof(Yolo::Detection) / sizeof(float) + 1; // we assume the yololayer outputs no more than MAX_OUTPUT_BBOX_COUNT boxes that conf >= 0.1
const char* INPUT_BLOB_NAME = "data";
const char* OUTPUT_BLOB_NAME = "prob";
static Logger gLogger;
//修改为自己的类别
char *my_classes[]={ "person", "bicycle", "car", "motorcycle", "airplane", "bus", "train", "truck", "boat", "traffic light",
"fire hydrant", "stop sign", "parking meter", "bench", "bird", "cat", "dog", "horse", "sheep", "cow",
"elephant", "bear", "zebra", "giraffe", "backpack", "umbrella", "handbag", "tie", "suitcase", "frisbee",
"skis", "snowboard", "sports ball", "kite", "baseball bat", "baseball glove", "skateboard","surfboard",
"tennis racket", "bottle", "wine glass", "cup", "fork", "knife", "spoon", "bowl", "banana", "apple",
"sandwich", "orange", "broccoli", "carrot", "hot dog", "pizza", "donut", "cake", "chair", "couch",
"potted plant", "bed", "dining table", "toilet", "tv", "laptop", "mouse", "remote", "keyboard", "cell phone",
"microwave", "oven", "toaster", "sink", "refrigerator", "book", "clock", "vase", "scissors", "teddy bear",
"hair drier", "toothbrush" };
static int get_width(int x, float gw, int divisor = 8) {
//return math.ceil(x / divisor) * divisor
if (int(x * gw) % divisor == 0) {
return int(x * gw);
}
return (int(x * gw / divisor) + 1) * divisor;
}
static int get_depth(int x, float gd) {
if (x == 1) {
return 1;
}
else {
return round(x * gd) > 1 ? round(x * gd) : 1;
}
}
//#创建engine和network
ICudaEngine* build_engine(unsigned int maxBatchSize, IBuilder* builder, IBuilderConfig* config, DataType dt, float& gd, float& gw, std::string& wts_name) {
INetworkDefinition* network = builder->createNetworkV2(0U);
// Create input tensor of shape {3, INPUT_H, INPUT_W} with name INPUT_BLOB_NAME
ITensor* data = network->addInput(INPUT_BLOB_NAME, dt, Dims3{ 3, INPUT_H, INPUT_W });
assert(data);
std::map<std::string, Weights> weightMap = loadWeights(wts_name);
/* ------ yolov5 backbone------ */
auto focus0 = focus(network, weightMap, *data, 3, get_width(64, gw), 3, "model.0");
auto conv1 = convBlock(network, weightMap, *focus0->getOutput(0), get_width(128, gw), 3, 2, 1, "model.1");
auto bottleneck_CSP2 = C3(network, weightMap, *conv1->getOutput(0), get_width(128, gw), get_width(128, gw), get_depth(3, gd), true, 1, 0.5, "model.2");
auto conv3 = convBlock(network, weightMap, *bottleneck_CSP2->getOutput(0), get_width(256, gw), 3, 2, 1, "model.3");
auto bottleneck_csp4 = C3(network, weightMap, *conv3->getOutput(0), get_width(256, gw), get_width(256, gw), get_depth(9, gd), true, 1, 0.5, "model.4");
auto conv5 = convBlock(network, weightMap, *bottleneck_csp4->getOutput(0), get_width(512, gw), 3, 2, 1, "model.5");
auto bottleneck_csp6 = C3(network, weightMap, *conv5->getOutput(0), get_width(512, gw), get_width(512, gw), get_depth(9, gd), true, 1, 0.5, "model.6");
auto conv7 = convBlock(network, weightMap, *bottleneck_csp6->getOutput(0), get_width(1024, gw), 3, 2, 1, "model.7");
auto spp8 = SPP(network, weightMap, *conv7->getOutput(0), get_width(1024, gw), get_width(1024, gw), 5, 9, 13, "model.8");
/* ------ yolov5 head ------ */
auto bottleneck_csp9 = C3(network, weightMap, *spp8->getOutput(0), get_width(1024, gw), get_width(1024, gw), get_depth(3, gd), false, 1, 0.5, "model.9");
auto conv10 = convBlock(network, weightMap, *bottleneck_csp9->getOutput(0), get_width(512, gw), 1, 1, 1, "model.10");
auto upsample11 = network->addResize(*conv10->getOutput(0));
assert(upsample11);
upsample11->setResizeMode(ResizeMode::kNEAREST);
upsample11->setOutputDimensions(bottleneck_csp6->getOutput(0)->getDimensions());
ITensor* inputTensors12[] = { upsample11->getOutput(0), bottleneck_csp6->getOutput(0) };
auto cat12 = network->addConcatenation(inputTensors12, 2);
auto bottleneck_csp13 = C3(network, weightMap, *cat12->getOutput(0), get_width(1024, gw), get_width(512, gw), get_depth(3, gd), false, 1, 0.5, "model.13");
auto conv14 = convBlock(network, weightMap, *bottleneck_csp13->getOutput(0), get_width(256, gw), 1, 1, 1, "model.14");
auto upsample15 = network->addResize(*conv14->getOutput(0));
assert(upsample15);
upsample15->setResizeMode(ResizeMode::kNEAREST);
upsample15->setOutputDimensions(bottleneck_csp4->getOutput(0)->getDimensions());
ITensor* inputTensors16[] = { upsample15->getOutput(0), bottleneck_csp4->getOutput(0) };
auto cat16 = network->addConcatenation(inputTensors16, 2);
auto bottleneck_csp17 = C3(network, weightMap, *cat16->getOutput(0), get_width(512, gw), get_width(256, gw), get_depth(3, gd), false, 1, 0.5, "model.17");
// yolo layer 0
IConvolutionLayer* det0 = network->addConvolutionNd(*bottleneck_csp17->getOutput(0), 3 * (Yolo::CLASS_NUM + 5), DimsHW{ 1, 1 }, weightMap["model.24.m.0.weight"], weightMap["model.24.m.0.bias"]);
auto conv18 = convBlock(network, weightMap, *bottleneck_csp17->getOutput(0), get_width(256, gw), 3, 2, 1, "model.18");
ITensor* inputTensors19[] = { conv18->getOutput(0), conv14->getOutput(0) };
auto cat19 = network->addConcatenation(inputTensors19, 2);
auto bottleneck_csp20 = C3(network, weightMap, *cat19->getOutput(0), get_width(512, gw), get_width(512, gw), get_depth(3, gd), false, 1, 0.5, "model.20");
//yolo layer 1
IConvolutionLayer* det1 = network->addConvolutionNd(*bottleneck_csp20->getOutput(0), 3 * (Yolo::CLASS_NUM + 5), DimsHW{ 1, 1 }, weightMap["model.24.m.1.weight"], weightMap["model.24.m.1.bias"]);
auto conv21 = convBlock(network, weightMap, *bottleneck_csp20->getOutput(0), get_width(512, gw), 3, 2, 1, "model.21");
ITensor* inputTensors22[] = { conv21->getOutput(0), conv10->getOutput(0) };
auto cat22 = network->addConcatenation(inputTensors22, 2);
auto bottleneck_csp23 = C3(network, weightMap, *cat22->getOutput(0), get_width(1024, gw), get_width(1024, gw), get_depth(3, gd), false, 1, 0.5, "model.23");
IConvolutionLayer* det2 = network->addConvolutionNd(*bottleneck_csp23->getOutput(0), 3 * (Yolo::CLASS_NUM + 5), DimsHW{ 1, 1 }, weightMap["model.24.m.2.weight"], weightMap["model.24.m.2.bias"]);
auto yolo = addYoLoLayer(network, weightMap, "model.24", std::vector<IConvolutionLayer*>{det0, det1, det2});
yolo->getOutput(0)->setName(OUTPUT_BLOB_NAME);
network->markOutput(*yolo->getOutput(0));
// Build engine
builder->setMaxBatchSize(maxBatchSize);
config->setMaxWorkspaceSize(16 * (1 << 20)); // 16MB
#if defined(USE_FP16)
config->setFlag(BuilderFlag::kFP16);
#elif defined(USE_INT8)
std::cout << "Your platform support int8: " << (builder->platformHasFastInt8() ? "true" : "false") << std::endl;
assert(builder->platformHasFastInt8());
config->setFlag(BuilderFlag::kINT8);
Int8EntropyCalibrator2* calibrator = new Int8EntropyCalibrator2(1, INPUT_W, INPUT_H, "./coco_calib/", "int8calib.table", INPUT_BLOB_NAME);
config->setInt8Calibrator(calibrator);
#endif
std::cout << "Building engine, please wait for a while..." << std::endl;
ICudaEngine* engine = builder->buildEngineWithConfig(*network, *config);
std::cout << "Build engine successfully!" << std::endl;
// Don't need the network any more
network->destroy();
// Release host memory
for (auto& mem : weightMap)
{
free((void*)(mem.second.values));
}
return engine;
}
ICudaEngine* build_engine_p6(unsigned int maxBatchSize, IBuilder* builder, IBuilderConfig* config, DataType dt, float& gd, float& gw, std::string& wts_name) {
INetworkDefinition* network = builder->createNetworkV2(0U);
// Create input tensor of shape {3, INPUT_H, INPUT_W} with name INPUT_BLOB_NAME
ITensor* data = network->addInput(INPUT_BLOB_NAME, dt, Dims3{ 3, INPUT_H, INPUT_W });
assert(data);
std::map<std::string, Weights> weightMap = loadWeights(wts_name);
/* ------ yolov5 backbone------ */
auto focus0 = focus(network, weightMap, *data, 3, get_width(64, gw), 3, "model.0");
auto conv1 = convBlock(network, weightMap, *focus0->getOutput(0), get_width(128, gw), 3, 2, 1, "model.1");
auto c3_2 = C3(network, weightMap, *conv1->getOutput(0), get_width(128, gw), get_width(128, gw), get_depth(3, gd), true, 1, 0.5, "model.2");
auto conv3 = convBlock(network, weightMap, *c3_2->getOutput(0), get_width(256, gw), 3, 2, 1, "model.3");
auto c3_4 = C3(network, weightMap, *conv3->getOutput(0), get_width(256, gw), get_width(256, gw), get_depth(9, gd), true, 1, 0.5, "model.4");
auto conv5 = convBlock(network, weightMap, *c3_4->getOutput(0), get_width(512, gw), 3, 2, 1, "model.5");
auto c3_6 = C3(network, weightMap, *conv5->getOutput(0), get_width(512, gw), get_width(512, gw), get_depth(9, gd), true, 1, 0.5, "model.6");
auto conv7 = convBlock(network, weightMap, *c3_6->getOutput(0), get_width(768, gw), 3, 2, 1, "model.7");
auto c3_8 = C3(network, weightMap, *conv7->getOutput(0), get_width(768, gw), get_width(768, gw), get_depth(3, gd), true, 1, 0.5, "model.8");
auto conv9 = convBlock(network, weightMap, *c3_8->getOutput(0), get_width(1024, gw), 3, 2, 1, "model.9");
auto spp10 = SPP(network, weightMap, *conv9->getOutput(0), get_width(1024, gw), get_width(1024, gw), 3, 5, 7, "model.10");
auto c3_11 = C3(network, weightMap, *spp10->getOutput(0), get_width(1024, gw), get_width(1024, gw), get_depth(3, gd), false, 1, 0.5, "model.11");
/* ------ yolov5 head ------ */
auto conv12 = convBlock(network, weightMap, *c3_11->getOutput(0), get_width(768, gw), 1, 1, 1, "model.12");
auto upsample13 = network->addResize(*conv12->getOutput(0));
assert(upsample13);
upsample13->setResizeMode(ResizeMode::kNEAREST);
upsample13->setOutputDimensions(c3_8->getOutput(0)->getDimensions());
ITensor* inputTensors14[] = { upsample13->getOutput(0), c3_8->getOutput(0) };
auto cat14 = network->addConcatenation(inputTensors14, 2);
auto c3_15 = C3(network, weightMap, *cat14->getOutput(0), get_width(1536, gw), get_width(768, gw), get_depth(3, gd), false, 1, 0.5, "model.15");
auto conv16 = convBlock(network, weightMap, *c3_15->getOutput(0), get_width(512, gw), 1, 1, 1, "model.16");
auto upsample17 = network->addResize(*conv16->getOutput(0));
assert(upsample17);
upsample17->setResizeMode(ResizeMode::kNEAREST);
upsample17->setOutputDimensions(c3_6->getOutput(0)->getDimensions());
ITensor* inputTensors18[] = { upsample17->getOutput(0), c3_6->getOutput(0) };
auto cat18 = network->addConcatenation(inputTensors18, 2);
auto c3_19 = C3(network, weightMap, *cat18->getOutput(0), get_width(1024, gw), get_width(512, gw), get_depth(3, gd), false, 1, 0.5, "model.19");
auto conv20 = convBlock(network, weightMap, *c3_19->getOutput(0), get_width(256, gw), 1, 1, 1, "model.20");
auto upsample21 = network->addResize(*conv20->getOutput(0));
assert(upsample21);
upsample21->setResizeMode(ResizeMode::kNEAREST);
upsample21->setOutputDimensions(c3_4->getOutput(0)->getDimensions());
ITensor* inputTensors21[] = { upsample21->getOutput(0), c3_4->getOutput(0) };
auto cat22 = network->addConcatenation(inputTensors21, 2);
auto c3_23 = C3(network, weightMap, *cat22->getOutput(0), get_width(512, gw), get_width(256, gw), get_depth(3, gd), false, 1, 0.5, "model.23");
auto conv24 = convBlock(network, weightMap, *c3_23->getOutput(0), get_width(256, gw), 3, 2, 1, "model.24");
ITensor* inputTensors25[] = { conv24->getOutput(0), conv20->getOutput(0) };
auto cat25 = network->addConcatenation(inputTensors25, 2);
auto c3_26 = C3(network, weightMap, *cat25->getOutput(0), get_width(1024, gw), get_width(512, gw), get_depth(3, gd), false, 1, 0.5, "model.26");
auto conv27 = convBlock(network, weightMap, *c3_26->getOutput(0), get_width(512, gw), 3, 2, 1, "model.27");
ITensor* inputTensors28[] = { conv27->getOutput(0), conv16->getOutput(0) };
auto cat28 = network->addConcatenation(inputTensors28, 2);
auto c3_29 = C3(network, weightMap, *cat28->getOutput(0), get_width(1536, gw), get_width(768, gw), get_depth(3, gd), false, 1, 0.5, "model.29");
auto conv30 = convBlock(network, weightMap, *c3_29->getOutput(0), get_width(768, gw), 3, 2, 1, "model.30");
ITensor* inputTensors31[] = { conv30->getOutput(0), conv12->getOutput(0) };
auto cat31 = network->addConcatenation(inputTensors31, 2);
auto c3_32 = C3(network, weightMap, *cat31->getOutput(0), get_width(2048, gw), get_width(1024, gw), get_depth(3, gd), false, 1, 0.5, "model.32");
/* ------ detect ------ */
IConvolutionLayer* det0 = network->addConvolutionNd(*c3_23->getOutput(0), 3 * (Yolo::CLASS_NUM + 5), DimsHW{ 1, 1 }, weightMap["model.33.m.0.weight"], weightMap["model.33.m.0.bias"]);
IConvolutionLayer* det1 = network->addConvolutionNd(*c3_26->getOutput(0), 3 * (Yolo::CLASS_NUM + 5), DimsHW{ 1, 1 }, weightMap["model.33.m.1.weight"], weightMap["model.33.m.1.bias"]);
IConvolutionLayer* det2 = network->addConvolutionNd(*c3_29->getOutput(0), 3 * (Yolo::CLASS_NUM + 5), DimsHW{ 1, 1 }, weightMap["model.33.m.2.weight"], weightMap["model.33.m.2.bias"]);
IConvolutionLayer* det3 = network->addConvolutionNd(*c3_32->getOutput(0), 3 * (Yolo::CLASS_NUM + 5), DimsHW{ 1, 1 }, weightMap["model.33.m.3.weight"], weightMap["model.33.m.3.bias"]);
auto yolo = addYoLoLayer(network, weightMap, "model.33", std::vector<IConvolutionLayer*>{det0, det1, det2, det3});
yolo->getOutput(0)->setName(OUTPUT_BLOB_NAME);
network->markOutput(*yolo->getOutput(0));
// Build engine
builder->setMaxBatchSize(maxBatchSize);
config->setMaxWorkspaceSize(16 * (1 << 20)); // 16MB
#if defined(USE_FP16)
config->setFlag(BuilderFlag::kFP16);
#elif defined(USE_INT8)
std::cout << "Your platform support int8: " << (builder->platformHasFastInt8() ? "true" : "false") << std::endl;
assert(builder->platformHasFastInt8());
config->setFlag(BuilderFlag::kINT8);
Int8EntropyCalibrator2* calibrator = new Int8EntropyCalibrator2(1, INPUT_W, INPUT_H, "./coco_calib/", "int8calib.table", INPUT_BLOB_NAME);
config->setInt8Calibrator(calibrator);
#endif
std::cout << "Building engine, please wait for a while..." << std::endl;
ICudaEngine* engine = builder->buildEngineWithConfig(*network, *config);
std::cout << "Build engine successfully!" << std::endl;
// Don't need the network any more
network->destroy();
// Release host memory
for (auto& mem : weightMap)
{
free((void*)(mem.second.values));
}
return engine;
}
void APIToModel(unsigned int maxBatchSize, IHostMemory** modelStream, float& gd, float& gw, std::string& wts_name) {
// Create builder
IBuilder* builder = createInferBuilder(gLogger);
IBuilderConfig* config = builder->createBuilderConfig();
// Create model to populate the network, then set the outputs and create an engine
ICudaEngine* engine = build_engine(maxBatchSize, builder, config, DataType::kFLOAT, gd, gw, wts_name);
assert(engine != nullptr);
// Serialize the engine
(*modelStream) = engine->serialize();
// Close everything down
engine->destroy();
builder->destroy();
config->destroy();
}
void doInference(IExecutionContext& context, cudaStream_t& stream, void** buffers, float* input, float* output, int batchSize) {
// DMA input batch data to device, infer on the batch asynchronously, and DMA output back to host
CUDA_CHECK(cudaMemcpyAsync(buffers[0], input, batchSize * 3 * INPUT_H * INPUT_W * sizeof(float), cudaMemcpyHostToDevice, stream));
context.enqueue(batchSize, buffers, stream, nullptr);
CUDA_CHECK(cudaMemcpyAsync(output, buffers[1], batchSize * OUTPUT_SIZE * sizeof(float), cudaMemcpyDeviceToHost, stream));
cudaStreamSynchronize(stream);
}
bool parse_args(int argc, char** argv, std::string& engine) {
if (argc < 3) return false;
if (std::string(argv[1]) == "-v" && argc == 3) {
engine = std::string(argv[2]);
}
else {
return false;
}
return true;
}
int main(int argc, char** argv) {
cudaSetDevice(DEVICE);
//std::string wts_name = "";
std::string engine_name = "";
//float gd = 0.0f, gw = 0.0f;
//std::string img_dir;
if (!parse_args(argc, argv, engine_name)) {
std::cerr << "arguments not right!" << std::endl;
std::cerr << "./yolov5 -v [.engine] // run inference with camera" << std::endl;
return -1;
}
std::ifstream file(engine_name, std::ios::binary);
if (!file.good()) {
std::cerr << " read " << engine_name << " error! " << std::endl;
return -1;
}
char* trtModelStream{ nullptr };
size_t size = 0;
file.seekg(0, file.end);
size = file.tellg();
file.seekg(0, file.beg);
trtModelStream = new char[size];
assert(trtModelStream);
file.read(trtModelStream, size);
file.close();
// prepare input data ---------------------------
static float data[BATCH_SIZE * 3 * INPUT_H * INPUT_W];
//for (int i = 0; i < 3 * INPUT_H * INPUT_W; i++)
// data[i] = 1.0;
static float prob[BATCH_SIZE * OUTPUT_SIZE];
IRuntime* runtime = createInferRuntime(gLogger);
assert(runtime != nullptr);
ICudaEngine* engine = runtime->deserializeCudaEngine(trtModelStream, size);
assert(engine != nullptr);
IExecutionContext* context = engine->createExecutionContext();
assert(context != nullptr);
delete[] trtModelStream;
assert(engine->getNbBindings() == 2);
void* buffers[2];
// In order to bind the buffers, we need to know the names of the input and output tensors.
// Note that indices are guaranteed to be less than IEngine::getNbBindings()
const int inputIndex = engine->getBindingIndex(INPUT_BLOB_NAME);
const int outputIndex = engine->getBindingIndex(OUTPUT_BLOB_NAME);
assert(inputIndex == 0);
assert(outputIndex == 1);
// Create GPU buffers on device
CUDA_CHECK(cudaMalloc(&buffers[inputIndex], BATCH_SIZE * 3 * INPUT_H * INPUT_W * sizeof(float)));
CUDA_CHECK(cudaMalloc(&buffers[outputIndex], BATCH_SIZE * OUTPUT_SIZE * sizeof(float)));
// Create stream
cudaStream_t stream;
CUDA_CHECK(cudaStreamCreate(&stream));
//#读取本地视频
//cv::VideoCapture capture("/home/nano/Videos/video.mp4");
//#调用本地usb摄像头,我的默认参数为1,如果1报错,可修改为0.
cv::VideoCapture capture(1);
if (!capture.isOpened()) {
std::cout << "Error opening video stream or file" << std::endl;
return -1;
}
int key;
int fcount = 0;
while (1)
{
cv::Mat frame;
capture >> frame;
if (frame.empty())
{
std::cout << "Fail to read image from camera!" << std::endl;
break;
}
fcount++;
//if (fcount < BATCH_SIZE && f + 1 != (int)file_names.size()) continue;
for (int b = 0; b < fcount; b++) {
//cv::Mat img = cv::imread(img_dir + "/" + file_names[f - fcount + 1 + b]);
cv::Mat img = frame;
if (img.empty()) continue;
cv::Mat pr_img = preprocess_img(img, INPUT_W, INPUT_H); // letterbox BGR to RGB
int i = 0;
for (int row = 0; row < INPUT_H; ++row) {
uchar* uc_pixel = pr_img.data + row * pr_img.step;
for (int col = 0; col < INPUT_W; ++col) {
data[b * 3 * INPUT_H * INPUT_W + i] = (float)uc_pixel[2] / 255.0;
data[b * 3 * INPUT_H * INPUT_W + i + INPUT_H * INPUT_W] = (float)uc_pixel[1] / 255.0;
data[b * 3 * INPUT_H * INPUT_W + i + 2 * INPUT_H * INPUT_W] = (float)uc_pixel[0] / 255.0;
uc_pixel += 3;
++i;
}
}
}
// Run inference
auto start = std::chrono::system_clock::now();//#获取模型推理开始时间
doInference(*context, stream, buffers, data, prob, BATCH_SIZE);
auto end = std::chrono::system_clock::now();//#结束时间
//std::cout << std::chrono::duration_cast<std::chrono::milliseconds>(end - start).count() << "ms" << std::endl;
int fps = 1000.0 / std::chrono::duration_cast<std::chrono::milliseconds>(end - start).count();
std::vector<std::vector<Yolo::Detection>> batch_res(fcount);
for (int b = 0; b < fcount; b++) {
auto& res = batch_res[b];
nms(res, &prob[b * OUTPUT_SIZE], CONF_THRESH, NMS_THRESH);
}
for (int b = 0; b < fcount; b++) {
auto& res = batch_res[b];
//std::cout << res.size() << std::endl;
//cv::Mat img = cv::imread(img_dir + "/" + file_names[f - fcount + 1 + b]);
for (size_t j = 0; j < res.size(); j++) {
cv::Rect r = get_rect(frame, res[j].bbox);
cv::rectangle(frame, r, cv::Scalar(0x27, 0xC1, 0x36), 2);
std::string label = my_classes[(int)res[j].class_id];
cv::putText(frame, label, cv::Point(r.x, r.y - 1), cv::FONT_HERSHEY_PLAIN, 1.2, cv::Scalar(0xFF, 0xFF, 0xFF), 2);
std::string jetson_fps = "FPS: " + std::to_string(fps);
cv::putText(frame, jetson_fps, cv::Point(11, 80), cv::FONT_HERSHEY_PLAIN, 3, cv::Scalar(0, 0, 255), 2, cv::LINE_AA);
}
//cv::imwrite("_" + file_names[f - fcount + 1 + b], img);
}
cv::imshow("yolov5", frame);
key = cv::waitKey(1);
if (key == 'q') {
break;
}
fcount = 0;
}
capture.release();
// Release stream and buffers
cudaStreamDestroy(stream);
CUDA_CHECK(cudaFree(buffers[inputIndex]));
CUDA_CHECK(cudaFree(buffers[outputIndex]));
// Destroy the engine
context->destroy();
engine->destroy();
runtime->destroy();
return 0;
}
修改完.cpp代码之后,tensorrtx-yolov5-v5.0 -> yolov5 - > build文件夹下,运行以下命令:
make
sudo ./yolov5 -v yolov5s.engine
运行之后摄像头调用成功,效果如下:
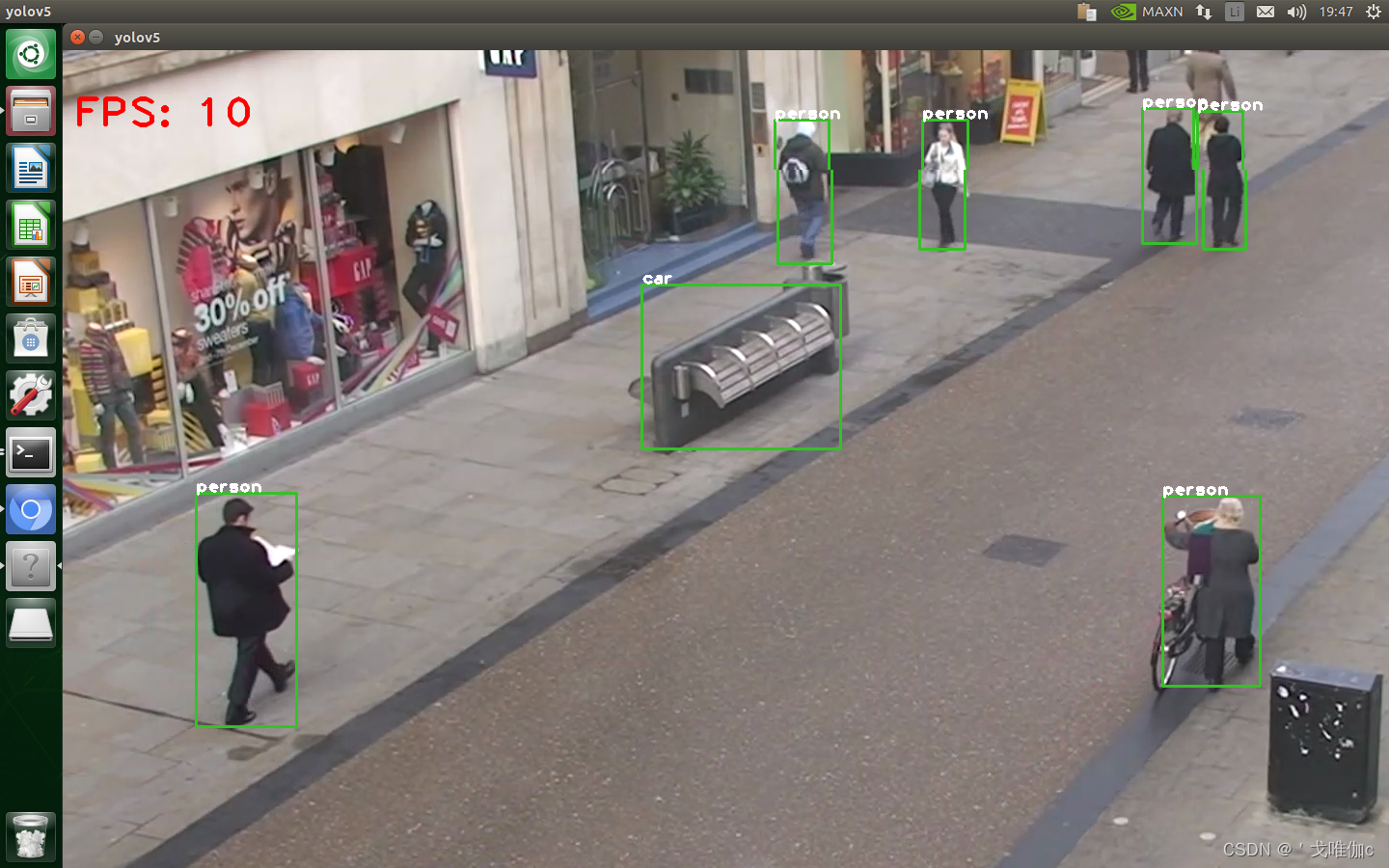
到此我们就大功告成了,以上就是Jeston nano完整的部署过程,希望对你们有所帮助,请大家多多支持。创作不易,希望得到你们的鼓励~
版权归原作者 戈唯伽c 所有, 如有侵权,请联系我们删除。