
一、Hive 部署
(一)Linux 环境搭建
一、虚拟机的安装
VMware (Virtual Machine ware)是一个“虚拟 PC”软件公司,提供服务器、桌
面虚拟化的解决方案。
使用的虚拟软件:VMware15
二、Linux 系统安装
1.环境准备
VMware15.5 pro
Centos7 镜像文件(mini)
2.虚拟机安装
2.1 新建虚拟机,选择自定义
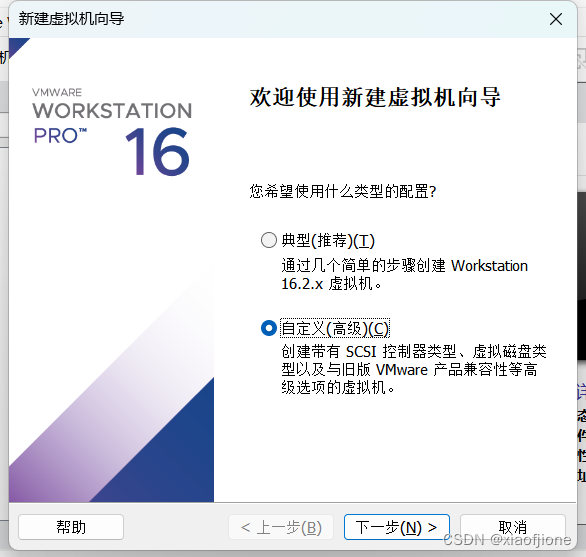
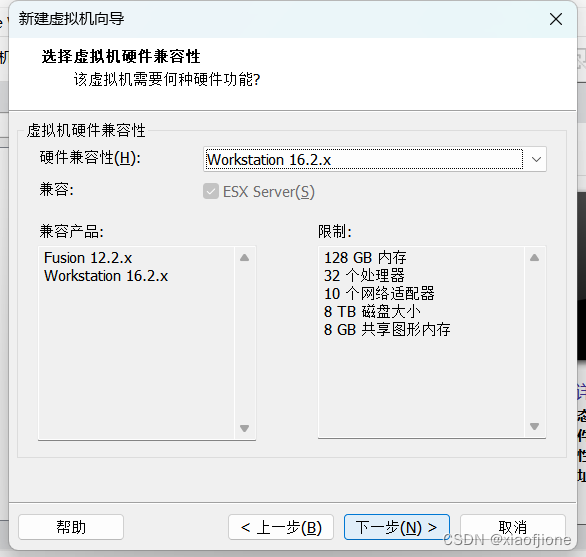
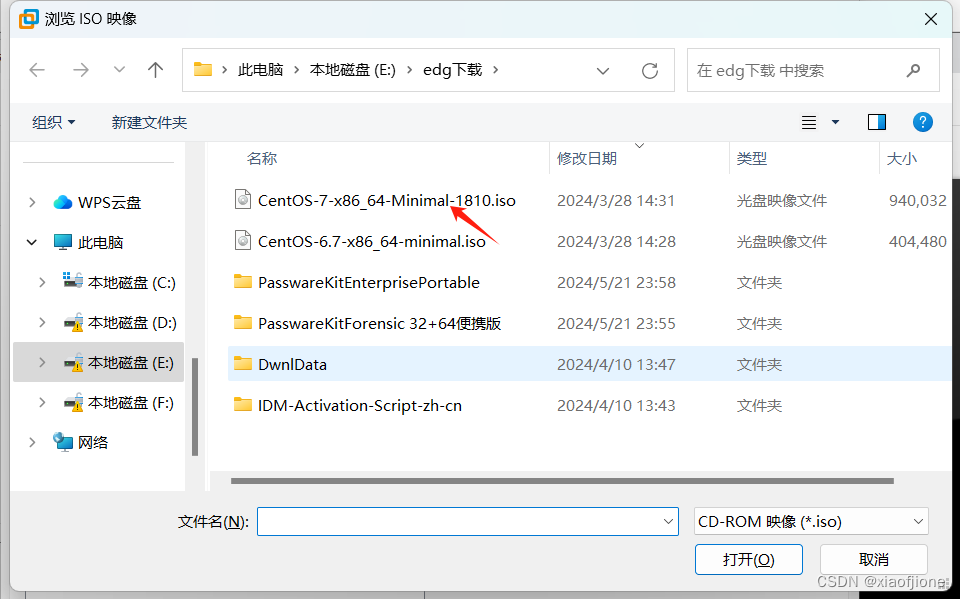
2.2 选择下一步安装程序光盘映像文件(iso)
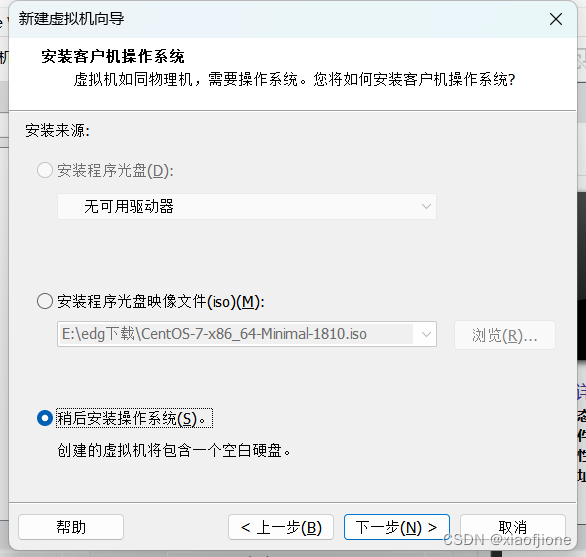
2.3 选择稍后安装操作系统
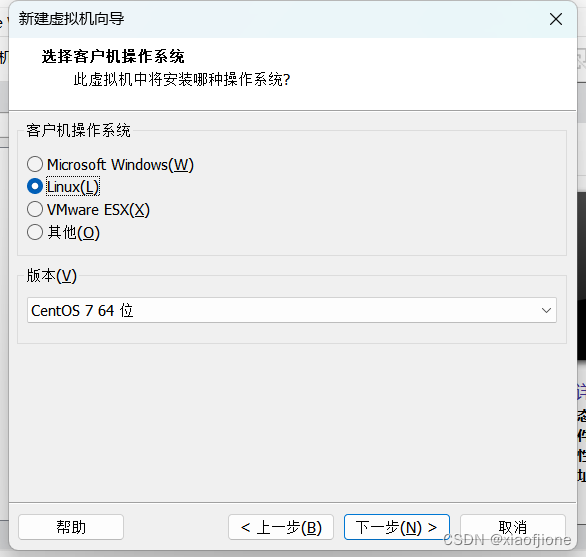
2.4 选择Liunx(L)版本Centos7
2.5 选择虚拟机的名称和位置
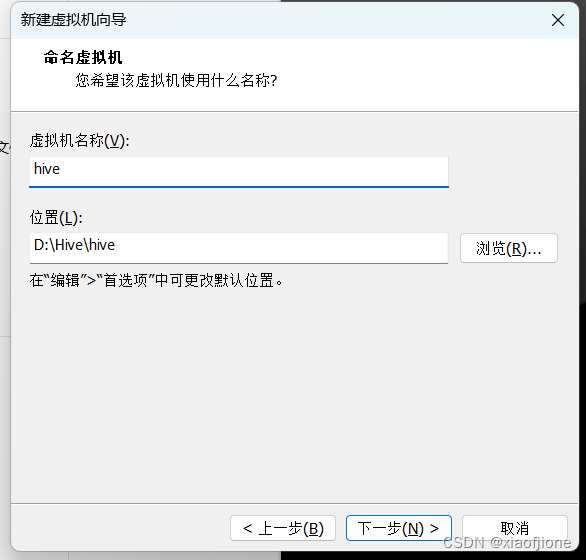
2.6配置处理器的数量和每个处理器的内核数量
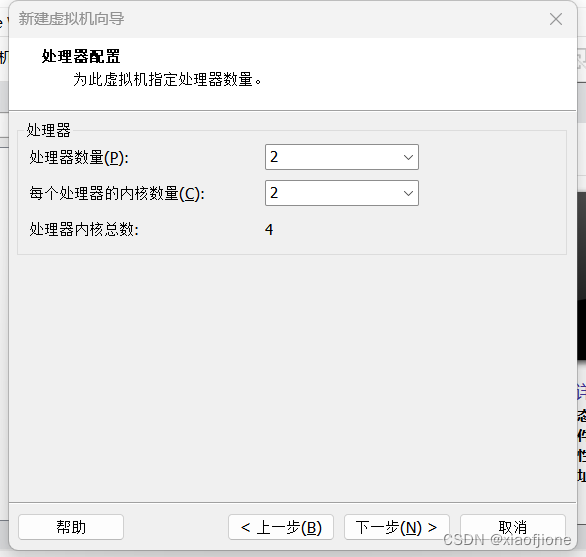
2.7配置虚拟机的内存
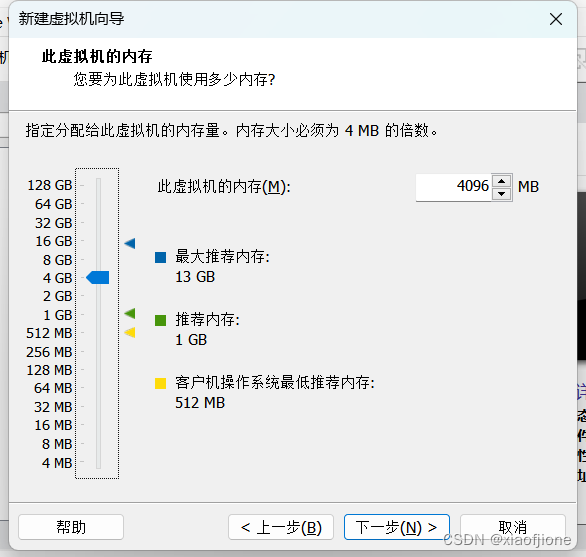
2.8配置网络类型
2.9选择 I/OK控制器类型
2.10选择 虚拟磁盘类型
2.11选择磁盘
2.12配置磁盘大小
2.13配置系统
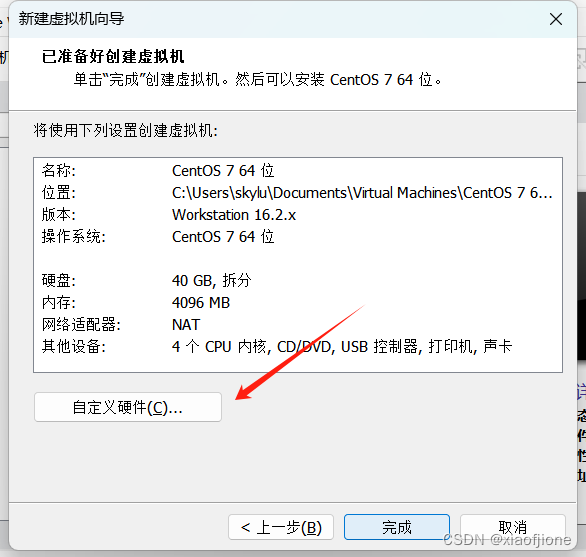
2.14 完成配置开启虚拟机
三、Centos 系统安装
1.开启虚拟机
2.安装 CentOS7

3.选择语言(默认为 English)

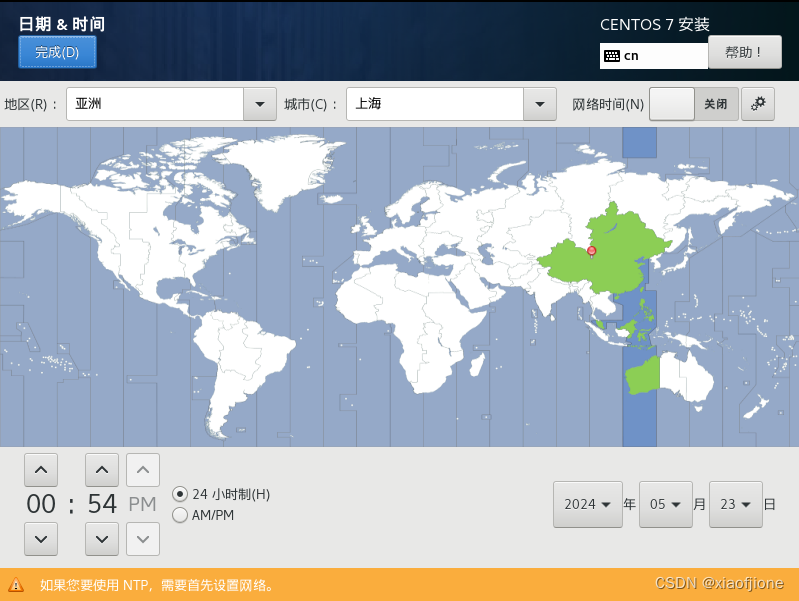
4.日期和时间亚洲/上海(这里默认为最小)
5.安装位置
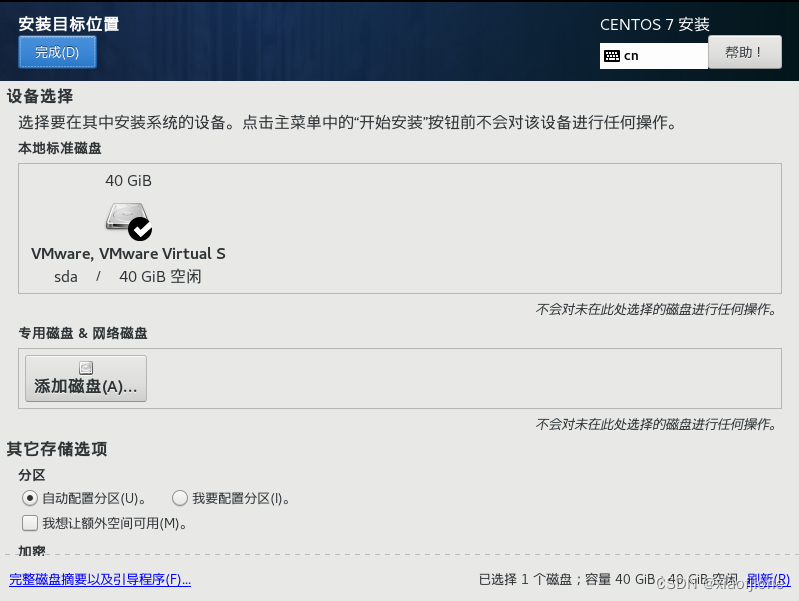
6.系统网络
7.开始安装
8.设置 ROOT 密码
9.安装完成后重启即可
10.使用 root 权限登录

四、静态网络配置
1.查看网络是否连通
ping www.baidu.com
2.安装 net-tools
yum upgrade
yum install net-tools
查看ip地址和网卡
ifconfip
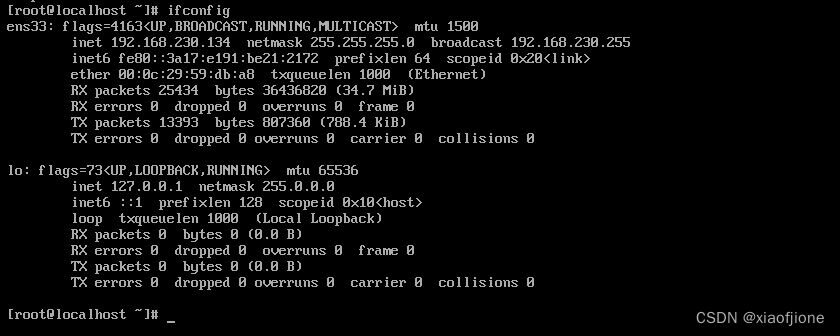
3.查看 Mac 地址
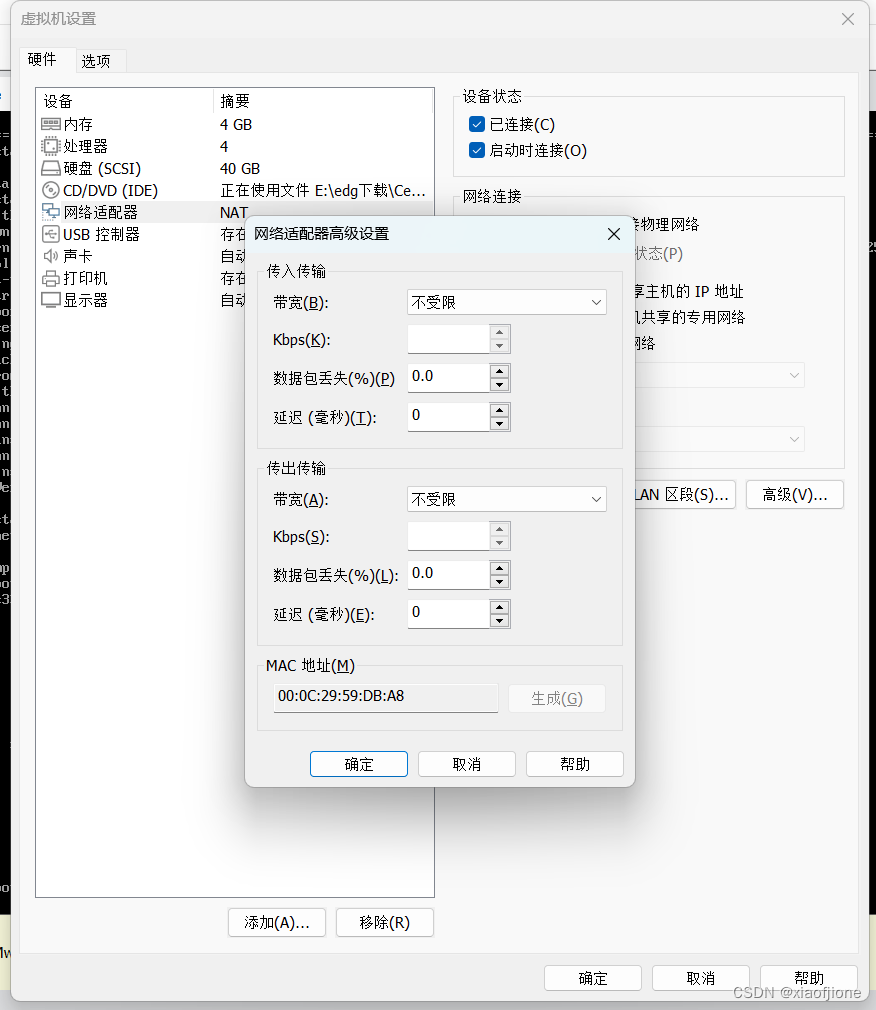
4.查看 ip 地址的起始和结束地址

5.修改网络配置文件
vi /etc/sysconfig/network-scripts/ifcfg-ens33
修改BOOTPROTO为
BOOTPROTO="static"
修改ONBOOT为
ONBOOT="yes"
mac 地址为 2 步骤的 enter 值2
ip 地址参照 4 步骤自行选择(必须在起始和结束的范围内)
子网掩码默认设置为 255.255.255.0
网关的值为将 ip 地址中最后一段的值改为 2
DNS 使用谷歌提供的免费 dns1:8.8.8.8

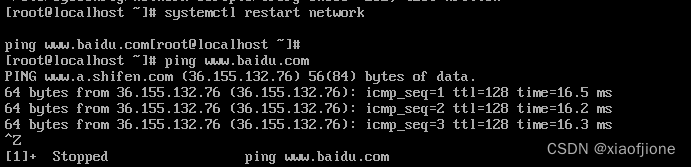
6.重启网络服务,查看是否配置成功
systemctl restart network
ping www.baidu.com
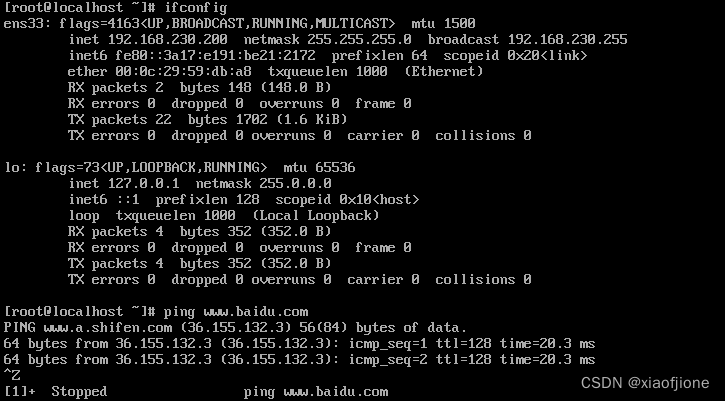
7.重启虚拟机后,查看是否连通网络(ip 地址并未改变,且能连通网络)
reboot
ifconfig
ping www.baidu.com
五、虚拟配置
(一)X-Shell远程连接Linux
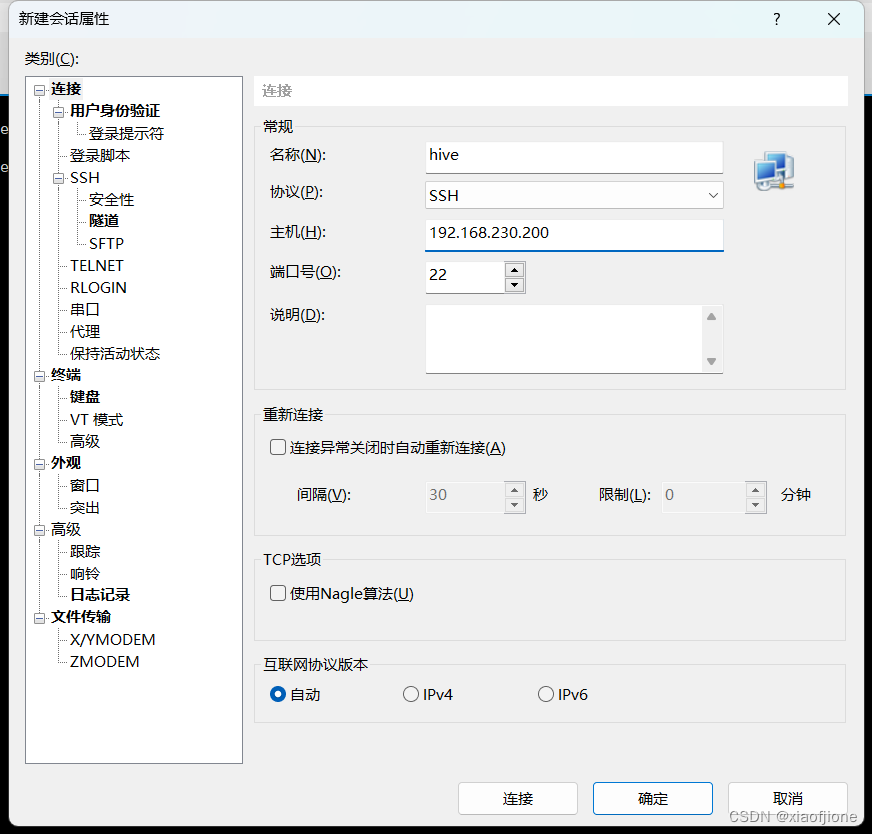
1.新建会话连接

2.设置名称主机
3.设置用户身份认证(Linux的账号 密码 )
4.连接成功
(二)Hadoop 的部署
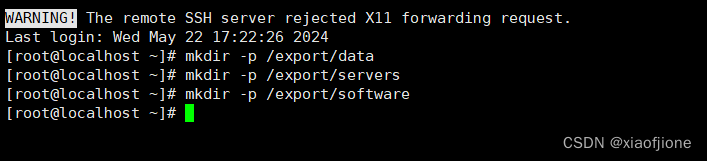
1.在所有虚拟机根目录下新建文件夹 export,export 文件夹中新建 data、servers
和 software 文件
mkdir -p /export/data
mkdir -p /export/servers
mkdir -p /export/software
2.准备安装包
hadoop-2.7.4.tar.gz
jdk-8u161-linux-x64.tar.gz
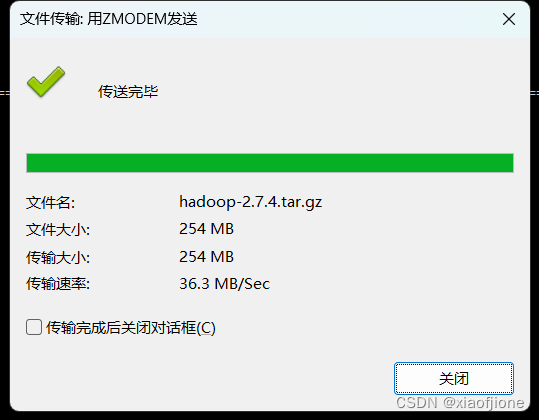
3.在 Xshell 先进入 software 文件内,然后下载 rz 命令,并使用 rz 命令进行文件
上传,此时会弹出上传的窗口,选择要上传的文件,点击确定即可将本地文件上
传到 Linux 上。
cd /export/software
yum -y install lrzsz
rz
4.ls查看安装包是否导入

5.安装 JDK(所有虚拟机都要操作)
5.1 解压 jdk
cd /export/software
tar -zxvf jdk-8u161-linux-x64.tar.gz -C /export/servers/
5.2 重命名 jdk 目录
cd /export/servers
mv jdk1.8.0_161 jdk
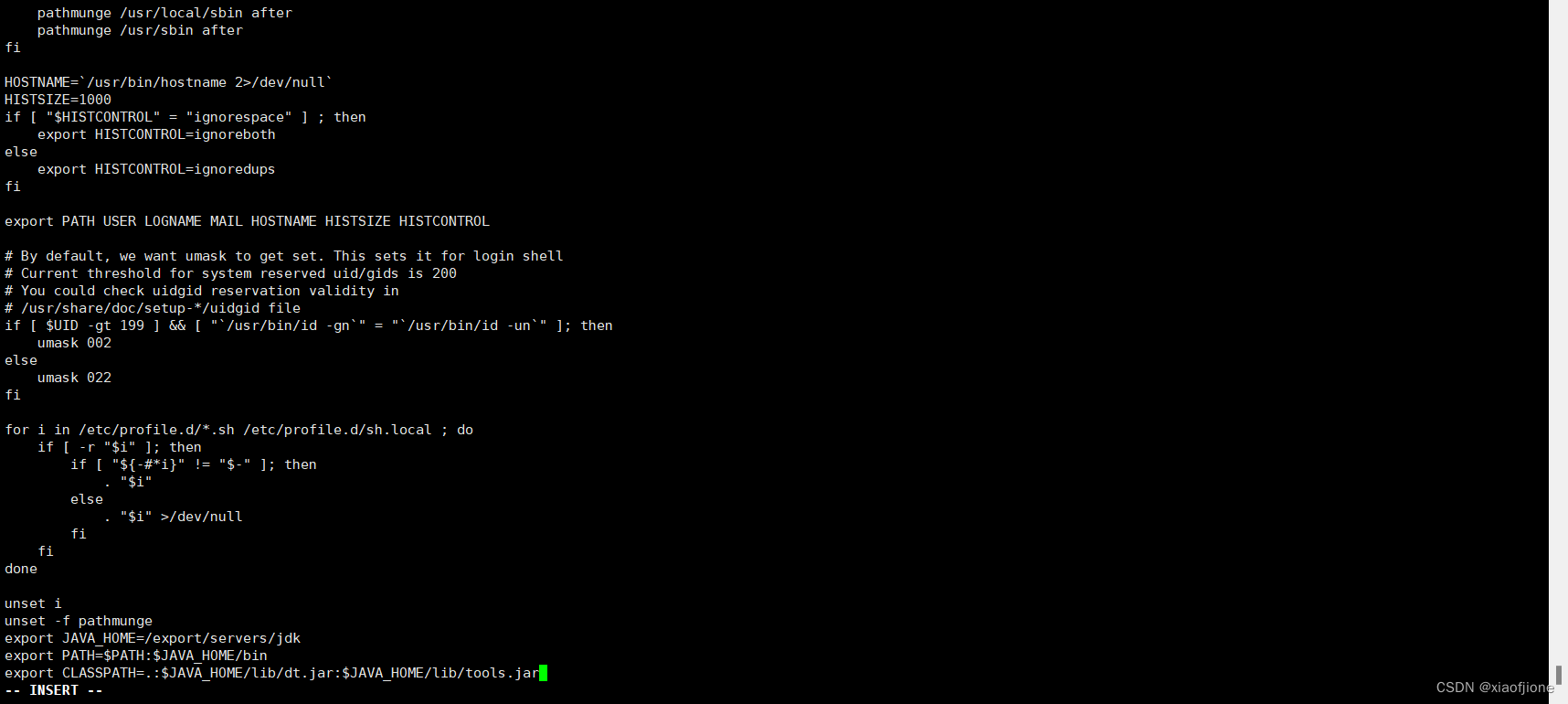
5.3 配置环境变量
vi /etc/profile
#tip:在配置文件末尾追加
export JAVA_HOME=/export/servers/jdk
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar

5.4 使配置文件生效
source /etc/profile
5.5 查看是否配置成功
java -version

6.Hadoop 安装(所有虚拟机都要操作)
6.1 解压 hadoop
cd /export/software
tar -zxvf hadoop-2.7.4.tar.gz -C /export/servers/
6.2 打开配置文件
vi /etc/profile
6.3 配置 hadoop 环境变量
#tip:在文件末尾追加
export HADOOP_HOME=/export/servers/hadoop-2.7.4
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin

6.4 使配置文件生效
source /etc/profile
6.5 查看是否配置成功
hadoop version

6.6配置ssh免密登录
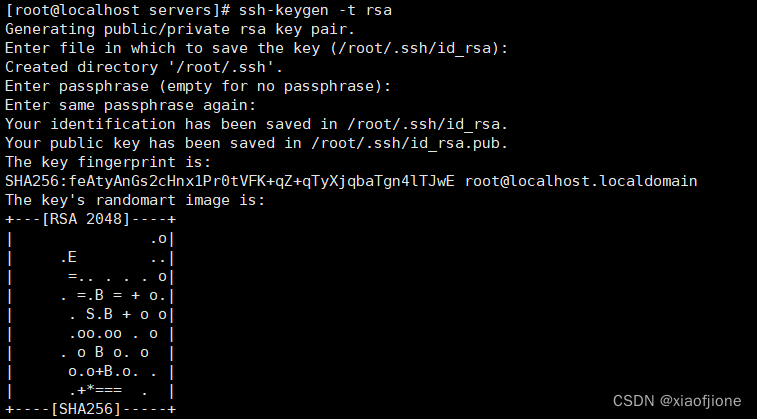
6.6.1生成密钥
ssh-keygen -t rsa
输入上面的代码后回车四次
6.6.2
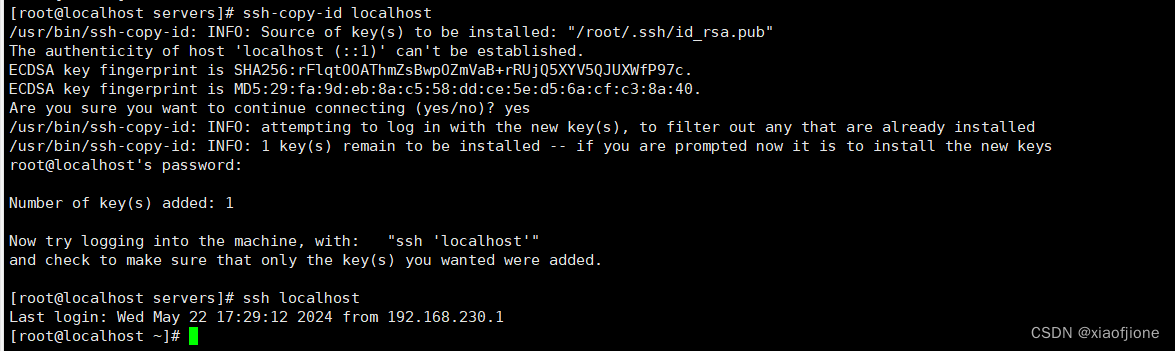
把公钥拷贝到本台虚拟机上面去
ssh-copy-id localhost
6.6.4
验证一下是否需要密码

7.Hadoop 集群配置
7.1 进入主节点配置目录
cd /export/servers/hadoop-2.7.4/etc/hadoop/
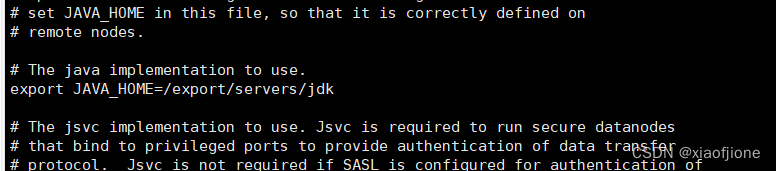
7.2 修改 hadoop-env.sh 文件
vi hadoop-env.sh
#tip:找到相应位置,添加这段话
export JAVA_HOME=/export/servers/jdk
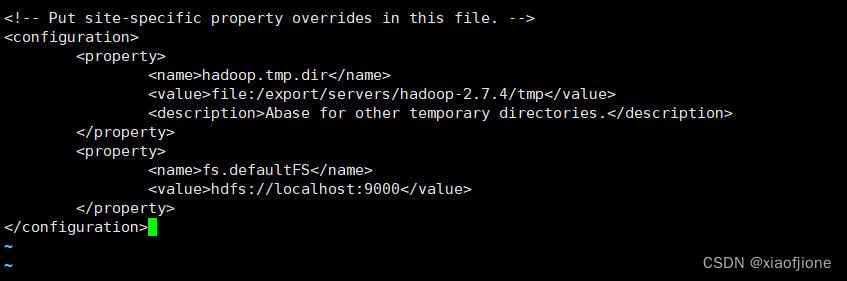
7.3 修改 core-site.xml 文件
vi core-site.xml
#tip:下图中乱码部分为注释代码,可以删掉,不影响
<configuration> ``` <configuration> <property> <name>hadoop.tmp.dir</name> <value>file:/export/servers/hadoop-2.7.4/tmp</value> <description>Abase for other temporary directories.</description> </property> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property> </configuration>
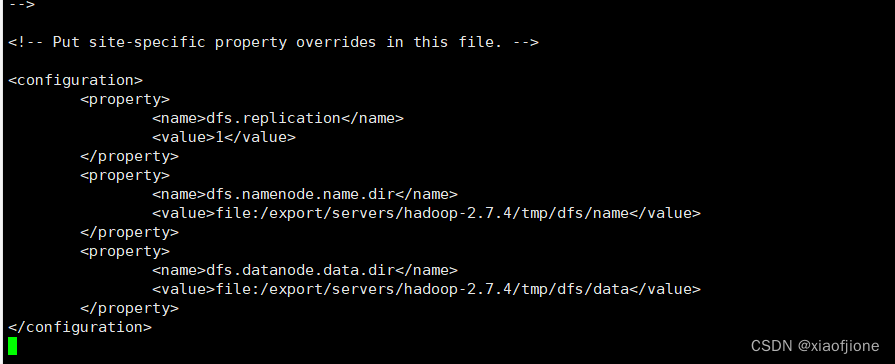
7.4 修改 hdfs-site.xml 文件
vi hdfs-site.xml
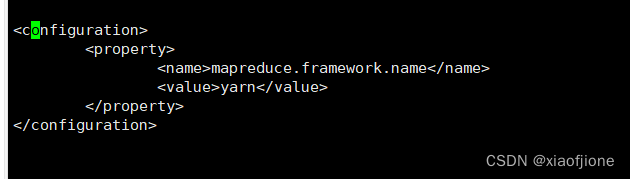
7.5修改mapred-site.xml
mv mapred-site.xml.template mapred-site.xml
vi mapred-site.xml
##### 7.6修改yarn-site.xml
vi yarn-site.xml
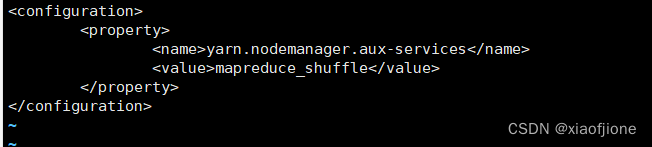
7.7格式化文件系统(successfully formatted 格式化成功)
hdfs namenode -format

三、Hadoop 启动
1.启动集群
1.1 点启动所有 HDFS 服务进程
start-dfs.sh

1.2 启动所有 HDFS 服务进程
start-yarn.sh

1.3一键启动集群
start-all.sh
1.4使用 jps 命令查看进程
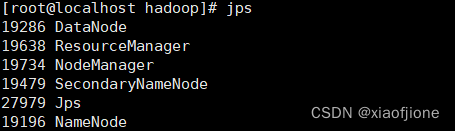
2.关闭防火墙(所有虚拟机都要操作)
systemctl stop firewalld
#关闭防火墙
systemctl disable firewalld.service
#关闭防火墙开机启动

3.打开 window 下
firewall-cmd --state
# 查看防火墙状态

的 C:\Windows\System32\drivers\etc 打开 hosts 文件,在文件末
添加代码:
192.168.230.222 hadoop
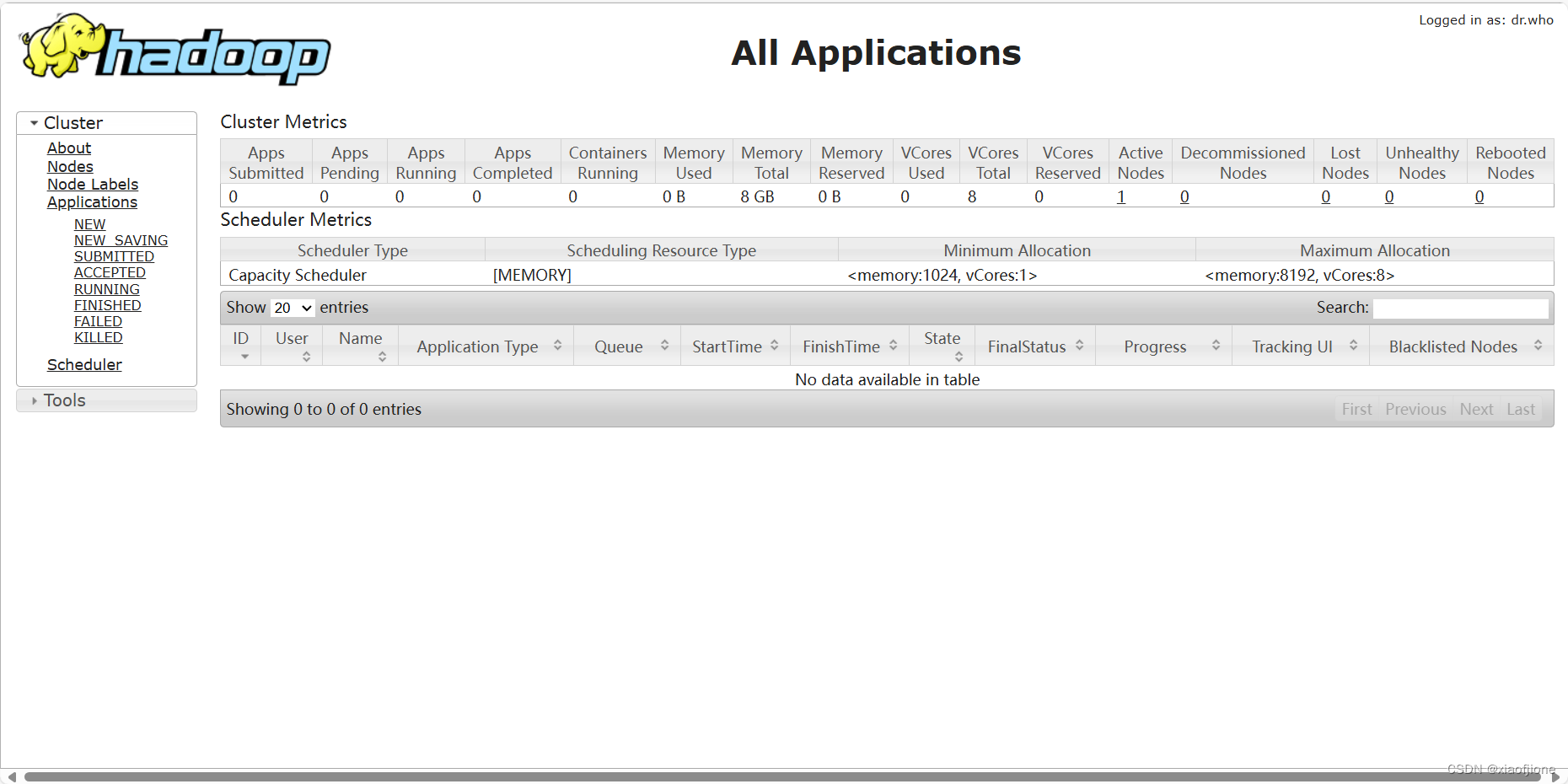
- 通 过 UI 界 面 查 看 Hadoop 运 行 状 态 , 在 Windows 系 统 下 , 访 问
http://hadoop:50070,或http://192.168.230.200:50070查看 HDFS 集群状态
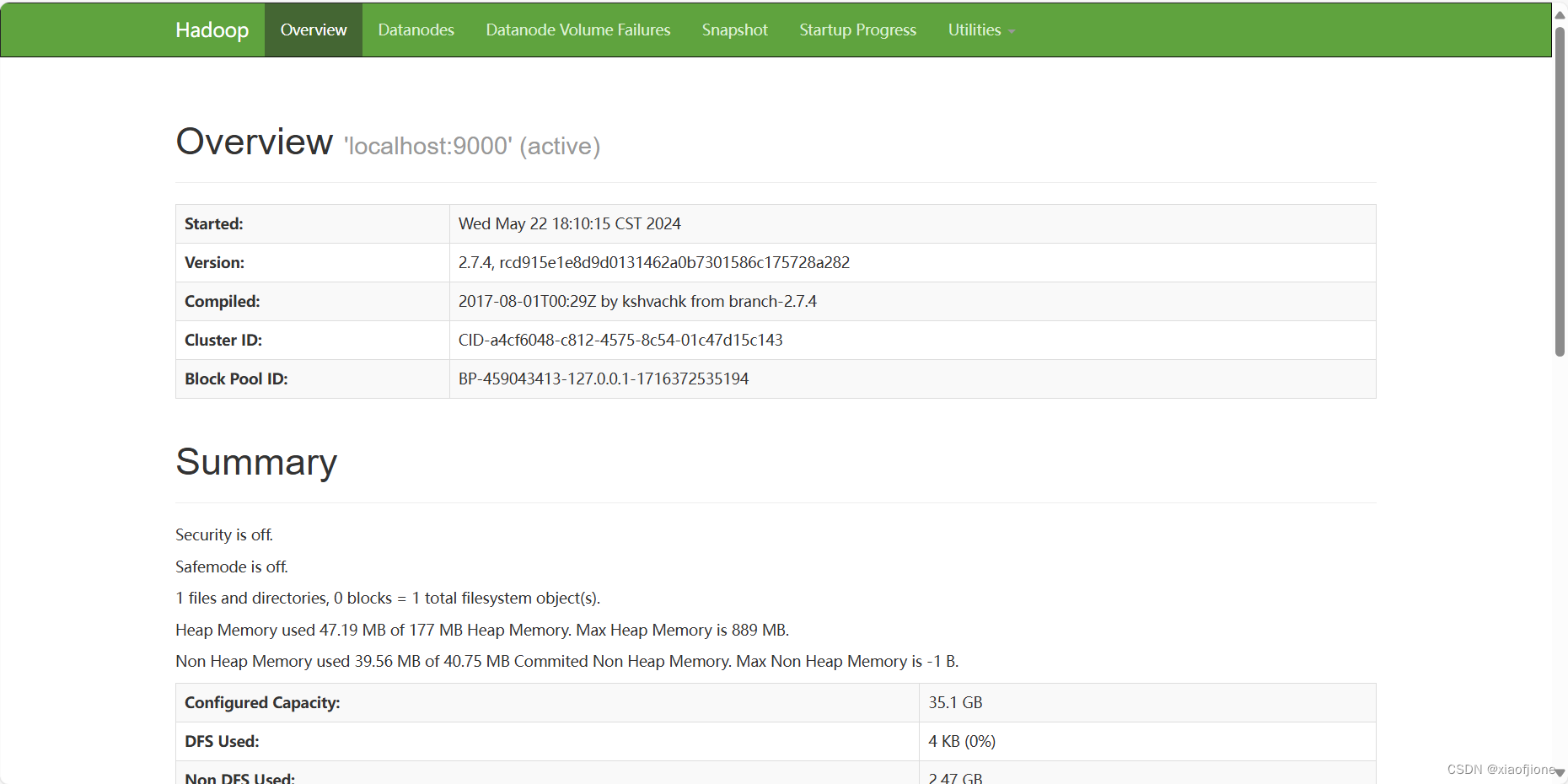
- 在 Windows 系统下,访问 http://hadoop:8088,或http://192.168.230.200:8088 查看 Yarn 集群状态
(二)Hive 的部署
**Hive ****安装 **
第一步:打开 X-Shell 软件,在 hive 上进入/export/software/目录,指令如下: cd /export/software/
cd /export/software/
第二步:使用指令 rz 进行安装包上传,选择安装包 apache-hive-2.3.9-bin.tar.gz。
ls 可查看到该目录
下存在 apache-hive-2.3.9-bin.tar.gz 文件。
第三步:上传完毕后将该安装包解压到/export/servers/目录,使用如下指令:
tar -zxvf apache-hive-2.3.9-bin.tar.gz -C /export/servers/
解压完成后使用 cd /export/servers/进入该目录,
cd /export/servers/
修改hive名称
mv apache-hive-2.3.9-bin hive-2.3.9
ls

配置环境
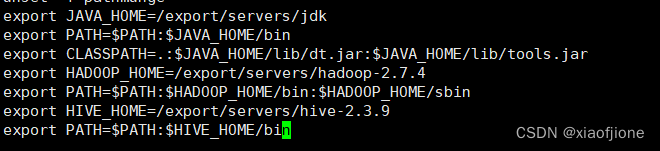
vi /etc/profile
export HIVE_HOME=/export/servers/hive-2.3.9
export PATH=$PATH:$HIVE_HOME/bin
source /etc/profile
2.安装mysql病配置sql服务器
2.1上传mysql安装包rz mysql-community-release-el7-5.noarch.rpm
2.2 安装 rpm
cd /export/sofrware
rpm -ivh mysql-community-release-el7-5.noarch.rpm

2.3 执行安装
yum install mysql-community-server

2.4 设置开机启动并启动mysql服务
systemctl enable mysqld
systemctl start mysqld
ok,因为版本的原因,安装的mysql未自动生成密码,8.x版本以上会自动生成
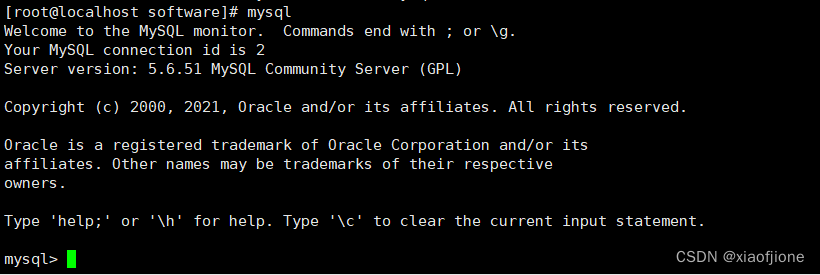
2.5 输入mysql ,启动mysql
mysql
在mysql命令窗口执行,为了能让root用户可以操作hive
abc123 为root密码
grant all privileges on *.* to 'root'@'%' identified by 'abc123' with grant option;

2.6 启动、关闭、重启服务
systemctl start mysqld
systemctl stop mysqld
systemctl restart mysqld

第四步:Hive 的配置。
首先进入 Hive 安装包下的 conf 文件夹,将 hive-env.sh.template 文件进行复制并
重命名为 hive-env.sh。具体指令如下:
cd /export/servers/hive-2.3.9/conf
cp hive-env.sh.template hive-env.sh
然后修改 hive-env.sh 文件,添加 Hadoop 环境变量。
修改指令:
vi hive-env.sh
在文件内容中找到#HADOOP_HOME=${bin}/../../hadoop 这句话,将这句话修改
成如下内容即可。
HADOOP_HOME=/export/servers/hadoop-2.7.4
export HIVE_CONF_DIR=/export/servers/hive-2.3.9/conf
export HIVE_AUX_JARS_PATH=/export/servers/hive-2.3.9/lib

4.2 配置hive-log4j2.properties和hive-site.xml
cd /export/servers/hive-2.3.9/conf/
cp hive-log4j2.properties.template hive-log4j2.properties
之后在 conf 目录下新建 hive-site.xml 文件,并添加配置信息。
新建文件并编辑如下:
vi hive-site.xml
编辑如下内容:
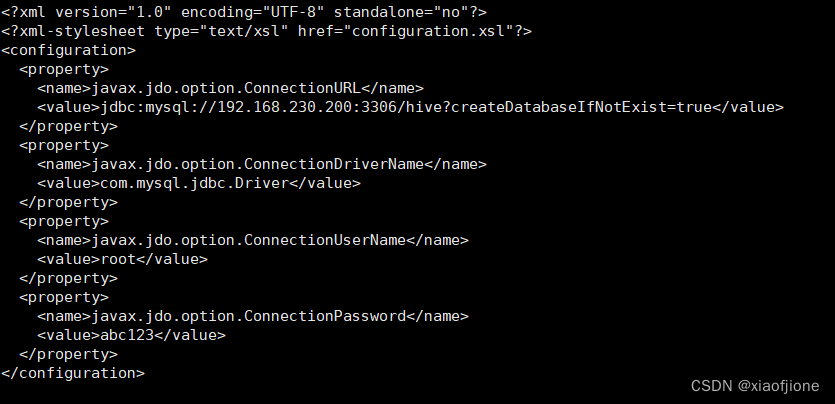
注:下述代码中,192.168.230.200为本机虚拟机ip地址,编辑时需要修改成自己的
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://192.168.230.200:3306/hive?createDatabaseIfNotExist=true&useSSL=false</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>abc123</value>
</property>
</configuration>
最后将连接驱动的 jar 包 mysql-connector-java-5.1.40.jar 上传至 Hive 安装包的 lib
文件夹下。
4.3 初始化数据库
schematool -dbType mysql -initSchema

4.4启动hive

二、数据仓库分层
(一)源数据层的实现
源数据层是数据仓库的基础层,负责存储原始的、未经加工的数据。在数据仓库
中,源数据层扮演着收集、存储和保留数据的角色。它是数据仓库中数据质量和
数据完整性的基础,同时也是其他层的数据加工和转换的起点。源数据层的作用
包括但不限于:
数据收集: 从各种数据源(如数据库、日志文件、API 等)中收集原始数据。
数据存储: 将原始数据存储在数据仓库中,通常使用原始格式或轻微加工后的
格式存储。
数据保留: 源数据层通常保留了历史数据,以便进行后续的数据分析、报表生
成等操作。
在实现数据仓库分层之前,需要启动 Hadoop Hive 实现数据库分层,具体操作步骤如下。
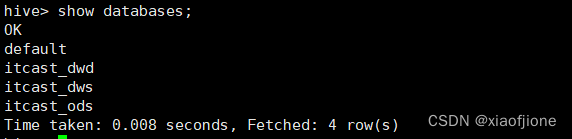
创建数据库 itcast_ods
在 Hive 中创建数据库 itcast_ods,用于存储源数据层的源数据表,具体命令如下。
CREATE DATABASE IF NOT EXISTS itcast_ods;
设置存储格式
设置 Hive 的属性 hive.exec.orc .compression.strategy 的属性值为
COMPRESSION,配置压缩生效,具体命令如下。
Set hive.exec.orc.compression.strategy=COMPRESSION;
创建源数据表 web_chat_ems_ods
在 Hive 的数据库 itcast_ods 中创建源数据表 web_chat_ems_ods 用于存储 MySQL
数据库中用户会话信息表 web_chat_ems_2019_07 的数据,具体命令如下。
CREATE EXTERNAL TABLE IF NOT EXISTS itcast_ods.web_chat_ems (
id INT comment '主键',
create_date_time STRING comment '数据创建时间',
session_id STRING comment '七陌sessionId',
sid STRING comment '访客id',
create_time STRING comment '会话创建时间',
seo_source STRING comment '搜索来源',
seo_keywords STRING comment '关键字',
ip STRING comment 'IP地址',
area STRING comment '地域',
country STRING comment '所在国家',
province STRING comment '省',
city STRING comment '城市',
origin_channel STRING comment '投放渠道',
user_match STRING comment '所属坐席',
manual_time STRING comment '人工开始时间',
begin_time STRING comment '坐席领取时间 ',
end_time STRING comment '会话结束时间',
last_customer_msg_time_stamp STRING comment '客户最后一条消息的时间',
last_agent_msg_time_stamp STRING comment '坐席最后一下回复的时间',
reply_msg_count INT comment '客服回复消息数',
msg_count INT comment '客户发送消息数',
browser_name STRING comment '浏览器名称',
os_info STRING comment '系统名称')
comment '访问会话信息表'
PARTITIONED BY(starts_time STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
stored as orc
location '/user/hive/warehouse/itcast_ods.db/web_chat_ems_ods'
TBLPROPERTIES ('orc.compress'='ZLIB');
创建源数据表 web_chat_text_ems_ods。
在 Hive 的数据库 itcast_ods 中创建源数据表 web_chat_text_ems_ods 用于存储
MySQL 数据库中用户会话信息表 web_chat_text_ems_2019_07 的数据,具体命令
如下。
CREATE EXTERNAL TABLE IF NOT EXISTS itcast_ods.web_chat_text_ems_ods
(
id INT COMMENT "主键 ID",
referrer STRING COMMENT "上级来源页面",
from_url STRING COMMENT "会话来源页面",
landing_page_url STRING COMMENT "访客浏览页面",
url_title STRING COMMENT "页面标题",
platform_description STRING COMMENT "用户信息",
other_params STRING COMMENT "扩展字段",
history STRING COMMENT "历史访问记录"
)
COMMENT "用户会话信息附属表"
ROW FORMAT DELIMITED
FIELDS TERMINATED BY "\t"
STORED AS ORC
LOCATION "/user/hive/warehouse/itcast_ods.db/web_chat_text_ems_ods"
TBLPROPERTIES ("orc.compress"="ZLIB");
(二)数据仓库层的实现
数据仓库层通常用于存储源数据层清洗或转换后的数据,根据业务需求的不同,
清洗或转换后的数据也会有所不同。本项目的数据仓库层涉及明细层和业务层,
其中明细层用于存储源数据层清洗转换后的数据;业务层用于存储访问用户量和
咨询用户量这两个指标的数据,实现数据仓库层的步骤如下。
创建数据库 itcast_dwd
在 Hive 中创建数据库 itcast_dwd 用于存储明细层的数据,具体命令如下。
CREATE DATABASE IF NOT EXISTS itcast_dwd;
创建明细表 visit _consult_dwd
在Hive 的数据库 itcast_dwd 中创建明细层的明细表 visit_consult_dwd 用于存储源
数据表 web_chat_ems_ods 和 web_chat_text_ems_ods 清洗转换后的数据,命令如
下。
CREATE TABLE IF NOT EXISTS itcast_dwd.visit_consult_dwd (
session_id STRING COMMENT "会话 ID",
sid STRING COMMENT "用户 ID",
create_time BIGINT COMMENT "会话创建时间",
ip STRING COMMENT "IP 地址",
area STRING COMMENT "地区",
msg_count INT COMMENT "客户发送消息数",
origin_channel STRING COMMENT "来源渠道",
from_url STRING COMMENT "会话来源页面"
)
COMMENT "访问咨询用户明细表"
PARTITIONED BY (yearinfo STRING, monthinfo STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY "\t"
STORED AS ORC
TBLPROPERTIES ("orc.compress"="SNAPPY");
创建数据库 itcast_dws
在 Hive 中创建数据库 itcast_dws 用于存储明细层的数据,具体命令如下。
CREATE DATABASE IF NOT EXISTS itcast_dws;
创建业务层宽表 visit_dws
在 Hive 的数据库 itcast_dws 中创建业务层的宽表 visit_dws,用于存储访问用户
量指标的数据,具体命令如下。
CREATE TABLE IF NOT EXISTS itcast_dws.visit_dws (
sid_total INT COMMENT "根据用户 ID 去重统计",
sessionid_total INT COMMENT "根据 SessionID 去重统计",
ip_total INT COMMENT "根据 IP 地址去重统计",
area STRING COMMENT "地区",
origin_channel STRING COMMENT "来源渠道",
from_url STRING COMMENT "会话来源页面",
groupType STRING COMMENT "1.地区维度 2.来源渠道维度 3.会话页面维度 4.
总访问量维度"
)
COMMENT "访问用户量宽表"
PARTITIONED BY (yearinfo STRING,monthinfo STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY "\t"
Stored as orc
TBLPROPERTIES ("orc.compress"="SNAPPY");
创建业务层的宽表 consult_dws
在 Hive 的数据库 itcast_dws 中创建业务层的宽表 consult_dws,用于存储咨询用
户量的数据,具体命令如下。
CREATE TABLE IF NOT EXISTS itcast_dws.consult_dws
(
sid_total INT COMMENT "根据用户 ID 去重统计",
sessionid_total INT COMMENT "根据 SessionID 去重统计",
ip_total INT COMMENT "根据 IP 地址去重统计"
)
COMMENT "咨询用户量宽表"
PARTITIONED BY (yearinfo STRING, monthinfo STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY "\t"
STORED AS ORC
TBLPROPERTIES ("orc.compress"="SNAPPY");
三、数据采集与转换
(一)数据迁移过程
1、Sqoop 的简介
Sqoop 是一款开源的工具,主要用于在 Hadoop(Hive)与传统的数据库(mysql、
postgresql … ) 间 进 行 数 据 的 传 递 , 可 以 将 一 个 关 系 型 数 据 库 ( 例 如 :
MySQL ,Oracle ,Postgres 等)中的数据导进到 Hadoop 的 HDFS 中,也可以将 HDFS
的数据导进到关系型数据库中。
sqoop1 最新版本是 1.4.7,sqoop2 最新版本是 1.99.7
sqoop2 特征不完整,不建议用于生产部署。
1.1、sqoop 依赖环境
2、sqoop 集群安装部署。
安装 sqoop 前集群的最低要求安装 mysql,jdk 和 hadoop。
可以添加 hbase,hive 和 zookeeper,进行试验。
参考 hive,hbase,zookeeper 和 hadoop 这些进行搭建。
2.1、sqoop 解压
cd /export/software
tar -zxvf sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz -C /export/servers/
cd /export/servers
mv sqoop-1.4.7.bin__hadoop-2.6.0 sqoop-1.4.7

2.2、sqoop 配置环境变量
vi /etc/profile
# SQOOP_HOME
export SQOOP_HOME=/export/servers/sqoop-1.4.7
export PATH=$PATH:$SQOOP_HOME/bin
source /etc/profile
2.3、sqoop 配置文件
进入 conf
cd /export/servers/sqoop-1.4.7/conf
cp sqoop-env-template.sh sqoop-env.sh

将 hadoop,hive,的绝对路径进行填写。
在Sqoop安装目录的conf目录中修改文件sqoop-env.sh,具体命令如下。
#指定Hadoop安装目录
export HADOOP_COMMON_HOME=/export/servers/hadoop-2.7.4/
export HADOOP_MAPRED_HOME=/export/servers/hadoop-2.7.4/
#指定Hive安装目录
export HIVE_HOME=/export/servers/hive-2.3.9
将 MySQL 的驱动包放到 sqoop 的 lib 下面
cp /export/servers/hive-2.3.9/lib/mysql-connector-java-5.1.40.jar /export/servers/sqoop-1.4.7/lib/
2.4、验证
sqoop help
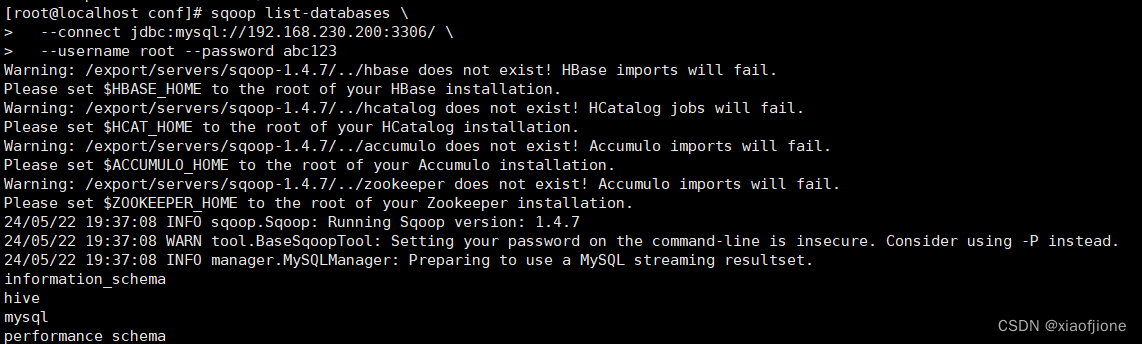
执行Sqoop查看本地Mysql数据库中数据库列表的命令,验证Sqoop是否成功部署,具体命令如下。
sqoop list-databases \
--connect jdbc:mysql://192.168.230.200:3306/ \
--username root --password abc123
导入数据文件
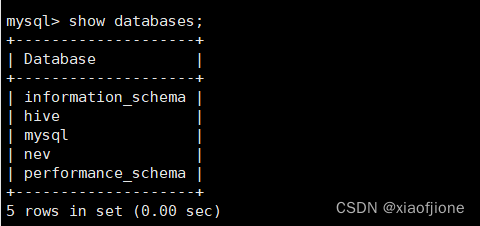
以root身份登录MySQL数据库,在MySQL数据库的命令行交互界面执行“source /export/data/nev.sql”命令,将数据库文件导入到MySQL数据库。数 据库文件导入完成后执行“showdatabases;”命令查看数据库列表。
source /export/data/nev.sql
show databases;
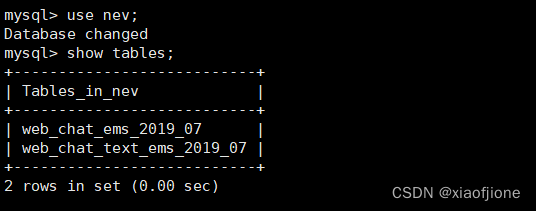
在MySQL的命令行交互界面执行“use nev;”命令,切换到数据库nev,然后执行“show tables;”命令查看数据库nev中的数据表。
use nev;
show tables;
导入依赖包
由于Sqoop向Hive表中导入数据时依赖于Hive的相关jar包,所以需要将Hive的相关jar包导入到Sqoop的lib目录中,具体命令如下。
cp /export/servers/hive-2.3.9/lib/{antlr-runtime-3.5.2.jar,hive-hcatalog-core-2.3.9.jar,hive-exec-2.3.9.jar,datanucleus-api-jdo-4.2.4.jar,datanucleus-core-4.1.17.jar,datanucleus-rdbms-4.1.19.jar,derby-10.10.2.0.jar,javax.jdo-3.2.0-m3.jar} /export/servers/sqoop-1.4.7/lib/
cp /export/servers/hive-2.3.9/lib/derby-10.10.2.0.jar /export/servers/hadoop-2.7.4/share/hadoop/yarn/lib/
导入配置文件
由于Sqoop向Hive表中导入数据时需要获取Hive的配置信息,所以需要将Hive 的配置文件hive-site.xml导入到Sqoop的conf目录下,具体命令如下。
cp /export/servers/hive-2.3.9/conf/hive-site.xml /export/servers/sqoop-1.4.7/conf/
(二)数据转换过程
1.实现数据迁移
(1)在虚拟机 hive执行 Sqoop 命令将 MySQL 数据库的用户会话信息表
web_chat_ems_2019_07
中的数据迁移到 Hive 数据仓库源数据层的 web_chat_ems_ods 源数据表,具体命
令如下所示。
sqoop import \
--connect jdbc:mysql://192.168.230.200:3306/nev \
--username root \
--password abc123 \
--query "select id,create_date_time,session_id,sid,create_time,seo_source,seo_keywords,ip,area,country,province,city,origin_channel,user as user_match,manual_time,begin_time,end_time,last_customer_msg_time_stamp,last_agent_msg_time_stamp, reply_msg_count,msg_count,browser_name,os_info from web_chat_ems_2019_07 where 1=1 and \$CONDITIONS"\
--hcatalog-database itcast_ods \
--hcatalog-table web_chat_ems_ods \
-m 10 \
--split-by id
(2)在虚拟机 hive 执行 Sqoop 命令将 MySQL 数据库的用户会话信息附属表
web_chat_text_ems_2019_07 中 的 数 据 迁 移 到 Hive 数 据 仓 库 源 数 据 层 的
web_chat_text_ems_ods 源数据表,具体命令如下所示。
sqoop import \
--connect jdbc:mysql://192.168.230.200:3306/nev \
--username root \
--password abc123 \
--query "select id,referrer,from_url,landing_page_url,url_title,platform_description,
other_params,history from web_chat_text_ems_2019_07 where 1=1 and \$CONDITIONS" \
--hcatalog-database itcast_ods \
--hcatalog-table web_chat_text_ems_ods \
-m 10 \
--split-by id
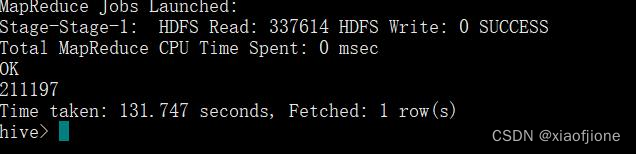
(3)统计源数据表 web_chat_ems_ods 中包含的数据行数,
select count(*) from itcast_ods.web_chat_ems_ods;
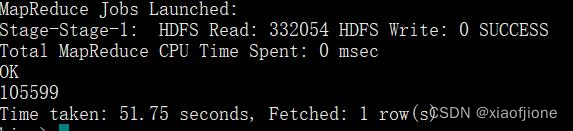
(3)统计源数据表 web_chat_text_ems_ods 中包含的数据行数,具体命令如下。
据转换,具体命令如下。
select count(*) from itcast_ods.web_chat_text_ems_ods;
四、数据分析
(一)实现地区访问用户量统计
- 需求是统计不同地区访问网站的用户量,公司决策者可以根据统计结果对不
同地区的业务进行调整,例如访问用户量比较多的地区可以增加客服人数,减少用
户等待时间;访问用户量比较少的地区可以加大推广,使更多用户了解并访问网
站。接下来,实现地区访问用户量统计,统计结果将存储在访问用户量宽表
visit_dws,具体命令如下。INSERT INTO itcast_dws.visit_dws PARTITION (yearinfo, monthinfo)
SELECT
COUNT(DISTINCT sid) sid_total,
COUNT(DISTINCT session_id) sessionid_total,
COUNT(DISTINCT ip) ip_total,
area,
'-1' origin_channel,
'-1' from_url,
'1' grouptype,
yearinfo,monthinfo
FROM itcast_dwd.visit_consult_dwd
GROUP BY area,yearinfo,monthinfo;
SELECT sid_total,sessionid_total,ip_total,area,yearinfo,monthinfo FROM itcast_dws.visit_dws WHERE grouptype="1" limit 6;
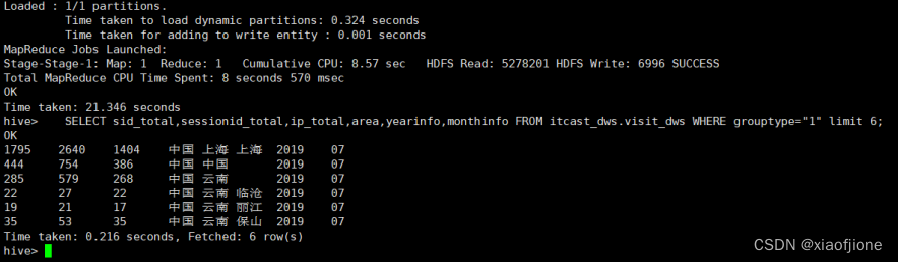
(二)实现会话页面排行榜
- 会话页面是指用户创建客服会话的页面,本需求是统计会话页面排行榜,公司
决策者可以根据统计结果了解网站中哪些页面对用户比较有吸引力,促使用户向
客服咨询。例如用户在浏览网站中的大数据学科相关课程介绍页面时,有大量用
户向客服进行咨询,那么从侧面可以反映出用户对于大数据学科学习的需求量比
较高。接下来,统计会话页面,统计结果存储在访问用户量宽表 visit_dws
INSERT INTO itcast_dws.visit_dws PARTITION (yearinfo, monthinfo)
SELECT
COUNT(DISTINCT sid) sid_total,
COUNT(DISTINCT session_id) sessionid_total,
COUNT(DISTINCT ip) ip_total,
'-1' area,
'-1' origin_channel,
from_url,
'3' grouptype,
yearinfo,monthinfo
FROM itcast_dwd.visit_consult_dwd
GROUP BY from_url,yearinfo,monthinfo;
SELECT sessionid_total,from_url,yearinfo,monthinfo FROM itcast_dws.visit_dws WHERE grouptype="3" AND from_url!="" ORDER BY sessionid_total DESC LIMIT 1;

(三)实现访问用户量统计
- 本需求是统计访问网站的总用户量,公司决策者可以根据统计结果了解网站
的访问情况,并根据实际情况对网站内容以及业务进行有效调整,同时访问用户
量统计结果也可以作为二次分析的底层数据,例如咨询率统计就需要访问用户量
统计结果 。接下来,统计访问用户量,统计结果存储在访问用户量宽表 visit_dws,
具体命令如下。
INSERT INTO itcast_dws.visit_dws PARTITION (yearinfo, monthinfo)
SELECT
COUNT( DISTINCT sid ) sid_total,
COUNT( DISTINCT session_id ) sessionid_total,
COUNT( DISTINCT ip ) ip_total,
'-1' area,
'-1' origin_channel,
'-1' from_url,
'4' grouptype,
yearinfo,monthinfo
FROM itcast_dwd.visit_consult_dwd
GROUP BY yearinfo,monthinfo;
SELECT sid_total,sessionid_total,ip_total,yearinfo,monthinfo
FROM itcast_dws.visit_dws WHERE grouptype="4";

(四)实现来源渠道访问用户量统计
- 本需求是统计通过不同来源渠道访问网站的用户量,公司决策者可以根据统
计结果了解不同渠道投放广告的效果,并根据实际情况进行调整,例如投放效果
好的渠道可以加大投资,投放效果不好的渠道可以舍弃等。接下来,统计来源渠
道访问用户量,统计结果将存储在访问用户量宽表 visit_dws。
INSERT INTO itcast_dws.visit_dws PARTITION (yearinfo,monthinfo)
SELECT
COUNT(DISTINCT sid) sid_total,
COUNT(DISTINCT session_id) session_total,
COUNT(DISTINCT ip) ip_total,
'-1' area,
origin_channel,
'-1' from_url,
'2' grouptype,
yearinfo,monthinfo
FROM itcast_dwd.visit_consult_dwd
19GROUP BY origin_channel,yearinfo,monthinfo;
SELECT sid_total,sessionid_total,ip_total,origin_channel,yearinfo,monthinfo FROM itcast_dws.visit_dws WHERE grouptype="2";
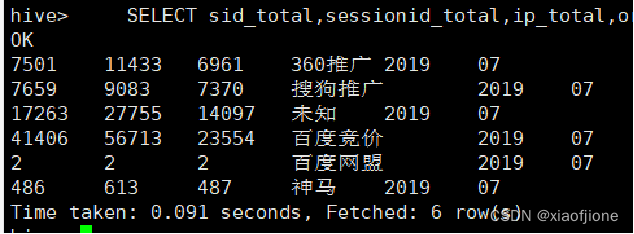
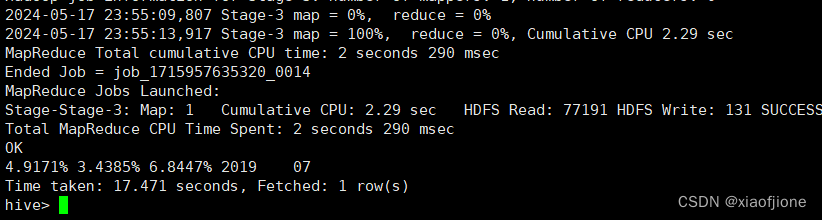
(五)实现咨询率统计
- 实现咨询用户量统计的命令执行完成后,通过访问用户量和咨询用户量统计
结果实现咨询率统计,具体命令如下。
SELECT
CONCAT(ROUND(msgNumber.sid_total / totalNumber.sid_total,4) * 100, '%')
sid_rage,
CONCAT (ROUND (msgNumber.sessionid_total/ totalNumber.sessionid_total,4)*100,
'%') session_rage,
CONCAT (ROUND (msgNumber.ip_total / totalNumber.ip_total,4)* 100, '&')
ip_rage,
msgNumber.yearinfo,
msgNumber.monthinfo
FROM
(
SELECT
sid_total,
sessionid_total,
ip_total,
yearinfo,
monthinfo
FROM itcast_dws.consult_dws
) msgNumber,
(
SELECT
sid_total,
sessionid_total,
ip_total,
yearinfo,
monthinfo
FROM itcast_dws.visit_dws
where grouptype="4"
) totalNumber;
(六)数据可视化
1.导出数据
在虚拟机 hive中执行“mysql -uroot -p”命令以 root 身份登录 MySQL 数据库,
在弹出的“Enter password:”信息处输入 root 用户的密码,从而登录 MySQL 数
据库进入命令行交互界面。
在数据库 nev 中创建表 visit_dws 用于存储 Hive 数据仓库中访问用户量宽表
visit_dws 导出的数据,具体命令如下。
CREATE TABLE nev.visit_dws (
sid_total INT(11) COMMENT '根据用户 ID 去重统计',
sessionid_total INT(11) COMMENT '根据 SessionID 去重统计',
ip_total INT(11) COMMENT '根据 IP 地址去重统计',
area VARCHAR(32) COMMENT '地区', -- 添加单引号并在注释前后加上空格
origin_channel VARCHAR(32) COMMENT '来源渠道', -- 添加单引号并在注释前
后加上空格
from_url VARCHAR(100) COMMENT '会话来源页面', -- 添加单引号并在注释前
后加上空格
groupType VARCHAR(100) COMMENT '1.地区维度 2.来源渠道维度 3.会话页面
维度 4 总访问量维度',
yearinfo VARCHAR(32) COMMENT '年',
monthinfo VARCHAR(32) COMMENT '月'
);
在数据库 nev 中创建表 consult_dws 用于存储 Hive 数据仓库中咨询用户量宽表
consult_dws 导出的数据,具体命令如下。
CREATE TABLE nev.consult_dws (
sid_total INT(11) COMMENT '根据用户 ID 去重统计',
sessionid_total INT(11) COMMENT '根据 SessionID 去重统计',
21ip_total INT(11) COMMENT '根据 IP 地址去重统计',
yearinfo VARCHAR(32) COMMENT '年',
monthinfo VARCHAR(32) COMMENT '月'
);
查看数据库 nev 中是否成功创建表 visit_dws 和 consult_dws,具体命令如下。
/切换到数据库 nev/
use nev;
/查看数据库 nev 中包含的表/
show tables;
在 MySQL 命令行交互界面执行“exit”命令登出 MySQL,在虚拟机 Node02 执
行 Sqoop 命令将 Hive 数据仓库中访问用户量宽表 visit_dws 导出到关系型数据库
MySQL 中 nev 数据库的表 visit_dws,具体命令如下所示。
sqoop export \
--connect "jdbc:mysql://192.168.230.222:3306/nev?useUnicode=true&character
Encoding=utf-8" \
--username root \
--password abc123 \
--table visit_dws \
22--hcatalog-database itcast_dws \
--hcatalog-table visit_dws
在 MySQL 命令行交互界面执行“exit”命令登出 MySQL,在虚拟机 Node02 执
行 Sqoop 命令将 Hive 数据仓库中咨询用户量宽表 consult_dws 导出到关系型数据
库 MySQL 中 nev 数据库的表 consult_dws,具体命令如下所示。
sqoop export \
--connect "jdbc:mysql://192.168.230.222:3306/nev?
useUnicode=true&characterEncoding=utf-8" \
--username root \
--password abc123 \
--table consult_dws \
--hcatalog-database itcast_dws \
--hcatalog-table consult_dws
2.安装、启动与配置 FineBI
访问 FineBI 的官方网站通过注册的方式下载 Windows x64 位操作系统的 FineBI
安装包 windows-x64_FineBI5_1-CN.exe。
双击 FineBI 安装包 windows-x64_FineBI5_1-CN.exe 进入“欢迎使用 FineBI 安装
程序向导“界面。
23在“欢迎使用 FineBI 安装程序向导”界面,下一步”按钮进入“许可协议”界
面,在该界面勾选“我接受协议选项”
在“许可协议”界面,单击“下一步”按钮进入“选择安装目录”界面,在该界
面中配置 FineBI 的安装目录,这里配置 FineBI 的安装目录为“D:\FineBI5.1”
在“选择安装目录”界面,单击“下一步”按钮进入“设置最大内存”界面,在
“最大 jvm 内存”输入框中输入最大 jvm 内存,默认为 2048(2G)。建议设置
最大 jvm 内存大于 2048,这里设置最大 jvm 内存为 4096(4G)。
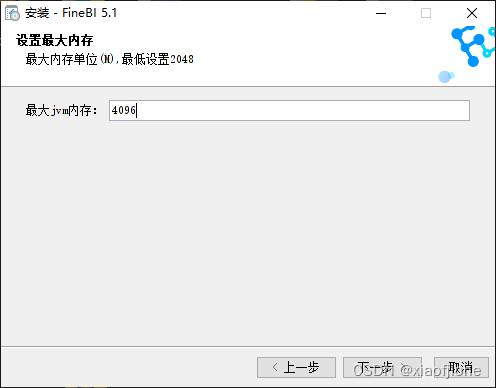
在“设置最大内存”界面,单击“下一步”按钮进入“选择开始菜单文件夹”界
面,在该界面使用默认配置即可。
在“选择开始菜单文件夹”界面,单击“下一步”按钮进入“选择附加工作”界
面,在该界面使用默认配置即可。
在“选择附加工作”界面,单击“下一步”按钮进入“安装中”界面,在该界面
FineBI 会自动安装。
等待 FineBI 安装完成后会自动进入“完成 FineBI 安装程序”界面,在该界面使
用默认配置即可。
26启动 FineBI
打开 FineBI 平台

等待 FineBI 启动完成后,系统默认配置的浏览器会打开 FineBI 平台。
初始化设置
首次使用 FineBI 时需要通过 FineBI 平台进行初始化设置,将用户名设置为“root”,
密码设置为“123456”
在”设置管理员账号界面”,单击“确认”按钮后,平台会显示“管理员账号设
置成功”信息,并且设置的管理员密码会以明文的方式显示
选择 FineBI 使用的数据库
在”管理员账号设置成功界面”,单击“下一步”按钮选择 FineBI 使用的数据
库。
FineBI 登录界面
在”选择 FineBI 使用的数据库”中,单击 “直接登录”选项,页面会自动跳转
到 FineBI 商业智能平台的登录界面。
28登录 FineBI 商业智能平台
输入用户名“root”和密码“123456”,单击“登录”按钮登录 FineBI 商业智
能平台。
数据连接管理
在 FineBI 商业智能平台依次选择“管理系统→数据连接→数据连接管理”进入
数据连接管理界面。
选择 FineBI 使用的数据库
在”数据连接界面”,单击“新建数据连接”按钮选择 FineBI 使用的数据库
29选择 FineBI 使用的数据库
在”选择 FineBI 使用的数据库界面”右侧的数据库列表中,选择“MySQL”选
项,配置连接 MySQL 的相关信息,完成 MySQL 相关信息配置。
选择 FineBI 使用的数据库
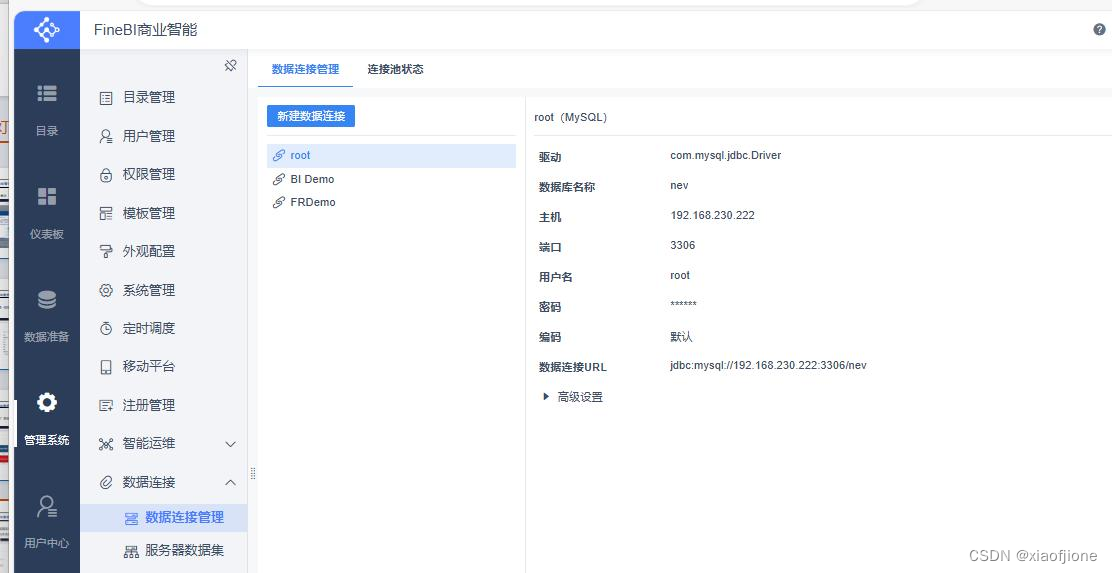
单击“测试连接”按钮,验证 FineBI 是否可以成功连接虚拟机 hive 中的 MySQL
数据库。
数据准备
在 FineBI 商业智能平台选择“数据准备”选项。
配置业务名称
在“数据准备”界面,单击“添加业务包”选项添加业务,并配置业务名称为“教
育大数据分析平台”。
配置业务使用的数据内容
在“配置业务名称”界面,单击业务“教育大数据平台”配置该业务使用的数据
内容。
选择数据库中需要使用的数据表
在“配置业务使用的数据内容”界面,依次单击“添加表→数据库表”选项选择
数据库中需要使用的数据表。
成功添加表
在“选择数据库中需要使用的数据表”界面,选中需要使用的访问用户量表
visit_dws 和咨询用户量表 consult_dws,单击“确认”按钮,在教育大数据平台
业务中展示成功添加表。
业务包更新
单击“业务包更新”选项更新“教育大数据平台”业务中添加表 consult_dws 和
visit_dws 的数据,否则后续无法使用这两个表的数据进行可视化展示。
新建 FineBI 仪表板
在 FineBI 商业智能平台单击“仪表板”选项进入仪表板管理页面,在该页面单
击“新建仪表板”选项,在弹出窗口的“名称”文本框中输入“教育大数据平台”,
单击“确定”按钮新建仪表板。
完成 FineBI 仪表板配置
30单击仪表板“教育大数据平台”,进入教育大数据平台仪表板的配置页面,显示
仪表板配置完成。
(三) 实现数据可视化
统计地区访问用户量
设 置 表 名 为 ” 根 据 sid 统 计 的 地 区 访 问 用 户 量 ” , 然 后 选 择 使 用 的 表
“itcast_visit_dws”,最后勾选使用的字段名称“根据用户 ID 去重统计”和“地
区”。
添加过滤条件
在”根据访问用户量”界面,单击“+”按钮添加过滤条件。
去除字段在过滤条件中去除字段“地区”中值为“-1”的数据,并且指定数据开
头为“中国”。
退出自助数据集页面
在“根据访问用户量”配置过滤条件界面,单击“保存并更新”按钮保存过滤条
件的配置内容,然后单击“×”按钮退出“自助数据集”页面。
添加组件
在弹出的“添加组件”窗口依次选择“教育大数据平台→根据 sid 统计的地区访
问用户量”
配置经纬度
在组件添加完成后,需要将地区字段内的数据转换为经纬度数据,便于后续通过
中国地图的方式进行可视化展示。
手动调整未匹配字段数据
FineBI 会自动将“地区”字段中的数据转换为经纬度,不过此时“地区”字段中
的特殊数据,FineBI 并不会自动匹配并转换,因此需要对特殊字段进行手动调整。
完成经纬度配置
在“手动调整未匹配字段数据”界面,单击“确认”按钮,此时在“地区”字段
下方会多出“地区(经度)”和“地区(纬度)”两个字段。
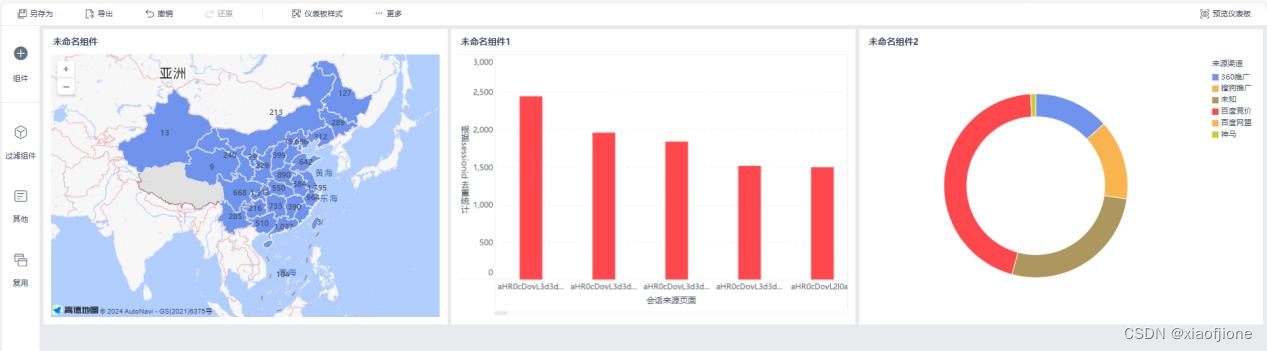
地区访问用户量可视化展示
在“图标类型”一栏中选择区域地区,然后将“地区(经度)”字段拖动到“横
轴”,将“地区(纬度)”拖动到“纵轴”,最后将“根据用户 ID 去重统计”
字段拖动到“图形属性”一栏中的“标签”中,此时 FineBI 会自动实现根据用
户 ID 统计的地区访问用户量可视化展示。
地区用户可视化展示
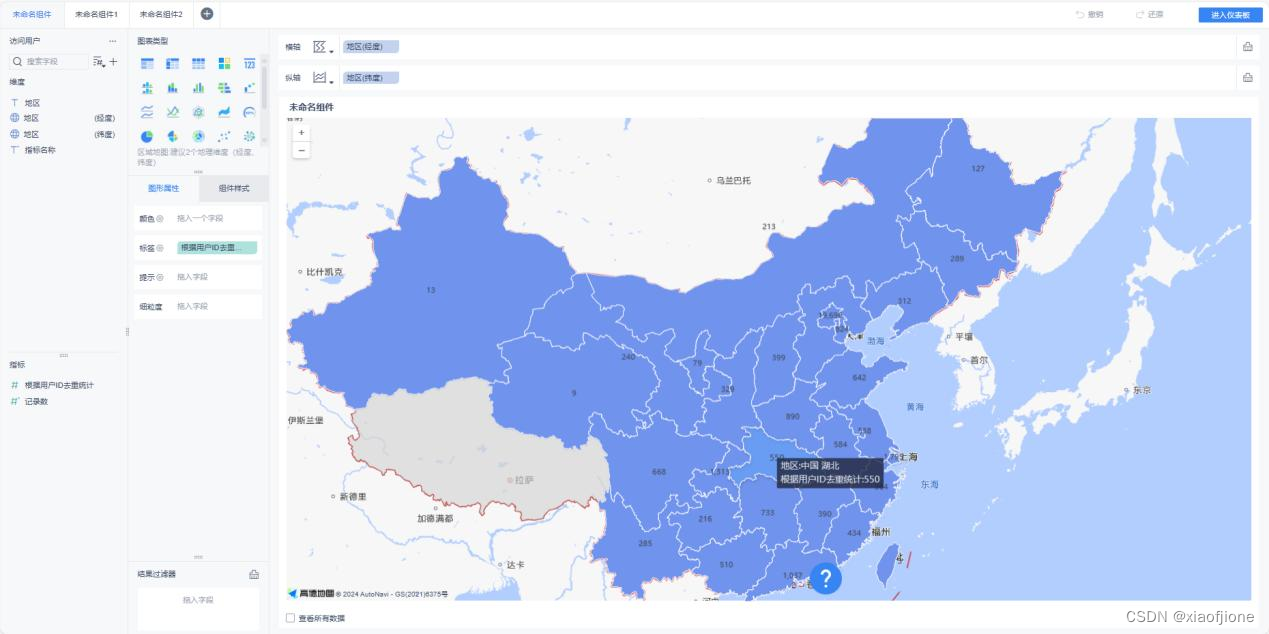
在“根据用户 ID 统计的地区访问用户量可视化展示”界面,更改标题名称,然
后单击“进入仪表板”按钮即可。
配置过滤件
在“根据 Session”选字段界面,单击“+”按钮添加过滤条件,去除字段“会话来源页
面”中的空数据和值为“-1”的数据。
统计会话页面排行榜
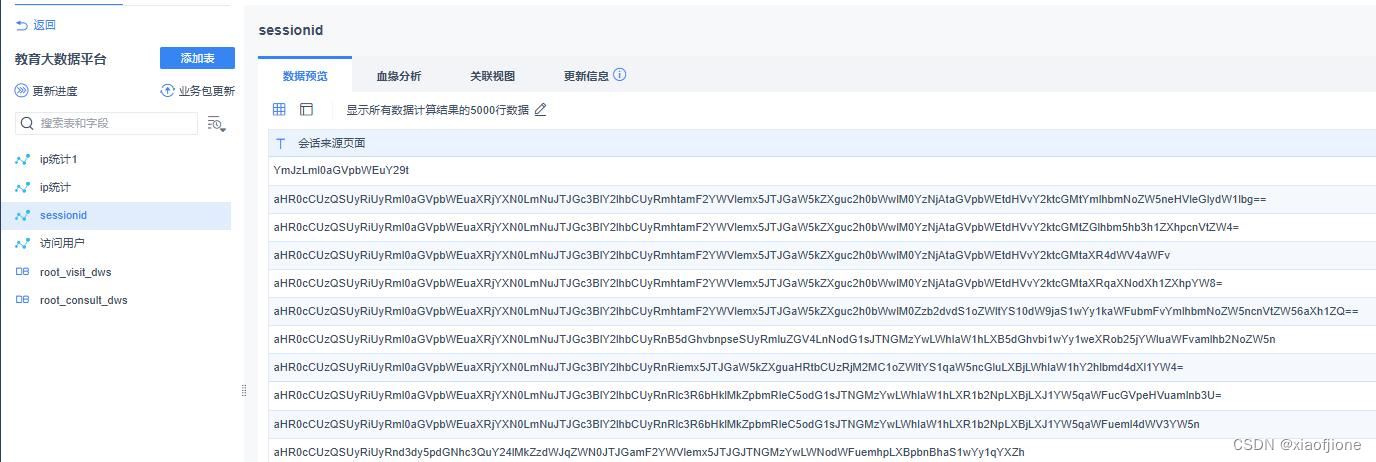
在“实现地区访问用户量可视化”界面,单击“组件”按钮,在弹出的“添加组件”窗
口依次选择“教育大数据平台→根据 Session”。
配置组件页面
在添加组件“Session”界面,单击“确认”按钮进入配置组件页面。
进入仪表盘
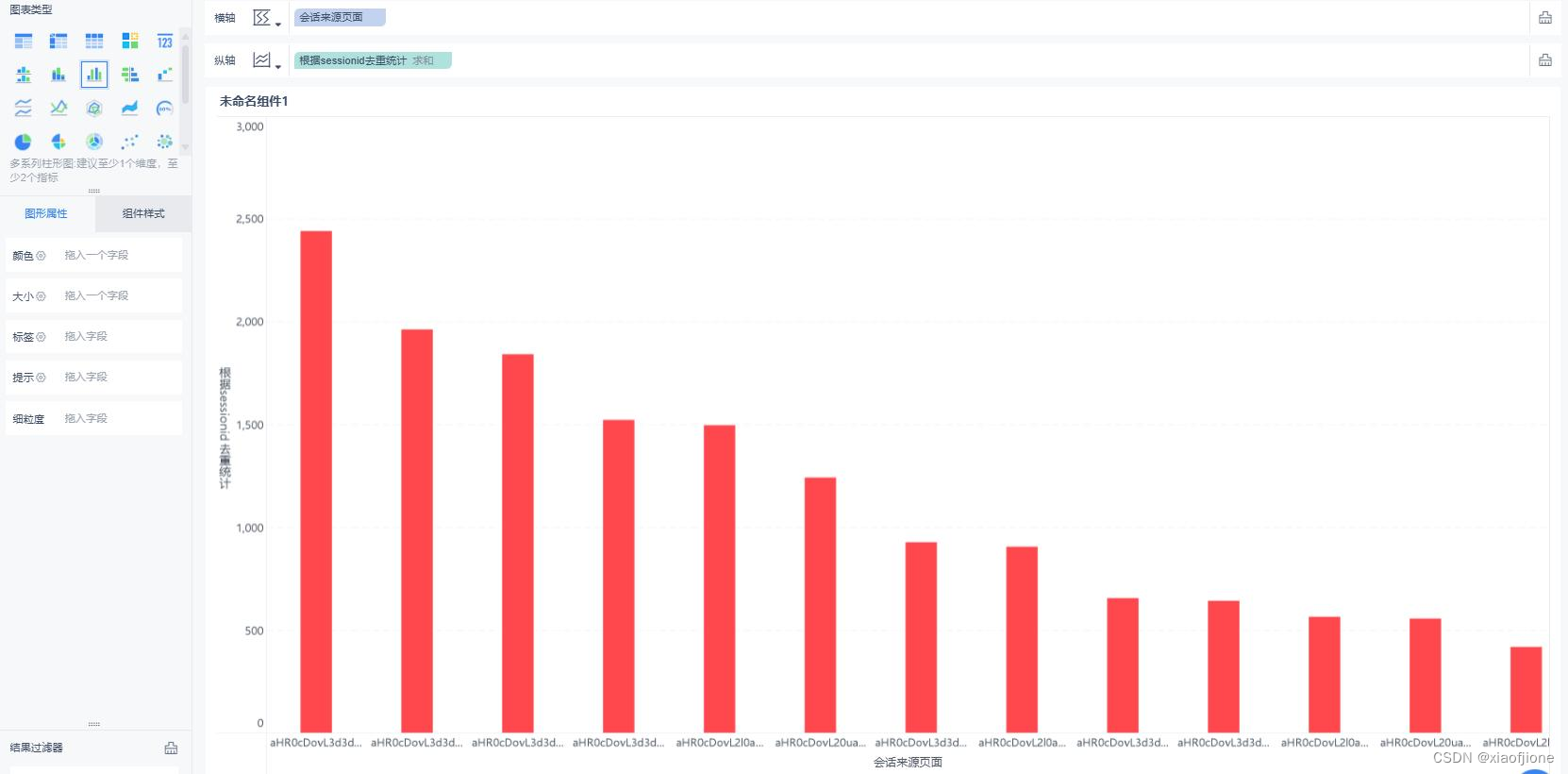
在配置组件“根据 SessionID 统计的会话页面排行榜”界面,单击“进入仪表板”按
钮进入“教育大数据平台”仪表板。
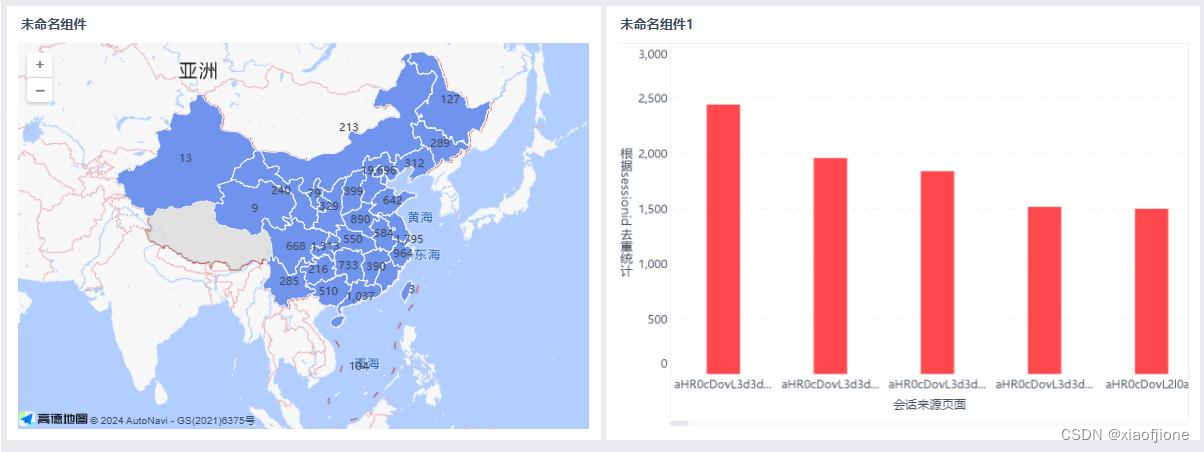
选字段
在“在教育大数据平台业务中成功添加表”页面,依次选择“添加表→自助数据
集”进入自助数据集页面,在该页面中首先设置表名为“根据 ip 统计的来源渠
道访问用户量”,然后选择使用的表“itcast_visit_dws”,最后勾选使用的字段
名称“来源渠道”和“根据 IP 地址去重统计”。
去除字段
在“自助数据集“根据 sid 统计的地区访问用户量”选字段页面,单击“+”按
钮添加过滤条件,去除字段“来源渠道”中值为“-1”的数据。
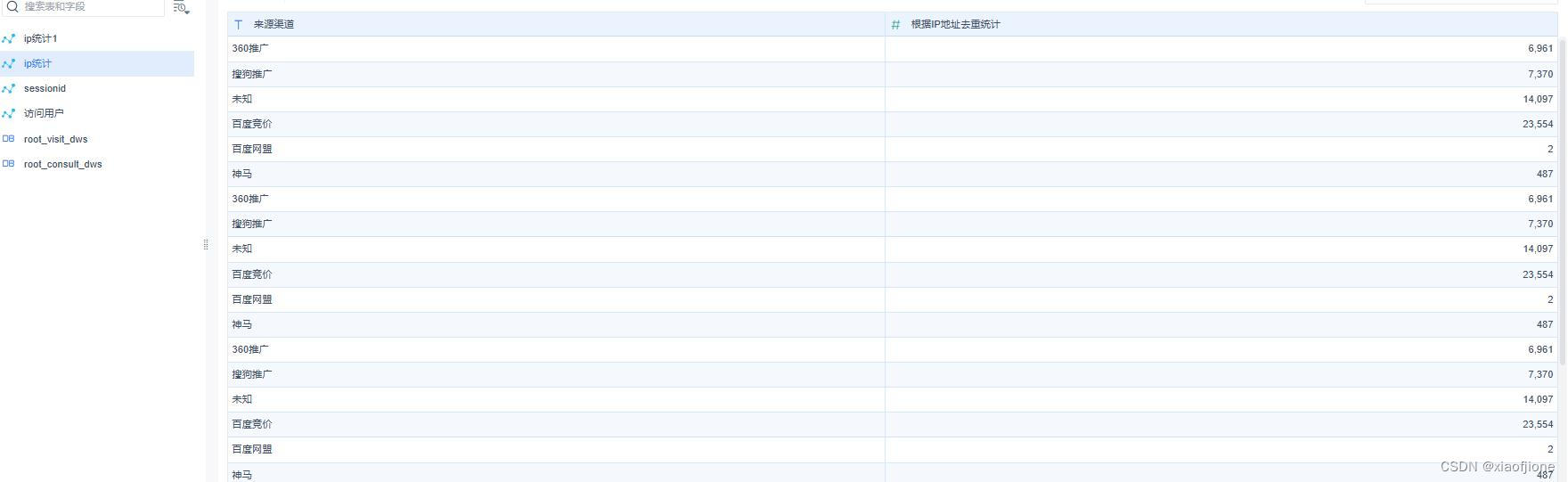
统计访问用户量
在“实现会话页面排行榜可视化”页面,单击“组件”按钮,在弹出的“添加组
件”窗口依次选择“教育大数据平台→根据 ip 统计的来源渠道访问用户量”。
退出自助数据集页面
在 “根据 Session”页面,单击“确认”按钮进入配置组件页面。
成功添加组件
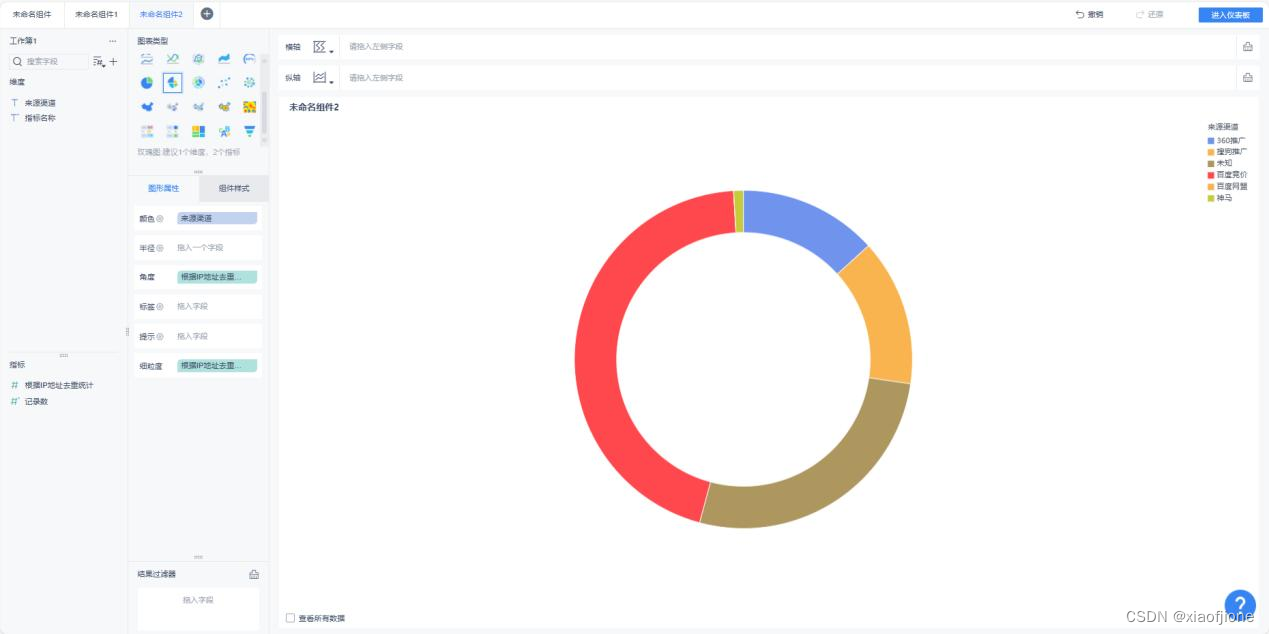
在“根据 ip 统计的来源渠道访问用户量”页面,单击“进入仪表板”按钮进入
“教育大数据平台”仪表板。
版权归原作者 xiaofjione 所有, 如有侵权,请联系我们删除。