
pytorch模型保存与加载总结
模型保存与加载方式
模型保存
方式一
只存储模型中的参数,该方法速度快,占用空间少(官方推荐使用)
model = VGGNet()
torch.save(model.state_dict(), PATH)
方式二
存储整个模型
model = VGGNet()
torch.save(model, PATH)
模型加载
方式一
对应第一种保存方式,首先构架模型架构,然后加载参数
new_model = VGGNet()
new_model.load_state_dict(torch.load(PATH))
方式二
对应第二种保存方式,不再需要第一种方法中的建立新模型的步骤
new_model = torch.load(PATH)
打包保存tar
使用大型数据集进行大网络训练时,往往时间很久,动辄一个星期以上,在这期间偶尔会遇到一些断电之类的需要暂停的情况,这时候你正在训练的模型就很尴尬,你放弃这个模型,之前花费的时间就都算白费;不放弃这个模型,你重新加载这个模型之后,一些类似学习率的超参数应该如何选择也是个问题,可能你原本训练的模型节奏挺好的,重新加载之后学习率不合适那这个模型可能就没有办法继续使用了。因此,在适当的时机保存模型参数,并在保存模型参数的同时保存类似学习率这样的超参数,对于模型训练很重要。因此,pytorch提供了一种模型的保存方式,保存一个压缩包tar,然后下载这个压缩包tar再解析,至于这个压缩包中保存哪些信息就看个人了
保存tar
state = {
'epoch': 10, # 保存当前的迭代次数
'state_dict': resnet18.state_dict(), # 保存模型参数
'learning_rate': 0.000456, # 保存学习率
}
torch.save(state, 'qqq.pth.tar')
加载tar
checkpoint = torch.load('qqq.pth.tar')
epoch = checkpoint['epoch']
model.load_state_dict(checkpoint['state_dict'])
可以看出内部其实是使用第一种模型保存和加载方式,可能这也是官方推荐的原因吧
断点续训
这个位置,个人常在训练的时候使用,用来提高模型最终的准确率。
训练的时候经常遇到一种情况就是,你可能设置了500个epoch,但是当模型跑到200个epoch之后,损失和精度就上不去了,或者出现明显的过拟合了,剩下的300个epoch,纯属浪费时间,这300个epoch对模型几乎没啥影响。但是其实你在200个epoch时保存参数和学习率,然后重新加载模型,并将学习率调低,你的损失有可能会再降一些,精度有可能会得到提高。
多卡训练遇到的问题
当你使用多块GPU进行训练的时候,保存的参数名称是module.conv1.weight,而单卡的参数名称是conv1.weight,这时你保存完模型后,再重新加载就会报错,找不到相应的字典。
报错

解决办法1
其实解决办法也挺简单的,就是在保存的时候把参数名中的‘module.’去掉就行,
就是将torch.save(model.state_dict(), 'fff.pth'))改为torch.save(model.module.state_dict(), 'fff.pth'))
保存模型
model = torch.nn.DataParallel(model)
torch.save(model.module.state_dict(), 'fff.pth'))
加载模型
model.load_state_dict(torch.load(load_pth_name))
解决办法2
其实解决办法挺简单的,就是在加载的时候把参数名中的‘module.’去掉就行
保存模型
model = torch.nn.DataParallel(model)
torch.save(model.state_dict(), 'fff.pth'))
加载模型
state_dict = torch.load(load_pth_name)
from collections import OrderedDict
new_state_dict = OrderedDict()
for k, v in state_dict.items():
name = k[7:] # remove `module.`
new_state_dict[name] = v
model.load_state_dict(new_state_dict)
这个位置好像是在哪见过一个更高级的写法,但是有些记不清了,等到之后想起来再更新吧
OrderedDict
这个位置简单介绍一个OrderedDict,OrderedDict是dict的子类,其最大的特征就是可以维护添加的key-value对的顺序。说白了,OrderedDict也是一个字典,但是这个字典中的key-value对是有顺序的。这个特性正好可以跟网络结构的层次性对应起来。
代码
from collections import OrderedDict
ordered1 = OrderedDict(a=1, b=2, c=3)
ordered2 = OrderedDict()
print(ordered1)
print(ordered2)
ordered2['bbb'] = 1
ordered2['aaa'] = 2
print(ordered2)
输出
OrderedDict([('a', 1), ('b', 2), ('c', 3)])
OrderedDict()
OrderedDict([('bbb', 1), ('aaa', 2)])
其实就是字典,输入的顺序不是安装字符的顺序,而是按照输入的顺序。解决方法2中无非就是借用这么个东西,更改一下结构节点名
torch.jit
其实pytorch还有一种模型保存和加载的方式,就是torch.jit。
pytorch为了在C++上能够运行训练好的模型,出了个包叫libtorch。libtorch之后,你就能够用C语言调用pytorch训练好的模型,毕竟最后工程化的东西不可能让你使用python的代码,这种东西其实有挺多的,比如说opencv就能够读取pytorch训练好的模型,然后使用c的代码;英伟达也有tensorRT;什么阿里、小米啥的有mnn、ncnn,都是偏C,偏工程化的东西。
为了配合libtorch,便于模型在C上运行,pytorch又推出了一个保存和加载模型的包,就是torch.jit
jit 保存模型
resnet18 = models.resnet34(pretrained=True)
dummy_input = torch.rand(1, 3, 256, 256).to('cpu')
torch_trace_model = torch.jit.trace(resnet18, dummy_input)
torch.jit.save(torch_trace_model, 'www.pth')
jit 保存模型的方式,和之前的保存方式还是有一些差别,jit 需要指定输入的尺寸
注意,需要转换模式torch.jit.trace,不然会报错

trace与script
在使用jit保存模型之前是需要进行模型转换的,转换的方式其实是有两种,一种是torch.jit.trace,另一种是torch.jit.script,这两种方式在大多数的情况下是相同的,但是也存在一些差异
总体而言就是script能够保存整个的网络结构,而trace只能保存你输入张量经过的网络结构。
因此,大多数的情况下两者是相同的,但是当网路结构中有对输入的张量进行判断而走不同的分支的时候,两者又不相同,如下方代码:
class ControlFlowModule(torch.nn.Module):
def __init__(self):
super(ControlFlowModule, self).__init__()
self.l0 = torch.nn.Linear(4, 2)
self.l1 = torch.nn.Linear(2, 1)
def forward(self, input):
if input.dim() > 1:
return torch.tensor(0)
out0 = self.l0(input)
out0_relu = torch.nn.functional.relu(out0)
return self.l1(out0_relu)
if __name__ == '__main__':
a = torch.randn(4)
b = torch.randn(2, 4)
traced_module = torch.jit.trace(ControlFlowModule(), a)
torch.jit.save(traced_module, 'controlflowmodule_traced.pt')
loaded = torch.jit.load('controlflowmodule_traced.pt')
e = loaded(b)
scripted_module = torch.jit.script(ControlFlowModule(), a)
torch.jit.save(scripted_module, 'controlflowmodule_scripted.pt')
loaded = torch.jit.load('controlflowmodule_scripted.pt')
f = loaded(b)
当保存模型时输入都为a,重新加载模型后输入为b,此时e为tensor([[0.5855], [0.2653]],grad_fn=<AddmmBackward>),f为tensor(0)。
a的维度为1,因此trace固化模型时,保存下来的分支是return self.l1(out0_relu),return torch.tensor(0)分支被舍弃掉了。因此,当固化完模型重新加载进来之后,缺少return torch.tensor(0)分支,此时输入b维度为2时也无法运行此分支,因为不存在。
jit 加载模型
model = torch.jit.load(model)
C加载模型
这个位置详细的内容可以参考后面参考链接,pytorch给了说明文档
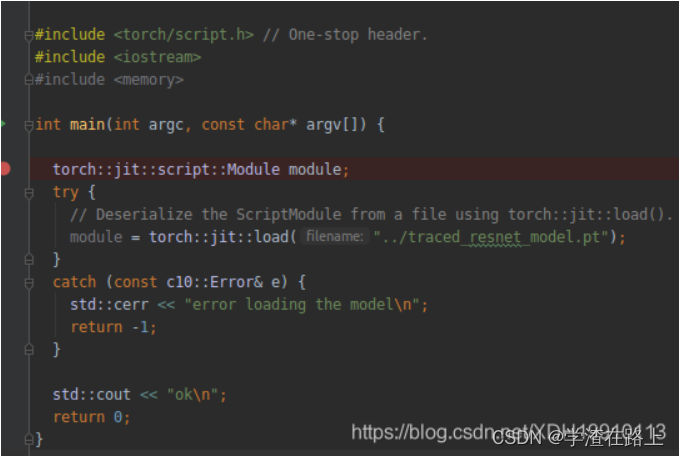
加载预训练模型
import torchvision.models as models
resnet18 = models.resnet18(pretrained=True) #加载参数
resnet18 = models.resnet18(pretrained=False) #只加载网络结构,不加载参数
报错
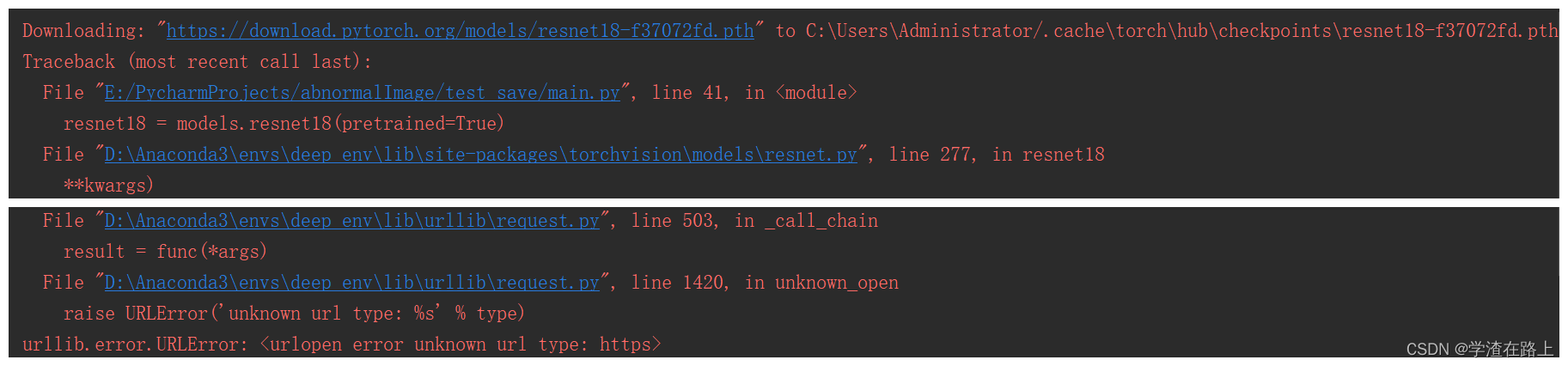
说明
据说是没有ssl模块不支持https
解决办法1
将https改为http
即将Downloading: "https://download.pytorch.org/models/resnet34-b627a593.pth" 改为
Downloading: "http://download.pytorch.org/models/resnet34-b627a593.pth" ,如下方所示
model_urls = {
'resnet18': 'https://download.pytorch.org/models/resnet18-f37072fd.pth',
#'resnet34': 'https://download.pytorch.org/models/resnet34-b627a593.pth',
'resnet34': 'http://download.pytorch.org/models/resnet34-b627a593.pth',
'resnet50': 'https://download.pytorch.org/models/resnet50-0676ba61.pth',
'resnet101': 'https://download.pytorch.org/models/resnet101-63fe2227.pth',
'resnet152': 'https://download.pytorch.org/models/resnet152-394f9c45.pth',
'resnext50_32x4d': 'https://download.pytorch.org/models/resnext50_32x4d-7cdf4587.pth',
'resnext101_32x8d': 'https://download.pytorch.org/models/resnext101_32x8d-8ba56ff5.pth',
'wide_resnet50_2': 'https://download.pytorch.org/models/wide_resnet50_2-95faca4d.pth',
'wide_resnet101_2': 'https://download.pytorch.org/models/wide_resnet101_2-32ee1156.pth',
}
我用的是anaconda虚拟的环境,环境名叫deep_env
在D:\Anaconda3\envs\deep_env\Lib\site-packages\torchvision\models\resnet.py找到上面的地址
解决办法2
第二个方法就比较直接了,

模型下载地址和存放地址在报错时都会提示出来
加载部分预训练模型
resnet50 = models.resnet50(pretrained=True)
pretrained_dict =resnet50.state_dict()
model =Net(...) # 读取参数
model_dict = model.state_dict() # 将pretrained_dict里不属于model_dict的键剔除掉
pretrained_dict = {k: v for k, v in pretrained_dict.items() if k in model_dict}
model_dict.update(pretrained_dict) # 更新现有的model_dict
model.load_state_dict(model_dict) # 加载我们真正需要的state_dict
更改预训练模型
预训练模型加载完成之后,是可以被修改的。修改的网络结构参数一定要与上下的结构相对应,不然无法运行成功
resnet34 = models.resnet34(pretrained=True)
resnet34.fc = nn.Linear(512, 2)
保存模型再加载精度损失
类似于知乎上的这个问题:
pytorch保存模型再加载比训练时低了两个点,这是为什么呢? - 知乎
问题分析
这个位置其实无非是要确认两个方面,一个是你的输入,一个是你的模型,只要是你的输入相同,模型相同,输出的结果不可能不一样。
不同的原因
数据增强里面有一些随机的东西
读数据的时候打乱顺序
模型不同
你保存模型或者是加载模型时的model模式,一定要切换成eval模式,train模式时,模型还在迭代,很容易造成你保存模型前的模型和你保存后重新加载进来的模型有差异,造成精度对不上。
代码
我将读取数据的位置设置成这个样子,就是不打乱顺序,不进行数据增强,防止一些随机参数对结果的影响
test_dataloader = torch.utils.data.DataLoader(test_dataset, batch_size=1, shuffle=False, num_workers=args.num_workers)
model.eval()
torch.save(model.state_dict(), 'rrr.pth')
训练时精度

测试时精度

两者精度完全一样
加载时
model.load_state_dict(torch.load(load_pth_name))
model.eval()
当加载模型时,不切换eval()模式也很容易出现下面的情况,精度完全是乱的对不上

一定注意切换model.eval()模型,防止模型的继续更新,或者可以深拷贝模型
未理解
没想明白为啥模型的第一种保存和加载方式更好,被推荐。
第一种方法只存储模型中的参数,该方法速度快,占用空间少。以resnet34为例,第一种存储方式模型大小为85281kb,第二种存储方式模型大小为85295kb,就差了14kb,这种空间占用完全没必要考虑吧
参考链接
pytorch如何保存模型? - 知乎
Serialization semantics — PyTorch 1.12 documentation
Loading a TorchScript Model in C++ — PyTorch Tutorials 1.12.1+cu102 documentation
pytorch模型加载方法汇总 - 走看看
https://www.jianshu.com/p/4905bf8e06e5
PyTorch模型读写、参数初始化、Finetune - leizhao - 博客园
版权归原作者 学渣在路上 所有, 如有侵权,请联系我们删除。