
在RISC-V平台上进行Pytorch源码编译
此次适配的环境是在算能的云空间中(可通过 https://www.sophon.cn/ 申请),适配流程参考了山东大学智研院的博客(原文链接 https://zhuanlan.zhihu.com/p/655277146)并进行了一定的补充。
算能云空间的服务器配置如下所示: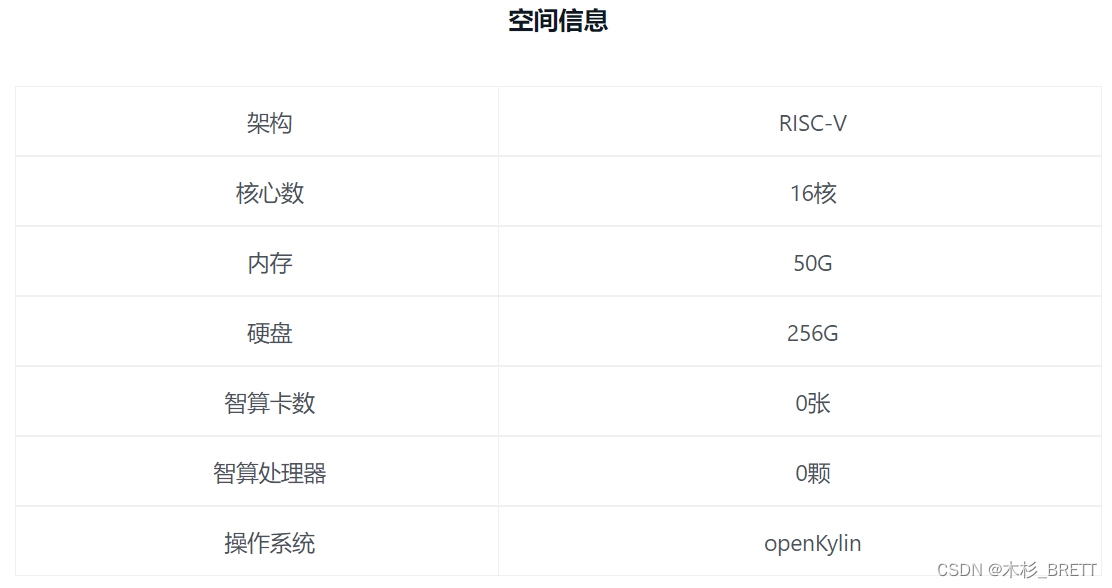
由于算能云空间中缺少基础的python环境以及一些包,因此在适配pytorch框架前需要一些预先的准备工作。
预先准备
由于笔者全程在root下配置,因此命令可不用添加sudo,若未在root下请在命令行前加上sudo,如:sudo apt …
python环境配置
apt install python3
apt install python-is-python3 python-dev-is-python3
apt autoremove
# 下载好python3后发现没有pip、yaml等工具
apt install python3-pip
pip install pyyaml
git安装
apt install git
编译工具链安装
apt install libopenblas-dev libblas-dev m4 cmake cython3 ccache
# 若执行过程中有以下报错,则杀死10198进程:Waiting for cache lock: Could not get lock /var/lib/dpkg/lock-frontend. It is held by process 10198 (apt)
kill -910198# 安装过程中,若发现libopenblas-dev无法正常安装,则跳过其直接安装libblas-dev m4 cmake cython3 ccache
apt install libblas-dev m4 cmake cython3 ccache
# libopenblas-dev无法安装的替代方案:手动安装OpenBLAS
git clone https://github.com/xianyi/OpenBLAS.git
cd OpenBLAS
make -j8
sudo make PREFIX=/usr/local/OpenBLAS install
# 进入/etc,用vim打开profile[在最后一行添加]: export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/OpenBLAS/lib/
source /etc/profile
源码获取
# 首先进入/root/yourname目录,再克隆pytorch源码# 由于网络问题可能无法下载好所有的包,但执行之后的git submodule update --init --recursive会将未下好的包重新clone
git clone --recursive https://github.com/pytorch/pytorch.git
cd pytorch
# 确保子模块的远程仓库URL与父仓库中的配置一致
git submodule sync
# 确保获取并更新所有子模块的内容,包括初始化尚未初始化的子模块并递归地处理嵌套的子模块
git submodule update --init --recursive
Commit 文件修改
本节中需要用到Vim对一些文件进行修改,涉及到的Vim操作主要有:
- Vim打开文件:vim filename
- Vim搜索:使用 / 向前搜索,使用 ? 向后搜索,搜索后按 Enter 定位
- Vim编辑:使用 shift+i 进入编辑模型,使用 Esc 退出编辑模式
- Vim保存:使用 :wq 保存并退出
- aten/src/ATen/CMakeLists.txt
将语句:if(NOT MSVC AND NOT EMSCRIPTEN AND NOT INTERN_BUILD_MOBILE)
替换为:if(FALSE)
- caffe2/CMakeLists.txt
将语句:target_link_libraries(${test_name}_${CPU_CAPABILITY} c10 sleef gtest_main)
替换为:target_link_libraries(${test_name}_${CPU_CAPABILITY} c10 gtest_main)
- test/cpp/api/CMakeLists.txt
在语句下:add_executable(test_api ${TORCH_API_TEST_SOURCES})
添加:target_compile_options(test_api PUBLIC -Wno-nonnull)
环境变量配置
# 直接在终端中输入即可,重启需要重新输入
export USE_CUDA=0
export USE_DISTRIBUTED=0
export USE_MKLDNN=0
export MAX_JOBS=16
编译
python3 setup.py develop --cmake
编译及引用过程可能会遇到的问题
- Could not find any of CMakeLists.txt, Makefile, setup.py, LICENSE, LICENSE.md, LICENSE.txt in /root/xxx/pytorch/third_party/pthreadpool
问题来源:编译过程
问题分析:由于网络的问题,clone仓库时有部分包未成功下载,导致文件夹为空
解决方法:重新下载对应包
- 进入third_party目录
- 在终端执行以下指令
rm -rf pthreadpool
# 执行下列指令前回退到pytorch目录
git submodule update --init --recursive
- /usr/bin/ld: /root/xxx/pytorch/build/lib/libtorch_cpu.so: undefined reference to `__atomic_exchange_1’****collect2: error: ld returned 1 exit status
问题来源:编译过程
问题分析:对__atomic_exchange_1的未定义引用
解决方法:使用patchelf添加需要的动态库
# path为存放libtorch_cpu.so的路径
patchelf --add-needed libatomic.so.1/path/libtorch_cpu.so
# 若提示无patchelf命令,则执行下列语句
apt install patchelf
- Error in cpuinfo: processor architecture is not supported in cpuinfo
问题来源:编译完成后,使用python时“import torch”报错
问题分析:git clone时下载的cpuinfo不支持Risc-V架构
解决方法:删除当前存在的cpuinfo并重新下载最新支持Risc-V架构的cpuinfo
- cpuinfo路径为pytorch/third_party/cpuinfo,因此先进入pytorch/third_party目录
- 在终端执行以下指令
rm -rf cpuinfo
git clone https://github.com/sophgo/cpuinfo.git
# clone完成后需要重新编译
python3 setup.py develop --cmake
深度学习模型实例
本节提供了一个简单的全连接神经网络模型的实例,可用于测试环境是否能正常运行并输出损失值
运行前置:
- 在pytorch目录下创建一个文件:touch sample.py
- 使用vim打开sample.py并将以下代码复制进文件中并保存
import torch
import torch.nn as nn
import torch.optim as optim
import os
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
N,D_in,H,D_out =64,1000,100,10# N: batch size, D_in:input size, H:hidden size, D_out: output size
x = torch.randn(N,D_in)# x = np.random.randn(N,D_in)
y = torch.randn(N,D_out)# y = np.random.randn(N,D_out)
w1 = torch.randn(D_in,H)# w1 = np.random.randn(D_in,H)
w2 = torch.randn(H,D_out)# w2 = np.random.randn(H,D_out)
learning_rate =1e-6for it inrange(200):# forward pass
h = x.mm(w1)# N * H h = x.dot(w1)
h_relu = h.clamp(min=0)# N * H np.maximum(h,0)
y_pred = h_relu.mm(w2)# N * D_out h_relu.dot(w2) # compute loss
loss =(y_pred - y).pow(2).sum()# np.square(y_pred-y).sum()print(it,loss.item())# print(it,loss) # BP - compute the gradient
grad_y_pred =2.0*(y_pred-y)
grad_w2 = h_relu.t().mm(grad_y_pred)# h_relu.T.dot(grad_y_pred)
grad_h_relu = grad_y_pred.mm(w2.t())# grad_y_pred.dot(w2.T)
grad_h = grad_h_relu.clone()# grad_h_relu.copy()
grad_h[h<0]=0
grad_w1 = x.t().mm(grad_h)# x.T.dot(grad_h) # update weights of w1 and w2
w1 -= learning_rate * grad_w1
w2 -= learning_rate * grad_w2
- 运行文件:python3 sample.py
本文转载自: https://blog.csdn.net/m0_49267873/article/details/135670989
版权归原作者 木杉_BRETT 所有, 如有侵权,请联系我们删除。
版权归原作者 木杉_BRETT 所有, 如有侵权,请联系我们删除。